基于注意力混合模型的中文医疗问答匹配
2021-11-15贾丽娜李冠宇
贾丽娜 陈 恒,2 李冠宇
1(大连海事大学计算机科学与技术系 辽宁 大连 116026) 2(大连外国语大学语言智能研究中心 辽宁 大连 116044)
0 引 言
随着互联网的发展及应用,线上医疗咨询越来越受欢迎,如寻医问药、好大夫和求医等平台。此类平台可以实现用户和专家无挂号交流。用户可以向专家发送病情,并得到专家回复。但是随着用户数量的增加,待解决的问题增加,难以保证24小时高质量服务。这为医生回复带来了负担,也降低了用户体验。为了解决等待时间延长的问题,设计了一个将问句与答案相匹配、自动选出最合适的答案自动问答系统。
在医疗问答服务中,存在着许多对于同一症状使用相似却不同的单词和句子进行描述,这些描述为实现医疗问答系统提供了可能。传统的问答系统采用信息检索[1-2]、手工规则[3-4]和浅层机器学习[5-6]等方法,这些方法只能获取浅层的特征和语句关系,深层特征仍需要人工获取,因此机器模型缺乏泛化能力。
近年来,最流行的方法是使用深度学习进行问答对匹配,其关键是如何有效地获取句子中重要的特征信息和关系。卷积神经网络CNN模型能够通过卷积层和池化层获取句子中局部位置不变的特征信息[7,21]。在CNN上改进的多尺度卷积神经网络(Multiscale Convolutional Neural Network, Multi-CNN)和堆栈卷积神经网络(stack Convolutional Neural Network,stack-CNN)等模型也在应用上取得了显著的效果。循环神经网络RNN[8]以及其变体长短期记忆网络(Long Short-Term Memory, LSTM)[9,22-23]和门控网络(Gated Recurrent Unit, GRU)[10]模型在考虑句子长距离依赖关系问题上被广泛应用。然而这些方法通常只使用一个单一神经网络结构对问答对进行嵌入表示,没有捕捉到问答对之间更复杂的语义关系和特征信息,改进程度有限。
为了尽可能多地获取问答对之间的内在语义特征,本文采用Multi-CNN和双循环门控网络(Bidirectional Gated Recurrent Unit, BiGRU)相结合,并引入注意力机制的混合模型(Attention-based BiGRU-CNN, ABiGRU-CNN)来对问答对进行处理。该模型不仅能获取问答对的局部特征信息和长距离依赖关系,还能结合注意力机制为问答对匹配中的重要信息赋予更高的权重。在cMedQA数据集上的实验表明,ABiGRU-CNN模型在医学问答匹配上明显优于现有方法。
1 相关工作
1.1 传统方法
Cairns等[1]提出了一个具有查询公式和自动问答注释等功能集成的MiPACQ系统来检索候选答案段落。Li等[18]使用BM25算法检索包含问题及其答案的语料库并将候选答案进行排序,用于问答匹配。这类方法属于传统手法中信息检索,包括查询扩展和候选答案重排序操作,但其匹配采用的关键词搜索策略对语义的分析和匹配效果不够好。
Athenikos等[3]提出了一个基于规则的医学领域问答系统的框架,以逻辑推理方式获得问题的正确答案。Jain等[4]提出了一种基于规则的问答系统的体系结构来对问题操作和答案检索方法进行描述。这类手工设计方法在面对多样的问答对时,缺少灵活性。
Moschitti等[12]提出了有监督的判别模型,该模型包括支持向量机、字符串核和语法树核等方法,能通过对答案进行排序选择得到与问题相匹配的正确答案。Lecun等[13]提供了一种基于支持向量机的基于上下文的问题解答模型,该模型具有问题分类和文档检索等功能。然而,浅层机器学习方法仍需要人工进行深层特征分类。
1.2 深度学习方法
近年来,深度学习被广泛用于问答领域中。例如RNN模型经常被用于获取句子序列和长距离依赖关系信息,CNN模型用于获取句子局部置不变特征信息。
Xu等[8]提出一种基于全时监控的双向RNN模型,该模型可以在每一个时刻进行监督。Qiu等[14]提出一种用于社区问答的卷积神经张量网络,它将句子建模语义匹配集成到一个基于卷积层和和流层组合的模型中,可以学习问题与答案之间的匹配度量。Zhang等[15]提出了Multi-CNN框架,利用多尺度卷积核获取问答对特征信息。
深度学习虽然在获取信息方面具有很好的效果,但上述的方法都是基于单一的神经网络建模,只能获取句子单侧信息。而在问答对匹配中需要更多具有代表意义的特征,因此有必要设计和实现更加复杂的神经网络。
2 基于注意力BiGRU-CNN模型
2.1 ABiGRU-CNN总体框架

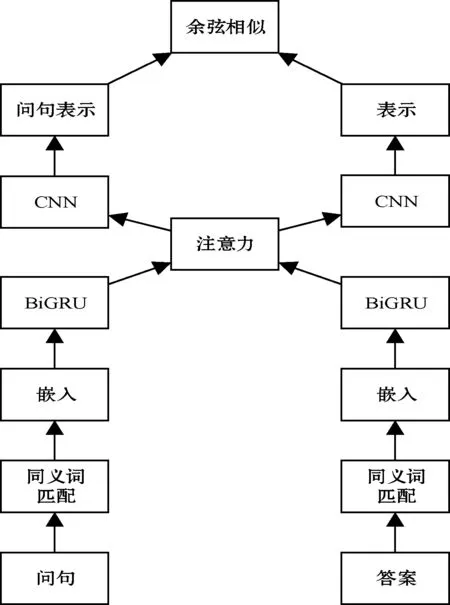
图1 ABiGRU-CNN总体框架
2.2 Multi-CNN模型
单尺度卷积神经网络(Single Convolutional Neural Network, Single-CNN)通过大小被固定的卷积核获取句子的单词特征。由于卷积核的大小不变,该模型只能获取句子的一部分(单侧)特征信息,这对于医疗问答中所要求的精准匹配显然是不合适的。针对这一问题,多尺度卷积神经网络(Multi-CNN)[16]使用一系列大小不同的卷积核对输入语句进行卷积,以弥补了单尺度卷积神经网络的不足。图2为Multi-CNN的网络架构获取上下文信息过程。输入到Multi-CNN模型中的语句被不同尺度卷积核进行卷积,再被最大池化以获取最重要的特征信息。

图2 Mutli-CNN网络框架
(1)

在句子匹配中,经卷积所提取的特征还需要通过池化层处理,以获得句子中最重要的特征信息。常用的池化处理方法有最大池化(max-pooling)和平均池化(mean-pooling),本文对Oq选择最大池化获取最大特征值获取问句的嵌入表示。其公式为:
(2)
(3)

Multi-CNN通过不同尺度的卷积能够有效获取句子的局部位置不变特征,但是CNN不能通过卷积获取句子的长距离依赖关系,因此Multi-CNN的能力和性能是有限的。
2.3 BiGRU模型
由2.2节可知Multi-CNN对获取句子中的局部位置不变特征信息有显著的效果,却不能获取序列中长距离依赖关系。在RNN中,当前隐藏层的输出不仅取决于当前输入值还与上一个隐藏层输出值有关,这使得RNN具有长期记忆功能,可以有效地获取句子序列中的语序信息和长距离依赖关系。而RNN长期依赖学习容易出现梯度消失和爆炸问题,因此GRU和LSTM等变体被提出。GRU和LSTM性能相当,但GRU更容易训练,图3为双向循环门控神经网络(BiGRU)的结构。

图3 BiGRU网络框架
(4)
(5)
(6)
(7)

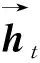
2.4 BiGRU-CNN模型
如2.2节和2.3节所述,BiGRU可以通过更新门和重置门获取句子全局依赖关系信息,而Multi-CNN则可以通过多尺度卷积神经网络获取句子局部特征信息。为了同时获得长距离相关性和位置不变特征信息,提出了一个基于BiGRU和Multi-CNN叠加的神经网络模型(BiGRU-CNN),其结构如图4所示。在模型中BiGRU的前向和后向输出连接成Multi-CNN的输入,而Multi-CNN则利用多个不同大小的卷积核获取句子特征信息。

图4 Multi-CNN网络框架
BiGRU-CNN模型结合BiGRU和Multi-CNN的优点,能够获取到更丰富的问答对关系和特征。但堆叠神经网络获取的问答对特征在结果匹配中会失去重点性,使得问答对的匹配结果并不理想。
2.5 ABiGRU-CNN模型

MA=(Hq)Τ·Ha
(8)
式中:MA∈Rn×m为所求的语义矩阵。
计算问句的权重公式:
Up=tanh(Wp·MΤ)
(9)
αp=softmax((wp)Τ·Up)
(10)
式中:Wp和wp表示参数;Up为随机初始化的权重矩阵;αp为归一化注意力权重矩阵。
Xp=Hqαp
(11)
式中:Xr为加入权重后的问句表示。
相同的步骤,获得答案的权重公式:
Us=tanh(Ws·M)
(12)
αs=softmax((ws)Τ·Us)
(13)
式中:Ws和ws表示参数;Us为随机初始化的权重矩阵;αs为归一化注意力权重矩阵。
Xs=Haαs
(14)
式中:Xc为加入权重后的句子表示。
之后,将加权后的问答句表示输入CNN进行多尺度卷积和最大池化处理,如图2所示。最后将问答句进行相似度计算,得到最终匹配结果。
2.6 目标函数
l=max{0,Mr-sim(rqiw,rai w+)+sim(rqiw,raiw-)}
(15)
3 实验与结果分析
3.1 数据处理

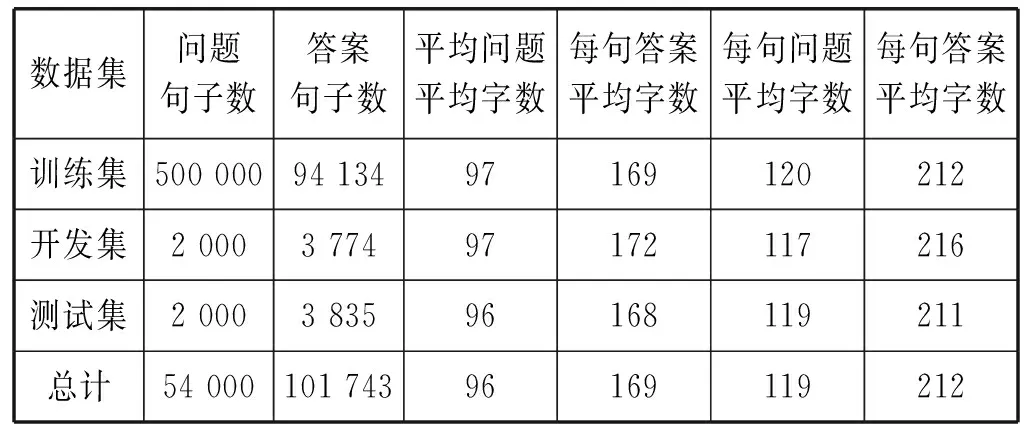
表1 cMedQA数据集
3.2 评价指标
模型性能将采用top-k(ACC@k)作为衡量的指标。其定义如下:
(16)

3.3 基线模型
(1) Random Selection:问题的正确答案将从候选答案集中随机选择生成[15]。
(2) Matching:通过计算问答句之间相似字符的个数,查找正确答案。
(3) BM 25:一种排序功能,应用于问答匹配[17]。
(4) Single-CNN:只使用一个固定卷积核来处理问答语句。
(5) Multi-CNN:在捕获问答对之间的局部不变低级别特征方面是具有很好的效果。
(6) Stack-CNN:与Multi-CNN不同,该模型可以获得句子高级别的语义信息。
(7) Multi-stack-CNN:Multi-CNN模型与stack-CNN模型结合生成,可以获取句子不同级别的信息。
(8) BiGRU:RNN的进化,可以获取句子的全局依赖关系信息。
(9) BiGRU-CNN:结合BiGRU和CNN优点,可以获取序列中长距离依赖关系以及局部位置不变特征信息。
3.4 实验参数
将使用文献[18]的方法把句子中的字符转换为向量表示实现汉字的嵌入,向量的维数为300。问答嵌入层之间共享相同的权重矩阵。Multi-CNN架构使用四种不同大小的卷积核,分别为1、2、3、5。stack-CNN架构使用两种不同大小卷积核,分别为3、4。两个模型特征映射数量均为500个。BiGRU架构在隐藏状态下使用200个特征。BiGRU-CNN架构和ABiGRU-CNN架构使用大小分别为1、2、3和5的卷积核,使用200个BiGRU隐藏状态的特征。
3.5 结果分析
(1) 各模型的ACC@1对比。如表2所示,可以看出混合模型ABiGRU-CNN在测试数据集上精度最高,性能明显优于其他模型表明ABiGRU-CNN在问答匹配中对句子关键信息的提取和匹配是合理有效的。

表2 模型ACC@1结果(%)
J行明显优于A、B和C行的模型,说明在问答对匹配上,神经网络比传统方法更适合于问答对之间的关系建模。
D到G行都是CNN模型的变体,表中可以看出模型Multi-CNN、stack-CNN 和Multi-stack-CNN的结果优于Single-CNN。这是因为Multi-CNN和stack-CNN都使用了不同尺度大小的卷积核对句子进行卷积,能够提取更多的句子信息。G行Multi-CNN的性能最高,它同时继承了Multi-CNN和stack-CNN的优势,提高了模型性能。G行和H行比较,BiGRU比Multi-stack-CNN结果有提高,说明在问答对匹配中BiGRU获取的特征信息和远距离依赖性在构建问答对表示中的重要性。
比较G行和J行、H行和J行,J行效果明显最优,可知BiGRU-CNN结合了BiGRU和CNN两种模式的优点,使其具有更强的功能。
比较I行和J行,可以看出ABiGRU-CNN的性能优于BiGRU-CNN。这说明ABiGRU-CNN不仅具有BiGRU和CNN两种模型的优点,且与注意力机制相结合为问答对重要特征赋予更高权值,使重要特征不被忽视,提高模型的性能。如表3所示,为问句的特征提取。在没有注意力的BiGRU-CNN模型中,斗鸡眼和双眼向内斜视都会被被提取出来,而且由于斗鸡眼出现了两次,再加上近视和散光,这些干扰项对答案匹配会起反作用。而加了注意力的ABiGRU-CNN模型,可以把斗鸡眼统一成双眼向内斜视,排除了斗鸡眼这个干扰项。近视和散光会被注意力机制过滤掉,剩下的特征也会被注意力进行筛选,从而提高比配效率。

表3 典型问句特征提取
(2) 各模型的ACC@3对比。如表4所示,可以看出ABiGRU-CNN模型具有较高的准确率。在实际的医疗问答系统中,有些用户往往不满足一个检索结果,他们希望了解更多的治疗手段,此时可以设置三个候选答案来满足用户的需求。

表4 模型的ACC@3结果(%)
4 结 语
与现有只利用一种模型获取句子的单侧特征和关系的医疗问答不同,BiGRU-CNN混合模型可以获取句子的局部位置不变特征以及全局顺序信息。但是随着网络模型的堆叠过深,模型无法获取对问答对匹配产生重要影响的特征。ABiGRU-CNN模型将BiGRU-CNN与注意力机制结合,通过注意力为重要的特征赋予更高的权重,提高了问答对匹配效率。实验表明,模型在ACC@1和ACC@3中都有较好的表现。但如果问句使用汉语,答案使用英语,模型不一定取到好的效果。为此,本文未来的工作是将外部人类知识融入ABiGRU-CNN模型中,增加模型的泛化能力,使其在跨语言数据集上也取得良好效果。
