基于生成对抗网络的唇形重建改进方法
2021-10-29毛志炜朱铮宇
◆毛志炜 朱铮宇
基于生成对抗网络的唇形重建改进方法
◆毛志炜 朱铮宇通讯作者
(广东技术师范大学电子与信息学院 广东 510665)
在视觉语音识别(Visual Speech Recognition,VSR)研究领域,已有的研究表明,基于正面的视图语音识别率是非常高的。而用于视觉研究的额叶面语料库很少。一方面,研究者从非正面视图(尤其是大角度)尝试提高视觉语音的识别效率;另一方面,研究者试图找到解决在现实场景下难以获取正面视图而从非正面视图进行重构正面视图的方法。本文就是基于第二种方案,基于生成对抗网络(GAN)强大的图像生成能力,对多角度视觉库中唇部进行正面视图重建。本文模型采用了U-Net网络结构,添加身份一致性损失Lid,在重构正面唇形的同时,保留了身份特征。
视觉语音识别(VSR);GAN;U-Net;图像重建;身份损失
1 研究背景
语音识别作为人工智能领域重要的一类,近些年发展非常迅猛。而视觉唇读语音识别也是其中的研究热门。我国语音技术发展相对于发达国家来说还不够完善,尤其是视觉语音识别方便的研究相对甚少。缺少合适的语音视听研究语料库是存在的突出问题。
近些年,随着硬件水平的提高,也带动了深度学习领域飞速发展。深度学习成了继人工智能、大数据又一热门的词汇。在深度学习领域,2014年基于自编码器改进的对抗生成网络的诞生,改变了传统的机器学习方式,尤其在和卷积神经网络融合之后。现如今,对抗生成网络成为图像处理领域绕不开的一个模型。肖芳等[1-3]都是以往对人脸正面化的研究,由于人脸有多个面目特征,其由眼睛,鼻子,嘴巴,轮廓等组成,在复原人脸过程中就容易忽视掉局部器官的微小特征,为此本文提出基于生成对抗网络新的方案实现唇形重建过程,以解决视觉语音中缺少正面语料库的问题。
2 数据获取与预处理
2.1 数据库介绍
本文中使用的芬兰奥卢大学机器视觉中心制作的多视觉视听数据库Ouluvs2,此数据库有53位测试者,其中男女人数分别为40位和13位。数据库从5个角度0°,30°,45°,60°,90°,6台摄像机同时录制,被测者从数字、短语、长句子三个方面进行说话,随机的数字,日常用语和长句子。特别的数据库针对嘴部区域制作唇部数据集。
2.2 图像预处理
由于本文针对视觉唇读演技语料库缺少的问题,所以只对唇部的动态特点进行研究,为了减少gpu和内存的消耗,提高运算效率,本发明对数据进行灰度化处理,同时按视频的帧率进行剪裁,最后都归一化,统一数据类型和数据形状大小。
假设样本(xxx,x),x为样本中像素点的值,x表示中最小像素点值,x表示中最大像素点值,归一化[-1,1]之间的值:

归一化后的值,送到深度学习网络当中,可以使求最优解过程变得更加平缓,更容易正确的收敛。同时统一数据量纲以后,还可以消除一些奇异数据的不良影响。
3 唇形重建原理
3.1 对抗生成网络
生成对抗网络,简称GAN(Generative Adiversarial Networks),由IJ Goodfellow[6]在2014年引入深度学习领域。随后,基于GAN思想的创新百花齐放,诞生了许多优异的GAN相关算法模型。
GAN的基本架构由生成器和判别器组成,生成器G接受随机向量生成假的样本数据(),()和真实样本同时输入到判别器网络进行判别。对于真实的数据判别器判断为1,对于假数据判断为0。判别器网络训练的目标就是使得判别真假数据越来越精确,生成器网络训练的目标就是使得生成的数据越来越接近1,骗过判别器网络。最后无论是真或假样本,都会被判别器判别输出概率为0.5,此时生成器网络模型达到最优。
3.2 本文改进算法
3.2.1模型架构
循环生成对抗网络(CycleGAN)使用一个生成器和判别器网络共享权值得到两个生成器和两个判别器,通过循环一致性损失,实现对图像不同域的映射。如图1,是本文改进单向CycleGAN实现过程。把X域转向Y域的框架图,X域中的样本I送到生成器GXY中,得到I´,GXY把I´复原为I,使得I和I越接近越好,同时为了保证身份一致,生成器GXY对I进行验证。判别器GY判别I和I´。

图1 本文改进的模型框架
生成器的网络架构使用U-Net网络模型。连接具有相同特征的图层,可以很好地保留原域与映射域间共同的特征,减少相同权值的特征在网络中传播叠加,防止造成网络训练成本增加。模型的卷积深度为13层,每层卷积核大小为4*4,步长为2。使用实例标准化(InstanceNormalization)加速模型收敛,保持每个图像实例之间的独立性。在反卷积层里面加入Dropout层,以防止过拟合。
判别器架构使用马尔科夫判别器,由全卷积层组成,输出为30x30的矩阵。最后以矩阵均值作为真假判断输出,矩阵的每一个输出都代表原图中的感受野。这样可使得生成器生成的图像保持高分辨率、高细节。
3.2.2损失函数设计
假设有待重构样本集={1,2,3,…,a},额叶面唇部域样本集={1,2,3,…,b},为了使域样本特征重建为域,:→。实验使用三部分损失对网络进行优化:
对抗损失:
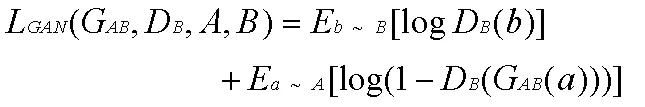
重构总损失:
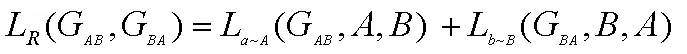
身份保持总损失:

由(1)到(3)组合,总的损失表示为:
其中,分别为生成器和判别器,为不同的样本数据集。分别表示中的样本数据,和为超参数用于对网络的影响。
4 实验结果分析
4.1 训练环境设置
实验使用3.3节中网络框架,为每一个视图创建一个模型,生成额叶面(正面)图像。作为网络的输入,使用40位测试者的数字和短语视频进行帧画面截取,对12位测试者的帧画面进行测试。本试验使用英特尔酷睿i7-7700(3.60GHz)16G和NVIDIA GeForce 1070 8G的计算机进行运行,迭代200个周期,使用每个域各为1.2万帧图像,两个生成器和两个判别器都使用β=0.5,学习率为10-4对模型进行优化,超参数设置=10,=10-2。
4.2 验结果分析
如图2所示,第一列依次为30°,45°,60°和90°真实唇部图像,第二列为对应的正面真实唇部图像,第三列为我们每个模型对应生成的唇部图像,很好的生成正面视图的开闭嘴特征,特别是高频细节能够很好保留。当角度增大时,接受特征减少,还原正面图像的难度会增大。
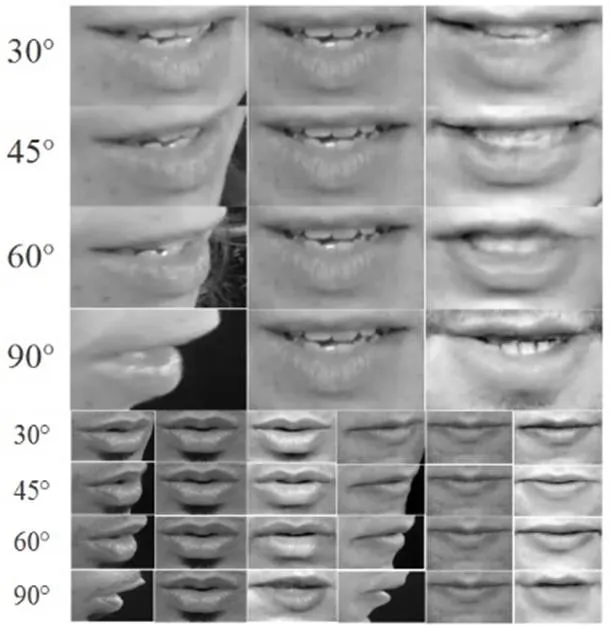
图2 唇部图像
原图像生成图像之间的结构相似性(SSIM)和信噪比(PNSR)与view2view对比发现,本文使用的方案结果有明显提升(表1)。

表1 对比表
5 总结与讨论
本文基于对抗生成网络的改进方案,使用U-net网结构,加入身份一致损失很好地重建了正面唇形,本文的初始目标是解决视觉语音语料库不足的问题,同时本实验方案也可以用于人脸转正,为人脸转正也提供一个参考方案。本试验不足之处,由于本身视觉语料库的缺少,可供实验的数据较少,本试验基于实验环境下数据库有很好的效果,但面对更复杂的条件,比如含光照,噪声等野外低分辨率数据还有待探究。
[1]肖芳.基于深度学习的多姿态人脸识别算法研究[D].四川:电子科技大学,2019.
[2]马佳欣. 基于深度学习的人脸正面图像合成方法的研究与实现[D].北京邮电大学,2019.
[3]钱一琛. 基于生成对抗的人脸正面化生成[D].北京邮电大学,2019.
[4]Koumparoulis, Alexandros, and Gerasimos Potamianos. "Deep view2view mapping for view-invariant lipreading." 2018 IEEE Spoken Language Technology Workshop(SLT). IEEE, 2018.
[5]Rui Huang,Shu Zhang, Tianyu Li and Ran He, “Beyond Face Rotation:Global and Local Perception GAN for Photorealistic and Identity Preserving Frontal View Synthesis”, arXiv:1704.04086,2017.
[6]Goodfellow I J,Pouget-Abadie J,Mirza M,et al. Generative adversarial networks[J]. arXiv preprint arXiv:1406.2661,2014.
