基于改进U-Net网络的内窥镜图像烟雾净化算法
2021-11-14林金朝蒋媚秋王慧倩
林金朝 蒋媚秋 庞 宇 王慧倩
(重庆邮电大学光电工程学院,重庆 400065)
引言
目前我国多数医院都配备了内窥镜[1],辅助医生进行腹腔、胸腔、耳鼻喉等部位的微创手术,并发展出多种衍生功能[2-3],其优势是医生不再需要用手术刀将腹腔、胸腔切开,仅在手术目标区域开3个小孔就可以进行手术(一个小孔放置医学影像装置,一个小孔放置超声波手术刀,一个小孔放置吸收手术废弃物装置)。根据人体的自恢复能力,小孔无需缝合,就可自行愈合,不仅缩短了康复的时间,而且减少了病人的创伤和痛苦。以腹腔镜为例,在手术过程中,医生通过超声探头和腹腔镜头来观察患者腹腔状况,由于这些器械通过小切口插入患者腹部,因此腹腔镜获取的视频或图像是手术期间的主要数据来源。在手术过程中,图像质量会因噪声而降低。噪声主要由血液、光照变化、镜面反射、烟雾等造成,其中由激光或电烙烧蚀人体组织引起的烟雾会显著降低遮挡区域图像的质量,影响医生判断,加长手术时间,增加手术风险。因此,用物理方法排除烟雾(如腹腔镜烟雾过滤系统)和图像处理算法来净化烟雾是非常必要的。
烟雾净化在许多领域中都有相关的应用,如交通烟雾净化、手术场景烟雾净化、烟雾警报、电子摄影设备拍摄图像的烟雾净化等。在现有的烟雾净化算法中,自然场景图像烟雾净化的研究较多,内窥镜烟雾净化作为近年来的热门研究领域,主要由基于传统方法、基于深度学习两大类方法构成。
基于传统方法主要有3个类别。第1类是暗道检测(DCP)及其优化与变形,此类方法的研究基础为采用暗色通道除烟。He等[3]提出了暗通道去雾方法(DCP),但是直接应用原始DCP时产生了颜色失真,这是由于去噪的基本假设不适合烟雾净化。为了克服颜色失真,Tchaka等[4]提出将经验选择的常数阈值化来优化暗通道值,或者对接近0.5的值进行更高的响应,然后通过直方图均衡化处理,增强去雾图像的对比度;为了定量地评价图像的性能,在序列开始处选取一个无烟帧作为背景真值,接着计算所选背景真值图像与后续帧之间的均方误差(MSE),与原来的DCP方法相比,该方法获得了更好的视觉质量。第2类为使用贝叶斯推理[5]及其优化方法[6]。Kotwal等[7]将去噪和去烟问题归结为一个贝叶斯推理问题,用马尔可夫随机场(MRF)对未包含烟雾的图像进行建模,并用最大后验概率(MAP)来获得增强版本。第3类为利用能见度驱动的融合及其优化方法。Luo等[8]受文献[9]的启发,收集了机器人辅助腹腔镜前列腺癌根治术中的内窥镜图像,在重新推导大气散射方程的基础上,提出了一种基于泊松融合的烟雾净化方法;该方法可以减少计算量,其评价指标是通过主观和客观两个方面来进行的,并与先前提出的除雾方法进行比较,结果显示还原度指标和锐度指标较好。物理方法能实现烟雾净化的目标,但对于手术场景来说,单场图像的处理时间较长,而基于神经网络的方法能够较好地提升网络的时间性能。
基于深度学习的方法主要分为2个类别。第1个类别仍然基于大气扩散模型,使用卷积神经网络对大气扩散模型公式中的透射率图像t和全局大气背景光A进行求解。例如,Cai等[10]在自然场景中使用改进的大气扩散模型,并修改公式使之能够通过CNN求解;Yang等[11]在此基础上改进,建立了能量模型,并针对暗通道和传输先验设计了一个迭代优化算法,利用卷积神经网络学习最近点算子,将迭代算法展开为一个深网络,称之为近端dehaze网络,在单图像去噪方面获得了最先进的性能;Salazarcolores等[12]将内窥镜图像结合暗道检测,通过对抗神经网络,分别求得透射率图像和大气背景光,接着进行烟雾净化。第2个类别采用端对端网络,利用模型直接进行烟雾净化。Chen等[13]借鉴monodepth[14]结构中的U-Net结构,采取简单的损失函数,最终图像色彩有一定失真;Wang等[15]采用编码解码器,在编码阶段加金字塔分解作为输入,采用端对端网络进行求解;Bolkar等[16]在自然图像去雾AOD-Net模型的基础上,采用迁移学习实现内窥镜图像去雾。还有各种以对抗神经网络GAN为基础的烟雾净化方法[17-19]。例如,Salazar等[20]将暗道检测结果与原图组合成四维图像并作为网络输入,采用GAN训练,效果优于GAN和暗道检测两种方法各自净化烟雾的结果。
医学图像边界模糊、梯度复杂,需要高分辨率信息表示;同时人体内部结构相对固定,同一组织器官的烟雾净化前景和背景之间有一定规律可循,需要低分辨率信息表示。因此,选择能够同时结合高、低分辨率信息的U-Net作为基础框架,通过编码器网络,经过多次下采样后得到低分辨率信息,再经过聚合(concatenate)操作,就能够直接从编码器将高分辨率信息传递到同高度解码器上,故U-Net[21]广泛应用于医学图像处理;以monodepth中使用的U-Net结构为主要框架,monodepth可实现双目视觉无监督深度估计,所提出的U-Net网络以经典的VGG模型为基础,结构简洁、功能完整,被许多内窥镜图像处理的文章广泛引用[22]。
对于烟雾净化算法,手术场景要求烟雾净化后的图像保留更多的细节特征。在U-Net网络的上采样和下采样的过程中,难免会使图像损失细节,图像拉普拉斯金字塔分解[23]的目的是将源图像分别映射到不同的空间频带上,融合过程是在各空间频率层上分别进行,这样就可以针对不同分解层的特征与细节,采用不同的融合算子,从而保留特定频带上的特征与细节。对于输入图像,拉普拉斯变换与U-Net网络的编码部分可以采用同样的下采样比例,使经过拉普拉斯变换的图像能够插入U-Net网络一起进行训练,经过拉普拉斯变换的图像要比U-Net结构使网络能够保留更多的细节特征。
采用监督学习完成烟雾净化,需要关注雾气所在的部分并进行处理。在计算机视觉中,注意力机制的基本思想是让系统学会忽略无关信息而关注重点,注意力机制通常由一个插在原神经网络外的模块实现,整个模型仍然是端对端的。注意力模块能够和原模型一起同步训练,并且能够帮助模型选择更好的中间特征,选择轻量级的CBAM注意力模块[24];能够结合空间信息和通道信息,在更少占用空间和内存的基础上添加注意力功能。
1 方法
1.1 实验流程
通过改进U-Net网络来实现内窥镜烟雾净化,具体步骤如图1所示。由于内窥镜领域开源数据集少,首先,根据Blender模拟手术过程中烟雾出现的各种情况,随机对腹腔镜图像加入烟雾;其次,对于网络设计,在U-Net网络基础上改进,在下采样部分加入拉普拉斯图像金字塔分解作为编码器,在上采样部分加入CBAM注意力机制作为解码器;然后,将包含烟雾的合成图像作为训练集,将原始图像作为训练集标签,送入改进的U-Net网络中进行训练,通过反向传播,使得网络各层获得相应参数;最后,将测试集送入到模型中,预测得到净化图像。
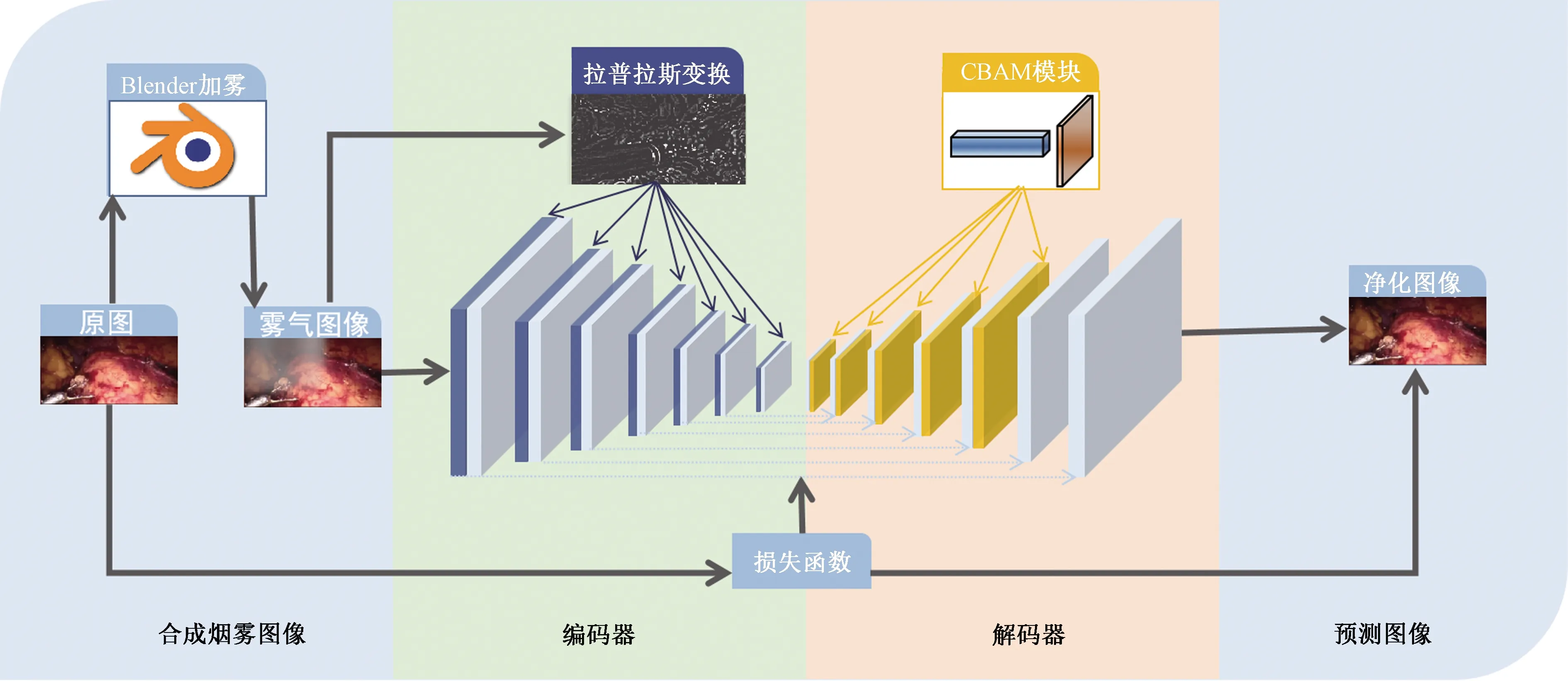
图1 整体流程Fig.1 Overall flow chart
1.1.1编码器
编码器可以通过卷积层提取内窥镜图像的特征,在U-Net网络编码部分的每一层插入对应尺寸的拉普拉斯变换图像得到改进的编码器,如图1左边下采样部分所示。编码部分包含7个卷积组,由卷积conv1~7组成,每一组包含两个步幅分别为1和2的卷积层,7个卷积组对应的卷积核大小分别为7×7、5×5、3×3、3×3、3×3、3×3、3×3,输出层数分别为32、64、128、256、512、512、512,因此总的下采样因子为64。
图像在下采样过程中会丢失部分高频细节,为了更好地保留图像细节,Wang等[15]在上采样部分引入拉普拉斯金字塔,采取最近邻插值方法进行上采样,计算量很小,运算速度较快,但仅使用离待测采样点最近的像素灰度值作为该采样点的灰度值,没考虑其他相邻像素点的影响,因而重新采样后灰度值有明显的不连续性,图像质量损失较大,可能产生马赛克和锯齿现象。笔者在该方法的基础上进行改进,采取双线性插值,考虑待测采样点周围4个直接邻点的相关性影响,缩放后图像质量高,基本克服了最近邻插值灰度值不连续的问题。
在编码器中的每一个卷积层之前,添加经过拉普拉斯变换后的烟雾图像 (Laplacian pyramid),定义为
Li(I)=Gi(I)-up(down(Gi(I)))
(1)
式中:I表示包含烟雾的原始图像,i表示金字塔的等级;Gi(I)表示对图像做高斯下采样,即图2中上方彩色内窥镜图片会随着高斯下采样次数增多而减小尺寸,但仍保留图像的主要信息;L(i)为高斯采样的图像减去经过上采样的下一级高斯采样图像的差值,L(1),…,L(7)构成拉普拉斯金字塔。
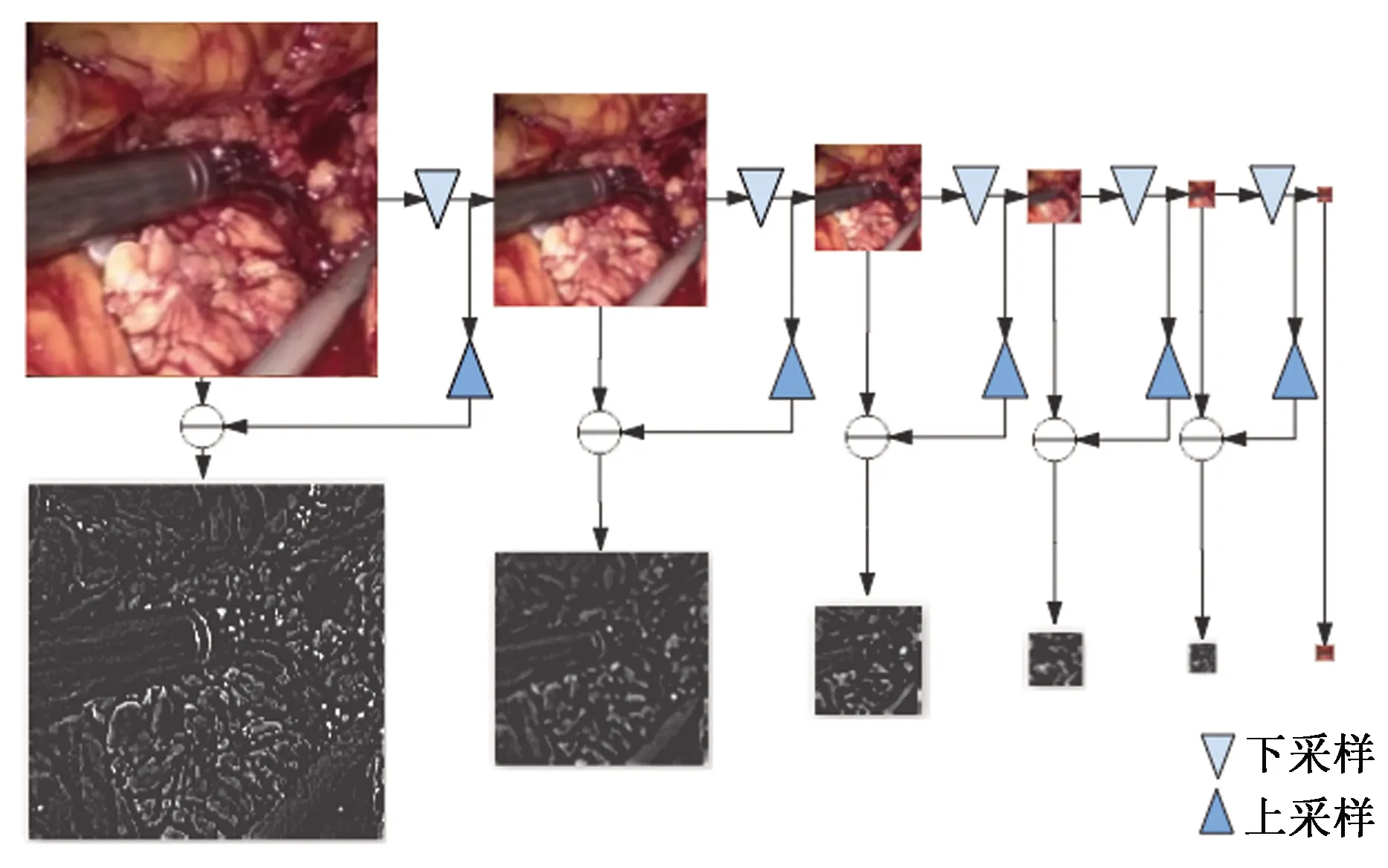
图2 拉普拉斯图像金字塔分解Fig.2 Laplace image pyramid decomposition
如图3中的拉普拉斯叠加层和拼接操作所示,将L(1),…,L(7)拼接到对应尺寸的卷积层参与训练。

图3 编码器解码器网络Fig.3 Encoder decoder network
1.1.2解码器
解码器将经过下采样的图像恢复至原有尺寸,在U-Net网络解码部分的前5层插入CBAM注意力模块,如3上采样部分所示,解码器也采用7组卷积,每一组包含步幅分别为1和2的两个上采样层,卷积核尺寸全为3×3,输出层数分别为512、512、256、128、64、32、16。编码器和解码器之间有对应连接,低层的特征与高层的特征相连接,将高层信息直接传输到网络底层,防止高质量细节的丢失。
采用CBAM注意力模块,由于CBAM量级较轻,因此该模块的开销较小,可以将其集成到CNN网络中进行训练,使模型能够更好地表示中间特征。将CBAM加入到解码器的第1~5组,对于任意层的中间特征图,CBAM模块会沿着两个独立的维度(通道和空间)依次得出注意力图,然后将注意力图与输入特征图相乘进行自适应特征优化。其具体过程如下:对于任意中间层的特征矩阵F∈RCHW,CBAM将会顺序推理出一维的通道特征图Mc∈RC11(见图4的蓝色部分),以及二维的空间特征图Mc∈R1HW(如图4的橙色部分),其过程推导如下:

图4 CBAM注意力模块Fig.4 CBAM attention module
F′=Mc(F)⊗F
(2)
F″=Ms(F′)⊗F′
(3)
特征图的每个通道都被视为一个特征检测器,通道注意力主要关注输入图片的内容。为了高效地计算通道注意力,使用最大池化和平均池化,对特征图在空间维度上进行压缩,得到两个不同的空间背景描述Fmax,c和Favg,c。使用由MLP组成的共享网络对这两个不同的空间背景描述进行计算,得到通道特征图Mc∈RC11。计算过程如下:
(4)
Mc(F)=σ(W1(W0(Favg,c))+W1(W0(Fmax,c)))
(5)
式中,W0∈RC/rC,W1∈RCC/r,在W0后使用Relu作为激活函数。
与通道注意力不同,空间注意力主要关注位置信息,在通道的维度上使用最大池化和平均池化,得到两个不同的特征描述Fmax,s∈R1HW和Favg,s∈R1HW,然后使用聚合操作将两个特征描述合并,并使用卷积操作生成空间特征图Ms(F)∈RHW,计算过程如下:
Ms=σ(f77([AvgPool(F);MaxPool(F)]))
(6)
Ms(F)=σ(f77([Favg,s;Fmax,s]))
(7)
改进U-Net网络的损失函数为原始图像和合成烟雾图像的最小绝对值偏差损失L,有
(8)
1.2 实验设计
1.2.1实验数据集
采用腹腔镜图像作为内窥镜图像,采取由汉姆林中心腹腔镜/内窥镜视频数据集(http://hamlyn.doc.ic.ac.uk/vision/)提供的真实腹腔镜图像,数据集总共包含32 400对双目内窥镜图像,图片的尺寸为384×192。
为训练神经网络提供数据集是一项非常昂贵且耗时的工作,尤其是在医学数据集资源稀缺且准确性和数量难以满足医疗实践标准的情况下。由于需要图像(有或无烟雾)和烟雾密度模拟,烟雾探测和清除任务更加困难。为了解决这个问题,使用三维图形渲染引擎Blender(https://www.blender.org/),将烟雾渲染到腹腔镜图像上来生成烟雾图像。使用渲染引擎比基于物理的烟雾更加准确,因为在腹腔镜场景中手术烟雾通常是局部产生的,并且与深度无关,所以没有必要使用传统的雾度模型来渲染手术烟雾,而且现代图形渲染引擎由于拥有良好的内置模型,因此可以生成更真实的烟雾形状和密度变化。
烟雾由渲染引擎渲染,并且具有局部颜色和透明度,位置由输入参数随机强度Trand、密度Drand和位置position控制,有
Ismoke(x,y)=Blender(Trand,Drand,Prand)
(9)
随机产生的烟雾图像Is-image由烟雾和腹腔镜图像Is-free叠加合成包含烟雾的图像Ismoke,可表示为
Is-image(x,y)=Is-free(x,y)+Ismoke(x,y)
(10)
烟雾遮罩Ismoke是根据渲染烟雾的R、G、B通道的亮度而得到的,有
(11)
将选定的训练集和测试集经过一次渲染得到轻雾数据集,将轻雾训练集再渲染一次得到浓雾数据集,将两种雾气浓度的图像分别进行训练。
1.2.2实验条件
实验条件为64位Windows 7操作系统、Intel(R) Core(TM) i5-4590 CPU、16.0 GB RAM,使用单个NVIDIA 12 GB 1080Ti GPU,安装CUDA9.0(由NVIDIA推出的通用并行计算架构),并使用cuDNN7.0(用于深度神经网络的GPU加速库)进行加速,在此基础上使用Tensorflow1.10.0框架,实现U-Net模型的搭建。
1.2.3实验设置
在左目图像中手动选择15 000张不含有雾气的图片作为训练集,数据集划分如图5所示。训练集共分为5组,每次将4份图像作为训练集,1份作为验证集。在分别训练和验证之后,使用测试集进行测试,并将上述过程重复5次,最后把平均5次的结果作为误差评估的结果。将1 000张图片作为测试集,选择原有数据集中包含真实烟雾的129张图像,验证模型的有效性。每张图像进行加雾渲染后作为训练集,渲染图像分为轻雾和浓雾两个等级。在训练过程中,首先将所有图像调整为256像素×128像素的固定尺寸,然后将其输入到模型中,采用均方误差损失函数,使用Adam作为优化,batch设置为16,初始学习率设置为0.0001。实验采取控制变量法,针对两种等级的雾气分别进行4组实验:仅包含U-Net网络、U-Net网络加上CBAM注意力机制、U-Net网络加上拉普拉斯变换、U-Net网络加上CBAM注意力机制和拉普拉斯变换。

图5 交叉验证数据集划分Fig.5 Cross validation data set partition
2 结果
各组平均训练时间为4.5 h,根据不同等级烟雾和不同模型进行组合。对于轻雾图像训练集,平均损失降低至0.02~0.03后不再降低,并且没有发生过拟合,在验证集上平均损失降至0.3左右后不再降低;对于浓雾图像训练集,平均损失降低至0.03~0.04后不再降低,并且没有发生过拟合,在验证集上平均损失降至0.4左右后不再降低。
2.1 模型性能分析
在U-Net编码部分的每层网络加入经过拉普拉斯金字塔变换的训练图像,在解码部分加入CBMA注意力机制。为验证模型的有效性,在控制数据集图片一致、轻雾、实验其余参数设置一样的情况下做4组对比实验,实验结果在5次的基础上取平均值,其结果如表1所示。在同时引入拉普拉斯金字塔变换和CBAM注意力机制的情况下模型的训练损失为0.026,单独添加CBAM模块的训练损失为0.023,单独添加拉普拉斯变换的训练损失为0.038,说明CBAM模块能够较好地优化模型。在处理时间上,CBAM模块取得的好效果为106.4 pfs,同时PSNR取得的最佳值为31.435。在SSIM指标上,加入拉普拉斯金字塔实验获得的最优效果为0.98。从实验结果可以看出,加入CBAM注意力机制模块能有效提升该模型的各项指标,而拉普拉斯金字塔变换可以更好地保留图像细节。实验在真实图像上的测试结果如图6所示:从(a)与(c)中可以看出,手术中的真实烟雾遮挡医生视线,模糊手术场景中的真实视野;从(b)与(d)中可以看出,经过净化后,由该模型处理的图像能够净化图中的烟雾,使得模糊图像更加清晰。合成数据集的测试结果如图7所示:(a)为合成烟雾图像,其特点是烟雾较浓、遮挡组织原本的结构;(b)为使用原始U-Net的结果,经过净化的图像仍然残留部分烟雾,效果不够理想;(c)为加入拉普拉斯变化,烟雾能够完全被净化,但原图色彩艳丽部分的亮度与饱和度降低;从(d)和(e)中可以看出,在加入拉普拉斯变换后,既能有效净化烟雾,图像色彩也保留较好。
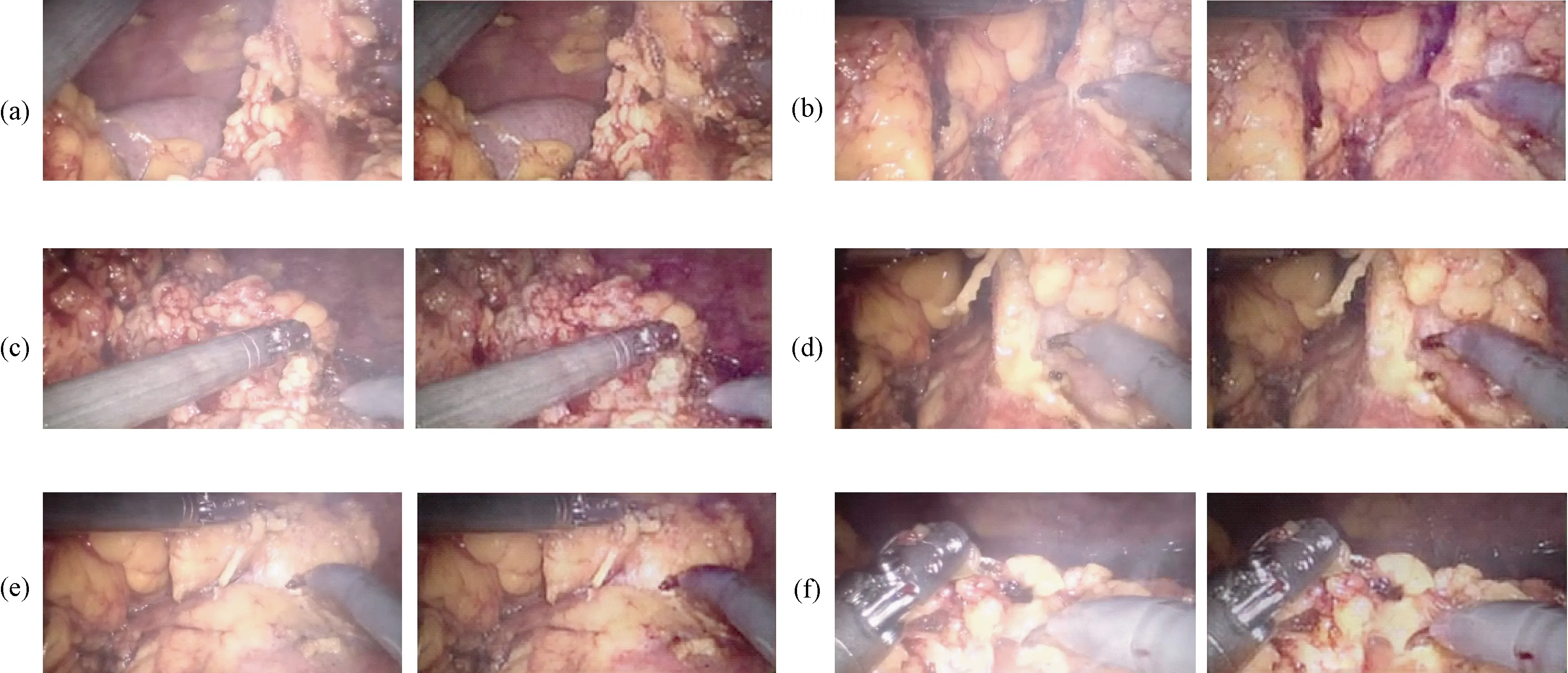
图6 真实烟雾腹腔镜图像及净化后的图像(每个子图中,左为真实手术视频里随机截取的烟雾图像,右为CBAM+拉普拉斯图像金字塔融合+U-Net模型对其的净化结果)。(a)图像1;(b)图像2;(c)图像3;(d)图像4;(e)图像5;(f)图像6Fig.6 The real smoked laparoscopic image and the purified image(In each sub-image, the left image represents the randomly selected smoked image from the real surgical video, and the right image represents the purification result of CBAM+Laplace image pyramid fusion+U-Net model of the left image. (a)Image 1; (b)Image 2; (c)Image 3; (d)Image 4; (e)Image 5; (f)Images 6.

图7 合成烟雾腹腔镜图像及净化后的图像(每个子图中,第1张图像为从合成烟雾数据集里随机选择的烟雾图像,第2张图像表示基础U-Net模型对其的净化结果,第3张图像表示CBAM+U-Net模型对其的净化结果,第4张图像表示拉普拉斯图像金字塔融合+U-Net模型对其的净化结果,第5张图像表示CBAM+拉普拉斯图像金字塔融合+U-Net模型对其的净化结果)。 (a)图像1;(b)图像2;(c)图像3;(d)图像4;(e)图像5Fig.7 The synthesize dense smoked laparoscopic image and the purified image(In each sub-image, the first image is a randomly selected smoked image from the synthetic smoke dataset, the second image represents the purification result of the first image by the basic U-Net model, the third image represents the purification result of the first image by the CBAM+U-Net model, the fourth image represents the purification result of the first image by the Laplace image pyramid fusion+U-Net model, the fifth image represents the purification result of the first image by the CBAM+Laplace image pyramid fusion+U-Net model). (a) Image 1; (b) Image 2; (c) Image 3; (d) Image 4; (e) Images 5
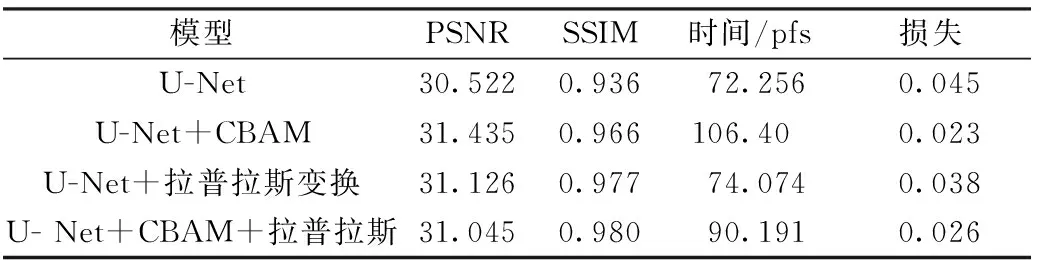
表1 交叉验证模型性能验证Tab.1 Model performance verification
2.2 模型对比分析
为验证本模型的有效性,与近期6种取得较好结果的方法对比,定量比较的结果如表2、图8、图9所示。表2为与其他6种方法的每秒运行画面数(fps)指标的对比,图8为与其他6种方法的PSNR指标的对比,图9为与其他6种方法的SSIM指标的对比。Bolkar等[16]对大气扩散模型进行推导,并用神经网络实现,是烟雾净化领域较早的经典方法,故与近期方法相比各项指标较低;Chen等[13]采用合成数据集,使用U-Net构架来实现烟雾净化,在对比的几种方法中时间性能较好,但真实烟雾图像的净化效果较差;Shin等[25]等采用辐射反射率优化方案,单张图片处理速度最慢;Wang等[15]采用U-Net构架并在下采样部分进行改进,相比前3种方法, PSNR指标有较大提升;Isola等[26]使用对抗神经网络的方法,在时间性能上取得了最优效果;Salazar等[20]使用对抗神经网络的方法,并将经过暗道检测的图像作为输入,在各项指标上都获得了较好的性能。本研究在PSNR和SSIM两项指标上取得了几种方法中的最好效果,在时间性能方面,与同样平台、同样框架的其他结果[13,20]处于相当水平,时间指标能够实现显示器稳定播放不抖动,因此可以应用在实时系统中。

表2 运行时间对比Tab.2 Processing time comparison in frames per second(fps)

图8 峰值性噪比PSNR对比Fig.8 Comparison of peak signal to noise ratio method

图9 结构相似性SSIM对比Fig.9 Comparison of structural similarity methods
3 讨论
在内窥镜手术过程中,由于手术需要注入的气体或者手术烧灼产生的气体严重遮挡医生的视线,会减慢手术进度,影响其他各项计算机辅助算法(如三维重建、疾病定位、疾病识别、手术导航系统)的应用。借助计算机辅助算法,可以有效解决此问题,因此提出基于改进U-Net网络的内窥镜图像烟雾净化算法。在U-Net网络编码器部分,加入经过拉普拉斯金字塔变换的训练图像,用于保留更多的图像细节;在U-Net网络解码器部分,加入CBAM注意力机制模块以提升网络性能,取得较好的效果。
深度学习对于训练集有较高要求,但在医学图像方面数据集相当匮乏。汉姆林中心腹腔镜/内窥镜视频数据集、TMI计算机辅助手术数据集(https://opencas.webarchiv.kit.edu/?q=tmidataset)提供了一些内窥镜图像数据集,但是含有真实标签的烟雾数据集太少。为解决此问题,许多研究者采用合成图像进行训练,并取得了较好效果[13,15,17,20]。因此采用由Blender渲染雾气的内窥镜图像作为训练集,在改进的U-Net网络上进行训练(见表2和图7~9),最终在合成数据集上获得了较好的定量和定性结果(见图6),在真实包含烟雾的内窥镜图像上具有较好的定性结果。
内窥镜图像是医学图像的代表,具有角点纹理信息弱的特点。U-Net网络结构在医学图像处理领域应用广泛,尤其是在以深度学习为基础的烟雾净化领域。U-Net结构[13,15]及以U-Net结构为基础的对抗神经网络[17-20]的研究层出不穷,说明该结构能够较好地处理医学图像。在采用原始U-Net时,其结果如图7(b)所示。在测试浓雾数据集时,经模型处理后的图像仍然有烟雾残留,与正常内窥镜图像对比颜色产生了失真,其性能不足以应用在医用场景中。为了提升网络性能,提出了改进措施。在参考文献[15]的基础上,在编码部分的每层网络中加入经过拉普拉斯金字塔变换的训练图像,将图像的细节及重要信息传递到每一层,降低了下采样过程中的细节信息损失。从定性验证的结果可以看出,加入拉普拉斯金字塔的模型能够更好地保存图像的色彩信息;在解码部分加入CBAM注意力机制,让网络明白每一层具体保存的图像信息,更好地获得网络的中间特征,并且提升网络的各项指标。如表1所示,在加入两种方案后,最终模型的损失值都有下降,并且单张图像处理的时间有所下降,PSNR和SSIM的值有所上升。在加入拉普拉斯金字塔变换后,单张图像的处理时间基本没有变化,为74.074 pfs;在同时加入两种方法后,单张图像的处理时间为90.19 pfs。在仅加入CBAM注意力机制后,单张图像的处理时间为106.4 pfs,说明该机制加入后模型的各项性能都有大幅度提升。CBAM注意力机制在空间注意力模块中注重位置信息,在通道注意力模块中注重内容信息,共同作用而真正提取出了有效特征,并提升了模型性能。在加入经过拉普拉斯金字塔变换的图像后,在定量指标上SSIM获得了较好的提升。由图7(d)、(e)两行可以看出,使用了拉普拉斯金字塔变换处理的图像,能够较好地保留原图像的色彩亮度。
虽然在烟雾净化后SSIM和PSNR指标都获得了较好的提升,但是仍然有许多尚未考虑到的因素,算法仍存在值得改进的地方。其一,烟雾净化过程中的图像没有考虑其他外界情况(如水雾),或者是医生在烧灼过程中加入纯白纱布吸出血液,纯白纱布和烟雾具有相似性,所以模型在训练和测试时可以考虑水雾、遮挡、纱布等外界因素影响。其二,在分别训练轻雾和浓雾两个类型的图像时,烟雾越浓厚,烟雾净化的效果越差,图像失真也越严重,尤其是色彩的失真;为更好地模拟烟雾从出现到消失的整个过程,增加合成烟雾的等级或者增加浓烟图像在训练集中的比例是一种改进方式,也可专门设计针对浓雾的网络结构。其三,实时性对于医用内窥镜系统来说也至关重要,在加入CBAM模块的实验中提升了模型的时间性能,说明优化网络结构可提升时间性能。后续研究可采取其他的注意力机制、优化的网络模型和压缩剪枝[27]等方法,以提升网络的时间性能。
4 结论
用改进的U-Net网络实现了内窥镜烟雾图像净化算法。为了保留更多图像细节,在U-Net网络编码器部分加入经过拉普拉斯金字塔变换的训练图像;为了提升网络性能,在U-Net网络解码器部分加入CBAM注意力机制模块。为解决烟雾图像稀缺的问题,采用Blender对腹腔镜图像进行渲染,得到轻雾、浓雾两种烟雾水平等级的图像,并将合成图像送入改进的U-Net网络进行训练。在轻雾和浓雾数据集上的综合测试结果如下:结构相似性指标SSIM为0.98,峰值性噪比PSNR为31.05,与其余6种方法相比均有提升,运行平均速度为90.91 fps,可实时运行。研究表明,本方法为内窥镜实时烟雾净化提供了可靠手段。
