基于强化学习的集群多目标分配与智能决策方法
2021-11-01朱建文赵长见李小平包为民
朱建文, 赵长见, 李小平, 包为民,3
(1.西安电子科技大学 空间科学与技术学院, 陕西 西安 710126; 2.中国运载火箭技术研究院, 北京 100076;3.中国航天科技集团有限公司, 北京 100048)
0 引言
随着导弹信息化与体系化能力的提升,其攻击模式由单一攻防作战拓展到多对多的群体协同对抗与博弈。多弹协同攻击能够充分利用分散的作战资源以及信息共享,是提升打击能力与突防能力的有效途径。针对多目标的分配与决策直接决定着体系的攻防性能,是协同攻击的关键技术之一[1]。
多目标决策与分配需要根据实时的攻防态势,对集群中的每个成员参与攻击与否进行决断,并分配合理的待攻击目标。攻防性能评估是目标分配的基础条件,可利用弹目相对运动信息来评估制导的难易程度以及攻击性能,而目标的威胁度可基于自身价值与运动特性来评估[2-3]。集群决策与分配是一个以攻防性能评估结果为模型、以攻防性能最大为性能指标的寻优过程[3]。倾向性和主观性是集群攻防性评估不可避免的因素,为此刘树衎等[4]综合利用专家系统与神经网络构建行为决策基础模型,进而建立智能指挥系统以优化目标分配。另一种典型方法是将分配问题转换为数学规划问题,进而利用枚举法、分支界定法或整数规划来求解[5-6]。然而,随着攻防双方规模的增加,寻优的复杂度会急剧增大,导致计算耗时呈指数型增长[7]。因此,具有灵活性、自适应能力强以及计算相对简单的智能优化方法,在求解复杂多目标决策与分配中具有较大的优势,遗传算法与粒子群优化(PSO)算法为其典型代表[8]。PSO算法利用种群中个体运动位置和整体最优位置的记忆与学习,在解空间中朝着最优的方向运动,该算法相对于遗传算法具有更高的计算效率,但其精细程度与全局搜索能力不足[9-10]。
高动态的集群攻防为决策的最优性与实效性提出了极高的需求,其复杂多变的攻防态势需要进行多次在线决策与分配。上述优化方法在计算效率、全局最优性以及多次决策的继承性上存在不足。集群决策与目标分配中能够影响攻防性能的分配矩阵是离散的,而且多目标决策与分配满足马尔可夫决策过程[9]。本文利用强化学习对集群攻击的导弹选取以及目标分配矩阵进行决策判断,具体包含攻防性能评估、非线性攻防效费比指标构建、强化学习框架的搭建、离散化动作空间、状态空间以及奖励函数的设计。
1 综合攻击性能评估
以多发导弹对地球表面运动的目标群进行协同攻击为背景,对其攻击性能进行评估。多对多的攻防态势包括导弹自身的攻击优势度以及目标的威胁度[3]。在攻击优势度中,主要考虑弹目相对角度、距离以及速度的优势模型;目标的威胁度可基于固有特性与运动信息来评估。
1.1 基于相对运动信息的攻击优势度评估
1.1.1 攻击角度优势度评估
由于导弹在攻击目标时需要满足速度倾角约束并消除航向误差,攻击角度优势度评估需要综合考虑速度倾角与方位角。在纵向通道,当实时速度倾角与终端约束相等时,制导越容易实现,意味着攻击优势度随角度差的减小而增大。在侧向通道,导弹制导的主要目标为消除航向误差Δσ,因此该误差的绝对值越大,制导任务越艰巨。相反地,若Δσ=0,则导弹对该目标的优势最大。因此,可构造角度优势模型为
(1)
式中:θ为速度倾角;θf为终端速度倾角约束;σ为速度方位角;σLOS为视线方位角;SMθ与SMσ分别为基于速度倾角θ与方位角σ的攻击优势度。
1.1.2 相对距离优势度评估
导弹与目标之间的距离必然影响制导指令的生成与打击目标的实现,当距离过近时导弹的反应时间太短,为制导指令的执行带来了巨大压力。相反,当距离太远时导弹的探测精度受到不良影响,并且过大的能量损耗也将影响打击任务的完成。因此,相对距离的优势模型可构造为
(2)
式中:SMr为基于弹目距离的攻击优势度;r为弹目距离;R0为综合考虑探测能力与机动能力而确定的距离。(2)式中基于距离优势度评估的物理意义为:当导弹与目标的距离为R0时优势最强;弹目距离与R0相差越大,则优势越弱。
1.1.3 攻击过载优势度评估
由于导弹的机动与控制能力直接体现在可用过载上,并且过载能够同时包含弹目相对角度、距离以及速度大小。因此,本文进一步引入过载为变量,以表征导弹对不同目标的优势度。具体方法如下:基于导弹当前的飞行状态与目标信息,采用最优制导方法计算导弹在侧向的需要过载指令。过载指令越大,意味着待飞时间越短、打击任务更加艰巨,过大的过载指令将超过导弹的控制能力,导致打击任务失败。越小的过载指令意味着越小的控制能力需求以及更加平直的弹道,但是平直的弹道将降低突防性能。因此,基于过载的优势模型为
(3)
式中:SMn为基于过载的攻击优势度;n为过载;n0为基于控制能力确定的过载基准量,n0>0g.
1.2 基于目标固有信息的威胁度评估
目标群中不同目标具有不同的战略价值与威胁程度,对于重要目标应当分配更多的导弹进行打击,以增强打击效果。本文考虑了易于获取的目标体积信息与速度信息作为威胁度评估的标准,体积代表弹载量与威胁度,速度表示目标的动力与机动性能,进一步将二者加权平均以综合评估目标威胁度,用于后续的目标分配。
1.2.1 目标体积威胁度评估
不同体积的目标具有不同的作战性能以及威胁程度,目标体积越大,则受威胁程度越大。因此,基于体积信息的目标威胁模型可构建为
(4)
式中:SΓt为基于体积的目标威胁度;Γtj为第j个目标的体积大小;Nt为目标的数量。目标体积威胁模型(4)式的物理意义为:获取所有目标的体积,则第j个目标的威胁度可用其在整个目标群中的体积占比来表述。
1.2.2 目标速度威胁度评估
目标的航行速度对其威胁程度存在较大影响。目标的机动性能随速度的增大而增大,但由于目标动力性能的限制,过大的速度意味着目标在体积与质量上存在不足。因此基于速度信息的威胁模型为
(5)
式中:Svt为基于速度的目标威胁度;vt为目标的实际航行速度;vt0为预先设定的速度。目标速度威胁模型(5)式的物理意义为:当目标速度为vt0时,越具有威胁性,过大或过小的速度都将降低威胁度。
1.3 综合攻击优势度评估
基于攻击优势模型与目标威胁模型,可建立用于目标分配的综合攻击优势度模型如下:
S=Sa+St,
(6)
式中:Sa为攻击优势度模型,
(7)
kθ、kσ、kr、kn为加权系数,不同参数设置对应不同的重要程度;St为基于目标体积与速度的威胁度模型,
(8)
kΓ、kv分别为体积与速度的加权系数。针对上述模型,需要给出以下3点说明:
1)不同加权系数意味着不同的关注度,可根据具体攻击任务进行设计;
2)针对不同目标需要考虑的因素存在差异,该模型主要针对地球表面航行的大型目标群;
3)除上述威胁模型外,还可根据需要考虑目标电磁辐射情况、预设目标的重要程度以及其他能够反映目标特性的重要因素。
2 攻防一体性能指标构建
多目标分配与决策需要以综合攻击优势度S为基础,通过优化方法获得分配矩阵X,实现攻击性能的最大化。首先,只考虑导弹运动信息与目标固有信息建立如下线性攻击性能指标:
(9)
式中:Jl,a为攻击性能指标;NM与NT为导弹与目标的数量;Sij为导弹i对目标j的量化综合攻击优势度;Xij为导弹群对目标群分配矩阵中的元素。评估模型(6)式与性能指标(9)式构成了典型的整数规划问题,可利用内点法等方法进行寻优求解[6]。
进一步考虑导弹的突防概率,建立目标的毁伤性能指标:
(10)
式中:Jo,d为毁伤性能指标;Stj为第j个目标的价值;Pij为导弹i对目标j的突防概率(0~1之间取值)。另外,导弹攻击必然造成导弹的消耗,因此导弹协同攻击的成本指标为
(11)
式中:Jc为导弹消耗指标;ci为导弹i的成本。综合考虑Jl,a、Jo,d以及Jc,则可得协同攻击的综合效费性能指标为
maxJt=[Jl,a,Jo,d,Jc].
(12)
指标(12)式的目的是获得最大的效费比,但其中包含两个相互矛盾的性能指标:Jl,a与Jo,d的目标是获得最大的攻击与毁伤性能,Jc的目标是获得最小的攻击成本。因此,进一步引入效费比来描述单一导弹的效能,将(12)式中的两个性能指标进行整合,进而利用整合之后的单一性能指标进行优化设计。其中:
攻击效费比指标Ja为
(13)
毁伤效费比指标Jd为
(14)
攻防效费比指标Jt为
(15)
性能指标(15)式的物理意义为:基于矩阵形式的综合攻击优势度S、突防概率Pij以及导弹的成本ci,确定相同维度的分配矩阵X,使得性能指标(15)式即攻防效费比最大。在协同攻击的多目标分配与决策过程中,必须满足的约束模型为
(16)
约束模型(16)式的物理意义为:目标分配结果以分配矩阵的形式表征,被攻击的目标标记为1,否则标记为0,即目标分配矩阵X的元素只能够是{0,1}中的某一值。由于每一发导弹最多只能攻击一个目标,矩阵中的每一行元素数值之和必为1.另外,需要保证每一个目标至少分配1发导弹进行攻击,并且目标分配矩阵中每一列元素之和不小于1,且分配至某一目标的导弹数量最多为Tj.
3 基于强化学习的多目标分配
性能指标(15)式是严格的非线性方程,本文利用强化学习方法实现多目标的智能分配。强化学习又称再励学习、评价学习或增强学习,该方法需要智能体与环境进行反复信息交互,通过学习策略或规则实现回报或指标的最优化[11]。
3.1 强化学习与Q-Learning逻辑
强化学习是一种试探、评价与更新的过程,智能体选择一个动作作用于环境,环境在执行完动作之后产生回报(奖励)信号发送至智能体,该信号包含对动作的定量评价;不同的动作对应不同的奖励值,智能体在接收回报信号之后,选择下一动作以获得更大的奖励[12]。
强化学习是迭代优化的过程,包含值迭代与策略迭代。Q-Learning是强化学习最常用的值函数迭代更新方法,设Q(s,a)为状态行为值函数,其物理意义为在当前策略π下,当前状态s与动作a对应值函数的具体取值[13]。若状态集合为p维、动作集合为q维,则Q(s,a)为p×q维表格,因此可称之为Q表。Q-Learning中值函数的更新方法[14]为
(17)
式中:α为值函数迭代的校正系数;γ为折扣系数;R与s′分别为执行当前动作获得的回报值与下一时刻的状态。
具体的Q-Learning方法步骤[15]如下:
步骤1人为初始化Q(s,a)表格。
步骤2对于每次学习训练,给定一个初始状态s.
步骤3执行以下操作:
①利用当前的Q值,依据策略π,确定当前的行为a;
②执行当前的行为a,获得量化的回报R与下一状态s′;
③根据(17)式更新Q表;
④更新当前的状态s←s′;
⑤当状态满足终止状态时,结束当前回合的学习。
步骤4基于已更新的Q表,重复执行步骤3,直至满足学习次数。
3.2 基于Q-Learning的多目标分配
在多目标分配与决策中,不同形式的0-1分配矩阵对应不同的攻防效费比。由于攻防性能只与当前和未来分配矩阵相关,而与过去的信息无关,因此集群决策与分配矩阵的确定符合马尔可夫决策过程。根据强化学习与Q-Learning方法的需求,需要根据实际优化任务对搭建智能分配模型,设计状态与动作空间以及回报函数,并利用典型的ε-greedy学习策略以探索更多的动作[16]。基于Q-Learning算法的多目标智能分配流程如图1所示。

图1 Q-Learning智能决策迭代计算流程Fig.1 Iterative calculation of intelligent decision by Q-Learning method
图1给出了多目标智能分配的流程,其核心步骤为行为策略、动作空间、状态空间以及奖励函数的设计。
3.2.1 行为策略设计
采用ε-greedy策略实现多目标分配。为了充分发挥强化学习的探索和寻优能力,利用随机方法对Q表进行初始化,在学习前期ε可选择较大,以探索更多的状态与动作;在学习后期ε逐渐减小,以使得目标分配在已有经验基础上做出正确的动作。
3.2.2 动作空间设计
根据强化学习中对动作空间的定义,动作需要对上述状态产生影响。过于复杂的动作空间将增大动作的搜索空间,进而影响学习效率。针对该问题,设计动作为能够直接影响飞攻防性能的目标分配情况,本文称为分配向量。分配向量中,某一个具体动作ai表示导弹选择目标i,即行向量表示的动作ai中,第i个元素为1,其余都为0.若存在NT个目标,则存在NT个具体动作,意味着动作空间为NT维。
(18)式给出了NT维的动作空间,选择第1个目标的动作1为a1=[1 0 … 0],相应地选择第2个目标的动作2为a2=[0 1 … 0],以此类推。
(18)
3.2.3 状态空间设计
状态空间是强化学习中必不可少的部分,是反映当前状态或者终端状态的数据集合,并且必须包含所有可能的状态参数取值。本文设计状态空间为量化攻防效费比评估值组成的数据集合,基于性能指标(15)式构建攻防效费比函数为
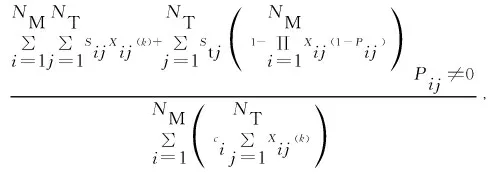
(19)


(20)
进一步将状态范围(20)式离散为等间隔的状态空间,进而获得目标分配的状态空间。
3.2.4 回报函数设计
量化的回报函数用来判断动作的性能,是强化学习的核心。在目标分配中,利用强化学习方法确定分配矩阵以获得最优的攻防性能。因此根据分配需求,设计回报函数如下:
(21)
(21)式中回报函数的物理意义是:当某一动作即目标分配矩阵满足所有攻击约束时,回报函数值为实际攻防量化值与最大值1.2倍的差。当不满足攻击约束即某一导弹分配了多个目标,或者某一目标未分配到导弹时,给予-5的回报值。
4 多目标决策仿真验证
采用数值仿真的方法对多目标智能分配与决策进行验证。在攻击优势度评估中,设置距离优势模型中的R0=100 km,过载优势模型中的n0=1g,各项的加权系数分别为:kθ=0.2,kσ=0.2,kr=0.2,kn=0.4.在目标威胁建模中,设置(5)式中的vt0=20 m/s,3个目标的速度分别为vtA=25 m/s、vtB=22 m/s 和vtC=20 m/s,归一化后的体积分别为ΓtA=1、ΓtA=1.2和ΓtA=1.5,加权系数为kΓ=0.6、kv=0.4.各发导弹属于同一类型,即c=1.
在强化学习中γ=0.2,采用ε-greedy策略实现决策目标,学习次数NQ-Learning的范围为1~1 000,时变参数ε=exp(-NQ-Learning/100)。参数ε设置的目的是:在学习前期更大地探索新的动作,在后期则保证学习的最优性。
4.1 导弹数量固定的智能分配
设置6发导弹攻击3个目标,各导弹对目标的量化综合攻击优势度以及突防概率如表1所示。从表1中可见,第1发导弹M1对目标B最具有优势,对目标C最无优势。
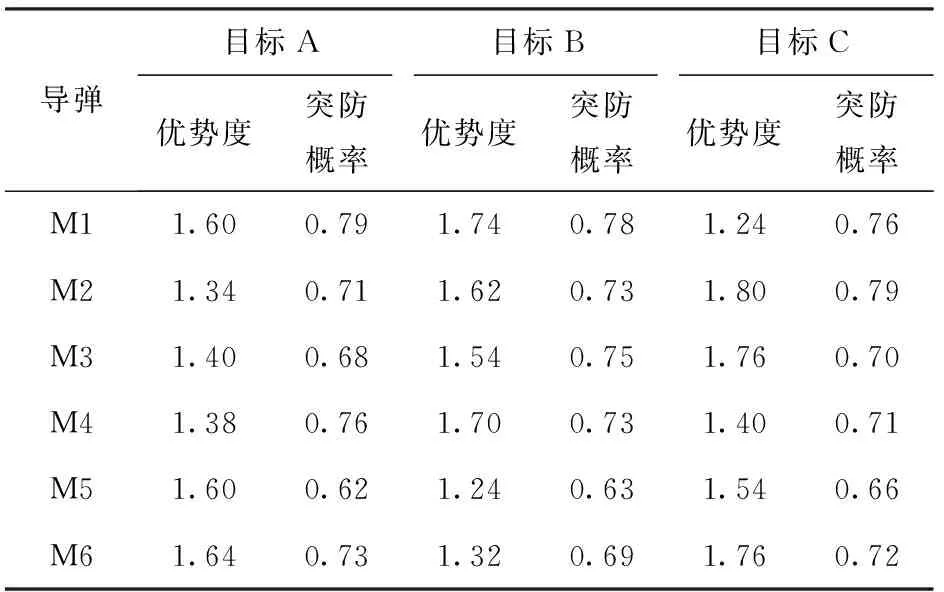
表1 各导弹对目标的量化综合攻击优势度与突防概率
选择表1中前4发导弹M1、M2、M3、M4攻击3个目标,利用本文研究的强化学习方法实现目标分配,目标分配矩阵为
(22)
由(22)式可知,慢速航行的大目标C具有较大的威胁度,因此分配矩阵中X12=1,X23=1,X33=1,X41=1,即导弹M2与M3都用于攻击目标C,以增强整体攻防性能。随着导弹的飞行,每间隔1 s,共进行10次目标分配,以充分验证智能方法的有效性,其中第1次与第2次分配的Q-Learning主要结果如图2、图3所示。由仿真结果可知,由于第1次学习采用随机方法对动作以及Q表进行初始化,因此迭代次数较多,在大约600次学习之后才得以收敛,综合效费比指标Jt为1.735 6. 第2次学习继承了上一次学习获得的Q表,该表已经包含了优良动的动作信息与回报值,因此迭代次数与收敛速率都有大幅度改进。在经过上百次学习迭代后,Q-Learning能够精确收敛。

图2 前两次分配的累计回报值Fig.2 Cumulative reward values of the first two assignments

图3 前两次分配的迭代次数Fig.3 Iteration steps of the first two assignments
在导弹飞行过程中,每间隔1 s,分别采用强化学习与PSO算法实现多目标分配,两种方法的耗时与指标结果如表2所示(i7 8550处理器,1.99 GHz, MATLAB 2016b仿真环境)。由表2可知,强化学习与PSO算法都可实现多目标的自主分配,最终的综合效费比指标完全相同。然而,两种方法在计算耗时上存在一定差异,初次分配时强化学习方法耗时较长,而后续分配PSO算法耗时较长。对于初次分配,强化学习方法采用随机方法进行初始化并探索更多的动作,因此耗时较长。在后续分配过程中,强化学习能够继承初次分配的结果,而PSO算法都需要由相同的初始状态出发进行寻优,因此强化学习耗时更短,效率更高。

表2 强化学习方法与PSO算法性能对比
4.2 导弹数量可变的智能决策
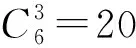

表3 协同攻击方案与分组
表3中42种攻击分组情况下的攻防性能指标与效费比指标如图4~图9所示。由图4可知,当不考虑攻击成本时,攻击导弹越多,则攻击与毁伤性能越强。当考虑攻击成本时效费比性能存在较大差异:图5中攻击效费比Ja在第38号编组时达到最大,此时分配5发导弹M1、M2、M3、M4、M6攻击3个目标;图7中毁伤效费比Jd总体上随着数量的增多而减小;图9中,综合考虑攻击与毁伤性能的攻防效费比Jt在第23号编组时达到最大,此时需要分配导弹M1、M2、M3、M6攻击目标,相应的目标分配矩阵为
(23)
(23)式中X12=1,X23=1,X33=1,X61=1,其余元素均为0,对应的物理意义是:导弹M1攻击目标B,M2与M3都用于攻击目标C,M6攻击目标A,量化攻防效费比指标为1.756.

图4 攻击性能指标Jl,aFig.4 Attack performance index J l,a

图5 攻击效费比指标JaFig.5 Attack cost-effectiveness ratio index Ja

图6 毁伤性能指标Jo,dFig.6 Damage performance index Jo,d

图7 毁伤效费比指标JdFig.7 Damage cost-effectiveness ratio index Jd
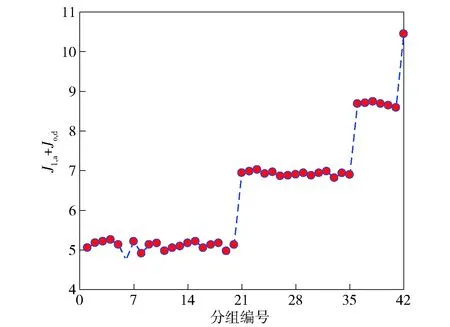
图8 攻防性能指标Jl,a+Jo,dFig.8 Attack-defense performance index Jl,a+Jo,d

图9 攻防效费比指标JtFig.9 Attack-defense cost-effectiveness ratio index Jt
5 结论
本文采用强化学习方法研究了复杂多变且高动态环境下多目标协同攻击智能决策方法,建立了攻防性能评估准则,包括基于相对运动信息的攻击优势度评估以及基于目标固有信息的威胁度评估。综合攻击性能、毁伤性能以及攻击消耗,设计了攻防效费比性能指标。构建了基于强化学习的多目标决策架构,设计了目标分配的动作空间与状态空间,利用Q-Learning方法对协同攻击方案,包括导弹的数量、分组选取以及目标分配进行了智能决策。得出以下主要结论:
1)基于相对运动信息与目标固有信息,可实现对攻击优势度与目标威胁度的评估,结合突防概率模型,可构建攻防效费比指标模型。
2)多目标协同攻击的目标是使得攻防性能最优化,攻击导弹的选取以及目标分配的决策结果与性能指标以及决策模型密切相关。
3)强化学习能够用于协同攻击中多目标的在线决策与分配,与PSO算法相比,其计算效率在非初次决策中具有更明显的优势。
本文研究的是一种基于强化学习的基础性、通用性的目标分配与智能决策方法。只需要建立矩阵形式的分配模型,便可利用该方法进行分配与决策。
