基于Storm非合作博弈调度的ETL研究
2021-10-28马海旭冯欣王贵磊孙开蔚
马海旭,冯欣,王贵磊,孙开蔚
(长春理工大学 计算机科学技术学院,长春 130022)
新技术的广泛使用产生了大量数据。例如,Twitter[1]上的微博数量每一分钟超过10万条。数据价值随着时间的流逝而减少并具有实时性、易失性等特点。目前发展较为成熟的Ma‐pReduce框架,本质上是批数据处理,而纯流式数据处理框架Storm能够有效地解决实时流处理问题。利用Storm构建ETL(Extract-Translation-Load)处理系统,本文针对ETL流程提取和转换阶段存在的问题展开研究。
变更数据捕获作为ETL流程实时处理的关键。文献[2]提出一种新的细粒度并行化/分发方法,对源数据进行分区并行处理,通过快照对比捕获变更数据。文献[3]提出了一种能够实时地为应用程序提供信息的ETL框架,该框架无需创建数据仓库便可对现有存储库进行分析。针对特定环境需求,文献[4]对ETL体系结构进行了优化,以满足实时感知并捕获数据。实时ETL关键在于提升数据捕获性能,针对变更数据捕获延迟问题,在快照对比捕获变更算法基础上,提出了变更数据标记捕获算法,该算法对源端变更数据置标志位,实验结果表明,降低了ETL系统捕获变更数据时间开销。
数据中间处理作为ETL流程的重要步骤,采用Storm作为ETL过程数据处理框架,但Storm默认采用轮询调度策略,存在通信开销大和负载失衡等问题,降低了系统数据处理性能。调度的关键任务是寻找最优解,文献[5]在生产调度中利用遗传算法提出了优化策略。Storm系统调度的目的是降低网络通信开销、系统处理延迟以及负载均衡。文献[6]提出了在Storm环境下离线和在线的两种自适应调度算法,在线调度算法根据实时监测节点负载及集群通信负载制定调度策略,弥补了离线调度的不足,对于复杂的拓扑容易陷入局部最优。熊安萍等人[7]引入拓扑热边的概念,该算法是将高频热边关联的任务对迁移到同一工作节点,但该算法只考虑优化拓扑内部高频热边通信的任务。鲁亮等人[8]提出了基于权重的任务调度算法,设计了边权增益模型,将任务移动到边权增益值较大的节点上。但存在一个工作节点负载过度低于其余节点的问题。刘粟等人[9]提出了基于拓扑结构的任务调度策略,将拓扑中度最大的组件对应的线程优先移动到CPU资源充足的节点上,但将任务尽可能移动到某个节点的同时必定影响集群负载均衡。文献[10]提出并实现了一种自适应在线调度方案,解决了在不发生拥塞的情况下处理波动负载,利用Cgroup实现了资源隔离,减轻了资源争用带来的性能干扰。王林等人[11]利用蚁群算法在NP-hard问题上的优势结合Storm本身拓扑特点,提出改进蚁群算法优化Storm任务调度,但算法易出现局部最优解。针对Storm默认调度算法以及相关研究不足,本文提出了非合作博弈Storm调度算法,构造博弈函数,充分考虑任务负载以及通信开销,将任务调度到合适的工作节点。实验结果表明,相对于Storm默认调度算法以及文献[6]的在线调度算法,提出的算法在通信开销、负载均衡以及系统延迟方面均有所改进。
1 ETL数据捕获
ETL作为构建数据仓库的核心部件,捕获数据又作为ETL的关键一步,企业组织要求零延迟捕获数据以支持决策系统。变更数据捕获(CDC)是ETL流程中数据捕获(E)步骤的关键。当变更数据捕获流程发现源数据库端有数据发生变化时,数据捕获系统将提取并处理这些数据以刷新数据仓库(DW)。其余数据(不受更改影响)将被拒绝,因为它已被加载到DW中。
1.1 标记变更捕获
关于ETL的功能流程,在文献[2]中作者详细阐述了基于快照对比的变更数据捕获(CDC)。针对快照对比无法低延迟捕获变更数据的要求,本文提出了变更数据标记捕获算法。
提出的新方法需要由特殊的源数据库端(标记变更数据)和捕获变更数据阶段共同完成。首先需要为源表设置标记位F,数据库插入、更新、删除操作标记位F分别对应1、2、3。表1为表2的快照。表2中标记位F=1、2、3的元组分别各有2个,表示源表插入2个元组,更新2个元组,删除2个元组,只是删除操作并没有立即执行,便于捕获阶段提前发现删除数据。待操作结束,需清零所有标记位。捕获变更数据和源数据库操作可同时执行,CDC阶段无需逐条元组对比来捕获变更数据,只是增加了源数据库端的负担。

表1 前一时刻表STpv

表2 当前表ST
1.2 标记捕获算法
为了降低ETL流程再次发现并捕获变更数据带来的系统时间开销,采取在源端标记变更的数据元组,从而减轻提取变更数据的压力。具体变更数据标记捕获算法如下:

算法1描述了改进后的CDC功能。第一行表示在数据源端对变更的数据做标记,对插入、更新、删除对应记录的标记位分别置1、2、3。依次读取tuple,如果tuple.F=1,则表示插入操作;如果tuple.F=2,则表示更新操作;如果tuple.F=3,则表示删除操作。
1.3 快照捕获思想
设tuple1和tuple2分别是存储在源数据库表ST和该表对应的快照表STpv中的两个元组。如果tuple1和tuple2满足式(1)和式(2),这意味着它们无变化(CRC,循环冗余校验)。tuple1应该被CDC进程拒绝,因为没有发生任何更改。如果仅满足式(1),表示tuple1已受到更改的影响,由CDC进程提取为UPDATE。如果满足式(3),则这表示tuple1为新插入元组,由CDC进程提取为INSERT。如果满足式(4),表示tuple2为已删除元组,由CDC进程提取为DELETE。

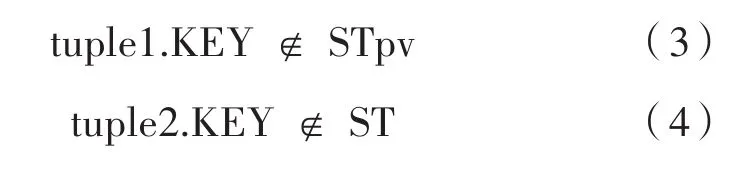
1.4 捕获实验分析
实验机器配有intel-Core i7-9700K CPU@3.6 GHZ x8处理器,8 GB RAM,40GB可用硬盘空间。机器安装CentOS-7.0 64系统,使用Mysql-7.6.10数据库和IDEA2018.2编辑器。采用高级语言Java编程语言,运行环境采用JDK 64位。
针对快照对比捕获变更数据算法与变更数据标记捕获算法对于发现并提取变更记录的性能优劣问题,本文利用单机模式及小规模数据,研究这两种算法捕获变更数据差异。采用简单的字母序列,来分析两种算法捕获数据表中变化的数据记录。
对比两种方法在不同记录数下捕获变更数据耗时,分别向Mysql数据库中加载不同数量的消息记录(每条消息记录包含20个字母型字段),执行插入更新删除数据库变更操作,记录被捕获到的变更消息记录。实验结果如图1所示,变更数据标记捕获方法捕获到变更数据消耗的时间相比快照对比方法捕获到变更数据消耗的时间降低了22.6%。
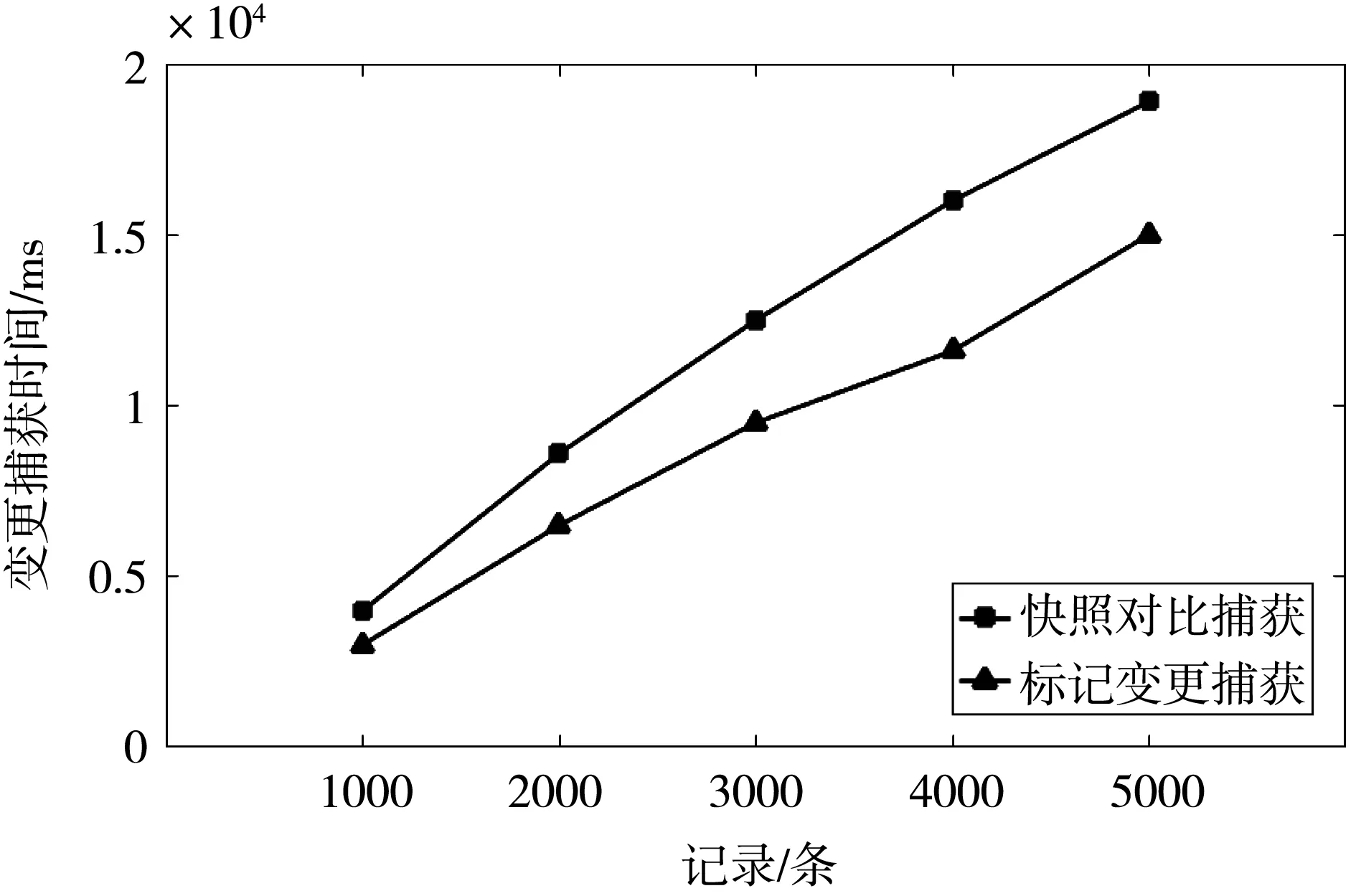
图1 记录数对变更捕获的影响
对比两种方法在不同字段数下捕获变更数据。分别向Mysql数据库中载入不同字段数(字母型)的消息记录(每种字段数均有2 000条记录),执行三种数据变更操作,记录被捕获到的变更消息记录。实验结果如图2所示,变更数据标记捕获方法捕获变更数据消耗的时间相比快照对比方法降低了23.1%。

图2 字段数对变更捕获的影响
实验表明,在单机模式下,面对小数据量,变更数据标记捕获方法在捕获变更数据方面要优于通过快照对比捕获变更数据的方法。
2 Storm博弈调度
2.1 Storm调度分析
Storm调度算法默认采用轮询算法,对空闲slot按端口号升序排序,将运行任务的executor轮询部署到已排序的slot上,集群最后一个节点负载明显低于其余各节点。默认轮询的调度算法存在负载失衡的问题。默认调度只是简单的将实例化的executor轮询分发到各节点,集群上各工作节点间存在大量的网络通信开销。如图3所示,拓扑由组件Spout,Bolt_1和Bolt_2实例的任务组成。

图3 拓扑结构图
如图4所示,显而易见,部署到集群中的拓扑,任务之间均为网络通信。数据通过网络传输消耗的时间远大于计算机内部进程间或进程内部的数据传输延迟,因此,降低拓扑网络间数据通信开销,提高节点内部数据通信量,可有效提升Storm数据处理性能。
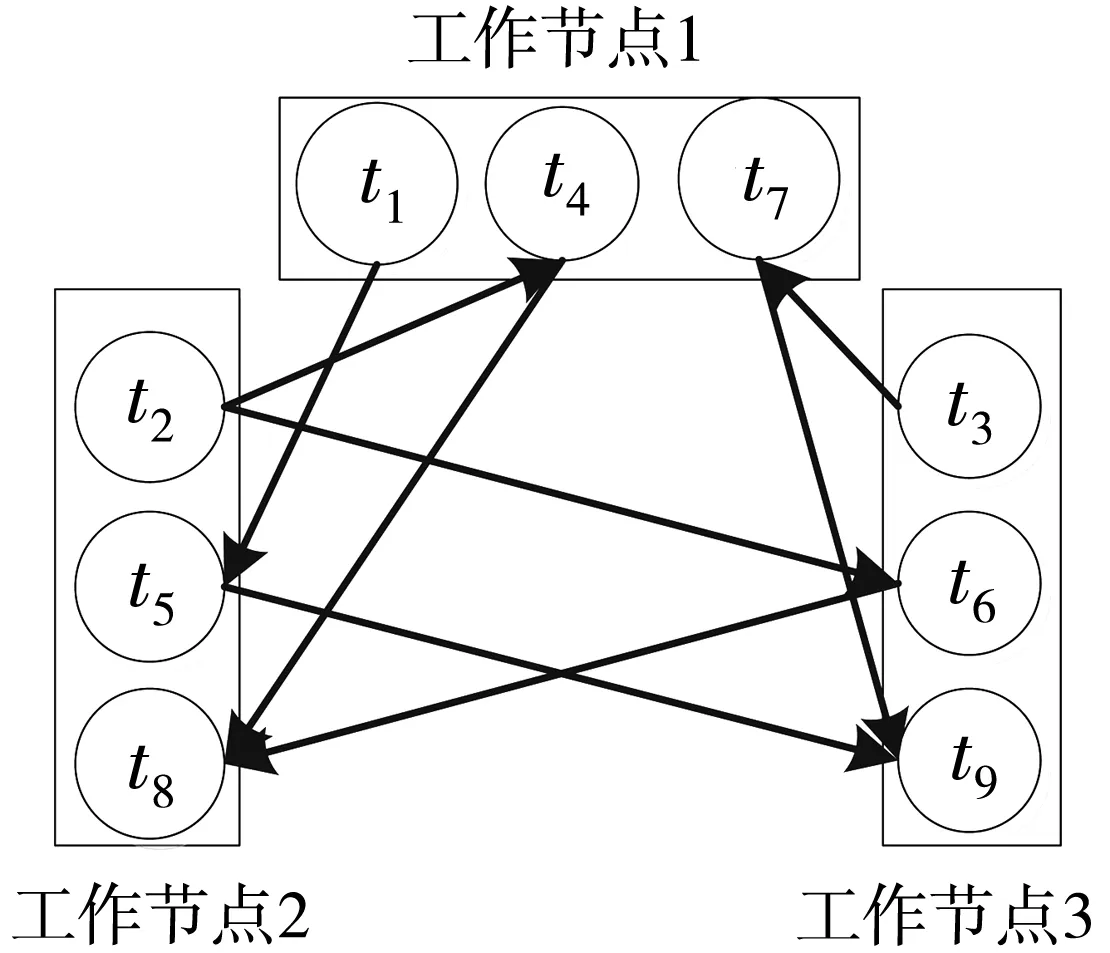
图4 拓扑部署图
2.2 调度思想
调度优化思想阐述。本文假定的拓扑简化模型如图5所示,集群配置了3个节点,每个节点仅配置一个slot。任务分配情况如图5所示,拓扑模型中任务t1和t2与任务t5传输的数据量远大于任务t4与任务t5之间的传输量,任务t6在节点2上无通信传输而与t8有通信往来,将任务t5从节点2转移到节点1上,任务t6从节点2转移到节点3上,可有效降低节点间通信开销,提升集群的负载均衡性,如图6所示。
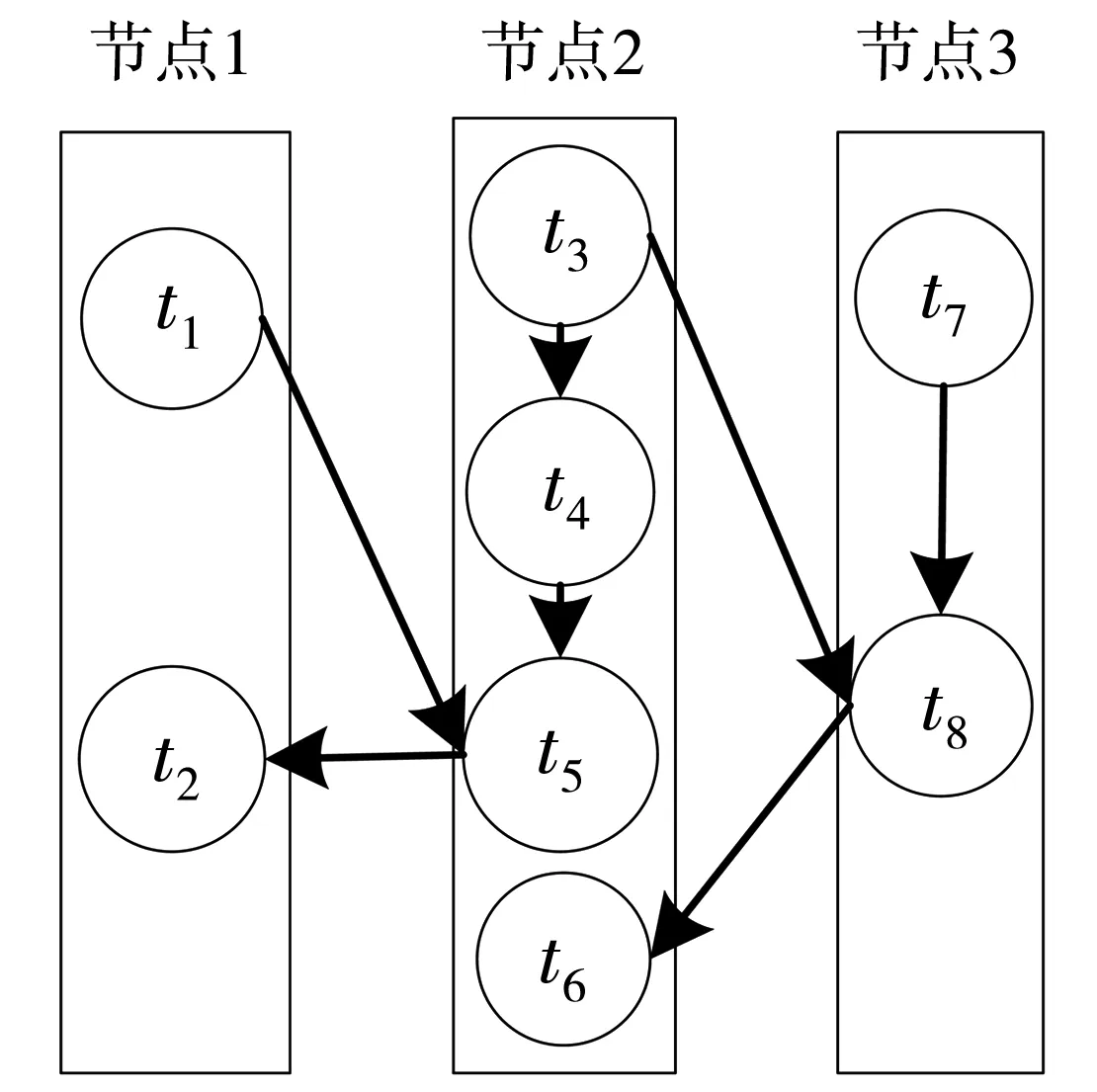
图5 未优化拓扑
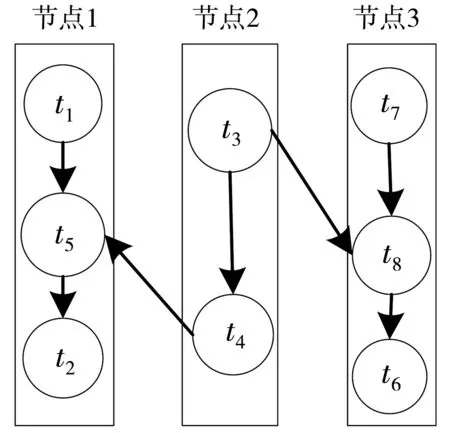
图6 已优化拓扑
2.3 相关定义
在Storm调度中,应考虑节点内部通信量最大(由数据传输总量固定,则节点间通信量最小)的同时兼顾集群负载均衡性,引入收益函数(博弈函数)求解系统调度的最优解。为了降低网络通信,一个节点部署一个slot[8]。针对上述模型,作出如下定义:
定义F为节点内部数据传输总量,如下:

其中,S为集群slot集合(一个节点部署一个slot);Tk为第k个slot内部任务集合;rij为任务i到任务j的数据流;Skrij为第k个 slot内部数据流rij。

其中,N为节点集合;nk为节点Wnk为节点的CPU负载;Mnk为节点的内存负载。
定义θ和η分别为工作节点的CPU和内存负载标准差,如式(9)、式(10)所示:
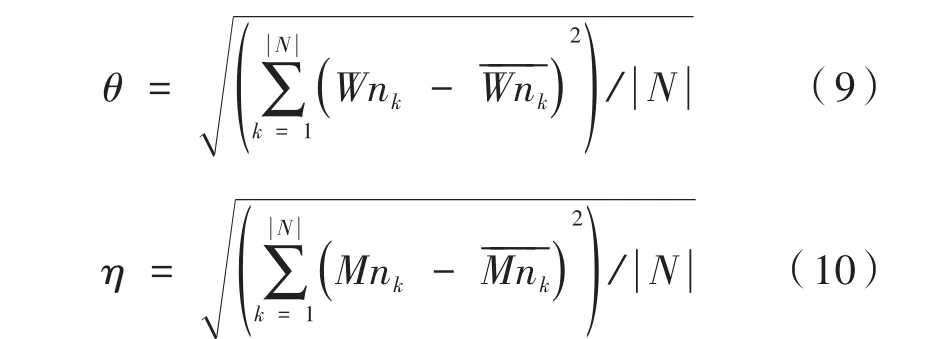
定义g为集群的CPU和内存负载标准差加权之和,如下:

其中,λ为θ的权重;γ为η的权重;通常λ≥γ,主要考虑CPU负载对系统的影响。
调度优化问题可以转化为满足式(12)、式(13)、式(14)的条件下收益函数u的最大值问题。

2.4 博弈建模
构建Storm拓扑控制的非合作博弈模型,其中博弈模型的博弈局中人或称博弈参与者为调度系统中的任务;参与者的策略为当其他参与者策略保持不变时改变自己的调度策略来最大化自身以及系统整体效用,将博弈参与者的所有可用策略构成一个策略集合,如下:

被称为一个调度策略向量;当博弈参与者使用上述策略时对应得到非合作博弈函数如下:

根据纳什均衡点的定义,当构造的Storm任务调度控制模型经过博弈达到纳什均衡时,即可认为系统收益已达到稳态,没有任一任务可以通过仅改变自身调度策略来提高自身以及系统的整体效用。
定义 策略集合 σt=[σt,1,σt,2,σt,3,...,σt,n]是提出的多任务资源分配博弈模型的纳什均衡点的充分必要条件,满足式(17):

接下来首先根据文献[12]中Boyd S提出的纳什均衡存在性定理Ⅱ证明所提出模型纳什均衡点的存在性。
定理 构造的任务调度控制非合作博弈模型存在纳什均衡点。
证明 由于Storm任务调度优化过程中集群节点内部通信量逐渐增加并趋于平稳,故边界条件(13)是欧式空间上的一个非空有界闭凸集,然而只需证明边界条件(14)满足纳什均衡存在性定理Ⅱ中规定的条件:
假设所有任务都分配给一个slot,那么必存在一个常量μ,使(m ax) Wnk< μ,根据式(9),θ≤(m ax) Wnk(1 ≤k≤n),同理根据式(10),η ≤(m ax) Mnk(1 ≤k≤n),而g=λθ+γη,又由于调度的不断优化,负载标准差逐渐减小并趋于平稳,故g是欧式空间上的一个非空有界闭凹集。综上所述,收益函数u为有界闭凸集。拓扑任务调度的收益函数u存在最大值,因此构建的Storm集群拓扑调度博弈模型中存在纳什均衡点。
2.5 算法设计
本算法执行的前提是监控集群的运行状态,其中包括拓扑中任务间的数据流量和集群中各节点的CPU消耗量以及内存的使用量。在获取节点内部任务间最大通信量的同时考虑负载均衡。因此在非合作博弈算法的设计过程中,当用户提交拓扑后系统会先执行默认调度算法,并当集群上各工作节点中的拓扑任务运行稳定后,采集并存储节点内任务间数据流以及节点的CPU负载和内存负载。结束后,则执行博弈算法对任务进行重新调度。在Storm拓扑运行中,若出现集群上各节点CPU负载持续不均,即在指定持续时间间隔内,集群中各个工作节点的CPU负载最大值与最小值之差大于设定阈值,则再次触发博弈调度算法,具体算法如下,具体参数如下所示。


上述算法基于采集默认调度信息,然后判断是否触发博弈调度。若初始调度集群节点任务数失衡,则重复初始化。随后遍历每个节点中的所有任务,分别移动到不同的节点,记录最优的收益值。迭代M次,若最优值没有改变,即为最优值。此调度算法的关键在于,未独立开来考虑减少集群上的网络间的通信开销与节点间的负载均衡,而是将节点内的数据通信与集群资源的负载均衡有机结合到一起,从自适应的角度出发,通过迭代的方法,使集群收益最大化,从而得出最优的调度策略。
3 ETL流程优化
改进后的ETL流程如图7所示,源数据库在变更数据时标记相关数据,便于ETL系统捕获变更,这样捕获变更可以有效节省后期因遍历数据带来的时间开销。基于非合作博弈调度的Storm系统负责提取、处理,并加载数据到数据仓库。本文提出的改进算法构建了实时GS-M-ETL数据处理流程。
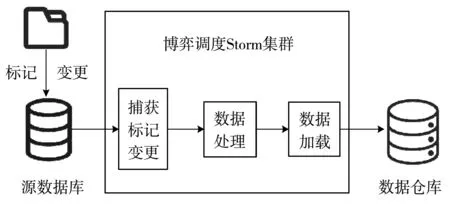
图7 ETL数据处理优化图
ETL流程中数据提取和处理转换是影响系统性能的重要因素,其中数据提取是关键部分。数据捕获采用变更标记捕获算法(CDMC),根据源数据库端变更的数据记录,提取相关的变更数据。数据处理采用基于非合作博弈调度的Storm(Game-Sorm)分布式流处理系统。
4 实验结果与分析
4.1 实验环境
测试环境是由13台PC搭建的Storm-1.2.2集群。每台机器都配有intel-Core i7-9700K CPU@3.6 GHZ x8处理器,8 GB RAM,40 GB可用硬盘空间。机器均安装CentOS-7.0 64系统,并通过LAN中的交换式以太网1 Gbit进行互连。其中3个节点共同运行Zookeeper-3.4.10集群和kafka-2.2.0集群,Nimbus、进程UI和数据库Mysql-7.6.10运行在其中1个节点上。其余10个节点运行Su‐pervisor守护进程。
4.2 实验方案
实验使用Storm框架提供的可插拔的自定义任务调度器Pluggable Scheduler,该调度器是专为开发人员设计的。利用自行实现的负载监控器Lead Monitor来采集拓扑运行时对应executor的一些关键数据,包括executor负载、worker node负载、executor间通信量等,并且Load Monitor以dae‐mon进程方式在后台运行。此外,本实验选择Ganglia[13]作为 Storm 集群监控工具,利用 Ganglia提供的数据来辅助实验结果的分析。为验证非合作博弈调度算法Game-Storm的有效性,本文同时部署了Storm框架默认调度算法(Default Scheduler)和Storm框架自适应在线调度算法(Online Scheduler)[6],算 法 Online-Storm 在 每 个节点配置2个slot,相关参数参照如表3所示。
表3列出了Game-Storm调度算法的各项参数配置。实验参数是通过若干次实验并经过微调后确定的理想值,具体参数需要根据实际运行情况进行人为调整。实验设置10个工作节点和10个工作进程,即每个工作节点上仅部署一个工作进程,这样可有效降低工作节点内部进程间通信开销,与本文非合作博弈调度算法描述相符。

表3 Game-Storm参数配置
本文提出的算法调度必须在运行时执行,以便使分配适应集群中负载的变化。图8展示了需在Storm体系结构中集成在线调度模块。图中描述的负载监控器运行在每台机器上,负责采集工作节点的各项性能参数(如节点间通信量,CPU和内存消耗量),并将负载数据存入数据库中。调度生成器模块从数据库中读取负载信息,生成调度策略。可以定期检查监控数据,并运行自定义调度程序,判断是否可以部署新的更有效的调度策略。

图8 改进的Storm系统框图
图8展示了Storm集群负载监视模块,该监控模块负责在拓扑运行一定的时间窗口内,采集并计算拓扑任务占用工作节点CPU负载信息,以及拓扑任务之间的通信量大小,具体系统监控及数据采集方案如下:
由于Storm系统中的一个拓扑任务运行于工作进程的一个工作线程中,因此为了获取拓扑任务在执行过程中对工作节点CPU、内存资源的占用量,还有各对拓扑任务在单位时间内传输的信息量,需实时追踪拓扑任务对应的工作线程ID及其相关联的所有工作线程。利用线程所在工作节点的CPU主频与该线程占用的CPU时间的乘积来表示线程占用的CPU资源大小。ThreadMXBean类的 getThreadCpuTime(long id)方法可以获取线程id占用的CPU时间。
各对线程间通信速率以及线程占用的内存大小,需要统计各线程收发总的元组数以及元组的传输时间,线程间的通信速率由线程收发数据差与对应时间窗容量的商求得,线程执行期间占用的内存量由单位时间内接受的元组数与发送的元组数之差决定。具体实现:在每个Spout/Bolt源中添加任务监控器。在具体的每个任务中必须通知其线程ID以在特定Java进程中运行。对于每一个Spout/Bolt,添加一个全局变量:

为了评估本文提出的Game-Storm-ETL平台,本文提供了一个ETL过程示例。开发了一个数据生成器程序来生成源数据,产生了1×109个元组,每个元组包含20个字母型字段。ETL过程为按如下方式处理数据。数据集载入Kafka(top‐ic=3,partitions=12)消息序列数据库,数据载入过程存在更新与删除操作。数据储存在消息中间件Kafka中,Storm从Kafka中读取数据,经处理后加载到Mysql数据库中。
4.3 实验结果
实验对比优化前后(Default调度算法、On‐line-Storm调度算法和改进后的Game-Storm调度算法)的Storm系统在节点间网络通信量和集群负载均衡两个方面的性能,以及对比了改进后的ETL系统数据处理延迟与原ETL系统数据处理延迟。实验结果如下:
如图9所示,实验开始任务分配遵循Storm系统默认的调度算法,首先执行默认调度算法,待Storm系统运行趋于稳定后,集群上节点间通信的数据流大小平均值约为119 372 tuple/s。由于在第85 s时系统出现持续70 s的观测周期内集群上工作节点的CPU负载的最大值与最小值之差大于20%,因此,再次触发了调度,在第115 s处重调度已结束,节点间通信量持续增长。随着时间的推移节点间通信量趋于平稳。

图9 三种节点间通信算法的比较
Game-Storm调度算法和Online-Storm调度算法在节点间数据流大小平均值分别为80 337 tuple/s和90 961 tuple/s,相比Storm默认调度算法分别降低了32.5%和23.2%。
图10显示的是三种调度算法下集群CPU负载情况。默认的调度算法CPU最大负载超过了60%,且最大最小CPU负载差也大于20%,所以在线算法与本文提出的算法都会被触发。默认调度CPU负载标准差高达9.57,重调度后,在线调度算法和Game-Storm调度算法的负载标准差分别为3.51和3.25。

图10 三种CPU负载平衡算法的比较
如图11所示,变更数据标记捕获算法与Game-Storm调度算法构建的系统(GS-M-ETL)使得ETL性能得到了提升。待Game-Storm调度结束,且系统运行趋于平稳,ETL过程时延相比于未改进的变更数据捕获方法与默认调度算法下的ETL系统,系统时延降低了29.5%左右。提出的基于非合作博弈的调度算法使Storm系统在降低网络通信量以及负载均衡方面的性能得到了提升。同时,与提出的变更数据标记捕获方法结合,降低了ETL过程数据处理延迟,提升了ETL系统性能。
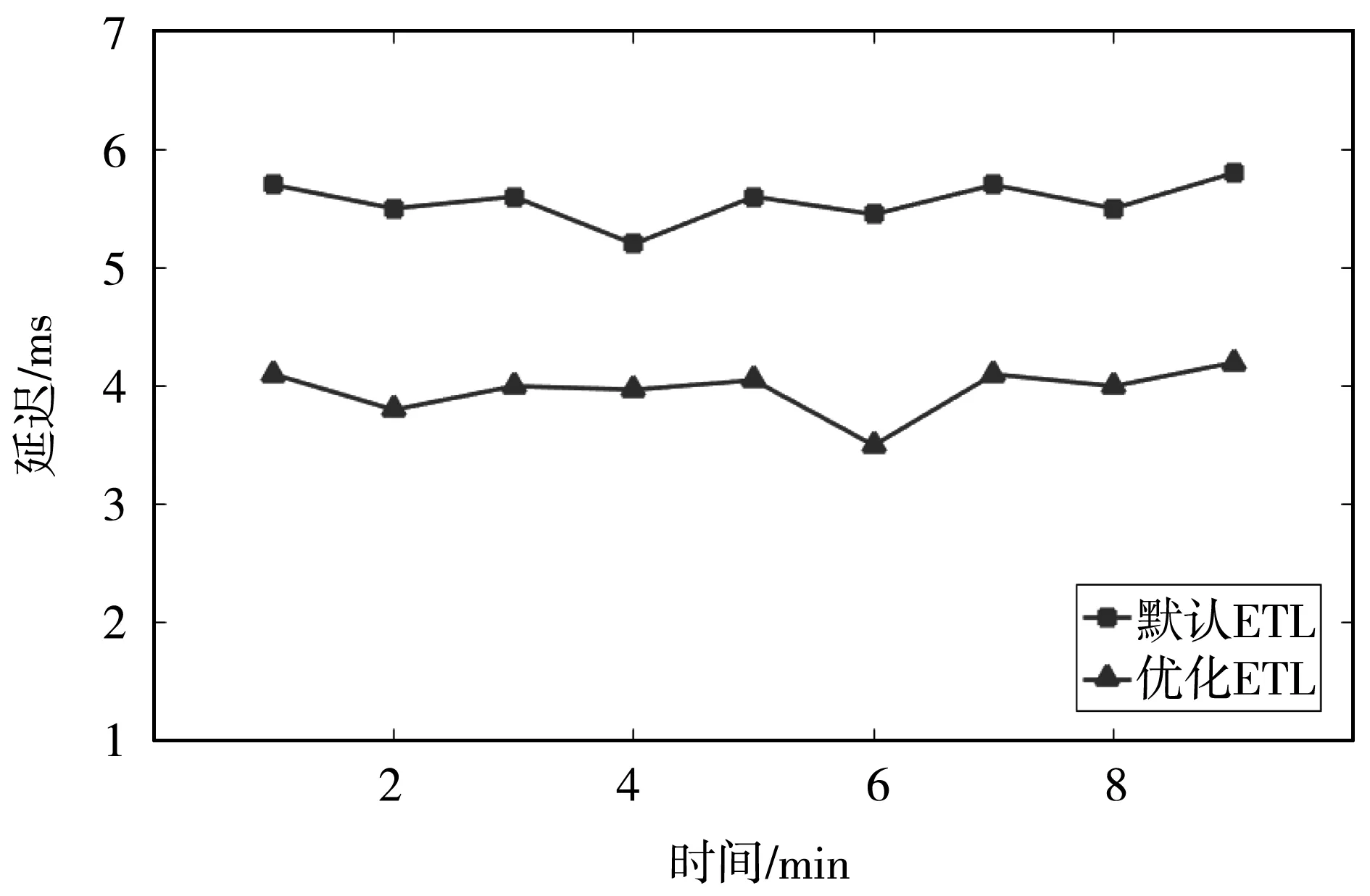
图11 ETL系统处理延迟对比
利用Ganglia对集群负载进行监控。从Ganglia监控改进后的调度系统得到的数据来看,Storm集群各工作节点CPU、内存等使用率都较为均衡,没有节点负载过重,集群整体负载较为均衡。
5 结论
本文提出了变更数据标记捕获算法,相对于传统基于快照对比捕获算法,在变更数据捕获方面性能得到了提升。Storm作为实时ETL流处理框架,默认采用轮询调度算法,节点网络通信开销和集群负载均衡存在优化空间。本文提出了非合作博弈的Storm调度,实验证明集群网络通信开销和负载均衡得到了优化。二者的改进,使得ETL流程的整体性能得到了提升。Storm调度尚未考虑网络带宽问题以及未曾考虑I/O传输接口等硬件资源的影响,希望未来这些问题可以得到解决。
