不确定需求下容量限制工厂选址的改进蜂群算法
2021-11-01李睿雪
李睿雪,马 良,刘 勇
(上海理工大学 管理学院,上海 200093)
随着工业的不断发展,工厂选址问题作为工业生产开展的第一环节,始终是工业中研究的重点。在以往的容量限制选址模型中通常将需求量作为确定值考虑,但是,在如今工业发展和市场环境不断变化的情况下,需求点的需求不再是确定值。因此,考虑需求的不确定性对选址模型的影响显得尤为重要。
近年来,国内外学者在选址问题中针对需求不确定以及容量限制作了大量的研究。在不确定需求方面,Bayram 等[1]在应急设施选址模型中考虑疏散需求的不确定性,建立了基于需求场景的两阶段随机规划疏散模型。张鑫等[2]通过区间灰数理论预测不确定需求,将差分进化和遗传算法混合后对应急物资选址模型进行求解,但是,求解算法依赖大量的数据。成律等[3]在传统配送中心选址中,利用随机规划理论和模糊理论构建了随机客户需求情况下配送中心选址的数学模型,并应用遗传算法通过算例对模型进行验证,但遗传算法存在早熟等缺点。随后国内外学者对容量限制因素进行研究,Jena等[4]发现容量限制对动态设施选址有极大影响。李建光等[5]通过离散场景表征避难需求的不确定性,考虑情形权重以及避难位置的规模,构建了一个鲁棒随机规划模型来确定避难场所选址。商丽媛等[6]在多情景下需求不确定的应急物流配送中心选址模型中,将配送中心容量作为约束,对不确定需求用区间灰数表示,设计了免疫量子粒子群算法进行求解。徐小峰等[7]构建了考虑同时取送货需求和带模糊容量约束的在线设施动态选址模型。
然而,目前研究大多是考虑需求不确定或容量限制单一因素对工厂选址的影响,而实际中这两种因素共同影响选址决策。基于此,本文建立不确定性需求下分级生产规模容量限制工厂选址模型。将备选工厂设置为按生产规模分级分段以满足需求的不断变化,并通过区间联系数对不确定的需求进行预测。在算法上,之前的研究算法通常采用遗传算法和粒子群算法等求解,存在早熟和收敛性差等缺点。由于本文提出的工厂选址模型考虑需求的不确定性和容量限制规模的变化,求解算法编码和计算量相对之前研究更为复杂。而具有较好的适应性和并行性的蜂群算法更适用于本文模型。因此,采用人工蜂群算法求解以保证能够达到全局最优解。
1 生产规模分阶段容量限制工厂模型
1.1 工厂选址模型及参数
容量限制选址作为选址问题的扩展模型,其含义为在备选点满足需求点需求并且不超过其本身的容量限制前提下,选择总距离成本和建设成本最低的位置作为选址方案。针对需求不确定性这一特征,将生产规模设置为分阶段规划。根据备选位置不同需求量之和选择合适的规模,更有利于节约成本以及后续发展。为此建立了改进的容量限制选址问题模型。
模型的选址目标是在备选位置中选择能使距离成本最小和建设成本最小的最优位置。设I为备选工厂的位置集;J为需求点的位置集;K为时间集合;N为备选工厂不同生产阶段规模的集合;ωj表示需求点j需求量历年变化率的平均值;Rjk表示需求点j第k年的需求量变化率;dj为需求点j的需求量;tij表示从备选工厂位置i到需求点位置j之间的运输成本;ein表示备选工厂位置i实际选择的第n阶段生产规模;gi表示备选工厂位置i的最大生产规模;hi表示备选工厂位置i在该地点的基础建设成本;kin表示备选工厂位置i在第n阶段生产能力下每单位的生产建设成本;f为选择方案的总成本。
在工厂的生产规模大于需求点的需求之和的前提下,选择最优的备选位置,模型如下:
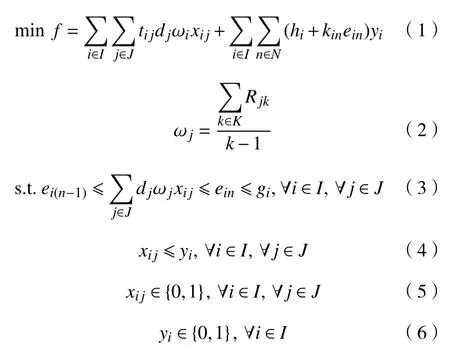
模型中目标函数式(1)表示工厂选址的运输成本和固定生产成本之和最小;式(2)表示需求点的需求量历年变化率的平均值;约束式(3)表示备选工厂所服务的需求点的需求之和不超出该备选工厂的最大生产能力;式(4)表示确保需求点和开放的备选位置保持对应;式(5)和式(6)为决策变量约束,xij为工厂i对需求点j服务,yi为在备选工厂位置i选择建设工厂,其中,开放取值为1,关闭取值为0。
1.2 基于联系数的区间灰数的不确定需求预测
针对事物不确定性和确定性关系,本文提出联系数这一概念,表示事物确定性测度和不确定性测度以及两者之间关系。不确定需求的区间数通过联系数表示,则可以更大程度地保留原来需求的不确定性[8]。
假设u=[A,B]是一个正区间数,可将其转化为联系数,表示为u=A+(B-A)i,根据联系数定义,i∈[-1, 1]。转化后区间数的范围扩大了一倍,变为[A-(B+A),A+(B-A)]。但由于需求的实际情况,本文不需要负范围,故取i∈[0, 1]。
灰色GM(1, 1)模型是常用的对含有不确定因素进行预测的模型,其中,灰色系统的基本元素为灰数,通常用“Gr”表示,指在某一个区间或者某个数集内取值的不确定数。区间灰数则是既有下界c又有上界d的灰数。记作Gr∈[c,d],c≤d,上界与下界的差值为区间灰数的长度,记作l=d-c。在预测模型中需要将一些列区间灰数组成一个区间灰数序列,记作Gr{Gr1,Gr2, ···,Grn}[9]。
设区间灰数Gr∈[c,d],则区间灰数序列为L{Gr}={Gr1,Gr2, ···,Grn},可将区间灰数白化,其白化值为Gri=c+μd,μ=[0, 1],μ为0~1的随机数。同样可以对区间灰数序列白化,其中,C{Gr}为白部,D{Gr}为区间序列白化后的灰部,如式(7)所示。
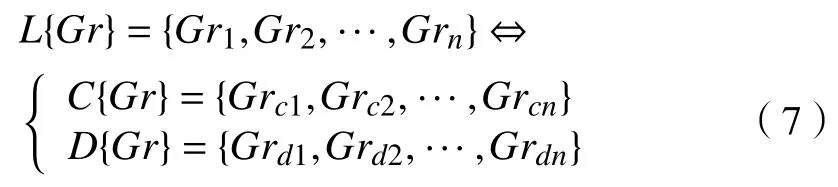
分别对区间灰色序列白部和灰部构建预测模型,将累加式还原到原始序列,得到式(8)和式(9)。
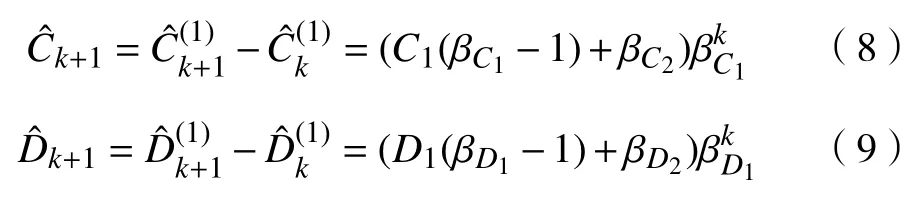
式中,β为最小二乘法的参数列中的参数。
结合联系数和区间数之间的关系,将不确定需求的区间转化为联系数,再利用灰色预测模型将联系数作为预测灰数,对需求进行预测。基于联系数的区间灰数预测模型既适用于小样本的数据,又能挖掘出样本之间隐含的不确定性。
设区间灰数Gr∈[a,b],U=A+Bi,A=a,B=b-a,i∈[0, 1],则U=A+Bi为其对应的联系数。U={U1,U2, ···,Un},Uk=Ak+Bki,Ak=ak,Bk=bk-ak,其中,A和B分别为联系数U的同部和异部,A={A1,A2, ···,An}和B={B1,B2, ···,Bn}为联系数序列U的同步序列和异部序列。根据区间灰数预测模型分别对A和B构建预测模型,可得同部和异部的响应函数。
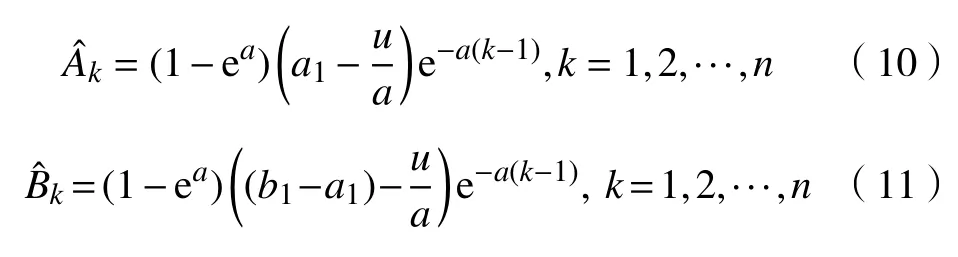
通过A和B值还原成区间灰数预测,即可得到需求量的模拟值。
2 改进的人工蜂群算法
2.1 人工蜂群算法
人工蜂群算法(artificial bee colony algorithm,ABC)是Karaboga等[10]在蜜蜂自组织采蜜的群体智能行为上提出的一种非数值优化计算方法,其中,蜂群实现采蜜的智能行为主要包含3个部分:蜜源、采蜜蜂、待工蜂,蜂群的采蜜过程主要包括:搜索蜜源、招募蜜蜂和放弃蜜源。
蜜源:蜜源表示存在的可能的解。通常为了方便求解,将收益度作为衡量蜜源优劣的标准;采蜜蜂:表示在蜜源中采蜜的蜜蜂,采蜜蜂通常携带蜜源信息,并且以一定比例成为引领蜂,引领蜂携带蜜源信息通过摇摆舞与其他蜜蜂分享这些信息;待工蜂:表示等待寻找蜜源采集的蜜蜂,他们可以分为两种,侦察蜂和追随蜂,侦查蜂搜索蜂巢附件的新蜜源,追随蜂在蜂巢内等待,通过分享采蜜蜂的信息, 寻找蜜源。
2.2 人工蜂群算法的步骤
在ABC算法中,将蜜源的位置抽象为解空间中的点,即待求解问题的可行解。蜜源i的质量用收益度fit表示,np为蜜源的数量。ABC算法中引领蜂和待工蜂各占蜂群的一半,且同一时刻下同一蜜源中只有一只引领蜂采蜜[11]。
a. 设求解问题的维度为D,蜜源i的位置表示为X,其中,t为当前的迭代次数。蜜源的初始位置根据式(12)在搜索空间中随机产生。

式中:xij代表第i个蜜源xi的第j维度值,i取值{1, 2, ···,sn},j取值{1, 2, ···,d};xmax,ij和xmin,ij分别为维度j的最大值和最小值。
初始化蜜源就是对每个蜜源的所在维度通过式(12)选取一个随机值。
b. 引领蜂阶段,在引领蜂阶段,引领蜂用式(13)更新新蜜源。

式中:xkj代表领域蜜源,k取值{1,2, ···,sn},且k不等于i;φ为取值在[-1, 1]之间的随机数。
通过式(13)更新得到新蜜源,再借助贪婪算法的原则,比较更新前、后的蜜源适应度值,选择最优者。
c. 追随蜂阶段,引领蜂搜索结束后,追随蜂开始搜索,在这一阶段,在舞蹈区接受引领蜂分享的蜜源信息,追随蜂采用轮盘赌策略来选择其所追随的引领蜂。为了保证适应度更高的个体可以得到保留。同时对每个蜜源设置参数R,当蜜源更新后被保留,R为0;反之,则R加1。从而记录一个蜜源没有被更新的次数。
d. 侦察蜂阶段。如果一个蜜源经过多次开采后,R值过高,并且超过了设定的阈值T,则需要放弃这个蜜源,同时进入侦察蜂阶段。这一阶段,侦察蜂利用式(12)随机寻找新的蜜源,以代替被抛弃的蜜源。
e. 评估所有蜜蜂搜索得到食物源的适应度并进行排序,进行下一次迭代。
2.3 改进人工蜂群算法
基本的人工蜂群算法是为解决连续空间的问题而设计,解是由蜜蜂在蜜源附近搜索生成的,通常都是在一个连续的范围空间。但是,在处理调度安排、选址方案等离散型问题时,蜜蜂的邻域搜索从连续变为离散,这就使得算法原来的公式不再有效。为了使这一算法可以应用在离散问题上,本文基于人工蜂群算法的基本原理以及相关研究[12],依照本文模型对公式进行改进,以适应离散化的选址模型,提出了改进的离散人工蜂群算法(new discrete artificial bee colony algorithm,NDABC),使得人工蜂群算法在保留原有并行性的优点下,对离散问题也有良好的适应性。同时也对其他算法的研究提供思路。
a. 个体编码。建立蜜蜂个体的编码形式是选址方案表示的关键,本文构建的工厂选址问题主要包括两方面:每个备选点是否被选中和每个需求点和备选点的对应关系。本文将备选点按位置进行排序,设定标号(1, 2, ···,m),需求点同样是按位置排序后形成一列n个元素的数列。
例如,有8个需求点,4个备选点,在4个备选点中选取2个位置作为工厂位置,解X为:

其中,X表示在4个备选位置中选取3和1号位置,3号位置为需求点1,3,4,6服务,1号位置为需求点2,5,7,8服务。
b. 初始化种群。作为整个算法计算的起点,优秀的起点可以更好地将蜜蜂分散在可行解中。为了更好地让蜜蜂分布在可行范围内,初始解采用随机生成的办法。备选点的选址数量和位置采用随机生成方式,以扩大选址方案。在确定备选位置后,随机在备选位置上分配需求点,并且将选址位置的方案作为蜜源,保证在初始生成的种群中个体分布在不同蜜源上。
为了保证蜜蜂群体的随机搜索能力,在蜜蜂群每次迭代更新中将群体的一小部分待工蜂作为侦察蜂。通过数据实验发现,根据适应度值进行排序后的45%个体作为追随蜂;选取总体种群中5%的个体作为侦察蜂。这种比例分配可以达到较好的优化效果,保证进行随机搜索,防止陷入局部最优。
c. 蜜蜂更新规则。
针对每一个个体都在自身的蜜源内进行搜索更新,本文参考了文献[13]的更新策略,提出了一种多方式的领域更新策略。其中,包括3种领域更新策略:领域交换更新策略,记作U1,在待更新个体中随机选取2个位置,并交换其值;领域插入更新策略,记作U2,在该更新个体中随机选取2个位置,插入1个备选位置的序号,后面的元素依次后延;领域内倒转更新策略,记作U3,待更新个体中随机选取2个位置,将2个位置间的位置进行倒置更新。表1列出各策略的具体示例。

表1 蜜蜂领域更新策略Tab.1 Strategy of bee field renewal
d. 观察蜂更新策略。
在人工蜂群算法中追随蜂是在所追随的采蜜蜂的蜜源附近进行搜索采蜜,所以,使用式(13)确定观察蜂的蜜源Y=[ya,yb, ···],其中,a,b表示备选位置的编号,Sf(i)表示在整个选址方案中选取备选位置i所产生的成本,同时保留其追随的采蜜蜂的选址策略。

e. 追随更新。在传统蜂群算法中,蜜蜂是在不同蜜源间进行搜索,针对选址问题,首先将工厂位置按照地理位置进行排序,将选址方案中的备选点位置作为蜜源。因此,追随蜂则会在所追随的选址方案中随机地在选取位置的前后进行变化,以模拟追随蜂在蜜源附近搜索的行为。当追随蜂表示的备选点确定后,则开始进行备选点与需求点间的对应。其中,更新原则按照上文的更新策略进行更新。
f. 侦察蜂更新策略。总体种群中选取总量5%的个体作为侦察蜂,进行随机搜索,以广大搜索范围,防止陷入局部最优。
g. 局部搜索。在传统人工蜂群算法中,为了防止单个蜜蜂多次在同一蜜源进行搜索,设置了最大搜索次数,在本算法中为了进一步扩大算法的搜索范围,防止陷入局部最优。每个蜜蜂个体均在个体更新过程中更新R次,保留R次中适应度值最大的个体。
h. 选择策略。采取类锦标赛,根据模型实际情况,与传统锦标赛算法中选择策略不同,本策略中在采蜜蜂个体中随机选择n个个体,找出这n个个体中的最大值,作为观察蜂的追随个体。这样可以扩大随机搜索方位,提高算法的搜索能力。
2.4 算法过程
a. 初始化蜜蜂种群,初始时刻所有蜜蜂都是侦察蜂,全局搜索蜜源并计算收益度;
b. 对步骤a中所有蜜蜂根据收益度的相对大小,蜜蜂转化为采蜜蜂(收益度靠前)和观察蜂,观察蜂根据采蜜蜂的舞蹈来接收招募;
c. 每个采蜜蜂都会在原蜜源附近采蜜(局部搜索);
d. 观察蜂按照蜜源以一定概率选择蜜源,并在附近局部搜索;
e. 采蜜蜂和观察蜂都在其蜜源附近使用局部搜索策略,保留最优的个体,进入下一次更新;
f. 记录当前所有蜜蜂找到的最优蜜源,执行步骤b。直至算法迭代结束。
3 仿真实验与分析
为了验证改进算法的有效性,以及模型的可行性,由于真实数据难以获取,本文通过模拟文献[14]的数据进行仿真实验。依照文献[14]的数据特征,通过Matlab在其基础上模拟生成更大规模的数据,保证算例可以更好地模拟实际环境并能更好地验证算法和模型。本文中备选点为20个,需求点为150,每个备选点可分为4阶段的生产规模,每阶段的单位生产成本为[16,14,12,10](元/万件),数据如表2所示。对每个需求点记录近5年的需求,如表3所示。
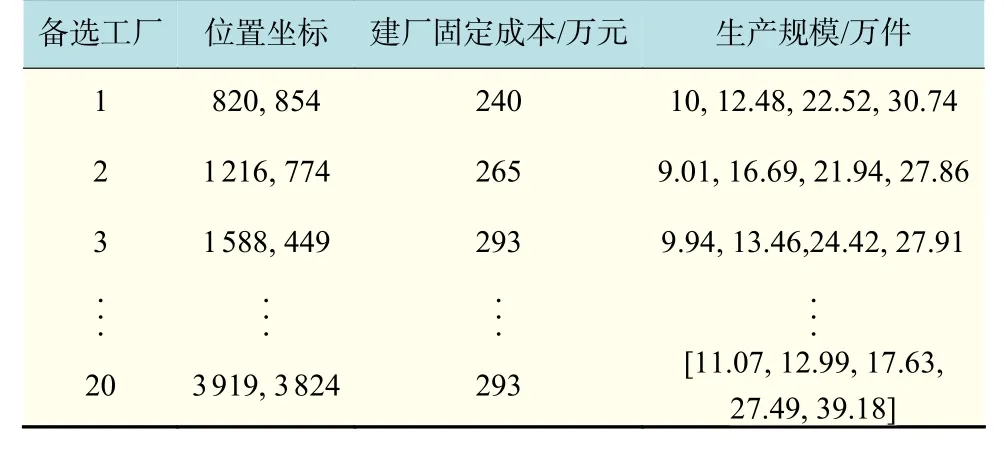
表2 备选工厂位置参数Tab.2 Alternative plant location parameters
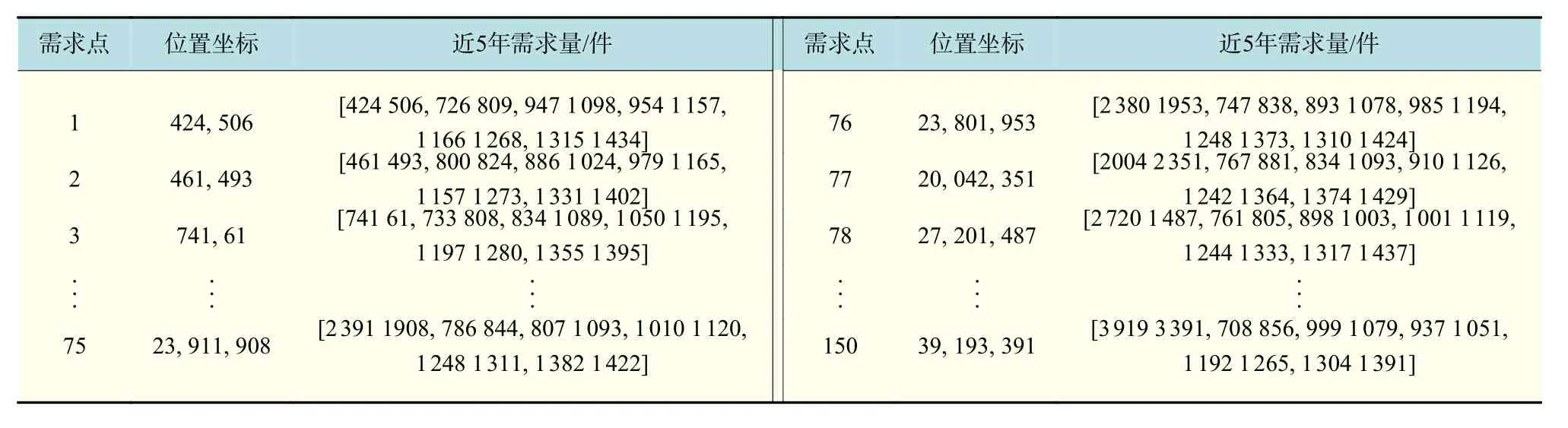
表3 需求点位置参数Tab.3 Location parameters of demand points
为了方便对比不同算法的迭代效果,本文加大了文中算法的迭代次数,减少群体的规模数量。保证得到更明细的算法优化结果曲线。因此,改进蜂群算法参数设置:初始种群个体数为40,迭代500次。同时通过遗传算法(genetic algorithm, GA)、粒子群算法(particle swarm optimization, PSO)、海鸥算法(seagull optimization algorithm, SOA)和文献[15]提出的改进萤火虫算法(firefly algorithm, FA)作为对比组,改进蜂群算法参数设置:初始种群个体数为40,迭代500次;遗传算法的初始种群为40,迭代500次,采用单点交叉和单点变异,其中交叉概率为0.5,变异概率为0.05;粒子群算法的初始种群为40,最大迭代次数500次,惯性因子为0.6,C1=C2=2,C1,C2为学习因子;萤火虫算法的初始种群为40,迭代500次,其中,移动概率0.7,变异概率0.1。海鸥算法的初始种群为40,最大迭代次数为500次,控制因子Fk的值从2线性降低到0。分别对每个算法进行20次独立计算后对比每种算法的平均值和标准差。每个需求点近5年的需求量使用式(10)和式(11)进行预测,将其代入算法中进行计算。选址工厂数为2。计算后算法迭代如图1所示。

图1 不同算法迭代对比图Fig.1 Iterative comparison of different algorithms
根据图1结果分析,本文算法相较于其他算法在迭代中不仅种群整体更新,而且加入了防止陷入局部最优的自身更新,由此提高了搜索效率,能够快速稳定地得到最优解,迭代次数远小于其他算法,收敛速度有了明显的提高。另外,从表4中也可以看出,相对其他4种算法,本文提出的改进的人工蜂群算法,在20次独立计算的平均值以及标准差明显优于其他算法。在选址方案中,本文算法并结合其他算法得出的方案,1号位置及附近和12号位置及附近都是选址方案中较优的位置。本文提出的算法得到的选址方案刚好选择1号和12号位置,并且在几种算法对比中得到最优的总成本。根据备选工厂的数据可以看出,12号位置的生产规模比1号位置更大。本文的方案12号位置相对1号位置服务更多的需求点,可以更好地满足需求点的需求。最后结合实际分析选址位置可以看出,本文算法所选的工厂位置更加分散,有利于实际情况下工厂的发展。
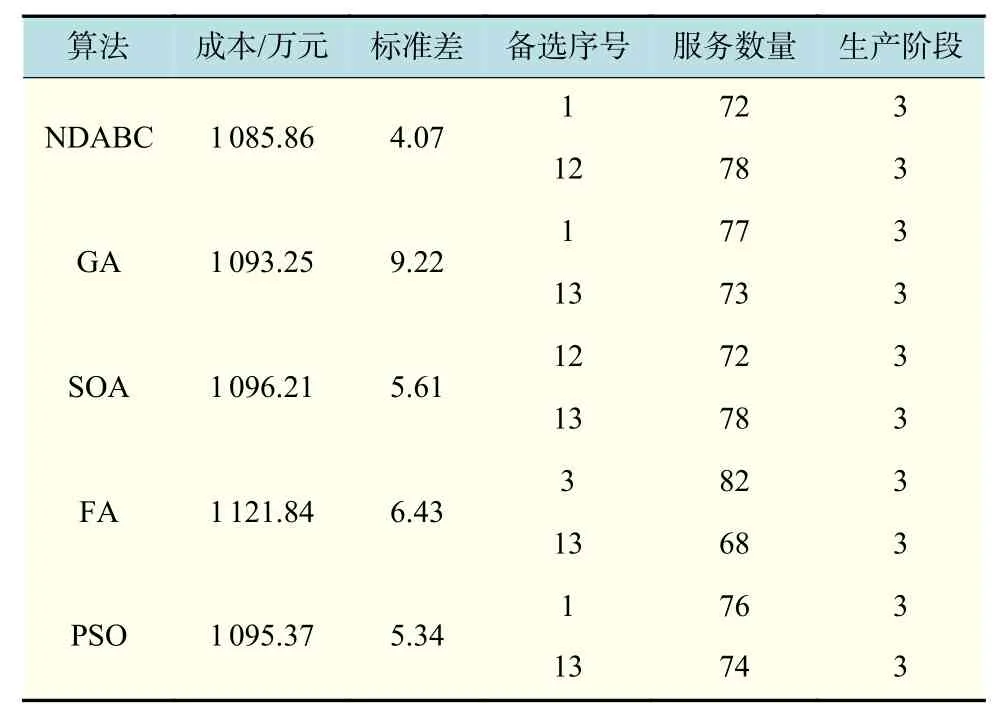
表4 不同算法计算结果对比Tab.4 Comparison of calculation results of different algorithms
在验证了改进算法有效后,对模型本身进行深入分析。开始考虑改变容量限制工厂选址模型的选址数量对整个选址模型的影响,对于本文的工厂选址问题模型选址位置不易过多,因此,仅分别求解选址数量N=2,3,4这3种情况,每种情况独立运行20次,计算20次的平均值、标准差以及迭代情况,运行结果如表5和图2所示。
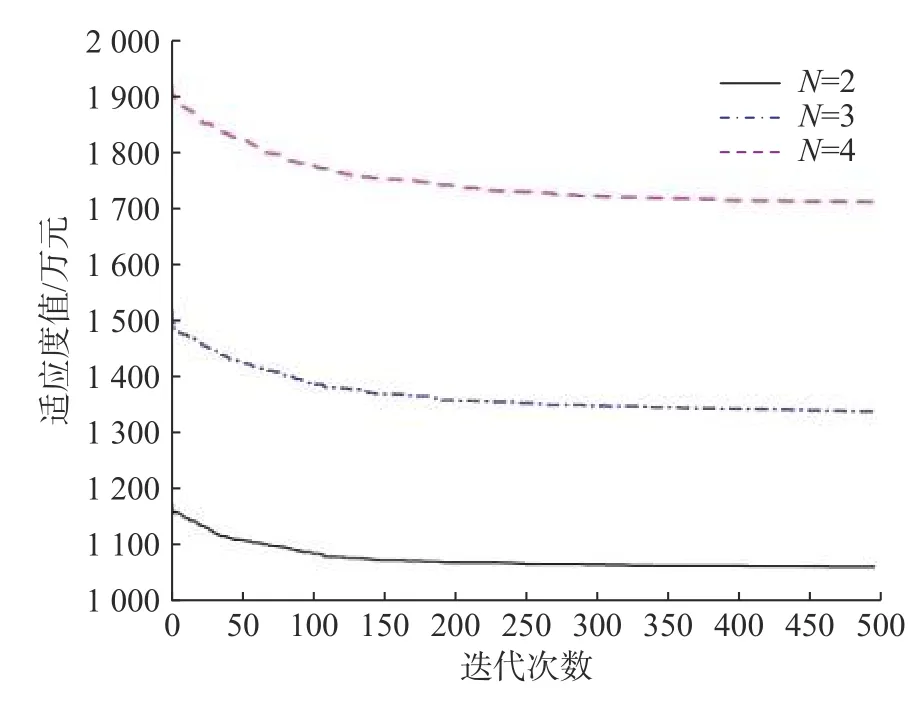
图2 不同工厂选址数量的迭代曲线图Fig. 2 Iterative curve of different numbers of plant sites
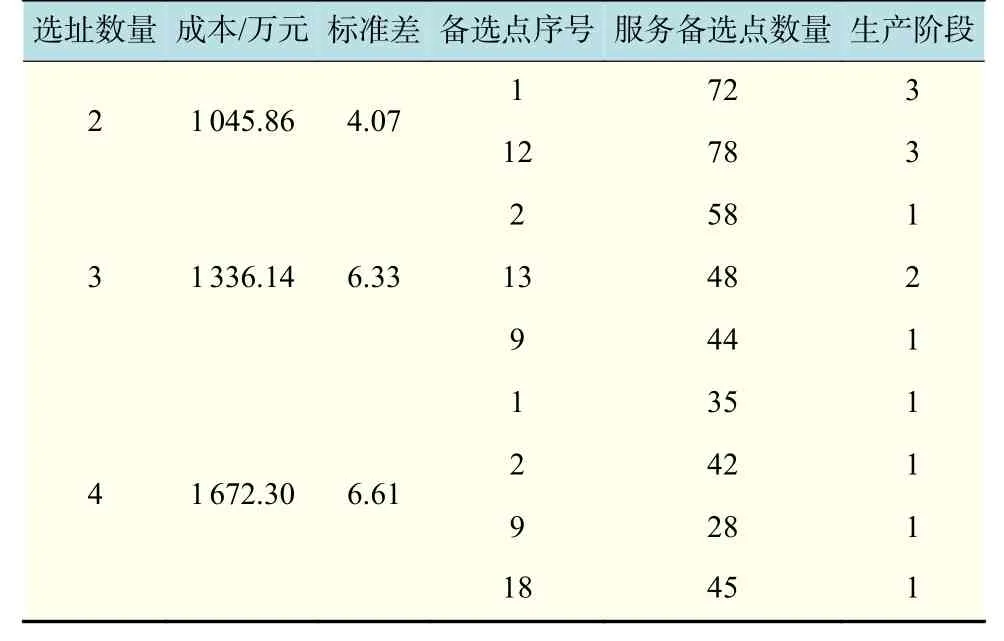
表5 不同选址数量下选址模型结果对比Tab.5 Comparison of location model results under different location numbers
通过分析不同选址数量的选址方案结果得出,当N=2时,即仅选择2个备选位置作为工厂位置,得到的成本最小,所选择的工厂的位置趋近于中心位置,其生产规模更大,服务需求点的数量更多,每个备选位置的后续扩建能力较差;而当N=3时,选择3个备选位置产生的成本相对2个备选位置有所增加,工厂有选择更小的生产规模的情况,可以兼顾后续需求增加后的扩建需求;最后N=4时,整个模型的选址策略所需的总成本最大,工厂的位置相比较其他策略更加分散,备选工厂仅需要选择最小的生产规模就可以满足需求。因此,如果选址方案的目标是追求低成本,那么可以选择更少的选址数量,以达到更低的选址方案成本。但是,如果为了后续的发展以及更大程度地满足需求的不断增长,可以在选址方案中适当增加选址数量,以满足后续发展中需求的增加以及服务尚未发掘的潜在需求点。
最后在选址位置上分析,3种不同选址数量的方案中均选择到了2号位置附近、9号位置和12号位置附近。由此分析可得,这3个位置是后续选址决策中可以重点考虑分析的位置,为后续的选址方案提供参考。
4 结束语
分析了现有容量限制选址问题中缺少对需求不确定性考虑和容量限制约束多为固定值这两部分。同时将这两部分因素加入容量限制选址模型中,用联系数和区间灰数将不确定的需求转化为固定值以及将固定的容量限制约束设置为分阶段,建立了全新的容量限制选址模型。并且采用了针对模型的特征而改进的人工蜂群算法对模型进行求解。通过与其他算法对比,验证了算法在此类问题上更加高效。但本文的研究仅为单一产品,下一步可以拓展为多种产品下的选址问题。
