基于标签校正的端到端实体关系联合抽取
2021-11-06陈鹏之程学旗
陈鹏之,张 瑾,刘 悦,程学旗
(1.中国科学院计算技术研究所 中国科学院网络数据科学与技术重点实验室, 北京 100190;2.中国科学院大学, 北京 100049)
实体关系联合抽取是指从非结构化文本中抽取出具有某种语义关系的实体对,即实体关系三元组,如图1所示。它应用广泛,可以用于构建知识图谱和本体知识库,支持上层应用,如问答系统、搜索引擎等,为其他自然语言处理技术提供支持。
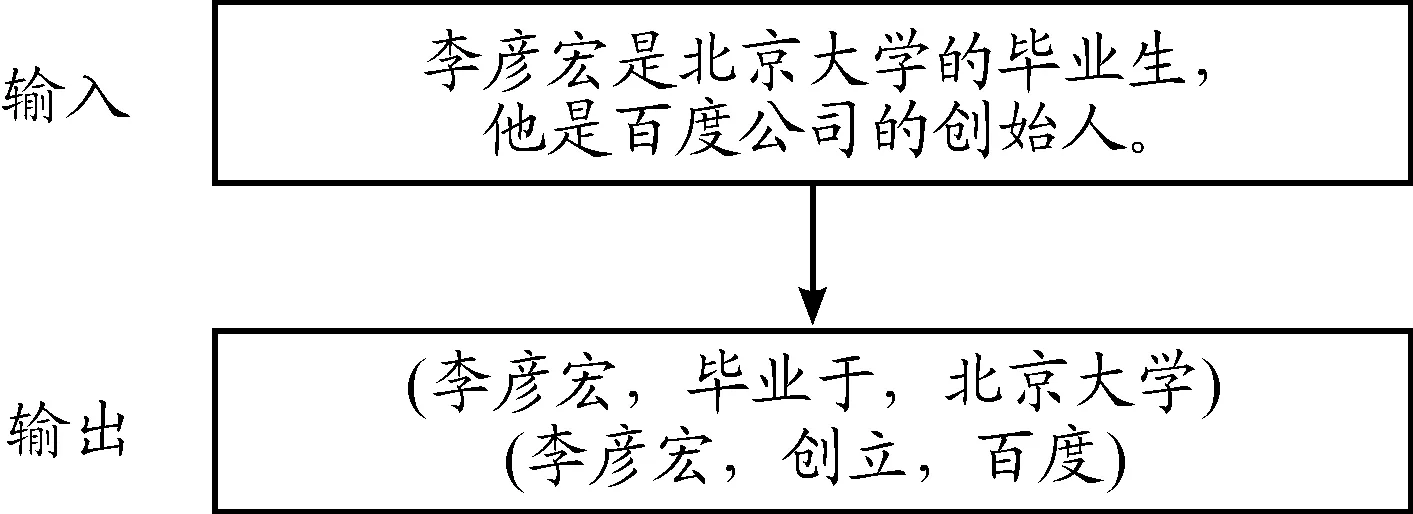
图1 实体关系三元组抽取
传统的实体关系抽取任务通常采用管道式(pipeline)模型,将实体关系抽取分成命名实体识别与实体关系分类2个独立的子任务,2个子任务独立工作。
管道式方法的优点是可以灵活调用每个模型,每个模型都可以应用到不同的场景,同时缺点也很明显,它忽视了实体识别与关系分类之间的语义关联;其次,实体识别引入的错误会影响关系分类的效果;最后,任意实体对间不一定都存在某种关系,但需要对所有实体对进行关系分类。
近几年研究者们逐渐将实体关系抽取当成一个整体任务来研究,同时抽取句子中的实体和关系。与管道式抽取方法相比,联合式抽取方法[1]能够有效利用实体和关系间紧密的交互信息,同时抽取实体并预测实体间的关系。Kate等[2]在2010年提出了“卡片-金字塔”的图形结构,并将其用在实体关系联合抽取上。Yang等[3]在2013年提出了一种联合抽取模型,使用整数线性规划提取符合条件的实体及关系。Katiyar等[4]在2016年首次将深度双向LSTM序列标注的方法用于联合提取观点实体IS-FROM、IS-ABOUT关系。Zheng等[5]在2017年提出一种复合型标签策略,利用序列标注的方法同时识别出实体和关系。近两年来,基于端到端的联合抽取方法逐渐被研究者提出,Zeng等[6]在2018年提出一种基于端到端的实体关系联合抽取模型CopyRE,根据机器翻译的思想,将输入语句看成是源语言,将实体关系三元组组成的序列看作是目标语言,以此抽取实体及关系。
基于端到端的联合抽取方法主要存在2个问题:首先,在实体抽取的过程中,该类方法默认每个实体仅由一个单词构成,从而导致模型没有办法抽取出完整的实体;其次,该类方法抽取出的实体对准确率低,在整个抽取过程中,关系预测和实体抽取会相互影响,使得关系预测不准确,进而导致抽取出的三元组准确率低。
针对上述问题,本文提出一种基于标签校正的联合抽取方法,称为CopyLC。首先,在解码阶段使用4个权重矩阵,配合Attention、Copy、Mask机制,分别抽取主、客实体的首尾,以此抽取完整的实体。其次,在解码完成时,通过标签序列对抽取的实体进行校正。最后,将以上2部分结合,构建一个多任务学习模型。实验结果证明,本文的方法在NYT和WebNLG数据集上均能获得更好的抽取效果。
主要贡献包括:
1) 引入4个权重矩阵进行解码,配合Attention、Copy及Mask机制,在解码过程中抽取出完整的实体;
2) 利用标签序列进行抽取实体校正,同时提高实体对抽取和关系预测的准确率,进而提升三元组抽取效果。
1 相关工作
实体关系抽取是信息抽取领域中的重要研究课题。主要分为2种抽取方法,一种是管道式抽取,另一种是联合式抽取。
1.1 管道式抽取方法
管道式抽取将实体关系抽取分为实体识别和实体关系分类2个独立的子任务。实体识别主要分为基于统计和基于深度学习2种方法。基于统计的方法将命名实体识别看成序列标注问题,代表方法如隐马尔科夫模型(HMM)[7],最大熵马尔科夫模型(MEMM)[8]以及条件随机场模型(CRF)[9]等。近几年,不少学者将深度学习技术应用在命名实体识别上。Lample等[10]使用LSTM等神经网络模型抽取实体。除此之外,卷积神经网络(CNN)[11]等深度学习方法也被用来解决命名实体识别问题,并取得了较好的结果。
实体关系分类可以分为基于特征向量、基于核函数以及基于深度学习3种方法。基于特征向量的方法抽取出2个实体所在位置的上下信息,如语法、语义特征以及实体的特征等,利用这些特征训练分类模型,此类方法有Kambhatla等[12-13]。相比于基于特征向量的方法,核方法能够有效地对实体对上下文信息进行表示,对人工的依赖更小,并且扩充了语义表达空间,可以涵盖更多信息。基于核函数的关系分类方法有Mooney等[14-15]。随着深度学习技术的发展与兴起,神经网络方法被引入到实体关系分类任务中。Socher等[16]于 2012 年首次提出基于RNN模型的关系分类方法。Zeng等[17]在2014年首次将CNN用于关系分类,通过CNN分别提取词汇和句子的特征,利用池化后的特征及位置特征对实体对进行分类。
1.2 联合式抽取方法
联合式抽取方法能够有效利用实体和关系间紧密的交互信息,将实体关系抽取看作一个整体任务,同时抽取实体并预测实体间的关系。Miwa等[18]在2016年首次将神经网络用于联合表示实体和关系。该方法将实体识别任务当作序列标注任务,使用双向LSTM输出具有依赖关系的实体标签;再根据依存树中目标实体间的最短路径对文本进行关系抽取。Katiyar等[19]于2017年首次将注意力机制与双向LSTM结合在一起,用于联合抽取实体及关系,该模型可以进行扩展以提取各种预定义好的关系类型,是真正意义上的第一个神经网络实体关系联合抽取模型。Zheng等[5]在2017年提出了一种新颖的标注策略的实体关系抽取方法,把原来涉及到命名实体识别和关系分类2个子任务的联合学习模型抽象成一个序列标注的问题,他们提出一种复合型标签策略,利用序列标注的方法同时识别出实体和关系。Zeng等[6]在2018年提出一种基于端到端的实体关系联合抽取模型,使用Encoder-Decoder框架,配合Attention、Copy机制等同时抽取实体及关系。
2 基于标签校正的联合抽取方法
为解决现有端到端模型的抽取中未考虑实体multi-token问题以及抽取过程中关系预测与实体抽取相互影响的问题,本节将选取当前代表性的端到端抽取模型CopyRE作为基础模型,根据机器阅读理解中寻找答案的思想,采用多个权重矩阵抽取实体,并引入标签校正机制,提出基于标签校正的联合抽取方法CopyLC(copy mechanism for relational facts with label correction)。
2.1 CopyRE
CopyRE是基于Encoder-Decoder框架的一种联合抽取模型,它主要包含Encoder和Decoder两部分。Encoder模块对输入语句编码并转化为特征向量。Decoder模块利用Encoder生成的特征向量,生成实体关系三元组。

(1)
Decoder模块使用单向LSTM,配合Attention机制与Copy机制抽取三元组。抽取过程分为迭代的3步,第1步是预测关系,第2步是抽取主实体,第3步是抽取客实体,然后迭代该过程,直至达到预先设定的步长。整个解码过程,模型会得到多个实体关系三元组。当输入语句中的三元组个数小于模型设置的最大三元组个数时,Decoder生成NA三元组,表示空实体关系三元组。
解码过程可形式化为式(2):
(2)
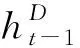
Decoder模块t时刻的输入ut由2部分组成,一部分是t时刻的输入vt,另一部分是Encoder的输出与Decoder的隐状态生成的Attention向量at。
ut表示如下:
ut=[vt;at]·Wu
(3)
vt表示t-1时刻模型预测的关系或是抽取出的实体。Attention向量at表示为:
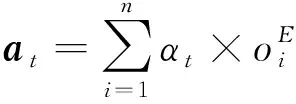
(4)
αt是权重,由Encoder的输出与Decoder的隐状态经过非线变化得到,如式(5)所示:
(5)
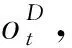
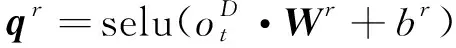
(6)
式中:qr是一个N维的向量,每一维表示对应的关系;Wr是权重矩阵;br是偏置项。因为模型可能会生成空关系,简称为NA关系,用qNA表示空关系向量,如式(7)所示:
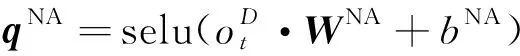
(7)
CopyRE将关系集合qr和空关系qNA拼接在一起,得到一个N+1维的向量,表示可能预测出的所有关系,再选出概率分布上值最高的那一维对应的关系作为当前三元组的关系,如式(8)所示:
prel=softmax([qr;qNA])
(8)
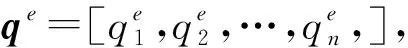
(9)

pe=softmax([qe;qNA])
(10)
客实体抽取与主实体类似,为了保证抽取的三元组有意义,2个实体不能重叠,M表示客实体不能是主实体对应的单词,客实体概率分布为:
pe=softmax([M⊗qe;qNA])
(11)
2.2 CopyRE存在的问题
2.2.1无法抽取完整的实体
CopyRE只能抽取实体中的最后一个单词。在现实情况中,实体不仅只由一个单词构成,也存在多个单词构成的实体,特别是在中文中,大多实体都是由多个字符组成,在这种情况下,CopyRE无法抽取出完整的实体。
2.2.2抽取出的实体对准确率低
通过复现CopyRE模型,还发现该方法抽取出的三元组F1值较低,主要原因是抽取出的实体对准确率较低,进而使得整体抽取效果较低。
2.3 基于标签校正的端到端实体关系联合抽取模型CopyLC
针对端到端抽取模型存在的不足,本文在CopyRE模型基础上提出一种基于标签校正的端到端实体关系联合抽取方法,称为CopyLC,模型框架如图2所示。
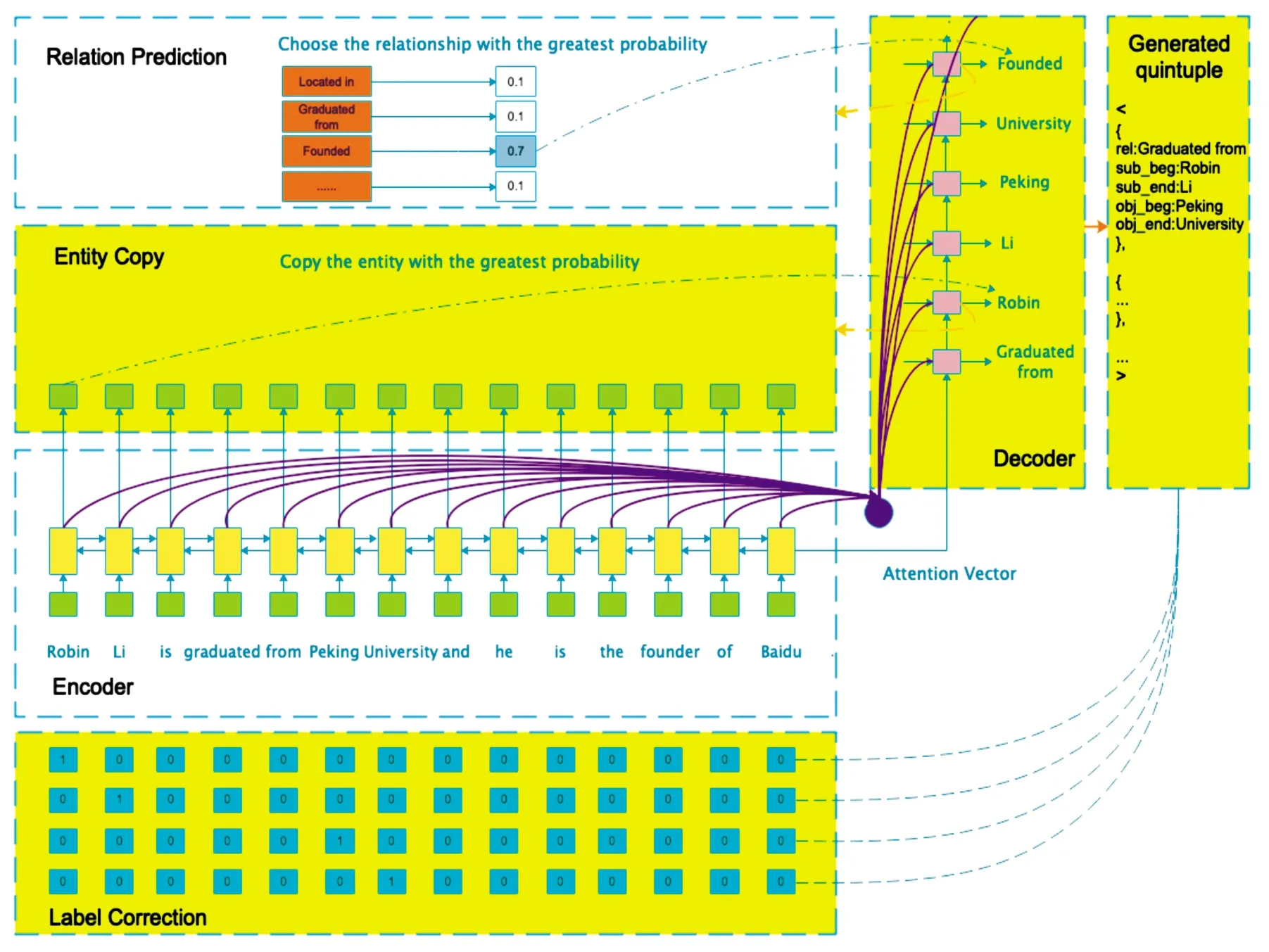
图2 CopyLC模型框架
如果只生成有明确意义的实体关系三元组,在一定程度上就能减少抽取所带来的冗余信息,同时,端到端模型自动将实体与关系以及实体与实体间建立了某种语义关联。另外,要抽取的实体一定是源于句子中,所以使用拷贝机制而非从固定词表中生成单词,可以更精确完整地抽取实体。因此,本文使用基于RNN的神经网络模型学习待识别句子的上下文信息,并通过注意力机制与拷贝机制,直接生成实体关系三元组,并且在解码完成时进行标签校正,实现多任务学习,从而提升实体关系抽取的效果,称为Copy Mechanism for Relational Facts with Label Correction,简称CopyLC模型。
模型框架包含3个主要模块,第1个模块是Encoder,负责对输入语句进行编码;第2个模块是Decoder,负责关系预测和实体抽取;第3个模块是标签校正,对抽取出的实体进行校正。Encoder编码及关系预测部分与CopyRE相同,在本文中不再赘述,下文主要针对实体抽取及标签校正进行介绍。
2.3.1实体抽取
标准生成式模型是每一步从固定词表中选择一个当前条件下概率最高的单词作为输出,但这个单词不一定是原文中的单词。就实体抽取而言,组成实体的每一个单词,其实都是原文中的某一个词,所以可以用拷贝机制替代固定词表生成,从输入文本中分别将2个实体拷贝出来。本文用2步来抽取一个实体,第1步,找到实体的开始位置,第2步,找到实体的结尾位置,这样,每2步就可以抽取出任意长度实体,而不受限于实体长度,也不存在分词等预处理引入的错误传递。整个过程类似于机器翻译,不断地生成单词,只不过现在是从原文中拷贝,每2步就可以抽取出一个实体,一个实体关系三元组由一个关系和2个实体(主实体、客实体)构成,所以,每5步就可以抽取出一个完整的实体关系对(第1步抽取出关系,第2步至第5步抽取主、客实体)。相对于管道式抽取方法,它能更好地建模实体与关系,以及实体与实体间的语义关联。
实体的抽取分为2大步,4小步,前2步抽取主实体,后2步抽取出客实体。第1步抽取主实体的开始位置,利用Encoder的输出与Decoder的输出得到输入句子中每个单词的表达向量:
(12)
psub_beg=softmax([qsub_beg;qNA])
(13)
下一步需要抽取出主实体的结尾位置,抽取方法与抽取主实体开始位置类似。主实体的结尾位置必须位于主实体开始位置之后(可以重叠,相当于实体由一个单词构成),为了保证抽取的实体有意义,使用Mask机制:

(14)
式中:j表示主实体开始位置:i表示句子中某个单词的位置,通过Mask机制可以计算主实体结尾位置的表达向量:
psub_end=softmax([Msub⊗qsub_end;qNA])
(15)
抽取出主实体后,接下来需要抽取客实体的开始位置。本文假设2个实体之间是不能重叠的,即客实体不能和主实体之间有交叉。同样,使用Mask机制来辅助抽取出客实体的开始位置:

(16)
式中:subject表示主实体所在的位置;i表示句子中某个单词的位置,通过Mask机制可以计算客实体开始位置的表示向量:
pobj_beg=softmax([Mobj_beg⊗qobj_beg;qNA])
(17)
最后一步,抽取客实体的结尾位置。这里存在2种情况,第1种是主实体位于客实体之前,第2种是主实体位于客实体之后。
当主实体位于客实体之前时,客实体开始位置位于主实体之后,所以客实体前的所有位置不可能成为客实体的结尾,具体表示如下:
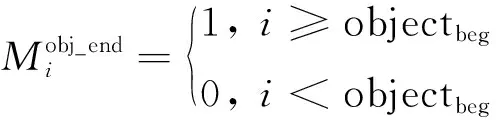
(18)
当主实体位于客实体之后时,客实体的结尾位置必须位于主实体开始与客实体开始位置之间,具体表示如下:
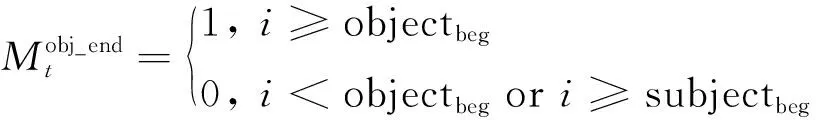
(19)
实际中,根据具体情况计算客实体的结尾位置:
pobj_end=softmax([Mobj_end⊗qobj_end;qNA])
(20)
最终,将开始与结尾的之间的所有单词组合,得到完整的实体,再将第1步预测的关系和第2步至第5步抽取出的2个实体组合在一起,就可以得到一个完整的实体关系三元组,迭代下去,就可以得到多个实体关系三元组。
2.3.2标签校正
当模型抽取出多对实体关系三元组后,使用一个标签校正(label correction)模块校正抽取出的实体。用正确的实体对模型抽取出的实体进行校正。本文用4个序列分别记录主实体开始、结尾、客实体开始、结尾位置的标签。将一个句子表示为s=[w1,w2,w3,…,wn],其中s代表整个输入的句子,n表示句子的长度,wi表示第i个单词,在中文里表示第i个字符。例如,当句子中第1个单词和第3个单词表示主实体的开头时,本文用tagsub_beg=[1,0,1,…,0]表示主实体开始的标签序列,即在输入句子中,将主实体开始对应的位置标记为1,其余位置标记为0。同理,用tagsub_end,tagobj_beg,tagobj_end分别表示主实体结尾,客实体开始、结尾的标签序列,具体标注方法如图3所示。
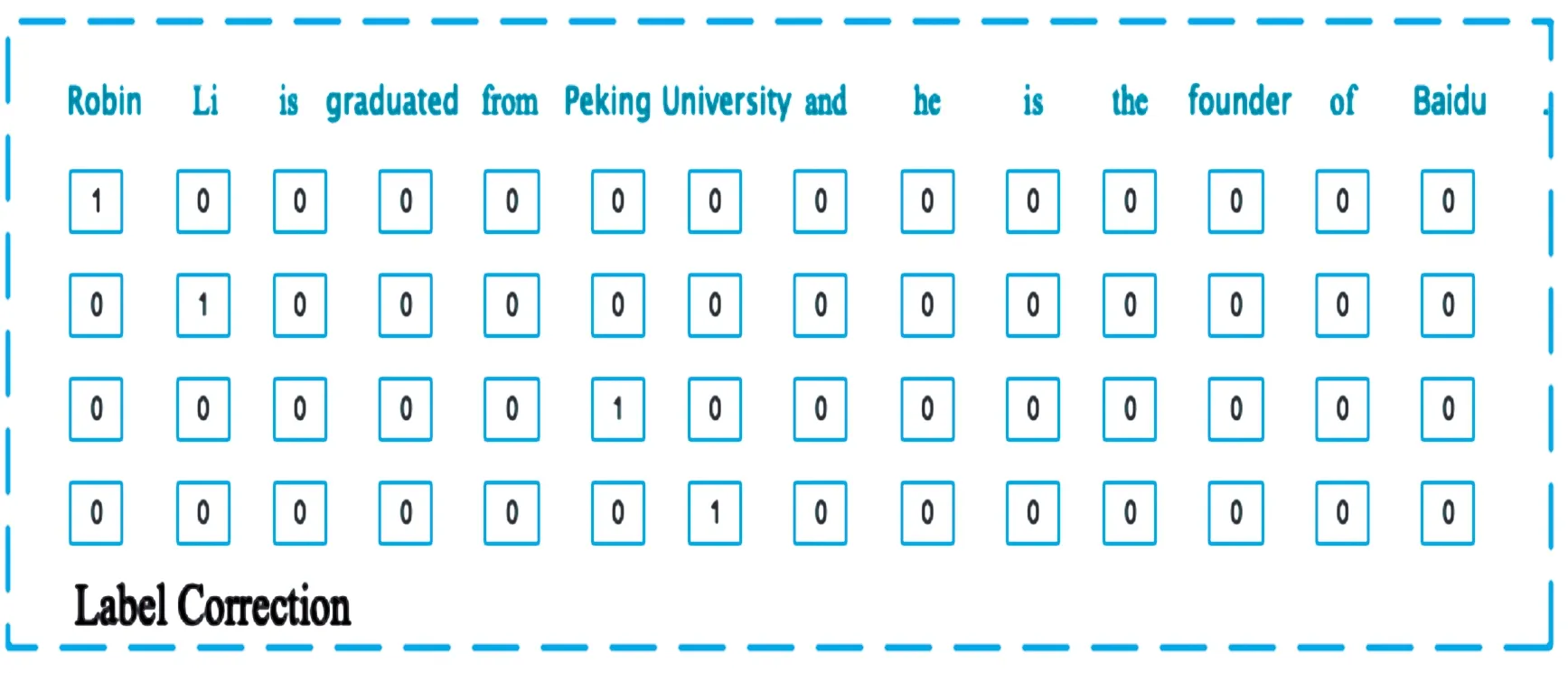
图3 标签校正序列
本文通过Decoder解码与标签校正,构建一个多任务学习系统,使得模型同时考虑生成的实体关系三元组以及实体本身,损失函数如下:
(21)
损失L由生成的三元组和标签校正共同决定,γ是权重,表示标签校正在整个损失函数中的重要程度;标签校正部分的损失Ltag由主实体开始、结尾,客实体开始、结尾这4部分损失共同决定,β,γ是权重,表示正确识别出实体开始位置与识别出实体结尾位置的相对重要程度。
3 实验
3.1 实验数据
实验采用2个公开数据集New York Times(NYT)和WebNLG来评估算法的有效性。
NYT是谷歌发布的关于远程监督关系抽取的数据集,该数据集包含1987年到2007年纽约时报文章中118万条句子,一共有24种关系。本文将数据集看作是监督数据,选出所有句子长度大于100的句子用于训练、验证及测试。
WebNLG原本是为自然语言生成任务而提出的数据集,一共包含246种关系。数据集中的每一个样本都包含几条人工编写的句子以及几个实体关系三元组,本文只选取每个样本中的第一条句子,并且过滤所有三元组都没在第一条句子中出现的样本,即保证一个样本中至少有一个三元组。
经过统计,发现NYT数据集中大约34%的实体是multi-token实体,WebNLG数据集中大约56%的实体是multi-token实体。数据集详情见表1。
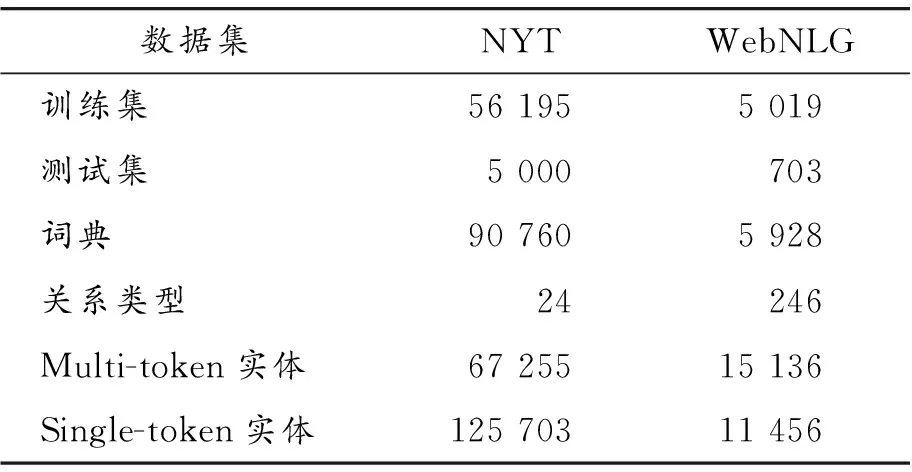
表1 数据集分析
3.2 实验设置
为了与CopyRE方法公平比较,本文在实验中的参数设置与CopyRE相同。本文使用双向LSTM进行编码,单向LSTM进行解码,词向量使用CopyRE预训练的词向量,使用Adam优化神经网络。实验中使用2种解码方法,一种是用一个解码器生成所有三元组,称为OneDecoder,另一种是一个解码器生成一个三元组,称为MultiDecoder。具体参数见表2。
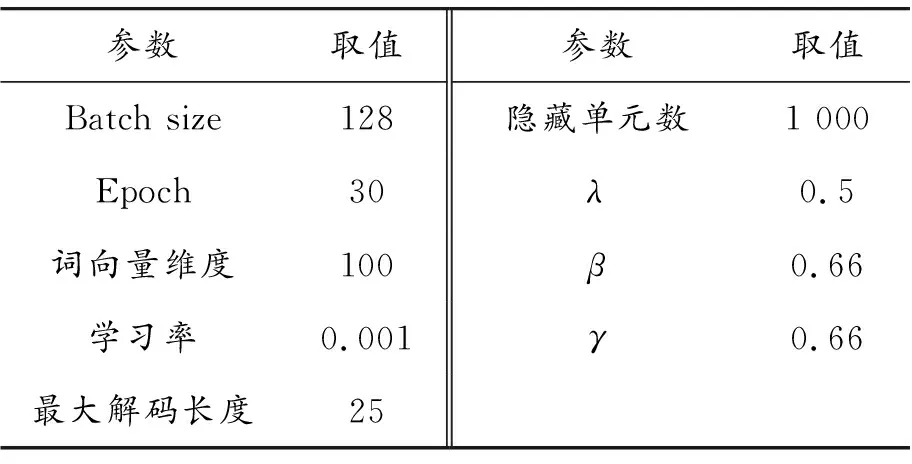
表2 参数设置
使用负对数似然损失函数(negative log likelihood loss,简称NLL)训练实体关系三元组的生成,损失函数如下式:
(22)
式中:T表示解码长度;y表示目标序列,y=[y1,y2,…,yn];yi表示目标序列中的第i个字符,表示已经生成的字符;x表示输入句子;θ表示模型的参数。
本文使用交叉熵损失函数(cross entropy loss,简称 CE)校正生成的实体,损失函数如下所示:
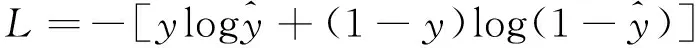
(23)
3.3 评估方法
与CopyRE方法相比,本文使用更严格的评价方法,只有当抽取出的关系以及主实体、客实体首尾都完全正确时,才认为抽取出的三元组是正确的。相比于CopyRE只抽取出实体的一部分就认为是正确的,本文的评价方法更加合理、严谨。
本文使用微平均精确率(precision),召回率(recall)以及F1值评估算法的效果。当模型预测的结果中含有NA对(空关系实体对)时,本文在计算精确率、召回率时,将其剔除。
3.4 实验结果及分析
将本文CopyLC模型实验结果与CopyRE结果进行对比,如表3和表4所示。可以看出,本文模型的抽取效果在不同数据集上都优于CopyRE。本文中,使用OneDecoder方法进行解码的CopyLC称为CopyLC-One,使用MultiDecoder方法进行解码的CopyLC称为CopyLC-Mul。CopyRE-One(ours)与CopyRE-Mul(ours)表示对CopyRE复现后的模型。
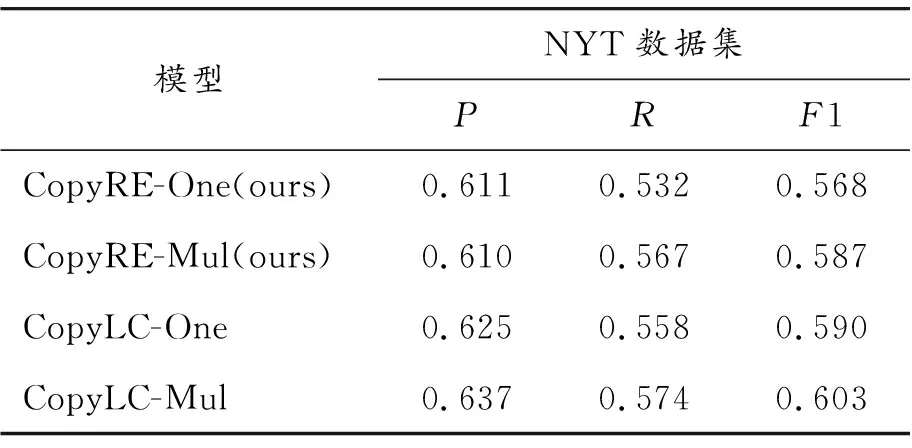
表3 NYT数据集实验结果
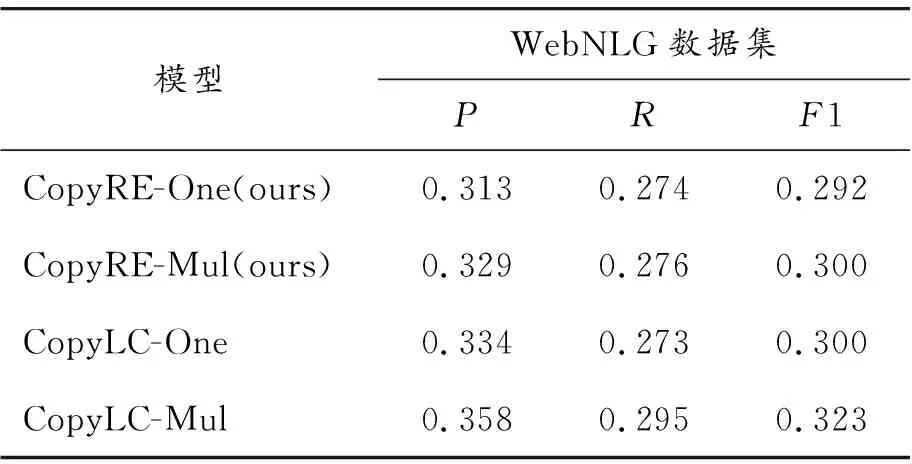
表4 WebNLG数据集实验结果
为了分析标签校正模块对抽取效果的影响程度,本文设计了消融实验,实验结果如表5和表6所示,分别验证标签校正模块在NYT和WebNLG数据集上的效果。CopyLC表示本文的模型,-LC表示本文模型去除标签校正模块。
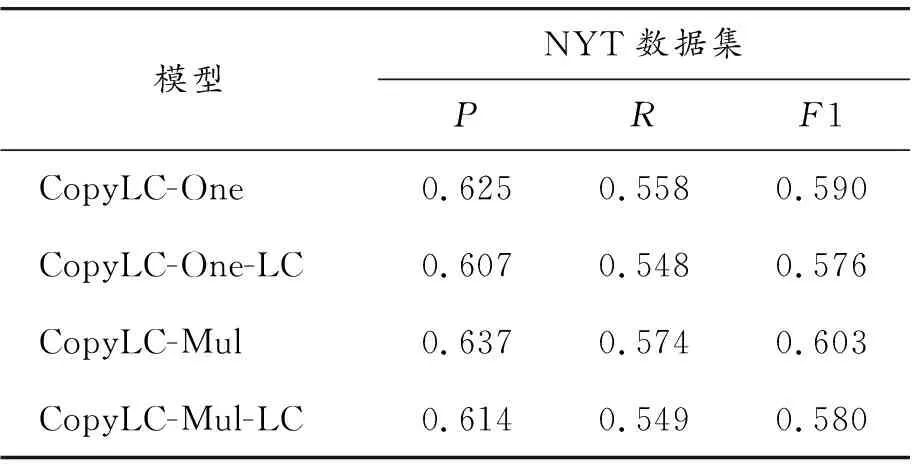
表5 NYT数据集消融实验

表6 WebNLG数据集消融实验
通过消融实验,发现标签校正模块对抽取效果有提升,三元组的准确率、召回率及F1值均得到提升,在使用OneDecoder的情况下,在NYT数据集上F1值提高1.4%,在WebNLG数据集上F1值提高2%;在使用MultiDecoder的情况下,在NYT数据集上F1值提高2.3%,在WebNLG数据集上F1值提高2.4%。为了进一步探究标签校正模块的具体影响,本文在CopyLC-One模型上进行实验,统计模型在关系预测和实体对(由主、客实体共同构成)抽取上的效果,如表7、表8所示。
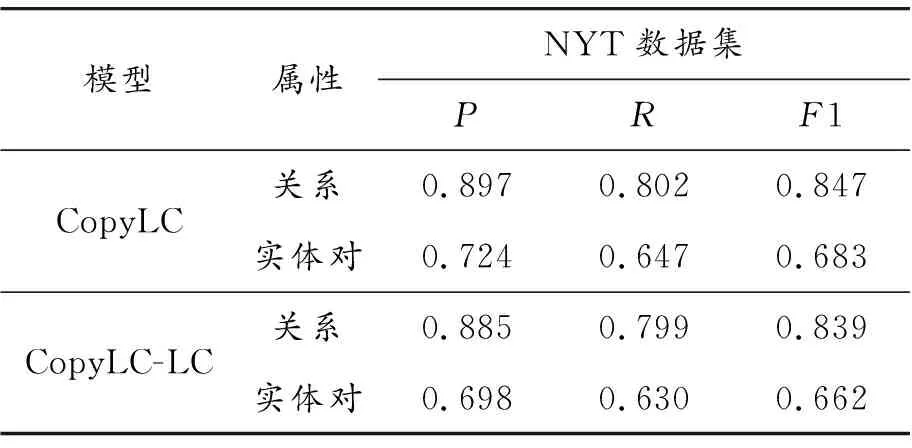
表7 NYT数据集关系和实体对抽取效果

表8 WebNLG数据集关系和实体对抽取效果
根据表7、表8的实验结果,本文发现标签校正模块对关系预测以及实体抽取的效果均有提升。本文认为关系预测及实体抽取效果提升的原因是模型采用的是Encoder-Decoder架构,标签校正使得抽取的实体更准确,抽取出的实体会影响下一个三元组中的关系预测,使得关系的预测更加准确,反之,关系预测也会影响实体的抽取。
4 结论
针对当前基于端到端的联合抽取方法存在抽取中未考虑实体multi-token问题以及抽取过程中关系预测与实体抽取相互影响等问题,本文结合Encoder-Decoder框架的特点,引入标签校正机制,提出了一种基于标签校正的实体关系联合抽取方法。从实验结果来看,本文提出的方法,在更严格的评价方法下,相比较当前主流方法在NYT和WebNLG数据集上均能获得更好的抽取效果。本文提出的方法在初始设置时需要指定最大解码长度,当一个句子中存在的实体关系事实大于预设定的最大值时,某些实体关系事实可能会被遗漏,同时融合更丰富的全局信息以获取更好的抽取效果,下一步研究将围绕这些问题继续推进。
