一种基于成词率和谱聚类的电力文本领域词发现方法*
2021-11-04尹春林李慧斌
杨 政 ,尹春林 ,蔡 迪 ,李慧斌
(1.云南电网有限责任公司电力科学研究院,云南 昆明 650217;2.西安交通大学 数学与统计学院,陕西 西安 710049)
0 引言
针对特定领域的文本数据,领域词的词库构建是最为关键的任务之一。传统领域词发现方法依赖互信息或邻接熵得到候选词集,进而利用word2vec 进行词向量转化、K-means 进行聚类[1],最终得到行业领域词。传统方法对词语组合规律运用得不够全面,因此这类方法筛选的候选词集存在诸多不合理的词语。领域词发现分为候选词集筛选与字符串过滤两个步骤。
在候选词集筛选方面,领域词发现算法主要是基于词语统计特性的无监督方法或序列模式机器学习的有监督算法。基于无监督的方法中,互信息和凝固度是最常见的用来筛选词语的度量,刘伟童等[2]提出使用互信息初步筛选词集,随后用邻接熵对词集进行再过滤的方法。刘昱彤等[3]使用改进的类Apriori 算法,通过组合、统计频率、过滤3 个步骤来筛选候选词集。杜丽萍等[4]提出利用改进的互信息,同时结合一定的构词规则筛选候选词集。无监督算法泛化性优良,但缺少规则,会遗留有较多垃圾串与非领域词。基于监督的机器学习词集筛选方法有马建红等[5]提出的基于CNN 和LSTM 抽取词特征,随后使用半马尔科夫条件随机场(SCRF)来识别词语边界。Fu Guohong 等[6]在隐马尔可夫模型(HMM)的框架下运用命名实体识别(NER)的思路,同时结合上下文筛选出候选词集。陈飞等[7]提出运用条件随机场来判断分词的词汇边界是否为候选词边界的方法。监督方法通常需要大量标注数据进行训练,耗费高额的人工成本。此外,部分方法选择基于纯规则的构词法[8-9](即汉语成词规则)与一些领域先验知识结合,进行候选词集的筛选。这种方式虽然准确性相对较高,但是规则维护复杂,基本无跨域能力。
在得到候选词集之后还需对垃圾字符串与非领域词进行过滤。赵志滨等[10]定义了词语相似度计算的Words-Avg 方法,通过与阈值对比来判断候选词集里的词是否为领域词。王鑫等[11]在使用word2vec 训练候选词向量时加入了词类信息,进而得到化学领域词。吉久明等[12]运用改进的GloVe 词向量模型提取词语向量,随后进行K-means 聚类,最终得到领域词。
1 本文方法
图1 展示了本文提出的方法,共分为5 个步骤:文本预处理、候选词筛选、文本切片算法、常用词过滤以及谱聚类[13]。
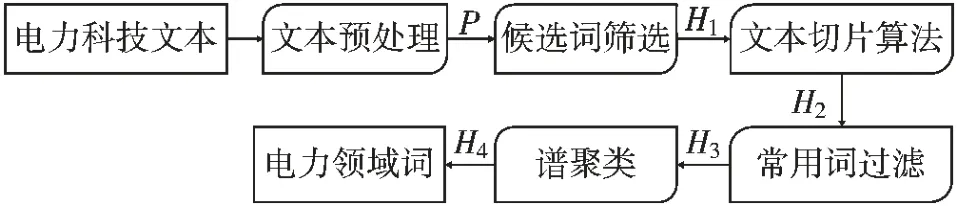
图1 本文所提方法流程图
1.1 文本预处理
在对文本进行候选词集筛选前,需对电力科技文档进行文本预处理,处理后得到文本记为P。具体处理步骤如下:
(1)筛选出电力科技文档中目的和意义、项目研究内容与实施方案三部分,避免其他电力领域词很少出现的部分干扰最终结果,同时提升算法运行效率;
(2)去除掉停用词,即语气助词、副词、介词、连接词(如“的”)以及标点符号。
1.2 候选词筛选
在得到预处理后的文本P 后,本文提出了一种新的候选词集筛选度量“成词率(Suc)”,用以对文本P 中的词语进行筛选,筛选后得到初步的词集H1。其中设定最长词语长度n 为4,候选词筛选度量Suc 的阈值设定为0.62,成词率由互信息(Mut)、左右熵(Adj)与构词规律(Reg)构成。
(1)互信息(Mut):指一个随机变量中包含的关于另一个随机变量的信息量,即随机变量间的联系程度,包含的信息量越高,则变量间联系程度越高,词内凝固度越高,该字符串则越容易成词。互信息Mut 的计算公式如式(1)~式(3)所示,分别表示2、3、4 字词的互信息,其中,x、y、z 代表单个字符。

(2)左右熵(Adj):指候选词的自由程度,左右熵表示词语搭配的不确定性。左右熵越大,词语搭配的不确定性越大,即候选的词左右搭配越丰富,成词概率越高,计算公式如式(4)、式(5)所示,Adjl、Adjr分别为左熵和右熵,w 为字符串,wr、wl为单前缀与单尾缀。

(3)构词规律(Reg):通过对电力行业领域词的观察发现,绝大多数领域词依然遵循构词学基本原理[14]:名词与名词、动词、形容词结合非常频繁,其他结合方式构成电力领域词的比例约四分之一,本文定义了字符串结合成词的构词规律Reg,其中a、b 为搭配成词的两个字符串。

(4)成词率(Suc):用来筛选候选词集的度量,结合了上述3 个变量的优点。

其中,k1和k2将互信息与左右熵的值映射到相近的量级,k1取值为Mut 均值除以Adjl的均值,k2取值为Mut均值除以Adjr的均值;m 为归一化常数。
1.3 文本切片算法
初步的词集H1中仍有诸多未被筛选的电力领域词,本文提出使用文本切片算法,算法步骤分为分词和回溯,具体如下:
(1)分词:在得到初步的词集H1以后,本文选择用H1对预处理后的文本P 进行切分,旨在得到更为合理的候选词集。在对预处理后的文本P 进行分词时,遵循的原则为“最准确切分原则”,例如:“各项目经理”这个字符串,很有可能“各项”、“项目”、“经理”、“项目经理”均在H1中,那么就选择不对此字符串进行分词,得到分词后的候选词集定义为H2。
(2)回溯:检查候选词集H2中的词语,如果词语长度小于n,则判断该词语是否在H1中,若不在H1中则从H2中删除;如果词语长度大于n,则判断该词语内部字符串是否有一半以上位于H1中,若没有则从H2中删除。例如:H2中有词语“单相接地故障”,该词语长度大于n,则判断“单相”、“单项接”、“单项接地”……是否在H1中,若不在H1中的词语个数小于其内部字符串组合情况总数的一半以上,则对该词语予以删除。
分词回溯举措中,分词意在最大化候选集中词语的准确性;回溯举措目的是进一步确保候选词集中的词语是内部足够“凝固”的,提高了候选词语的准确性。
1.4 常用词过滤
在得到的候选词集H2中,需要进一步对非领域词进行过滤。本文从中国知网中选择经济、哲学、化工3 个领域分别爬取50、50、40 篇非电力领域科技文本,对这140 篇文档重复第1.1~1.3 小节步骤,得到词集H21,同时将H2过滤掉H2与H21的交集,进而得到词集H3,如式(8)所示。

1.5 谱聚类
此时得到的候选词集H3除了电力行业领域词外,还有其他领域词以及不常用的非电力行业词,诸如:“麦克斯韦方程”、“对抗样本”、“池化层”等。因此,需要对H3中的词语进行聚类处理,此处选择BERT[15]算法对词集中的词语进行向量化处理,维度为512,最后运用谱聚类进行降维处理并聚类,最终得到电力领域词集H4。
谱聚类:把所有数据看作空间中的点,这些点可以用边连接起来,距离较远的两个点之间的边权重值较低,距离较近则较高。通过对所有数据点组成的无向图G=(V,E)进行切图,让切图后不同的子图间边权重和尽可能低,子图内的边权重和尽可能高,从而达到聚类的目的。其中,图顶点间权重集合为E={Ai,j},邻接矩阵为W={Ai,j},定义度D 为与当前图相连的所有图的权重Ai,j之和。优化函数如式(9)所示:
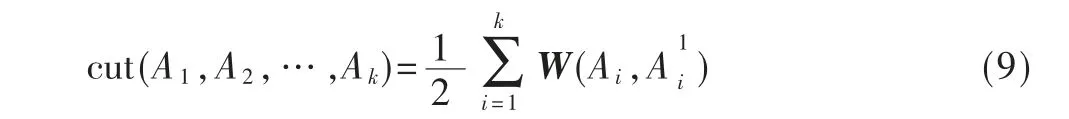

2 实验
2.1 数据集及预处理
本文从中国南方电网有限公司云南电力科学研究院科技项目申报文档数据库中选取了140 篇项目可研申请书作为领域词发现的语料库,研究主题主要包括:高电压与绝缘技术、电机与电气以及电力系统及自动化,表1 给出了数据集的组成情况。其中语料中的电力领域词总数为619 个,例如:高压、绝缘、电路、相位、电阻、继电器等。

表1 语料库中各类文本的数量
实验环境为:8 核16 线程CPU,Ubuntu20.04,Python3.6,TensorFlow-GPU 2.1.0,Nvidia 2070s 显卡。
在得到语料库后对每篇文档做如下处理,处理前后文档大小及本文所提算法运行时间如表2 所示:

表2 语料处理前后对比
(1)抽取出文档中目的和意义、项目研究内容与实施方案两部分。
(2)对抽取出的部分做正则化处理,包括去掉通用格式、数字等对中文领域词发现无意义的字符。
(3)将每篇文档被抽取出的部分拼接起来并存入JSON数据库,形成需要的数据。
2.2 评价指标及参数设置
评价指标:本文选取的模型评价指标为准确率P′、召回率R 以及F 值,这些度量指标用来评判电力词领域词发现模型效果,计算公式如下:

其中,识别到的词语总数为识别出的电力领域词集;语料中的电力领域词总数为人工筛选的电力领域词集;识别正确的电力领域词为识别出的电力领域词集与人工筛选的电力领域词集重合的部分。
参数设置:k1、k2由互信息(Mut)的均值与左右熵(Adj)权重来确定。对于成词率阈值,本文选取贪心算法进行阈值的取值计算,设定成词率Suc 阈值取值介于0~1 之间,步长为0.1,设定k1和k2取值介于100~500 之间,步长为1,m 为归一化常数,n_clusters 与gamma 为谱聚类参数,具体设置如表3 所示。

表3 参数设置
2.3 实验结果
首先,使用本文方法对140 篇电力科技文档进行领域词发现,同时将聚类效果进行可视化。如图2 所示,圆点表示电力领域词,五角星为非电力领域词,可以发现,与预期的预测结果基本一致,谱聚类输出结果中,电力领域词基本被聚集在了一起。

图2 谱聚类可视化效果
为了更加直观展示本文提出的基于成词率和谱聚类的领域词发现方法的效果,进一步对聚类后的词语做部分展示,如图3 所示。

图3 本文方法用于电力文本领域词发现的效果展示(部分)
从图3 中可以发现,筛选出的电力词汇是具有一定可信度的,但领域词中也有像“自动化”这种经常出现在电力科技文档里的词语,也有“电信网”这种带“电”字样却不是电力行业领域词的词语;非领域词中也有“相位”、“母线”这种个别被分错的电力领域词。
为了进一步验证提出方法的有效性,本文做了4 个消融实验,实验结果如表4 与图4 所示。可以发现,本文提出的成词率相比传统运用互信息和左右熵的方法有明显优势;使用文本切分算法后,各项指标也有明显提升。谱聚类方法相比传统K-menas 聚类方法也有明显优势。值得注意的是,聚类算法会使召回率与聚类前相比有所降低,主要原因在于聚类操作会使部分电力领域词被错分为非领域词。

图4 实验结果展示

表4 实验结果展示
3 结论
本文通过结合统计特征与语言规则,提出了成词率这一新的过滤指标,并结合谱聚类实现无监督电力科技文本领域词发现新方法。实验结果表明,所提方法与现有传统方法相比有效提升了候选词集筛选的准确性,同时在词语聚类时有效地解决了词向量维数过高的问题。
后续研究将着眼于对成词率指标的改进以及将词嵌入过程与聚类过程更加有效的融合,使其能够更准确地过滤非电力领域词,进一步提升方法效率和精度。
