嗅觉可视化技术对啤酒品质的快速检测
2021-09-28翟晓东黄晓玮邹小波
杨 梅,翟晓东,黄晓玮,李 崎*,邹小波,*
(1.江南大学生物工程学院,江苏 无锡 214122;2.啤酒生物发酵工程国家重点实验室,青岛啤酒股份有限公司,山东 青岛 266100;3.江苏大学食品与生物工程学院,江苏 镇江 212013)
啤酒是以麦芽、酒花、水为主要原料,并在酵母菌作用下进行酿造而形成的一类饮料。啤酒按照酿造工艺可以分为2 种,分别为上发酵啤工艺和下发酵工艺[1]。上发酵工艺是指酵母在麦芽汁顶部发酵,特点是发酵温度高、时间短,以此生产出来的啤酒一般称为Ale啤酒。下发酵工艺是指酵母在麦芽汁底部发酵,特点是发酵温度低、时间长,以此生产出来的啤酒一般被称为Lager啤酒。另一种分类方式按照啤酒的色泽进行分类,通常分为淡色啤酒、浓色啤酒、黑色啤酒。此外,还有使用乳酸菌进行二次发酵的白啤;采用无菌技术酿造的纯生啤酒;加入果汁酿造而成的果啤等。这些生产原料以及酿造工艺的区别赋予啤酒不同的品质,而品质检测是保障啤酒品质的关键程序。
目前,啤酒品质评价最直接的方法是人工感官评定法[2],但感官评定容易受到嗅觉疲劳等客观因素的影响。其次,在理化检测方法中,较常用的方法有气相色谱-质谱(gas chromatography-mass spectrometry,GC-MS)法[3-4]和高效液相色谱(high performance liquid chromatography,HPLC)法[5-6]等。这些方法能够准确测定啤酒中的各种成分,但分析过程耗时长、步骤繁琐。电子鼻系统能够实现食品气味成分的检测,且具有快速、无损的优点。电子鼻在酒类品质检测中的研究已有报道[7-8],但是电子鼻系统采用的金属氧化物传感器价格相对昂贵。
嗅觉可视化技术可以利用可视化传感器与待测气体反应前后的颜色变化对待测物进行定性、定量分析[9]。其原理在于嗅觉可视化传感器与待测分子之间可以通过范德华力、氢键等作用力,以及金属键、极性键等较强化学反应产生信号[10]。相比于GC-MS和HPLC,嗅觉可视化技术具有检测速度快、成本低等优势。而相比于电子鼻系统,嗅觉可视化成像更加直观、快速,同时降低了成本,因此更适合大批量检测。目前,嗅觉可视化技术在多种食品品质检测中的可行性得到了验证,包括肉品[11-12]、小麦[13]、红茶[14]和蔬菜[15]等固态食品,以及香醋[16]、白酒[17]和咖啡[18]等液态食品。然而,嗅觉可视化技术在啤酒品质检测中的研究仍较少[19]。
由于啤酒中含有各种酯、高级醇、醛、有机酸和硫化物等挥发性化合物[20-21],而不同的啤酒挥发性成分具有一定的差异,因此这些挥发性物质可作为其特异性识别分子。青岛啤酒是我国最早的啤酒品牌之一,畅销国内外,深受消费者的好评。利用嗅觉可视化技术对青岛啤酒品质的快速、无损检测目前鲜见报道。因此,本研究拟利用嗅觉可视化传感器对不同种类的青岛啤酒进行定性区分以及关键品质指标的定量预测,为实现啤酒品质的快速、无损检测提供一种有效方法。
1 材料与方法
1.1 材料与试剂
同批次的纯生、1903、奥古特、白啤、黑啤、皮尔森、IPA、Strong共8 种啤酒样品,每种啤酒20 瓶、每瓶330 mL 青岛啤酒有限公司。
氯苯、乙醇、邻苯二胺、盐酸 国药集团化学试剂有限公司;无水乙醇(≥99.7%)、卟啉、卟啉化合物美国Sigma-Aldrich公司。
1.2 仪器与设备
数显恒温水浴锅 江苏金怡仪器科技有限公司;BS-224S分析天平 德国Sartorius仪器设备制造有限公司;Cary100紫外-可见光光度计 美国Agilent科技公司;CC-4603-01毛细管 亚速旺(上海)商贸有限公司;KQ-100KDE超声波清洗器 昆山市超声仪器有限公司;嗅觉可视化检测系统由本实验室自主搭建。
1.3 方法
1.3.1 样品制备
所有啤酒以未开封状态,置于4 ℃的冰箱中密封冷藏保存。啤酒、苦味和色度等参数由青岛啤酒公司提供,如表1所示。
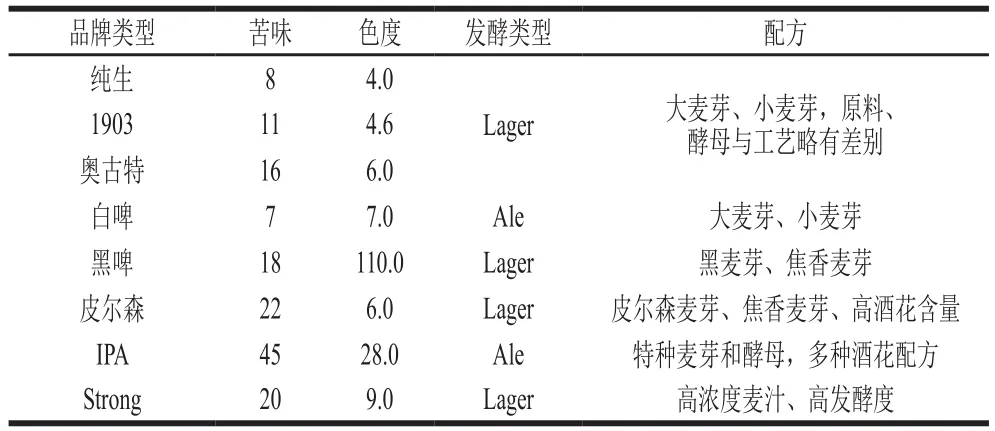
表1 8 种不同类型的青岛啤酒样品Table 1 Information of eight Tsingtao beer samples examined in this study
1.3.2 嗅觉可视化传感器的制备
选取具有较强响应信号的9 种卟啉类化合物以及7 种酸碱指示剂,制备成4×4的嗅觉可视化传感器阵列。
将聚四氟乙烯薄膜裁剪成3 cm×3 cm的正方形基底材料备用。卟啉以及卟啉类化合物分别溶解于氯苯中,酸碱指示剂溶解于无水乙醇中。2 种溶液的浓度均为0.05 mol/L,超声振荡50 min后,置于4 ℃冰箱内保存备用。使用100 mm×0.3 mm的毛细管作为微量取样器。将金属卟啉溶液以及10~16的传感器材料(依次为中性红、亚甲基蓝、溴酚蓝、溴甲酚绿、溴甲酚紫、甲基红、百里酚蓝)分别滴1 滴样在聚四氟乙烯薄膜上,形成4×4的传感器阵列,制作完成的传感器阵列置于通风橱中自然风干,风干完成后迅速置于黑暗、且充满氮气的密封环境中保存。制作的嗅觉可视化传感器阵列如图1所示。

图1 嗅觉可视化传感器阵列Fig.1 Image of the olfactory visualization sensor array
1.3.3 啤酒质量指标的测定
根据GB/T 4928—2008《啤酒分析方法》中方法对啤酒的乙醇体积分数(容量法)、原麦汁质量分数(密度瓶法)和双乙酰质量浓度进行测定。
1.3.4 响应信号的采集与提取
嗅觉可视化传感器的实验装置与数据采集均参考文献[22]方法。分别对8 种啤酒进行15 次平行测试,获取嗅觉可视化传感器与啤酒样本挥发性成分发生反应前后的图像。通过Matlab2018软件提取传感器阵列上每个传感器区域的红(R)、绿(G)、蓝(B)平均值。传感器反应前后的R、G、B均值的差值取绝对值作为传感器的响应信号,分别按照式(1)~(3)[23]计算。

式中:ΔR、ΔG和ΔB分别为传感器反应前后R、G、B均值的差值绝对值;Ra、Ga和Ba分别为传感器反应前的R、G、B均值;Rb、Gb和Bb分别为传感器反应后的R、G、B均值。
2 结果与分析
2.1 啤酒质量指标分析
表2显示了8 种青岛啤酒的乙醇体积分数、原麦汁质量分数和双乙酰质量浓度。由于Strong啤酒的高原麦汁质量分数和高发酵度,其3 种质量指标均最高,而纯生啤酒的3 种质量指标含量均最低。其中,Strong啤酒乙醇体积分数(9.0%)约为纯生啤酒(3.1%)的3 倍;其他6 种啤酒的乙醇体积分数较为接近,处于4.1%~5.8%之间。两者的原麦汁质量分数也相差较大,Strong啤酒原麦汁质量分数(21.0%)约为纯生啤酒(8.1%)的2.6 倍。其他6 种啤酒的原麦汁质量分数处于10.4%~15.8%之间。由于啤酒的原麦汁质量分数很大程度上决定了啤酒的乙醇体积分数,因此原麦汁质量分数与乙醇体积分数的测量结果较为类似。其中,黑啤原麦汁质量分数也较高,可能是因为黑啤中加入了焦糖,使测得的啤酒真正浓度的值较高,从而引起测得的原麦汁质量分数的值较高。Strong啤酒双乙酰质量浓度(0.11 mg/L)约为纯生啤酒(0.03 mg/L)的4 倍,其他6 种啤酒的双乙酰质量浓度处于0.04~0.10 mg/L之间。
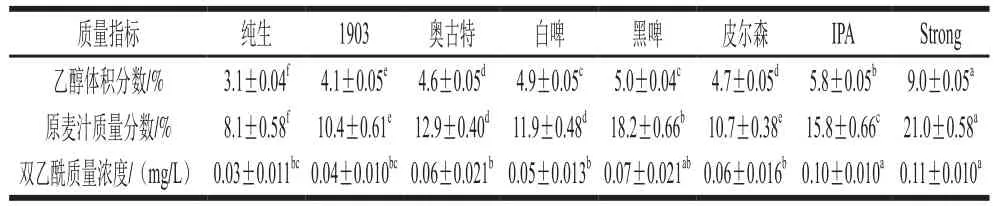
表2 8 种不同啤酒的质量指标Table 2 Quality indicators of eight kinds of beer
2.2 嗅觉可视化传感器对不同种类啤酒的判别分析
2.2.1 不同啤酒的传感器响应特征
由图2可知,不同色素与不同的啤酒样品反应后呈现出不同程度的颜色变化,其中,Strong啤酒的传感器阵列颜色变化值与其他7 种呈现出明显的不同,这与其质量指标含量均最高的特征一致。

图2 嗅觉可视化传感器与不同种类啤酒反应后的RGB差值图像Fig.2 RGB difference images of the olfactory visualization sensor array in response to different beer samples
2.2.2 主成分分析(principal component analysis,PCA)每个嗅觉可视化传感器阵列有16 个传感色素点,而每个色素点拥有ΔR、ΔG和ΔB这3 个颜色变量,因此每个嗅觉可视化阵列的变量个数为48。PCA通过正交变换对可能存在相关性的变量转换为线性不相关的变量,在对变量进行降维的同时,也尽可能多地保留了原始变量特征[24]。图3为嗅觉可视化传感器前3 个PC投影图。可以发现8 种不同种类的啤酒基本能被清晰地区分开。前3 个PC
方差贡献率的之和为66.60%。但是奥古特、纯生和1903
牌啤酒在图3中的离散程度相对于其他样品较低。可能是因为这3 种啤酒均为Lager啤酒,只是在配方、酵母品种和制作工艺上略有差别。此外,IPA牌啤酒和黑啤的点阵与其他点阵分隔明显较远。可能是由于IPA采用了特种麦芽和特种酵母,从而比其他啤酒具有更加浓郁的酒花香气;而黑啤中添加黑麦芽和焦香麦芽等原材料,其风味较其他啤酒有明显不同。

图3 不同啤酒的前3 种PC的三维投影图Fig.3 Three-dimensional score pot of top three principal components for different beer samples
2.2.3 邻算法模型(K-nearest neighbor,KNN)识别
KNN模型通过对距离度量函数计算出待测样本x与每个预测样本集数据的距离,并对计算出的距离进行排序。如果一个样本在特征空间中的K个最相邻样本中的大多数属于某一个类别,则该样本也属于这个类别[25]。KNN模型以PCA的分向量作为输入向量,每个样品对应的类别作为输出向量,采用不同的PC数和K值对模型进行优化,以校正集的最高识别率作为判断优化结果理想程度的依据。按照2∶1的比例将120 个啤酒样品随机分为校正集组(80 个)和预测集组(40 个)。选取前10 个PC数和9 个参数K值对KNN模型进行同步优化,结果如图4所示。当参数K为7,PC数为10时,校正集的识别率达92.5%,预测集的识别率达87.5%。
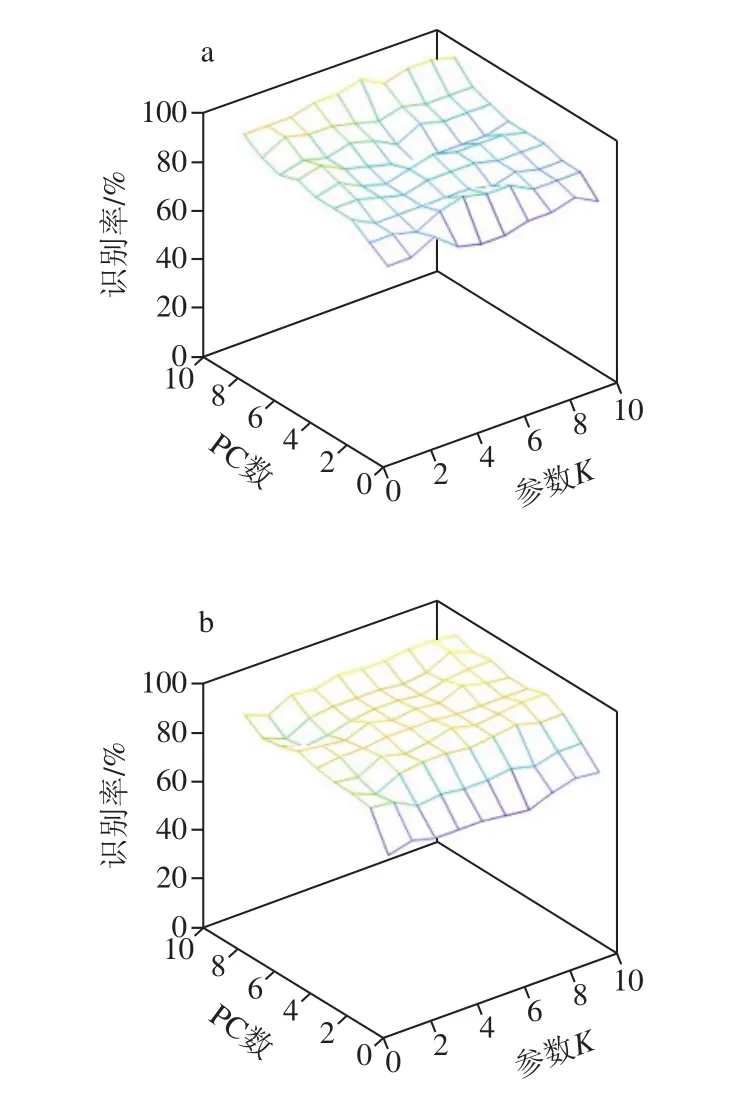
图4 不同种类啤酒的KNN模型的校正集(a)、预测集(b)结果Fig.4 Results of KNN model discrimination of different beer samples in calibration (a) and validation sets (b)
2.2.4 线性判别分析(linear discriminant analysis,LDA)模型识别
与PCA类似,LDA也是一种降维方法,其基本思想是将多维数据投影到低维空间,将不同组的数据尽可能分开,使得新生成的组有最大的组间距离和最小的组内距离[26-27]。LDA同样以PCA的分向量作为模型的输入变量,每个样品对应的类别作为输出变量。如图5所示,当PC数从1逐渐上升时,校正集和预测集模型的识别率也逐渐上升;而当PC数超过3时,校正集和预测集的识别率有所下降。当PC数为3时,预测集和校正集的识别率均达到最高的100%。出现此情况的原因可能是当PC数较小时,数据量不足以对样本做最精确的分类;当PC数超过3并逐渐增加时,出现了冗余信息,因此识别率降低。因此,PC数为3时,能够取得最佳预测效果。
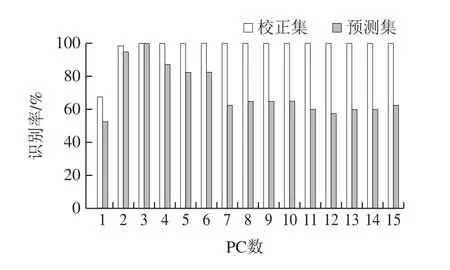
图5 不同种类啤酒的LDA模型的校正集和预测集结果Fig.5 Results of LDA model for different beer samples in calibration and validation sets
综上所述,KNN和LDA模型都能够对不同的青岛啤酒进行定性区分。其中LDA模型选用的PC数比KNN少,而识别率更高。因此,建立的LDA模型为不同青岛啤酒的最佳定性判别模型。
2.3 嗅觉可视化技术对啤酒质量指标的定量预测
2.3.1 偏最小二乘(partial least square,PLS)法模型分析
PLS法是经典的多元校正方法,能够克服常见的数据集共线性问题[28]。由于嗅觉可视化传感器中的不同传感器点可能存在同时对某一类或者多类物质具有响应的特征,使得传感器点的色度值之间存在相关性,因此PLS适用于嗅觉可视化传感器的数据分析[29]。本研究中,将嗅觉可视化数据的PC作为自变量,啤酒理化指标的实际测量值为因变量,构建啤酒理化指标的定量模型。一般情况下,PLS模型中的交叉验证均方根误差(root mean square error of cross validation,RMSECV)越小,建立的预测模型的预测能力越强。本研究根据啤酒质量指标将120 个样本排序,每3 个样本中选取中间样本为预测集(40 个),另外2 个样本为校正集(80 个)。PLS对啤酒的乙醇体积分数、原麦汁质量分数和双乙酰质量浓度的预测效果如表3所示。当PC数为5时,PLS模型对乙醇体积分数的预测能力最强。校正集的RMSECV和相关系数Rc分别为0.186%和0.993 6(图6a1);预测集均方根误差(root mean square error of prediction,RMSEP)和相关系数Rp分别为0.143%和0.996 6(图6a2)。当PC数为7时,PLS模型对原麦汁质量分数的预测能力最强。校正集RMSECV和Rc分别为0.729%和0.982 7(图6b1);预测集RMSEP和Rp分别为0.675%和0.986 9(图6b2)。当PC数为6时,PLS模型对双乙酰质量浓度的预测能力最强。校正集RMSECV和Rc分别为0.302 mg/L和0.983 0(图6c1);预测集RMSEP和Rp分别为0.254 mg/L和0.988 2(图6c2)。在最佳PC数下,3 种质量指标的PLS模型的校正集与预测集散点图如图6所示。因此,PLS模型对啤酒这3 种质量指标的定量预测效果较好。

表3 PLS模型对啤酒质量指标的预测结果Table 3 Results of prediction of quality indicators of beer samples by using PLS model
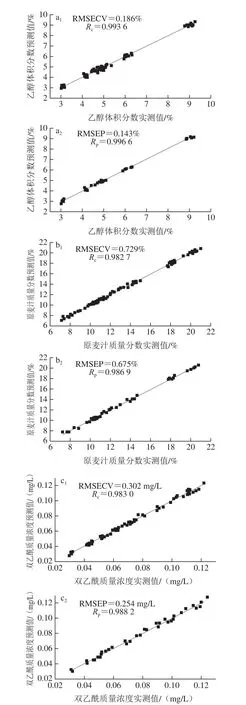
图6 啤酒质量指标的PLS模型Fig.6 Plots of PLS model predicted values against measured values for quality indicators of beer samples in calibration and prediction sets
2.3.2 最小二乘支持向量机(least squares-support vector machines,LS-SVM)模型分析
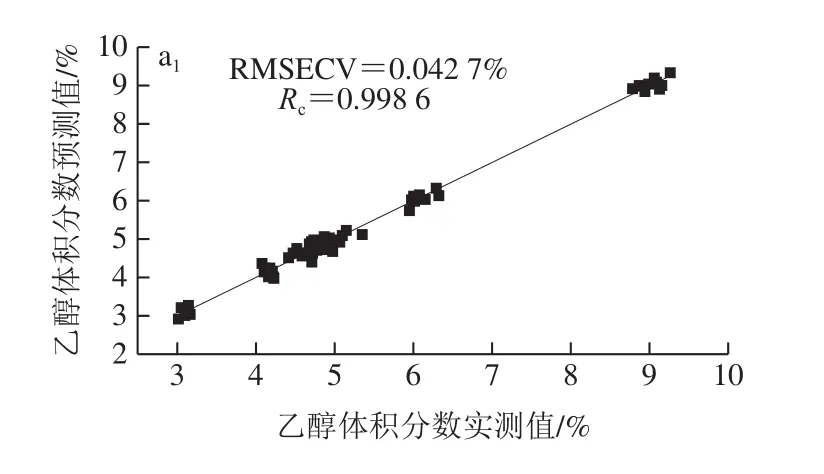
LS-SVM利用解线性等式代替SVM中的二次规划问题,是SVM的改进版本[30]。LS-SVM建模过程采用径向基核函数(radial basis function,RBF)为核函数,并结合二部格点搜索法和留一法寻找最优的RBF正则化参数γ和核函数参数σ2。LS-SVM对啤酒的乙醇体积分数、原麦汁质量分数和双乙酰质量浓度的预测结果如表4所示。当最佳参数组合(γ,σ2)为(269.65,181.96)时,LS-SVM模型对乙醇体积分数的预测能力最强。LS-SVM模型得出乙醇体积分数的校正集RMSECV和Rc分别为0.042 7%和0.998 6(图7a1),LS-SVM模型得出乙醇体积分数的预测集RMSEP和Rp结果分别为0.108 0%和0.997 0(图7a2)。当最佳参数组合(γ,σ2)为(13 248.94,42.58)时,LS-SVM模型对原麦汁质量分数的预测能力最强。LS-SVM模型得出原麦汁质量分数的校正集RMSECV和Rc结果分别为0.376%和0.994 9(图7b1);LS-SVM模型得出原麦汁质量分数的预测集RMSEP和Rp结果分别为0.611%和0.988 3(图7b2)。当最佳参数组合(γ,σ2)为(10 059.51,109.13)时,LS-SVM模型对双乙酰质量浓度的预测能力最强。LS-SVM模型得出双乙酰质量浓度的校正集RMSECV和Rc分别为0.117 mg/L和0.998 9(图7c1);预测集RMSEP和Rp分别为0.244 mg/L和0.989 2(图7c2)。在最佳PC数下,3 种质量指标的LS-SVM模型的校正集与预测集散点图如图7所示。因此,LS-SVM模型对啤酒这3 种质量指标的定量预测效果很好。
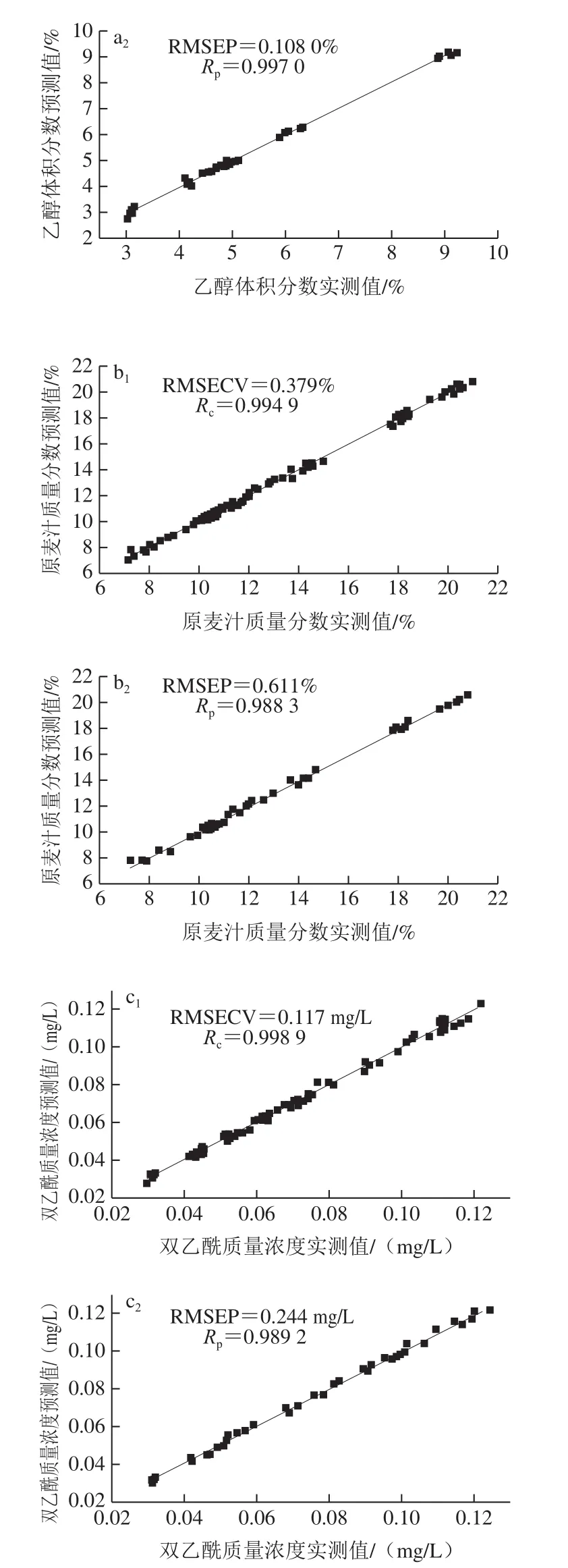
图7 啤酒质量指标的LS-SVM模型Fig.7 Plots of LS-SVM model predicted values against measured values for quality indicators of beer samples in calibration and prediction sets
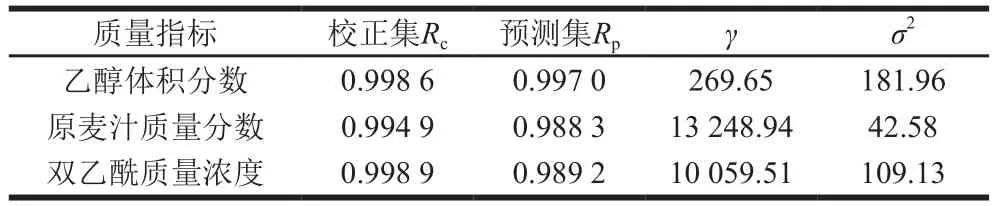
表4 LS-SVM模型对啤酒质量指标的预测结果Table 4 Results of prediction of quality indicators of beer samples by using LS-SVM model
综上所述,PLS、LS-SVM模型都能够对青岛啤酒的3 种质量指标进行定量预测。其中LS-SVM模型比PLS模型预测效果更好。因此,建立的LS-SVM模型为青岛啤酒3 种质量指标的最佳定量预测模型。
3 结 论
测定8 种青岛啤酒的乙醇体积分数、原麦汁质量分数和双乙酰质量浓度,结果表明不同啤酒的3 种质量指标都具有一定差异,其中纯生啤酒的这3 个质量指标均最低,而Strong啤酒均最高。构建的嗅觉可视化传感器阵列结合化学计量学分析结果表明,LDA模型能够较好地区分8 种啤酒;同时,LS-SVM模型对乙醇体积分数、原麦汁质量分数和双乙酰质量浓度都具有良好的定量预测能力。因此,使用嗅觉可视化传感器技术对啤酒品质进行快速、无损检测可行。
