CIDDPG的多智能体通信优化方法研究
2021-10-18耿俊香魏胜楠
耿俊香,姜 静,魏胜楠,段 昶
(沈阳理工大学 自动化与电气工程学院,沈阳 110159)
强化学习(Reinforcement Learning,RL)是机器学习的范式和方法论之一,用于描述和解决智能体在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题[1],广泛应用于机器人[2-3]、五子棋游戏[4-5]、自动驾驶[6-7]、目标定位[8]等诸多领域。强化学习的大部分成功应用均基于单智能体的情况[9-10],在面对一些复杂环境决策问题时,单个智能体的决策能力远远不够,如在拥有多玩家的Atari2600游戏中,需要多个智能体之间的相互配合才能完成任务。因此在特定的情形下,需要将强化学习模型扩展为多个智能体之间相互合作、通信及竞争的多智能体系统(Multi-AgentSystem,MAS)[11-12]。
通信是多智能体交互中出现的重要特征,智能体之间需要合作,每个智能体只能获得部分观测,环境中的智能体需要通过交流来更好地达成一个共同目标。
阿里推出多智能体双向协调网络(BicNet)研究智能体之间协作行为的学习,其基于连续行动的行动者-批评者模型,使用循环网络来连接每个智能体的策略和价值网络,实现内部层中的双向沟通,使多个智能体能够交流协作。但该算法由于奖励函数的定义原因无法适应多智能体的纯合作环境,此外,预定义的通信架构会限制通信,从而限制智能体之间的潜在合作,因此无法适应场景的变化。多智能体深度确定性策略梯度(Multi-Agent Deep Deterministic Policy Gradient,MADDPG)[13]是针对混合合作竞争环境的演员-评论家模型的扩展,采用集中训练分散执行的方法,其通信只发生在价值网络中,因模型结构过于简单,仅适用于一些较为简单的实验环境,当环境变得复杂时,算法的性能会发生显著下降。此外,在多智能体强化中还有几种学习通信的方法,包括DIAL、CommNet和Master-Slave等。
在所有智能体之间或在预定义的通信架构中,上述方法采用的信息共享可能存在问题。当存在大量智能体时,智能体无法区分有助于合作决策的有价值信息,因此通信几乎没有帮助,甚至可能危及合作学习。此外,实际应用中当所有智能体都进行通信时,接收大量信息需要高带宽,并会导致长延迟和高计算复杂度。因此,智能体高效通信成为重要研究方向。
本文提出一种基于通信的高效信息学习算法——通信改进深度确定性策略梯度(Communication Improvement Deep Deterministic Policy Gradient,CIDDPG),通过集中训练分散执行方法来实现。与环境交互时,在深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)算法的网络中加入双向循环网络建立通信机制并且加入调度模块,使智能体通过部分观察信息的重要性来确定有权广播其编码消息的智能体,以修剪无用信息,提高通信效率。在价值网络中引入注意力机制,有选择地关注其他智能体的信息,从而有针对性地更新策略,更好地完成任务。
1 高效通信的多智能体强化学习策略
DDPG是近年来备受关注的非执行性Actor-Critic经典强化学习算法,采用卷积神经网络作为执行网络(Actor)和评价网络(Critic)的模拟,执行网络根据行动者的状态来推断其行动,评价网络评判选择该行动的好坏,以指导执行网络的行动更新。DDPG模型结构如图1所示,该算法不仅能够在一系列连续动作空间任务中表现稳定,且时间效率也远优于其他算法。
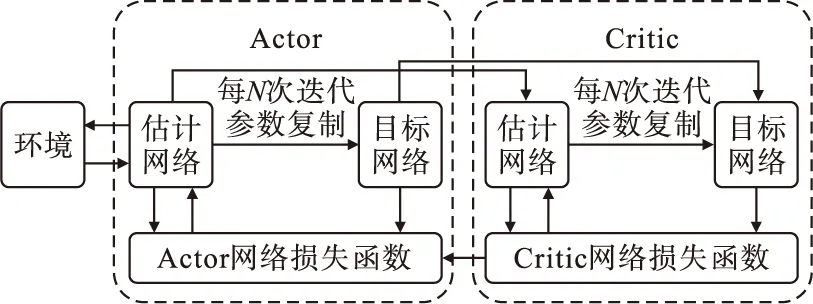
图1 DDPG模型结构
本文以DDPG为基础算法进行改进,其核心是基于通信的集中训练分散执行的Actor-Critic。在多智能体环境中,采用双向循环网络充当通信通道,连接各智能体,建立通信,整合一个群体中各主体的内部状态,引导主体进行协调决策。引入调度模块判断需要进行通信的智能体,根据智能体信息的相关性判断智能体的关联程度,使智能体有针对性地更新策略。根据最大熵的思想,智能体在最大化奖励的同时鼓励探索,提高算法的鲁棒性。CIDDPG模型结构如图2所示。

图2 CIDDPG模型结构
1.1 集中训练分散执行的Actor-Critic框架
本文采用Actor-Critic训练框架。
集中训练方法如下。
(1)训练时,首先Actor根据当前的状态si选择一个动作ai,然后Critic根据状态-动作计算一个Q值,作为对Actor动作的反馈。Critic根据估计的Q值和实际的Q值进行训练,Actor根据Critic的反馈来更新策略。
(2)测试时只需Actor即可完成,不需Critic的反馈。
分散执行方法为:每个智能体均训练充分后,每个Actor根据状态采取合适的动作,此时不需其他智能体的状态或动作。
1.2 权重调度机制的Actor模块
大量智能体进行通信时会受到带宽的限制,需尽可能压缩带宽,减少不必要的通信。在执行网络中引入调度模块,可选择合适的智能体进行通信,优化交互过程,提高沟通效率。调度模块结构如图3所示。
由图3可见,该调度模块由消息编码器、权重生成器、调度器和动作选择器组成。现有N个智能体,第i个智能体观察到局部环境信息oi,权重生成器根据不同的Actor局部观测信息得到对应的权重w,然后输入调度器,由调度器根据权重选择有权广播消息的K名智能体,生成调度向量C,其中K取决于智能体自身权重与平均权重的比较,当自身权重小于平均权重时舍弃。因广播的资源有限,需通过消息编码器将信息进行压缩,再根据调度器的调度向量C选取要广播的压缩信息,并传给所有的Actor,以采取合适的策略u。
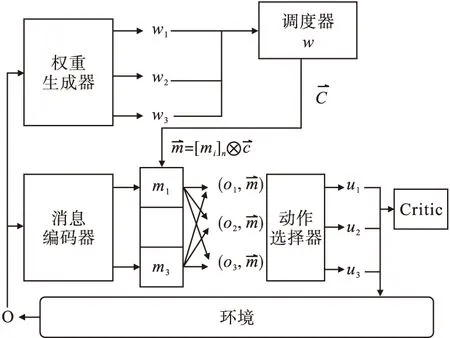
图3 调度模块
智能体i的权重wi生成为
(1)
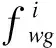
智能体i的编码信息mi为
(2)
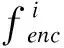
智能体i的策略ui选择为
(3)
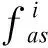
1.3 注意沟通的Critic模块
在Critic模块中引入注意力机制,其结构如图4所示。
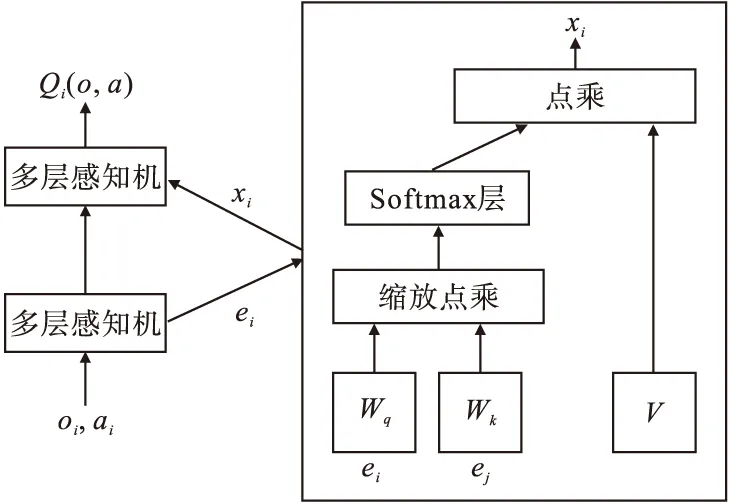
图4 注意力机制
注意力机制引入的目的是希望智能体在学习其他智能体策略时,能够关注利于获取更大回报的信息进行学习,而非无差别地完全学习其他智能体的所有信息。注意力机制本质上是使各智能体能够查询到其他智能体的观测信息和动作信息,并将此信息根据注意力权重的大小整合至自身动作值函数估计中。
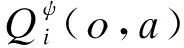
(4)
式中:fi为一个双层MLP网络;gi为一个单层MLP嵌入式网络函数;ai表示策略ui与环境进行交互做出动作;xi为其他智能体对第i个智能体价值的加权和,计算式为
(5)
式中:vj为智能体j的嵌入式编码函数;V为共享矩阵;h是ReLU激活函数;αj为注意力权重,通过查询值-键值系统比较ej=gj(oj,aj)与ei=gi(oi,ai),并将二者的相似值传递给softmax网络处理,得到
(6)
式中:dk表示维度;Wk和Wq分别表示两个线性映射的矩阵;ei和ej分别表示智能体i和j的状态编码。Wq将ei转化为查询值;Wk将ej转化为键值,然后根据该两个矩阵的维数进行匹配,以防梯度消失。由式(5)可见,注意力权重越大,智能体之间关系越紧密,获取的信息越多,反之获取的信息越少。
1.4 基于最大熵的Loss改进
最大熵的核心思想是不遗漏任何一个有用的信息,使神经网络尽可能探索所有的有效路径。引入最大熵的优势在于:在最大化奖励的同时鼓励探索;可以学到更多次优策略,提高算法的鲁棒性;训练速度加快,使探索更均匀。
加入最大熵的Critic网络的更新表达式为
(7)
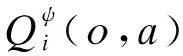
(8)
式中:ri为奖励值;γ为折扣因子;ψ′为评价的目标网络参数;θ′为策略的目标网络参数;α为温度参数,决定熵项相对于报酬的重要性,控制最优策略的随机性。
Actor网络的更新表达式为
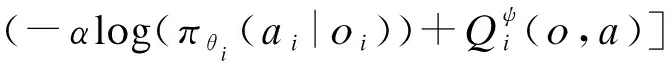
(9)
式中J(πθ)为最大奖励。在策略网络中同样引入最大熵提高算法的泛化能力。
2 实验及结果分析
2.1 实验环境及设置
为评估CIDDPG算法的性能,采用OpenAI的多智能体粒子环境(Multiagent Particle Envs,MPE)作为测试平台,该平台具有时间离散、空间连续的二维环境。由智能体和界标组成。在合作导航和合作推球两个场景中进行实验,每个智能体的观察视野均有限。实验中选取BiCNet和DDPG算法作为CIDDPG的对比算法,DDPG没有通信机制,BiCNet具有完整的交流模式。
本文使用Adam优化器,学习率取为0.001,折损因子取为0.96。
2.2 合作导航
在该场景下,假设N个智能体协同到达L个地标,并避免碰撞。每个智能体根据与最近地标的接近程度进行奖励,当与其他智能体碰撞时进行惩罚。理想情况下,每个智能体通过自身的观察和从其他智能体接收的信息预测附近智能体的动作,并确定自身在不与其他智能体冲突的情况下占领地标的动作。
采用N=30和L=30的设置训练CIDDPG和基线,其中每个智能体可观察到三个最近的智能体和四个具有相对位置和速度的地标。合作导航平均奖励学习曲线如图5所示。
图5显示出三种算法进行3500次迭代的平均奖励学习曲线,可以看出,DDPG算法的平均奖励值略优于BiCNet算法,但伴随着较大的波动,CIDDPG算法不仅能够收敛到比DDPG和BiCNet算法更高的平均奖励值,而且波动较小,收敛速度也较快。
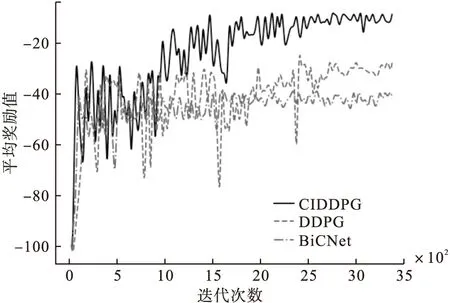
图5 合作导航平均奖励学习曲线
三种算法的合作导航实验结果如表1所示。
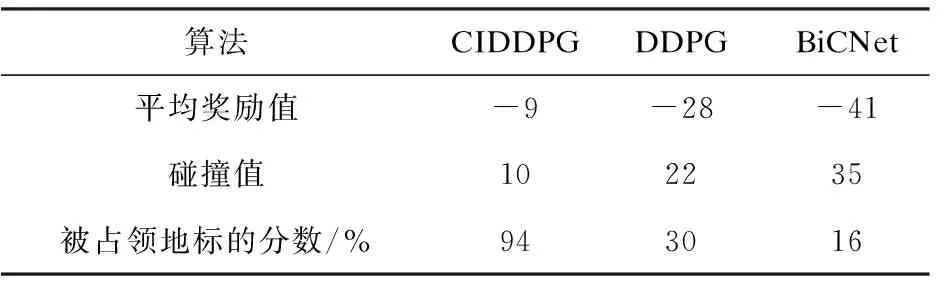
表1 合作导航实验结果
由表1可见,BiCNet和DDPG没有学习到CIDDPG获得的策略。在CIDDPG算法运行过程中,一名智能体首先试图占据最近的地标,如该地标更有可能被其他智能体占用,则转向另一个空闲地标,而不继续探测并接近最近的地标;DDPG算法的策略更激进,多个智能体通常同时接近一个地标,故可能导致碰撞;BiCNet算法中智能体比较保守,选择避免碰撞而不抢占地标,故会导致少量地标被占用,此外BiCNet的智能体更易围绕一个地标,观察其他智能体的动作,但聚集的智能体也易发生冲突。
带有通信机制的CIDDPG算法优于没有通信机制的DDPG算法,表明通信的确有益。带有通信机制的BiCNet性能较差,原因是通信网对隐藏层的信息进行算术平均,即平等对待来自不同智能体的信息。来自其他不同智能体的信息对于智能体决策具有不同的价值,大量无用的信息可看作干扰智能体决策的噪声。与BiCNet不同,CIDDPG利用调度机制及注意力机制动态地执行通信,多数信息来自附近的智能体,有助于其决策。
2.3 合作推球
在该场景下,N个智能体合作将一个重球推至指定位置。智能体通过碰撞而非通过力来推动球,并以不同角度击球来控制移动方向。实验中有20个智能体,每个智能体可以观察球的相对位置。
图6为CIDDPG及其对比算法的平均奖励学习曲线;表2为三种算法的合作推球实验结果。
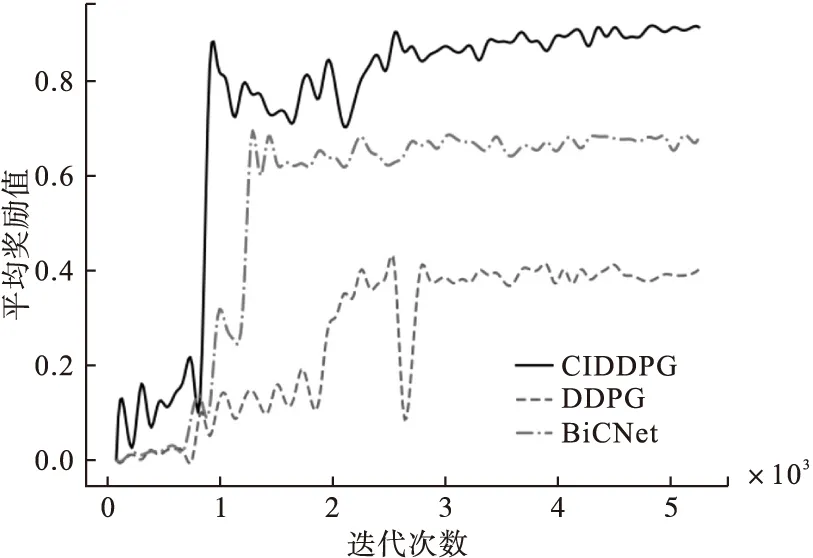
图6 合作推球平均奖励学习曲线

算法CIDDPGDDPGBiCNet平均奖励值0.910.40.68
由图6和表2均可看出,CIDDPG算法的平均奖励值明显高于BiCNet和DDPG算法,并且收敛速度快,最终获取的平均奖励值达到0.91,比没有通信的DDPG算法高出127%,比全通信的BiCNet算法高出33%。
带有通信优化的CIDDPG算法优于全通信的BicNet算法及没有通信的DDPG算法。CIDDPG中的智能体学习复杂的策略,智能体通过击中球的中心来推动球;通过击打球的侧面来改变运动方向;当球接近目标位置时,一些智能体会转向球运动的相反方向,与球碰撞以降低球的速度,阻止球通过目标位置;对移动方向和减速的控制通过通信来完成,体现了智能体之间的分工和协作。BiCNet中有沟通,故优于DDPG。DDPG智能体的行为相似,没有分工,几乎所有的智能体均从同一个方向推球,会导致方向偏离或很快通过并远离目标位置,DDPG智能体意识到推错方向后又一起转向相反方向,球被推回并受力,很难稳定在目标位置。
3 结论
提出一种基于通信的高效信息学习算法—CIDDPG。首先通过双向循环神经网络建立通信机制,然后将所有智能体信息进行编码,输入调度模块中,为每个智能体生成一个权重,权重排在前K名的智能体相互通信,选取合适的动作,输入到评价网络中。评价网络通过共享一个注意力机制,有选择地关注利于获取更大回报的信息进行学习,从而实现有针对性的策略迭代。采用本文的算法可有效利用每个智能体的信息,提高沟通协作能力,优化交互过程,实现合作决策。实验证明该算法具有较好的迭代效率和泛化能力,可明显提高平均回报值。但该算法会偶发震荡问题,解决该问题可从调度机制选取智能体通信的原则入手,找到更合适的选取通信智能体的条件,此为该算法未来的研究方向。
