基于深度神经网络的冠脉造影图像的血管狭窄自动定位及分类预测
2021-11-14肖朝晖陈文俊
丛 超 肖朝晖 陈文俊 王 毅
1(陆军军医大学大坪医院特色医学中心放射科,重庆 400016)
2(重庆理工大学电气与电子工程学院,重庆 400054)
3(重庆理工大学计算机科学与工程学院,重庆 400054)
引言
冠状动脉疾病(冠心病,coronary artery disease, CAD)已经成为全球发病率和死亡率的主要原因[1]。侵入式冠脉造影成像技术(X-ray coronary angiography, CAG,或invasive coronary angiography,ICA)是目前诊断冠心病的金标准成像技术,其中针对动脉狭窄的诊断和评估是开展进一步诊断和临床规划的重要步骤。
目前,在医疗图像处理及辅助诊断领域,基于机器视觉和人工智能的方法与临床诊断评估方法已越来越紧密地结合在一起,用于解决处理过程中的图像降噪、目标识别、组织分割、疾病预测等问题,成为医疗诊断不可分割的一部分。在侵入式冠脉造影成像中,也有许多研究人员对狭窄检测方法提出基于机器视觉、模式识别的自动或半自动算法,以协助疾病的评估诊断。其中,较为常见的是基于动脉血管检测的算法流程[2],其步骤包括动脉提取、直径计算和狭窄分析等。例如,许多学者将机器视觉中目标轮廓提取/中心线提取的技术应用到血管中心的跟踪上[3-5],更为流行的方法是基于图像分割的技术[6-8]和基于卷积神经网络(convolutional neural network, CNN)的分割[9-15]等。这样,通过精确提取CAG图像中的冠状动脉,以此为基准,实现对冠心病的疾病预测与定性/定量分析。
现有技术中的一些算法在实际临床应用上有一定局限。首先,血管分割或轮廓提取降低了算法的鲁棒性,使许多方法只能在小规模的数据集上进行评估;其次,这些方法很难做到端到端(end-to-end),都包括一定比例的预处理步骤,如选择对比帧和绘制动脉轮廓。此外,血管轮廓的标注工作是评估标准和监督学习样本的不可或缺的一部分,其中大量的手动工作给操作人员带来沉重的负担。
近年来,基于端到端的深度学习技术(deep learning)逐渐成为医疗图像处理领域的重要研究方向。例如,通过CNN分类/预测模型,可以实现针对癌症疾病的病理图像分类、肿瘤目标检测[16-17]和眼底病变的分类[18]等。然而,在心脏图像处理领域,深度学习技术还是主要集中于CT/MRI图像的左心室分割、血管分割和基于分割的CT血管的狭窄识别。针对CAG图像的处理,深度学习技术还没有得到广泛的应用。
因此,针对CAG图像中动脉狭窄的诊断,提出了一个端到端的深度学习模型架构。该算法架构主要利用冠脉造影定量分析(QCA),而无须依赖血管分割掩模或轮廓提取结果进行监督学习,从而实现了图像级/动脉级/患者级的狭窄分类预测与图像中的狭窄定位检测。同时,在图像数据准备的过程中,利用inception模型,结合长短记忆模型(LSTM),识别不同冠脉类别和造影时间序列图像中的造影帧,实现了算法流程的全自动化。
1 方法
1.1 数据来源和评估方式
针对235例患者展开研究,数据均来自CORE320——多种族、多中心、国际性的冠状动脉疾病的诊断数据库[19]。该数据集使用了侵入性冠状动脉造影图像,将造影血管的病变严重程度的冠脉造影定量分析(QCA)作为其评价标准[20]。
所有用例都保存为通用DICOM格式,每个都包括8~20个DICOM视频文件,分辨率为512像素×512像素或1 024像素×1 024像素,每个DICOM包含60~200帧, 15帧/s。使用DICOM标签识别主视图(LAO/RAO)和次视图(CRA/CAU),并按照临床诊断经验选取4个LCA的典型视角(LAO CRA、LAO CAU、RAO CRA和RAO CAU)和3个RCA典型视角(LAO、RAO和浅CRA)进行狭窄识别实验。
数据集删除了5个缺乏足够数据的用例(LCA或RCA中DICOM视频数量少于1),并排除了36个由于图像质量低或对比度差而无法进行训练的用例(但仍包括在狭窄分类评估中)。剩下的194例中,共计1 844个视频被归类为上述的7个典型视图。随后,通过视觉检查,进一步排除了74个对比度差或狭窄特征不明显的视频。最后,共计194例的10 872张图像(CAG中的完全造影帧)被用作图像级狭窄分类训练和评估,所有的230例的13 744张图像被用作多视角结合的动脉级和患者级狭窄预测评估;针对分类呈阳性(>25%)的用例中,又选取了690张图像和1 588个人工标注的狭窄定位框用作血管狭窄定位训练和定位评估。在评估的过程中,参与训练的图像都采用4倍交叉验证(4-fold cross validation)的方式参与评估。
1.2 训练与评估标签准备
狭窄分类的训练标签主要由QCA中的狭窄分数确定。根据狭窄程度,QCA结果被分为3个临床相关组:0类为<25%狭窄组,1类为25%~95%狭窄组,2类为>95%狭窄组。图像分类训练主要基于以上定义进行三分类或二分类(<25%和>25%)训练,这里命名为2-CAT/3-CAT。其中,动脉级/患者级的狭窄标签可以直接由QCA生成,而图像级别的标签可通过QCA中的每段狭窄严重程度[20]和29段模型[21]位置确定。为了最大程度地让算法流程自动化,采用最优视图映射(optimal view mapping, OVM)方法[22],将每个节段的狭窄类别映射到7个典型视角视频/图像中。
血管狭窄定位的训练标签被定义为图像中的一组坐标或矩形框,被标定了图像中的血管狭窄或疑似狭窄病灶所出现的位置和大小,由两位独立的专家从690 张CAG图像中直观绘制。该方法规定:在分辨率为512像素×512像素的CAG图像中,狭窄病灶区域的最小尺寸为35像素×35像素。
1.3 训练模型及训练策略
Inception-v3模型[23]作为基本的图像分类器与特征提取器,应用于造影帧分类、血管狭窄分类及特征提取。模型的输入尺寸均为512像素×512像素×3通道,并对输入图像进行随机小幅度(变化在10%以内)对比度偏移、图像旋转平移、仿射变换等数据增强技术,以提高算法鲁棒性。
1.3.1造影帧预检测
首先,采样1 000张完全造影帧和非造影帧图像。其中,完全造影帧定义为“候选帧”,非造影帧定义为“冗余帧”。将这些图像输入,并预训练一个inception模型,让其分类识别候选/冗余帧。然后,将训练完成模型的全连接(FC)层的输出特征矢量连接到一个双向LSTM结构的输入端。另外,采样了146个CAG视频,每个视频通过最近邻法进行插值或采样选取64帧,并定义其完全造影阶段的起始帧和结束帧作为标签,再将这些视频图像输入双向LSTM结构进行训练。最后,对LSTM的输出结果进行采样来避免相似的帧,这就是候选帧的选取。
针对inception的候选/冗余预训练,将损失函数定义为二元熵,初始学习率(LR)为1×10-4,预训练100个周期(epochs)。对于LSTM训练,将损失函数定义为卷积F1分数[24],LR=4×10-5,共训练200个周期。
1.3.2狭窄分类训练
对于图像级狭窄分类训练,将inception分类网络的最后一个全连接层和激活层用2/3-CAT设置替换。为了让训练能够更快收敛并提高分类性能[25-26],使用ImageNet数据集将inception预训练得到网络权重作为血管狭窄训练的初始值。随后,使用4倍交叉验证的方式,将194例患者的10 872张图像分为3倍训练集和1倍验证集,使用训练集对预训练好的inception模型进行狭窄分类训练。
为了提高训练效果,减少过拟合,设计了一种新的训练策略——冗余训练。该策略将预先分类的冗余帧添加到训练数据集中(不在测试或验证中),冗余帧被标记为一个新的类别(R类)。在2/3-CAT(名为2R/3R-CAT)上,执行了此训练策略。为了避免引入类别不平衡,对每种情况下的冗余帧和候选帧进行了大致相同的采样。
每个模型(4个LCA角度视图训练集和1个RCA训练集,在2/3/2R/3R-CAT设置中)都接受了200个阶段的LR=1×10-4训练。采用Adam优化器和交叉熵损失函数,并采用类别重采样策略,以防止类别不平衡。
此外,在LCA/RCA的4或3角度视图中,对1类(狭窄)的输出分数应用max-pooling层来评估动脉级狭窄预测,并使用类似的方法评估患者级狭窄预测。对于动脉/患者水平,仅使用2R-CAT训练模型评估<25%/>25%的预测。
图像级、动脉级和患者级狭窄分类的详细网络结构如图1所示。
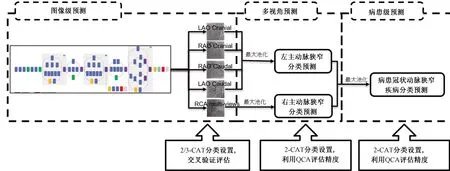
图1 基于Inception的多级别狭窄分类网络架构Fig.1 Multi-level stenosis classification network architecture based on inception model
1.4 狭窄检测与定位方法
训练后,使用类激活图(class activation map, CAM[27])来识别每个训练模型中的区分区域,这些区分区域对其分类决策具有不同的权重。CAM提供了对CNN行为的深入检查,并且可以用于特征模式定位,而无需在图像分类的情况下使用额外的标签或信息。
CAM(用变量Ms指代)的计算可以描述为第l层中k个特征图Alk(i,j)的线性加权总和,再根据全局平均池化(global average pooling, GAP)层映射到对应的行列坐标(i和j)。CAM的详细实现和公式如下:
(1)
神经元权重wsk是从指定的输出类别s反向传播(back propagation)通过对梯度的平均池化获得的,有
(2)
式中,Z是归一化操作。
在式(2)中,将ReLU运算应用于线性组合,以从特征图Alk中排除负激活值。实验将CAM的位置放在倒数第2个卷积层(inception-v3的第310层,l=310),同时在反向传递时取输出类别为狭窄类别(在2/2R-CAT,s=1),这样所获得的识别血管狭窄定位的能力最佳。在获取CAM之后,将其上采样至原图大小(512像素×512像素),然后对其进行阈值处理,以通过输入CAG图像创建狭窄区域s和峰值狭窄定位信息。 用式(1)和(2),可以计算出狭窄区域的激活范围及其坐标,其计算流程如图2所示。

图2 基于类激活图的狭窄定位方法Fig.2 CAM-based stenosis positioning method
基于CAM,通过阈值检测从背景中检测到高激活区域,并生成了其边界框。 CAM的计算提供了一种粗略的狭窄定位能力,作为一种无监督的方法,而无需为狭窄的位置提供大量的人工输入。
1.5 血管狭窄检测评估分析
在本研究中,辅助诊断分类算法性能的评估主要基于患者进行4倍交叉验证,包括各患者的图像级、血管级、患者级的严重性分类。在CORE320数据集中,0、1、2类的分布分别为39.5%、49.9%、10.6%。为了避免类别不平衡问题,利用加权准确度Accuracy、加权Cohen's Kappa和F-score值进行评估,并绘制了ROC曲线以及曲线下面积AUC。
针对血管狭窄的检测评估,主要是通过计算整体敏感度(Sens)、每狭窄敏感度(Senss)、每狭窄特异度(Specs)和均方误差(MSE)来完成。Sens定义为图像中最显著狭窄的检测召回率,与COCO基准[28]中的AR^(max=1)相似;Senss和Specs被定义为图像中所有狭窄检测的召回率。
所有统计评估均在Python中进行(版本3.6, Python软件基金会,https://www.python.org),敏感性、特异性、准确性、T1得分和AUC使用Scikit-learn版本0.19.1计算。对具有随机性的实验结果开展统计分析,其中基于正态分布的连续变量,报告为均值±标准差。
2 结果
2.1 狭窄分类实验
狭窄分类评估基于230例的13 744张图像,其中严重性分布为:狭窄<25%者87例(37.8%),狭窄25%~99%者119例(51.7%),狭窄100%者24例(10.4%)。为了检验所提出的冗余训练策略的性能,分别采用了原生训练法和冗余训练法,并比较了它们之间的评价指标。
基于图像级的定量评价结果如表1所示,冗余训练对2-CAT和3-CAT类别的分类准确度(Acc)、F1分数和Kappa分数都有显著的改善。同时,比较了本方法和文献[3-4,12,29]方法针对狭窄分类的性能。结果表明,提出的方法在分类性能上优于传统方法。一些基于血管的方法[3-4]的准确度分别为0.86、0.94,但它们并不是完全自动化的狭窄评估,也不能提供患者级别的狭窄分类结果。

表1 3-CAT、2-CAT分类诊断性能评估(μ±σ),计算准确度(Acc)、Cohen′s Kappa(κ)和F1评分(F1)Tab.1 Performance (μ±σ) in 3/2-CAT setups, metrics were calculated by accuracy (Acc), Cohen’s Kappa (κ) and F1-score (F1)
在基于动脉级别和患者级别的评估中,LCA、RCA和per-patient的灵敏度分别为0.94、0.90和0.96,对LCA、RCA和per-patient的AUCs为0.87、0.88和0.86。基于图像、动脉、患者分类的ROC曲线如图3所示。

图3 基于4-fold交叉验证的ROC特性曲线。(a)LCA分类;(b)RCA分类;(c)患者级分类Fig.3 The receiver operating characteristic curve derived from validation. (a)RCA; (b)LCA;(c)patient-level
2.2 狭窄检测评估
狭窄区域的定位实验主要基于训练好的2-CAT/2R-CAT分类模型。图4中的热图显示了模型在图像中定位可疑狭窄特征的能力,如血管边界变窄和主动脉直径异常。其中,(b)的图形是由原生训练模型生成的CAM,(c)是由冗余训练模型生成的。与原生训练模型相比,冗余训练模型在冠状动脉上的关注区域更集中于造影血管的形态上,同时也更不容易受到背景噪声的干扰。
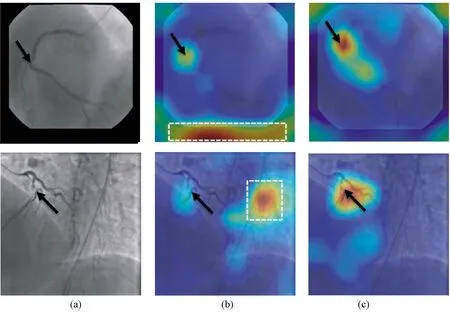
图4 类激活图(CAM)热图的注意力机制(上为RCA示例,下为LCA示例;黑色箭头标注疑似狭窄区域)。(a)输入的原始图像,用黑色箭头标注疑似狭窄区域;(b)原生训练2-CAT模型生成的CAM注意力热图与原始图像的叠加,用白色矩形标注过拟合区域;(c)冗余训练2R-CAT模型生成的CAM热图与原始图像叠加Fig.4 Examples of class activation maps (CAM) generated from RCA (the top) and LCA (the bottom), the arrows indicate suspected stenosis. (a)Frames with suspected stenosis annotated with black arrows; (b)CAM with overfitting regions annotated by white dash rectangle; (c)CAM with redundancy training
图5提供了狭窄检测算法的一些结果,包含LCA和RCA各个视角的各3例图像。可以看出,算法可以很好地检测血管造影各个视角图像中出现的血管狭窄特征,尤其是当狭窄特征出现在冠状动脉血管的近端时,检测效果更加突出。

图5 狭窄检测算法结果。(a)原始图像,从左到右依次为3个不同视角的RCA图像和LCA图像,用白色箭头标注疑似血管狭窄区域;(b)基于CAM狭窄检测的算法结果,用黄框表示狭窄检测的ROI最大外接矩形框Fig.5 Results of stenosis detection algorithm. (a) Orignal image, the suspected vascular stenosis area is marked with white arrows; (b) The algorithm results in this paper include the thermal map generated by CAM and the detection frame after binary processing
针对血管狭窄的检测评估的定量结果如表2所示。基于CAM的方法在没有任何定位标签的情况下,可达到70%的全局灵敏度。并且,在512像素×512像素的图像上,定位的均方误差(MSE)小于40 像素。图5提供了狭窄检测算法的结果,包含LCA和RCA各个视角的各3例图像。从检测效果可以看出,算法可以很好地检测血管造影各个视角图像中出现的血管狭窄特征,尤其是当狭窄特征出现在冠状动脉血管的近端时,检测效果更加突出。
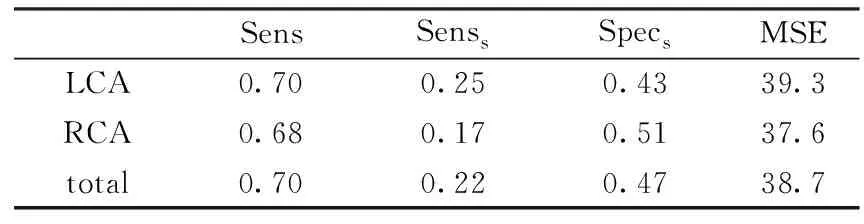
表2 左冠状动脉(LCA)、右冠状动脉(RCA)狭窄的定位性能评估Tab.2 Performance of stenosis positioning on left coronary artery (LCA), right coronary artery (RCA)
此外,进一步在完整的CAG时间序列图像(视频)中应用并可视化了2R-CAT模型的检测结果,如图6所示。在心脏和相机运动的影响下,算法仍然成功地跟踪了狭窄特征在不同时间序列图像上的位置。对于视频中的早期或后期中血管造影剂不足的图像,模型将其排除在狭窄检测之外。对于部分血管造影并具有狭窄特征的中间帧,该模型能够正确定位狭窄发生的位置。
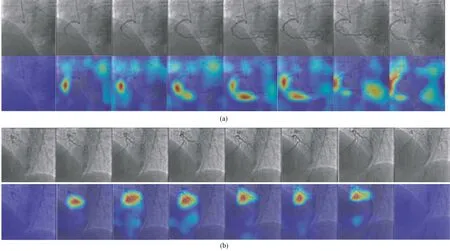
图6 视频中的CAM可视化(每行从左到右依次为同一个CAG视频的第3、6、9、12、15、18、21、24帧,每个子图上为视频中的图像、下为CAM热图)。(a) RCA,在其中段和远端发现两个明显的狭窄; (b)LCA,在其近端发现一个明显的狭窄Fig.6 Examples of CAMs visualization in a video(From left to right in each line are the 3rd, 6th, 9th, 12th, 15th, 18th, 21st and 24th frames of the same CAG video; In each sub-picture, the upper are images from video, the bottom are their CAM). (a)Two significant stenoses were identified by the physician in the mid-RCA and the distal segment of RCA; (b)A significant stenosis was found at the proximal end of the LCA
3 讨论
研究的主要发现归纳如下:一是提出了一种全自动、端到端(end-to-end)的CAG图像的血管狭窄分类工作流程,在无需血管轮廓提取和分割的前提下,达到了较高的分类灵敏度(0.96)和AUC(0.86);二是提出的冗余训练策略进一步提高了分类的AUC值、准确性、F1得分和kappa评分;三是采用了基于CAM的弱监督目标识别定位方法,用于预测血管狭窄的位置。实验证明,分类模型和定位算法已经实现了从图像到患者的辅助诊断预测潜力,具有较高的精确度,不仅提供了冠脉造影过程中的初步筛选方法,而且为更精确和自动化的计算机辅助CAD诊断奠定了基础。
端到端的工作流程有利于减少人机交互步骤[30]。所提出的工作流程可以直接应用于CAG视频,算法会自动选择最佳帧来进行狭窄分类并定位狭窄位置,同时在动脉和患者水平上提供结果。该工作流程在海量图像数据的临床环境中具有优势,因为及时筛选所有CAG视频来消除正常或轻度狭窄的病例,可以提高生产率,并有可能挽救生命[1]。
在以往的一些研究[3-4,12]中,血管分割是一个初步的、必不可少的步骤,它导致了整个系统的不稳定和过多的人工操作。一个重要的原因是冠脉造影图像中包含了太多的信息,包括多角度视图、背景框架和血管狭窄的视觉特征。如前所述,这些因素很难处理,并且在监督学习过程中会导致严重的过度拟合和采样不平衡。在这样的情况下,冗余训练策略的提出,提高了分类的精确度,并减少了分类训练中的过度拟合;然后,可视化和比较实验表明,该方法减少了背景结构引起的训练过拟合,提高了分类性能。
与先前的方法[3-4,12,29]进行比较研究,也显示了本算法的优越性:仅使用来自QCA的训练标签和有限的用户交互,就能达到与半自动、重标签的训练方法近似或更优越的性能。另外,通过提供狭窄的分类和定位,医生或放射科医师可以验证所提出的CNN框架的性能,并更快地进行定量冠状动脉造影。
提出的研究有如下几个局限性:
1)狭窄分类的评估是在相同的研究和模式下进行的,其分类金标准和训练标签主要来源于单一的诊断参考源(QCA)。后续将会使用外部同类研究(例如CTA[14])进行比较,从多个角度评估技术的性能。
2)狭窄分类方法具有一定的局限性。实验将狭窄分类定义为3组:<25%狭窄,25%~99%狭窄和完全闭塞(3-CAT),而<25%狭窄和25%~100%狭窄(2-CAT)。这是因为现阶段的目的是将正常和轻度狭窄病例从队列中排除。后续可以将轻度~中度狭窄的更精确分类用于不同的临床目的,如血液动力学显著的狭窄检测。
3)需要改进的方面是狭窄定位实验,由于定位标签选取上的工作量较大,在定位评估中只针对CAG视频中的单个静态帧,而没有对所有时间序列图像中的狭窄特征/位置跟踪进行量化评估。
4 结论
本研究提出了一种全自动的端到端深度学习方法,用于冠脉造影图像中动脉狭窄的分类和检测。该方法利用深度学习模型与监督学习技术,仅使用来自QCA的轻度训练标签,在有限的用户交互下完成监督学习并达到较精确的分类和预测的任务。随后,在一个多中心、多种族的数据集上,对提出的方法进行了全面的验证,并与几种最新的方法进行了比较,展示了方法的潜力、前景和先进性。
未来的工作将着眼于进一步完善算法,以满足针对时间序列的处理,并利用其他临床信息进行训练及评估。同时,考虑把算法应用到其他成像方式(如计算机断层血管造影)的狭窄检测中。
