基于Python网络爬虫和数据可视化技术的某招聘网站数据采集与分析
2021-10-21接辉
接辉
随着信息技术的深入发展和广泛应用,网络平台成为各类信息发布和收集的主要渠道。网络爬虫作为网络数据采集的重要技术手段,已广泛应用于各个领域。本文使用基于Selenium 技术的网络爬虫,从某招聘网站采集到北京、上海、深圳、南昌四个城市IT行业招聘信息,使用数据可视化技术进行分析研究,得出了一些有益的结论。本文采用的数据采集和可视化分析方法对于一般研究工作具有普遍的借鉴意义。
一、相关技术
1.网络爬虫
网络爬虫是按一定规则自动抓取互联网信息的程序或脚本。在大数据时代,网络爬虫是进行数据收集的有效手段。目前网络爬虫一般使用Python语言调用Requests、BeatifulSoups、Selenium等类库实现。
2.Selenium
Selenium是一款开源的Web应用程序测试工具,可以在浏览器中模拟用户请求网页服务,很难被网站检测到,能有效规避各种反爬虫策略。
3.SQLite数据库
SQLite是一款轻型数据库,占用资源少,支持主流操作系统,支持ODBC接口。与一般数据库不同,SQLite引擎嵌入在程序中,整个数据库系统存储在单一文件中。在很多应用场景,它的处理速度优于MySQL、PostgreSQL等数据库。
二、目标网站分析
本文以某招聘网站为目标,通过观察法分析出网站页面间的逻辑关系。
1.首页与登录页
使用FireFox浏览器打开网站首页(https://www.zhaopin.com/),找到用户注册登录页面(https://passport.zhaopin.com/login)。注册后返回首页,选择用户名、密码方式登录。
2.职位搜索页
登录后,进入“职位搜索”页,可以输入关键词搜索职位,还可以选择不同的城市、职位类别、公司行业以及列表的页码等。本文选择自己关心的城市、行业和页码,发现随着选择的不同地址栏中链接的参数也会发生变化。比如城市选择南昌时jl=691,行业选择电子商务时in=100020000,页面选择第2页p=2,浏览器地址栏中的链接变为https://sou.zhaopin.com/?jl=691&in=100020000&p=3。
3.职位详情页
在职位搜索页列表中,可以看到职位名称、公司名称、工资待遇、岗位要求等基本信息。查看职位详细信息需要进入详情页。在职位搜索列表页,使用浏览器检查工具可以找到详情页的链接地址信息(https://jobs.zhaopin.com/后加一个无规律的html文件名)。
在详情页中,右键点击详细信息进入“检查”菜单,可以找到职位描述等文字信息所在的页面元素。
三、系统设计与实现
根据对网站的分析,系统可分为页面解析、数据采集与存储、数据可视化分析三个模块。
1.页面解析模块
在这个模块中,主要实现网页加载和页面结构解析与元素定位。
通过前文分析可知,我们需要加载和解析的页面主要是登录页、职位搜索页和职位详情页,相关页面的链接在分析中已经获取。我们可以使用browser = selenium.webdriver.Firefox()方法加载火狐浏览器的驱动程序,然后通过其browser.get(url)方法,获取链接url对应的页面。
首先实现页面自动登录。通过browser.get(“https://passport.zhaopin.com/login”),获取登录页。在登录页的中,分别找到用户名、密码所在的位置点击鼠标右键,选择“检查”菜单;在检查页面中相应的页面元素上点击右键,复制XPath;将复制的XPath作为参数,通过 browser.find_elements_by_xpath(XPath)方法获取输入用户名、密码的网页元素,调用sendkeys()方法将用户名、密码分别传送给浏览器,模拟用户输入用户名和密码;再用同样的方法获取“登录”按钮所在的网页元素,调用click()方法模拟用户点击登录。登录时,如遇图片滑块验证,可手动操作(只需在爬虫开始运行时操作一次)。
用同样的方法可以获取职位搜素列表页和职位详情页。
2.数据采集与存储模块
完成网页解析后,使用Selenium类库函数定位到需要的网页元素,访问其text属性即可获取相应的数据。通过这种方式可获取职位名称、公司名称、工资待遇、岗位职责、技能要求、详细描述等信息。
在进行数据存储时,使用sqlite3.connect()方法獲取数据库连接,再调用其cursor().execute(sql)方法,执行相应的sql语句即可。
程序执行时,容易被网页错误、数据库错误打断,影响数据采集效率。可将网页获取、数据库读写操作放在try...except语句中,对产生的异常进行处理;同时将try...except语句块放在循环语句中,循环重试若干次后如仍异常则记录错误并跳过当前页面,继续采集后续页面。
3.可视化分析模块
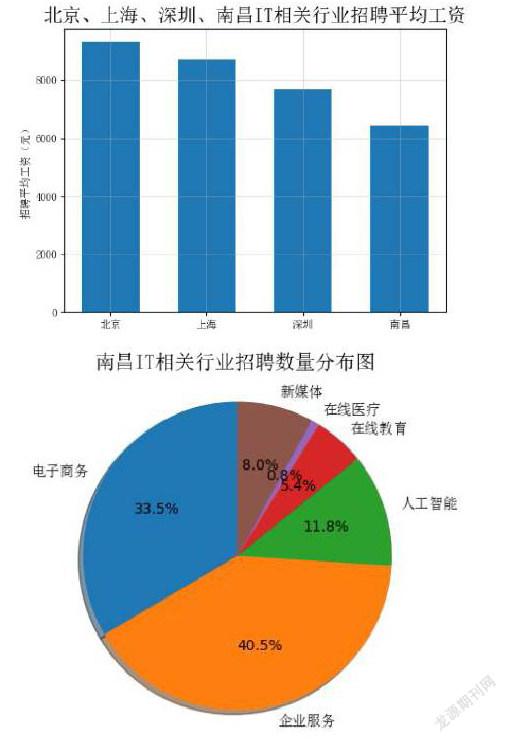
笔者发现,因网站限制,每个细分行业只能查询到34页共1020条招聘信息。北京、上海、深圳的实际数据超过了这个数量,不适合进行招聘职位的行业分布分析;南昌没有达到这个限额,不受影响。
在工资收入方面,一般来说招聘信息中的下限值比较接近真实收入情况。
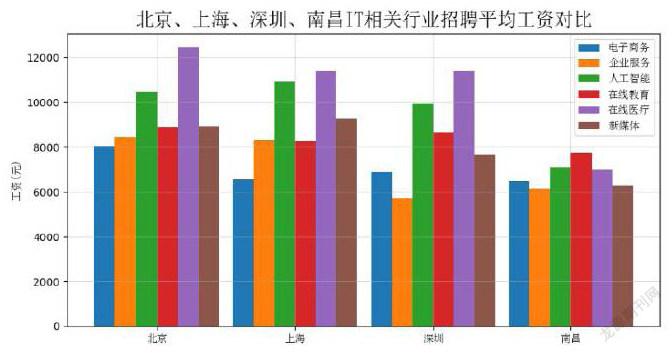
根据上述特点,本文从四个城市的行业平均工资、招聘数量行业分布、职位平均工资三个方面,使用Python的matplotlib类库的数据可视化方法,分别以下列条形图、饼状图的形式进行展示。
四、总结
根据上述分析,可以得出以下结论:
1.南昌IT行业总体工资水平和行业间差异低于北京、上海和深圳等一线城市。这与南昌社会经济情况是一致的。
2.南昌IT行业中,企业服务和电子商务方向就业机会最多、工资水平较低。说明这两个方向发展成熟、运行平稳。
3.一线城市在线医疗、人工智能方向收入较高,但在南昌工资优势不明显且招聘数量不多。说明南昌这两个方向发展较弱。
4.在线教育方向城市间收入差距较小。说明教育是刚性需求,在一般城市在线教育行业同样有较好的发展机会。
