基于特征融合的轻量级SSD目标检测方法
2021-10-15吴天成王晓荃蔡艺军荆有波陈铖颖
吴天成, 王晓荃, 蔡艺军, 荆有波, 陈铖颖
(1. 厦门理工学院 光电与通信工程学院,福建 厦门 361024; 2. 中国科学院 微电子研究所,北京 100029)
1 引 言
边防指的是维护国家领土主权和边疆的安定与发展,由边防武装力量在边境地区实施的武装防御和保卫活动[1]。随着信息技术发展的快速发展,边防管控技术的重心也逐渐向信息技术领域转移。本文依托中国科学院微电子研究所的边缘计算终端项目,针对边防监控中目标尺度较小、检测难度高等问题,主要研究提升目标检测算法的检测精度和小目标物体的检测能力,设计了应用于网络边缘嵌入式设备的目标检测算法,协助边防管控。
传统目标检测算法通过手工设计特征的方法并结合SVM[2]、Adaboost[3]等分类器的方法获得检测结果,但是该类方法在精度和速度上都不理想。随着深度学习技术的快速发展,依靠大量的训练数据,自动获取特征的目标检测技术已经代替了传统的目标检测方法[4-6]。基于深度学习的目标检测算法主要分为有两大类:一是双阶段目标检测算法,包括R-CNN[7]、Fast R-CNN[8]和Faster R-CNN[9]。上述几种方法的检测精度高,但耗时较大,且对硬件设备要求较高,部署到移动端设备上也存在较大困难;二是单阶段目标检测算法,单阶段算法直接在图片的多个位置进行分类和回归,从而大幅度提高算法的检测速度。包括YOLO[10]、 SSD[11]。SSD算法在整体回归的思想上,借鉴了YOLO,同时参考了Faster-RCNN的锚点框设计,在运行速度与检测精度上有了较好的平衡。
边缘计算终端主要由嵌入式设备构成,执行边防管控任务。针对嵌入式设备中的目标检测任务,MobileNetV2是Google提出的优秀的轻量级神经网络[12]。使用MobileNetV2对SSD网络进行优化,在牺牲部分检测精度的情况下大幅优化了其计算量和参数量,实现了在嵌入式设备中执行目标检测任务。本文在MobileNetV2-SSD的基础上,使用特征融合的概念对该模型对各个尺度目标的检测精度进行优化,并在边缘计算终端中的Jetson AGX Xavier设备中对模型进行测试。
2 理论基础
2.1 MobileNetV2
2.1.1 深度可分离卷积
使用深度可分离卷积减小模型参数量是轻量化网络MobileNet的核心思想[13]。深度可分离卷积标准卷积分为深度卷积和逐点卷积两个过程,在输出和标准卷积一致的情况下,大幅减小了参数量。
图1所示为标准卷积过程。图2和图3分别为深度卷积和逐点卷积过程。

图1 标准卷积Fig.1 Standard convolution

图2 深度卷积 Fig.2 Depthwise convolution
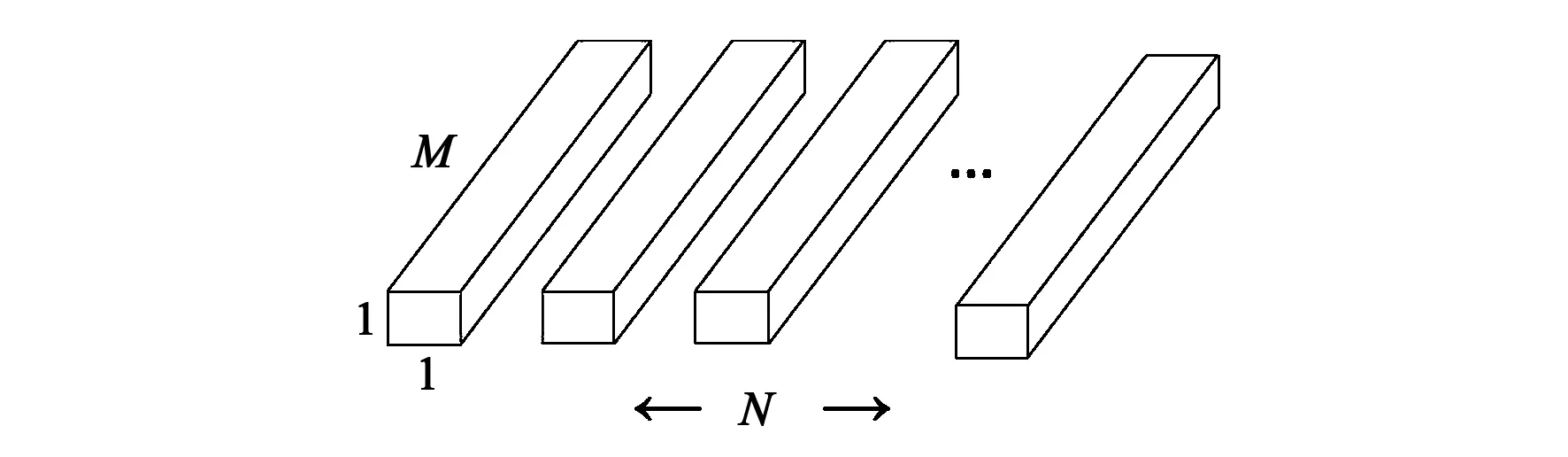
图3 逐点卷积Fig.3 Pointwise convolution
图中D为卷积大小,M是卷积通道数,N表示卷积的个数,M为卷积核的个数。假设输入F的大小为(DF,DF,M),采用的传统卷积核K的大小为(DK,DK,M,N)。
深度卷积和逐点卷积的参数量相加为深度可分离卷积的参数量,其结果与标准卷积参数量相比如式(1)所示:

(1)
由公式(1)比较发现,MobileNet网络模型参数数量大幅减少,降低了计算开销。由此,深度可分离卷积方法改进了采用传统卷积的YOLO、SSD网络的参数冗余等问题,更适合部署至嵌入式设备。
2.1.2 线性瓶颈层
线性瓶颈层是MobileNetV2相对于MobileNetV1做出的改进[12]。MobileNetV2中在深度分解卷积之前使用逐点卷积用于扩张输入数据的维度,使得网络后续的卷积操作可以在高维空间提取更多特征信息。引入线性瓶颈层将低维度信息映射到高纬度中,避免了MobileNetV1中由于ReLU非线性激活函数造成的特征信息损失。
2.1.3 倒残差块
倒残差块结构是基于ResNet中残差块所提出的一种操作方法[12]。ResNet残差块和 MobileNetV2的倒残差块结构图如图4所示。
图4中 MobileNet V2的倒残差块使特征图的维度先升后降,与残差块的功能正好相反,因此后者被称为倒残差结构。倒残差块结构可以使深度分离卷积在高维度空间上提取更多的特征,以此来获取更多语义特征。

图4 Residual Block和Inverted Residual Block结构对比Fig.4 Comparison between Residual Block and Inverted Residual Block
2.2 SSD算法
SSD算法采用VGG-16网络结构为特征提取网络,并在ⅤGG-16后接入多个大小依次减小的特征提取层,生成不同尺寸特征金字塔以检测不同大小的目标。尺寸较大的特征图检测体积比较小的目标物,尺寸较小的特征图检测体积较大的目标物[14]。SSD还使用了不同宽高比锚点框,使其能够高效地检测不同尺度的目标。SSD的结构图如图5所示。
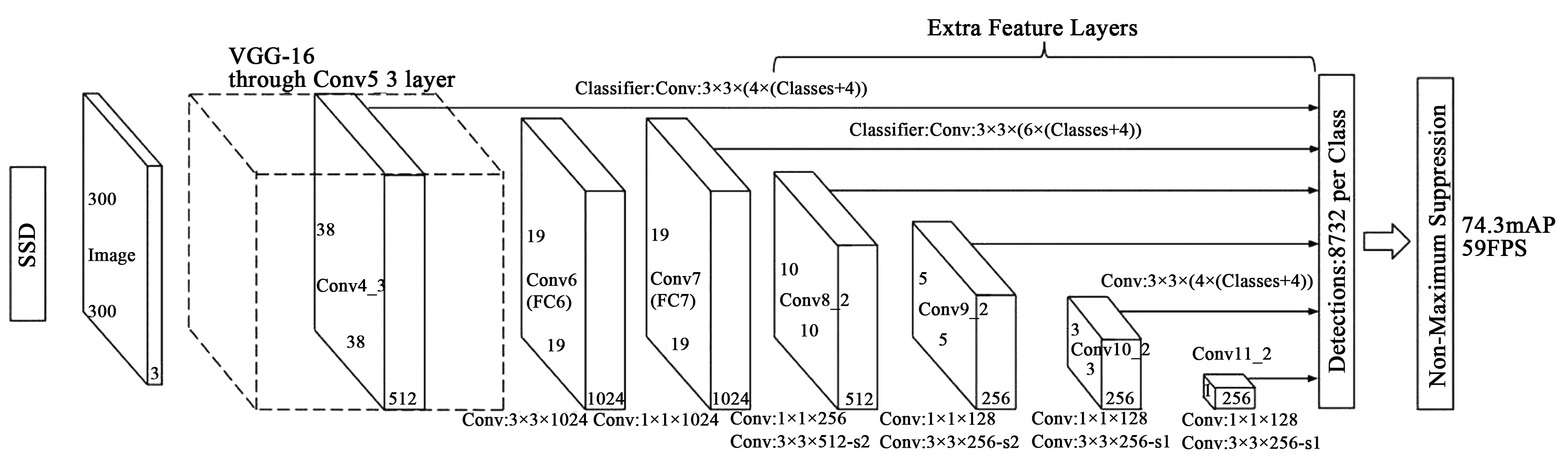
图5 SSD结构图[14]Fig.5 Structure map of SSD[14]
SSD舍弃了VGG16最后的全局池化部分和全连接层(FC6、FC7)并且分别用3×3×1 024的conv6卷积层和1×1×1 024的conv7卷积层替代VGG-16中的FC6和FC7作为基础分类网络的最终特征抽取部分。通过不同尺度的卷积层在图像上做特征提取,然后回归得到锚点框的具体位置以及各类型分类的置信度,最终通过非极大值抑制算法得到最终结果。
2.3 FPN
Tsung-Yi Lin等人提出了特征金字塔网络(Feature Pyramid Network, FPN)的概念,FPN的原理是融合不同尺寸的特征图,并在融合后的特征图上进行预测[15]。FPN能够很好地利用卷积神经网络中不同层级的语义特征和特征细节,对特征图自上到下进行连接,将带有更多局部特征细节的高分辨率特征图和带语义信息较强的低分辨率特征图连接起来。图6是FPN的结构示意图。
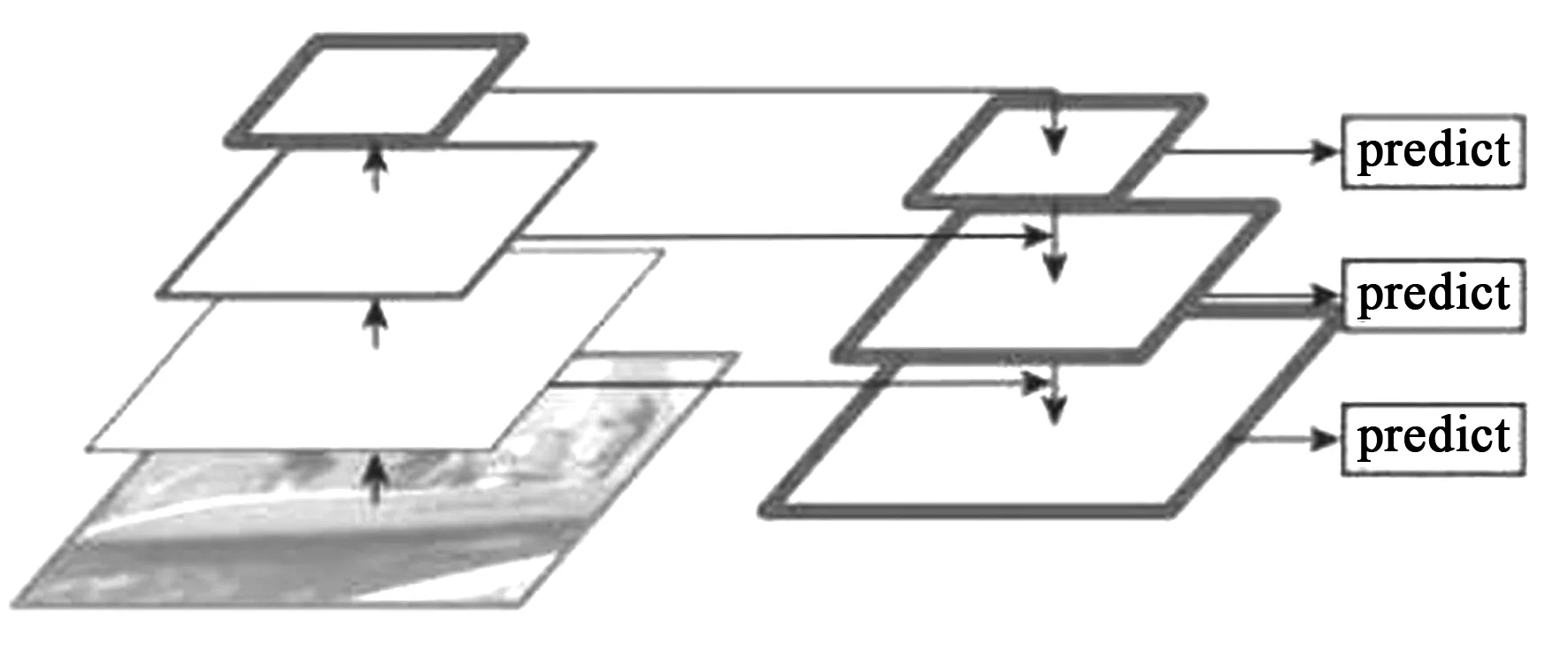
图6 FPN框架[15]Fig.6 Frame of FPN
2.4 MobileNetV2-SSD分析
MobileNetV2-SSD以300×300×3尺寸的图像作为输入,使用MobileNetV2提取特征图,然后使用SSD模型中的6个检测层对不同尺度的目标进行多尺度的检测。其中在步长为1的卷积层之间均采用了shortcut结构来加快训练。该网络采用了Inverted Residual Block结构使卷积层能够在更高维度获取更多的语义信息。使用Linear线性激活函数避免了MobileNetV1中非线性激活函数对特征图信息的破坏。删去了MobilenetV2全连接层,以4组倒残差块结构作为替换,即bottleneck。并使用主干网络中的Conv13_expand、Conv16_pw以及在Conv19_2、Conv19_3、Conv19_4和Conv19_5这4层进行多尺度的目标检测。其中expand代表对特征通道的扩张,扩张可以在特征信息不损失和参数量不增加的前提下加大卷积层的感受野范围,pw代表逐点卷积。MobileNetV2-SSD网络结构图如图7所示。
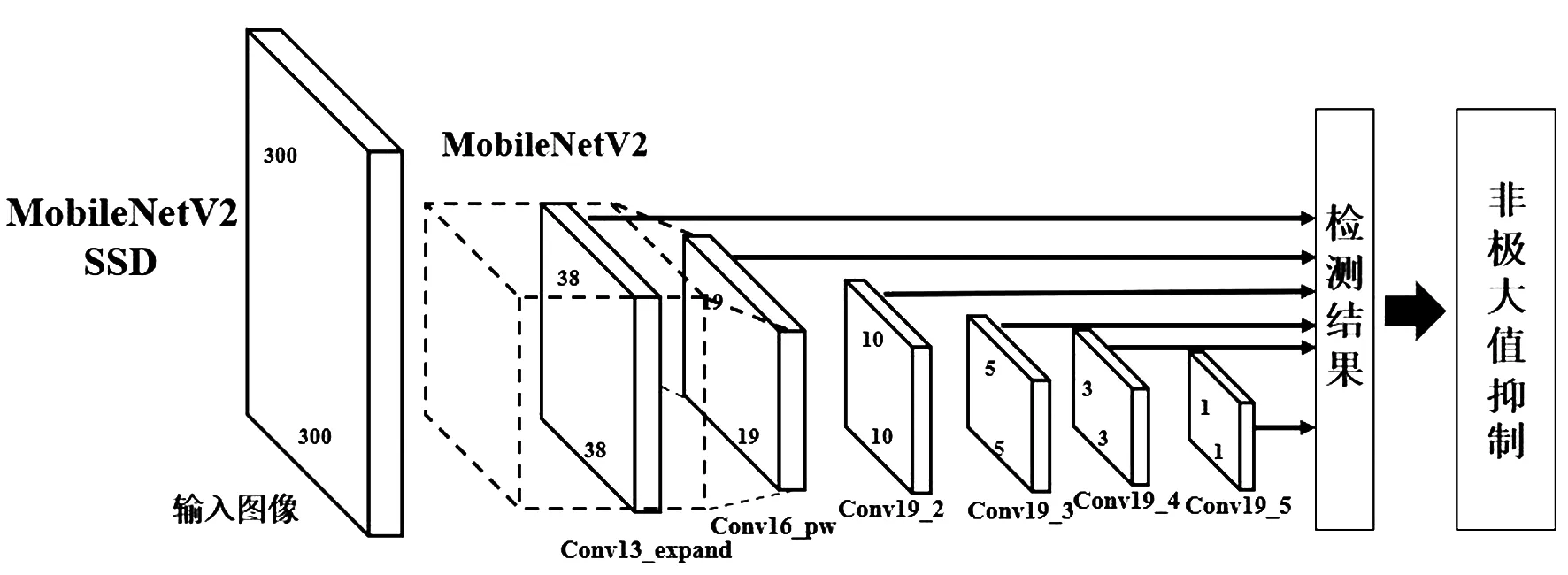
图7 MobileNetV2-SSD结构图Fig.7 Structure map of MobileNetV2-SSD
3 算法改进
本文基于FPN特征融合的思想,设计了一种轻量级特征融合方式,在MobileNetV2-SSD网络结构的基础上实现特征融合,提升模型的检测精度。
3.1 存在问题
MobileNetV2-SSD会将输入的图片特征提取成不同尺度的特征图进行预测,但是仅是在不同的特征图上完成预测,并没有融合不同尺度的特征图,不能充分利用深层语义特征和局部特征的细节,对于小目标的检测效果并不好(小目标指像素区域小于30×30的目标)。FPN 为逐层特征融合机制,新生成的特征金字塔上每层特征图,将同层和高层的特征信息融合,网络结构复杂,整体操作耗时,加强了检测精度的同时牺牲了过多的检测速度,难以达到实时检测的效果。
3.2 改进策略
3.2.1 设计思路
FPN为逐层特征融合机制,同层和高层的特征信息融合,生成新的特征金字塔,整体操作耗时大且网络结构复杂。不同于FPN中的逐层融合,本文在原FPN模型的基础上新增了特征融合模块,使特征融合只在一个位置发生。
3.2.1 特征层选取
原模型采用Conv13,Conv16_pw,Conv19_2,Conv19_3,Conv19_4,Conv19_5上进行边框回归和分类,其对应的分辨率分别为38×38,19×19,10×10,5×5,3×3,1×1。Conv19_3,Conv19_4,Conv19_5这3层的特征层过小,语义信息不丰富,与原始上一层特征图融合之后不会得到太多的语义信息,对模型精度并无提升,甚至还会降低检测速度,因此不对这3层进行特征融合。分别对Conv13,Conv16_pw,Conv19_2这3层网络进行特征融合。
3.2.2 特征融合
如图8所示,分别对Conv13,Conv16_pw,Conv19_2这3层网络进行特征融合。使用1×1 卷积统一输入通道,bilinear interp意为双线性插值,实现上采样操作,将不同大小的特征图转换成统一大小,融合的不同网络层。

图8 本文特征融合示意图Fig.8 Schematic diagram of feature fusion in this paper
FPN中使用的 element操作融合不同尺度的特征图,element要求特征图的大小和通道数均保持统一,FPN中使用 1×1 卷积统一融合时的通道数。在本文模型中,1×1 卷积只负责降低通道,融合时选用了Concat操作(图(9)),简单有效,可以不改变其原有的值,将两张特征图的通过维度相加结合,不需要特征图通道统一。

图9 Concat操作示意图Fig.9 Concat operation diagram

(a)原图 (a)Original image
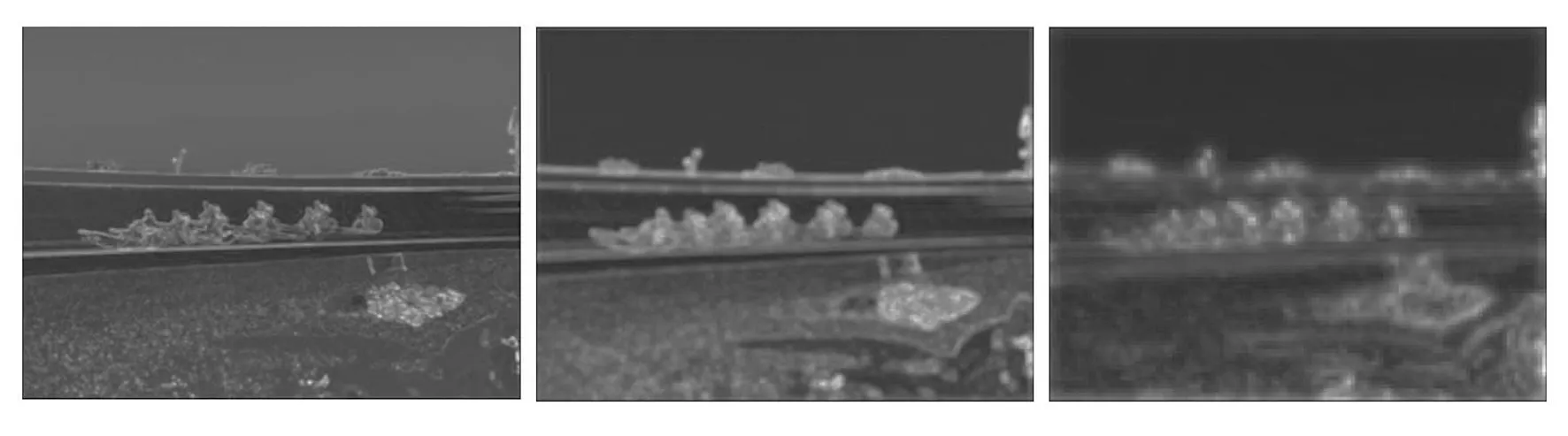
(b)特征融合前图像 (b) Image before feature fusion

(c)特征融合后图像 (c)Feature fusion image图10 特征融合效果图Fig.10 Feture fusion effect picture
我们输出不同层级的特征图使其可视化,展示特征融合前后的对比,结果如图 10 所示。图10中(a)为原图,(b)分别为特征融合前Conv13,Conv16_pw,Conv19_2三层卷积层输出的特征图像,(c)为融合这3层后输出的特征图像。从图10可以得出,低层特征层分辨率较高,包含更多图像细节,但是由于经过的卷积更少,语义信息较弱,噪声更多。高层特征更为抽象,具有更强的语义信息,但是分辨率很低,对细节的表达更差。特征融合后的特征图像中重要的特征信息更加明显,有助于提高目标检测精度。
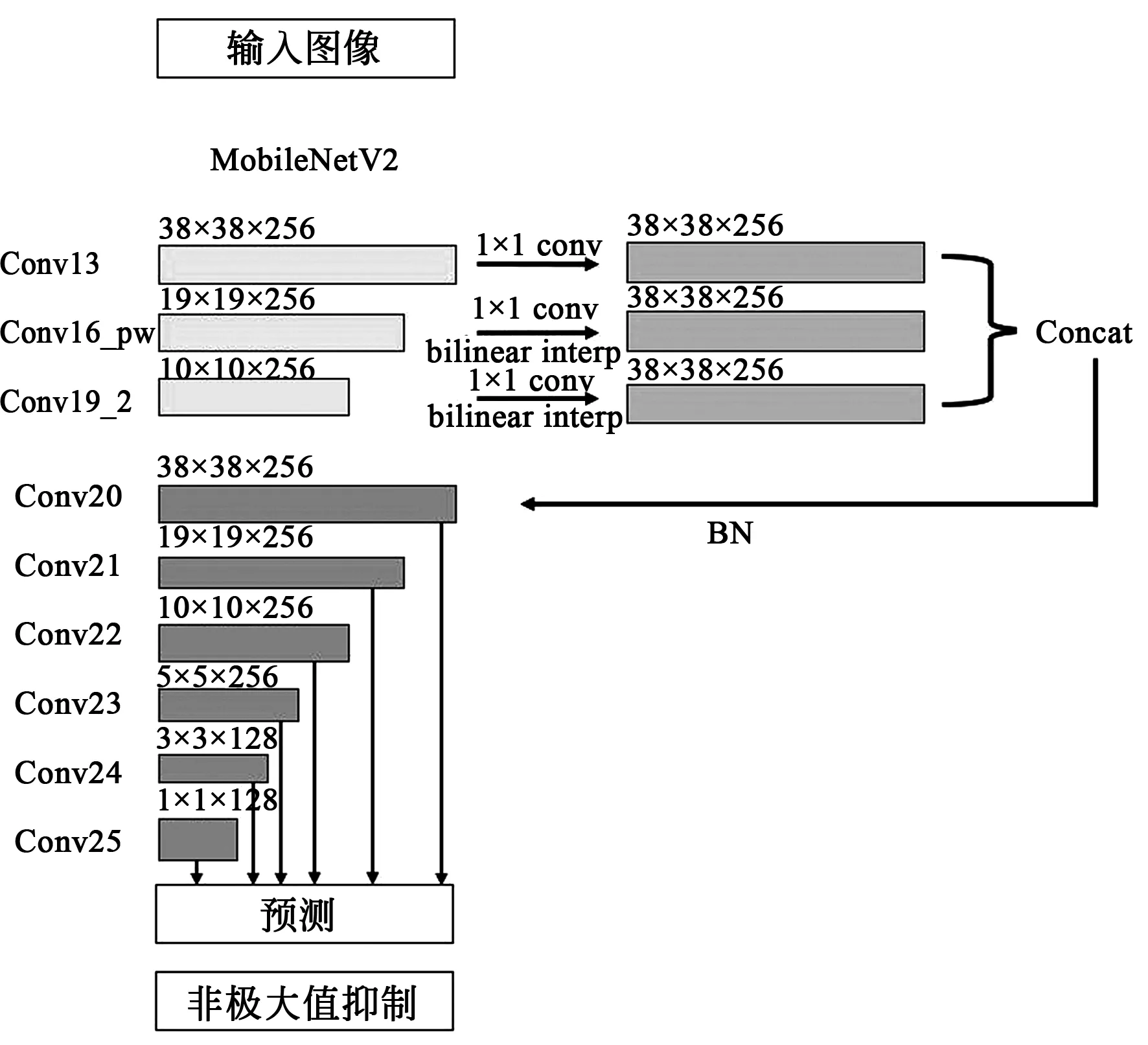
图11 改进后的网络结构Fig.11 Improved network structure
使用BN(Batch Normalization)正则化Concat融合后的特征图,BN层可以实现归一化处理,改善网络的梯度,防止梯度爆炸。完成改进后的网络结构如图11所示。当输入图像的分辨率为 300×300时,使用Conv13,Conv16_pw,Conv19_2三层进行特征融合。经过融合得到Conv20,对融合的特征图进行下采样,重新生成类似SSD的多尺度金字塔型特征层,Conv20~Conv25一起用于预测。
4 实验结果与分析
4.1 实验准备
为了检验优化后MobileNetV2-SSD算法的有效性,本文使用PASCAL VOC2007和VOC2012数据集共16 551张图片对模型进行联合训练,并用VOC2007测试集共4 953张图片进行测试,并将测试结果与原始MobileNetV2-SSD算法结果进行比较和分析。
4.2 评估标准
本文使用平均精度均值(mean average precision,mAP)、FPS(rames per second)、MB(MByte)这3类指标分别评估模型的精度、速度和模型大小,以验证模型的性能。其中mAP是评估目标检测模型精度的重要指标,其计算公式如公式(2)、(3)、(4)所示。
(2)
(3)
(4)
其中:TP表示图像中当前类别正确检测的次数,TotalObjection表示当前图像中类别的实际目标数量,TotalImg表示包含当前类别目标在所有图像的数量,P表示准确率,C表示需要识别目标的总类别数,AP表示单个目标的平均精度值,最后计算出mAP为所有目标类别的平均精度均值。
4.3 模型训练参数
模型训练时将每次迭代输入的样本数量batch_size设置为64。Learning _rate学习率用于控制模型训练速度,取值过大会导致参数越过最优值,取值过小会导致模型收敛速度慢,将学习率初始化为0.001,权重衰减weight_decay设置为 0.000 1,防止产生过拟合现象。
4.4 实验结果
对模型的大小和精度进行对比,在该部分实验中加入了SSD模型进行比较,3种模型性能的比较如表1所示。

表1 目标检测模型性能比较Tab.1 Object detection model performance comparison
3种模型的输入图像大小同为300×300,本文改进的模型大小稍大于MobileNetV2- SSD,在mAP上提升了3.6%,接近了原SSD模型。同时模型大小也远小于传统的SSD模型,与MobileNetV2-SSD相差仅为8.8 MB。表2列举了部分不同尺寸的目标,分别使用本文改进模型和MobileNetV2- SSD的检测精度试验结果。如表2所示,本文改进模型在不同尺度目标的检测精度均好于MobileNetV2-SSD,尤其是sheep、bird、bottle以及potted plant等较小的目标,精度有了较大提升。这是由于改进后的模型融合了不同尺度的特征层,能够获取图像中更多小目标的特征信息。选择了带有小目标的检测结果图进行对比,图12为MobileNetV2-SSD的检测效果,图13为本文改进模型的检测效果。上述实验证明了特征融合的方法可以增强多尺度检测模型的目标检测精度。

表2 不同尺寸目标检测性能比较Tab.2 Comparison of detection performance of different size targets (%)

图12 MobileNetV2-SSD检测效果Fig.12 MobileNetV2-SSD detection results

图13 本文模型检测效果Fig.13 Improved model detection results
将模型部署至边缘计算终端中的Jetson AGX Xavier设备中,测试MobileNetV2-SSD和本文改进后的模型在嵌入式设备中的检测速度,验证其在嵌入式设备中执行实时目标检测任务的可行性。Jetson AGX Xavier上部署了Ubuntu 18.04 LTS aarch64操作系统,并具有512核高性能Volta GPU。测试中FPS代表模型在设备中的解析速度。

表3 目标检测模型性能比较Tab.3 Object detection model performance comparison
由于采取了轻量级的特征融合策略,本文改进后的模型在FPS上相对于原模型仅下降了4帧/s左右的速率(表3)。在精度提升的同时,依然可以在嵌入式设备实现实时检测,协助边缘计算终端完成边防管控。
5 结 论
本文依托边缘计算终端项目,设计了一种可以部署在嵌入式设备的目标检测模型。介绍了轻量级神经网络MobileNetV2、SSD目标检测模型和FPN特征金字塔网络,指出了MobileNetV2-SSD和FPN特征融合存在的问题,提出了一种轻量级的特征融合方案用于改进MobileNetV2-SSD。改进后的模型与MobileNetV2-SSD在VOC2007测试集上进行测试比较,获得了更高的模型精度,相对于MobileNetV2-SSD提升了3.6%,达到了76.5%,并且,在小目标的检测效果上获得了显著提升。此外将模型部署至嵌入式设备比较检测效果,改进的模型在网络结构更加复杂的情况下,在检测速度上并没有较大损失。从而验证了本文方法的有效性。本文方法可以协助边缘计算终端完成边防管控,在嵌入式设备上实现更高效的目标检测。
