基于随机森林结合地球物理测井资料的煤体结构识别方法及应用
2021-09-13张占松郭建宏秦瑞宝
肖 航, 张占松*, 郭建宏 , 秦瑞宝, 余 杰
(1.长江大学地球物理与石油资源学院,武汉 430100;2.长江大学油气资源与勘探技术教育部重点实验室,武汉 430100; 3.中海油研究总院,北京 100027)
中国煤层气资源丰富,煤层气的勘探开发至关重要[1]。受地质因素影响,煤层在多期构造运动下形成的不同的煤体结构与煤层气产量关系密切[2-3],所以准确识别煤体结构极为重要,直接关系煤层气勘探开发与产能研究。
识别煤体结构最直接的方法是钻井取心进行岩心鉴定,但取心成本较高,同时因其易碎性、机械强度低,在取心过程中煤样结构容易遭到破坏,岩心的完整程度会受到影响[4],所以通过岩心资料直接进行大量煤样的煤体结构判别很难实现。而测井资料具有连续性且成本相对低,测井参数丰富,所以利用测井资料进行煤体结构识别被广泛应用。已有不少学者进行了大量研究,早期研究集中在煤体结构的测井响应特征,依据曲线变化特点制定模板划分煤体结构[5];然后从测井曲线数值出发,依据不同煤体结构的测井值,定量划分煤体结构[6-7],并基于此结合定性特征以提高识别准确度[8];进一步发展到多元回归方法,建立煤体结构评价指标同测井曲线之间的回归方程,从数学角度更加有效的识别煤体结构[9];前人在常规测井方法识别煤体结构的研究上,主要经历定性到定量再到多元回归方法的过程,定性识别主要是从测井响应形态进行大致的区分,定量识别是从测井参数数值出发,找寻各类煤体结构的测井响应数值范围进行区分。相比之下,定性识别反应的测井曲线特征可能在不同地区有一定的适用性,但是不能达到定量识别的准确性;而定量识别虽然有一定的规律,但是不同地区甚至不同井的同类煤体结构在测井数值上存在比较大的差异性,其相对泛化性差,并且不同煤体结构的响应数值很可能存在大量重叠,难以做到精细划分。基于定量识别的多元回归方法,一定程度上可以提高定量识别方法的泛化性,所以目前用常规测井方法识别煤体结构多以多元回归法为主。多元回归法在部分区块取得了一定的成果,但是局限于线性关系,不能满足更加复杂的储层环境和地质因素影响的煤体结构识别;因此更高效、适用性更强的机器学习方法逐渐应用于煤体结构的识别。
由于测井响应受众多因素影响,简单的线性分类不足以实现对煤体结构的准确划分,解决这种非线性的分类问题正是机器学习的优势。前人在机器学习方面的研究主要集中在反向传播(back propagation, BP)神经网络方法及支持向量机法(support vector machine, SVM),早在2011年有学者基于煤体的声波性质建立波速等特征同煤体结构的BP神经网络模型[10],之后则主要通过煤体结构的测井曲线响应特征及机理,依据不同地区实际测井资料,选择不同的测井曲线建立相应的BP神经网络模型[4,11-12],利用机器学习的非线性优势比较准确的识别煤体结构类型,一定程度解决常规测井方法对煤体结构的多解性问题。BP神经网络模型在煤体结构识别方面的确发挥了比较大作用,但是BP神经网络略显复杂,其对目标函数的优化迭代过程很烦琐,而且因数据量少训练到一定程度容易出现过拟合现象,造成假象结果。随后郭建宏等[13]基于SVM结合地球物理测井资料利用两种模式识别煤体结构取得了一定效果,但上述方法对于类别不均衡样本,其应用效果尚未可知。
随机森林(random forest)是一种既简单又高效的机器学习算法,其随机有放回的样本抽取模式保证了对类别不均衡的适用性。不同于神经网络更适合处理大样本数据的特性,随机森林算法既能有效处理大样本数据,也适用于小样本数据。已有学者利用随机森林算法评价了煤层含气量参数[14]。柿庄南区块煤心取样完整率低使得实验资料数量受限,且各类煤体结构数量难以达到均衡,基于此,从测井曲线与煤体结构响应机理出发,选择对煤体结构变化相关的测井曲线作为特征输入,利用随机森林算法建立测井曲线与煤体结构间的分类模型,并用实际测试样本验证其准确性与泛化性。
1 随机森林算法原理
1.1 随机森林原理
随机森林算法是Breiman[15-16]在Bagging算法和集成学习思想的基础上提出的一种组合分类预测算法,bagging为自助抽样集成,此方法将训练集分成k个新训练集,然后在每个新训练集上建模,得到k个互不相关的模型,预测时综合每个模型的结果从而得到最终结果。在分类中即为每个模型对样本进行投票,哪一类得票最多就归于此类;在回归中即为每个模型的预测值取均值。随机森林是一种特殊的bagging,它把决策树作为bagging中的模型,而模型即决策树所需要的训练数据则是通过自助法(bootstrap)完成,即从大小为N的样本集中随机有放回的抽取N次,形成一个和原来样本一样大小的新的训练集,样本集中的每个样本被选中的概率相同(1/N),这样重复k次,能得到k个新的训练集,以此为基础建立k个决策树,进而形成森林。
1.1.1 随机森林形成
单个决策树的建立过程如下。
(1)通过bootstrap法从样本集中选择N个样本形成训练集。
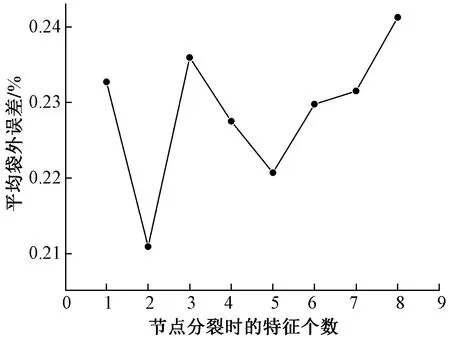
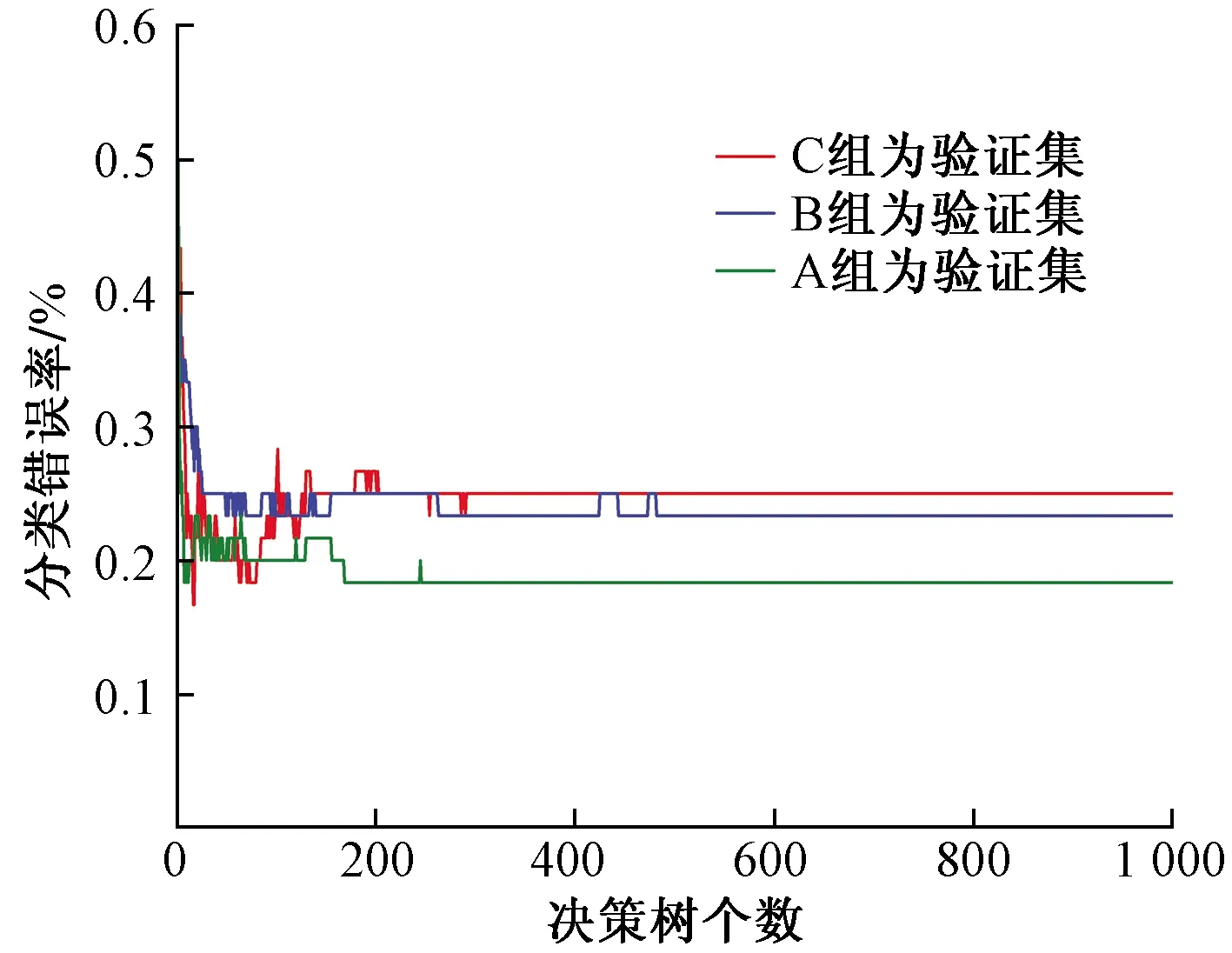
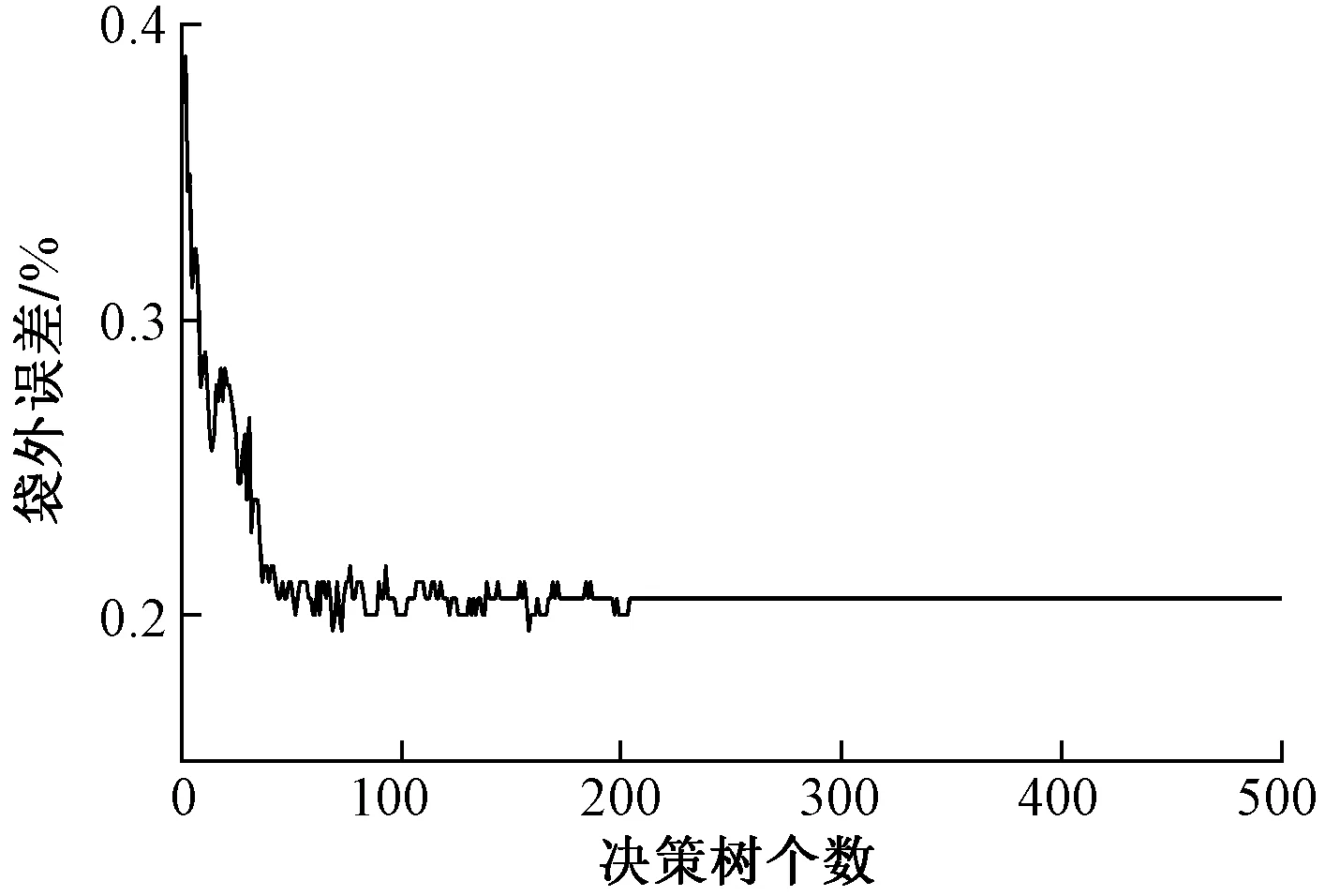
(2)从根节点出发,进行节点分裂,分裂原则为分裂后的两个子节点能尽可能地提升纯度,一般选择基尼系数、信息增益等进行衡量。分裂时选择的特征个数m从训练样本的M个特征中进行随机选择,满足(m (3)每个节点按照步骤(2)进行分裂,直到不能分裂为止,即形成叶子节点。 每个决策树按照以上步骤进行,最终形成森林,最终预测阶段的方法就是bagging的决策模式。随机森林的形成过程实际上对样本及特征都进行了随机取样,避免了单个决策树出现的过拟合现象,并且采用的自助采样方法在面对小样本数据也能发挥算法特性,能够最大化利用数据本身。 1.1.2 随机森林袋外误差 袋外数据是随机森林的重要特点,袋外数据的产生源自算法本身的自助法采样。即形成第k个决策树所需要的训练集时,通过N次随机由放回抽取,每次抽取时任何一个样本没被抽中的概率为(1-1/N),那么任何一个样本没有进入训练集中的概率为(1-1/N)N,当N趋近于无穷大时,有 (1) 可见,大约有36.8%的数据没有参与训练,这些数据就是第k个决策树的袋外数据,即oob样本。在随机森林模型建立时,每个原始样本作为oob样本时的决策数大约为全部决策数的1/3,这些决策树会对样本进行投票得到预测结果,那么分类错误样本占总样本的比率就是袋外误差。袋外误差被证明是无偏估计,结果近似于交叉验证,而且直接在随机森林内部进行,所以随机森林的泛化性评估不需要进行复杂的交叉验证,直接使用袋外误差即可。 随机森林分类算法流程图如图1所示。 图1 随机森林分类算法流程图 经前人对沁水煤田的研究表明,煤岩煤体结构经地质活动改造,随着其破碎程度的增加,可以分为原生结构、碎裂结构、碎粒结构和糜棱结构[17-18]。不同煤体结构的孔隙度和渗透性因其破碎程度有较大差异,物理特性和化学成分发生改变,这些变化与测井曲线响应关系密切。 井径曲线反映煤层井壁直径的大小,煤体破碎程度越大,煤质越疏松,机械强度越低,在钻井过程中更容易出现井壁垮塌,导致扩径[6,8,19]。 自然伽马测井通过测量接收到的自然伽马射线的强度,反映井下放射性元素含量。煤本身的放射性很弱,随着煤体破碎程度的增加,其裂隙系统会更加发育,黏土矿物等杂质会不同程度的在裂隙中进行填充,导致煤层放射性发生改变[8]。另外,灰分含量和自然伽马值呈现明显的正相关性,这是因为灰分在沉积过程中会吸附次生放射性物质,不同煤体结构的灰分含量受构造作用有所不同。 电阻率测井反映地层的导电性能,一般情况下,构造煤的自由基浓度较高,小分子含量也会增加[8],而且更加发育的裂隙会导致水分的增加,因此导电性能增加,电阻率会呈现减小的趋势。但是不同煤阶的煤岩强度有所差异,外力作用下产生的形变不同,其裂缝、孔隙结构不同,电阻率的变化大小也会有所不同[20]。再者,不同地区煤层含水性不同,在弱含水环境下,不同煤体结构的电阻率反响可能非含水性主导,更大程度上由矿物等杂以及煤岩成分所决定。总体来说,不同煤体结构在电阻率上有所差异,不过不同地区的具体变化趋势不能一概而论。 声波时差测井主要测量声波在地层中传播的速度,不同煤体结构孔隙度发生改变,煤中矿物质含量、水分、煤质以及煤阶的不同都会影响声波在其中的传播速度[7,19,21]。 补偿中子测井主要反映地层的含氢指数,煤层在构造作用下,渗透率、孔隙度发生改变,不同煤体结构的含水率不同,其氢元素含量也会产生改变[7,21]。 密度测井主要反映地层密度变化,煤层破碎程度的不同导致其孔裂隙发生改变,不同煤体结构中的矿物等杂志填充程度以及含水率不同,密度测井值会产生差异[4,7,19,21]。 针对本区块实际测井资料,首先进行数据预处理,包括高灰及不符合测试规定样和夹矸影响的清洗、测井曲线标准化、扩径影响敏感曲线一定程度校正,进而进行煤体结构同测井曲线的相关性分析,具体情况如图2所示,由各测井曲线交会图可见,随煤体结构破碎程度的增加,自然伽马(GR)有增大的趋势,补偿中子(CNL)有减小的趋势,深双侧向电阻率(RD)和浅双测向电阻率(RS)呈现减小的趋势,且趋势相对较明显,但是都存在大量数值重叠,二维交会图效果很差;声波时差(AC)的变化趋势不明显,除去小部分补偿密度(DEN)较高的原生和碎裂结构,整体还是呈现增加趋势,不过重叠依然很多;井径X与井径Y变化趋势不明显,重叠较多,部分原生和碎裂结构煤的双井径出现一些较高值,这是由于该区块钻井时井壁加固技术相对不成熟,且三类煤体结构对应的镜质组含量接近,这也与该地区煤为软煤的地质特点相符,因而使得该区块三类结构煤对应的扩径变化为非线性。综上,仅从线性角度来看,测井曲线很难实现对本区块煤体结构的有效划分,测井曲线与各类煤体结构上的响应存在复杂的非线性关系,线性方法无法挖掘背后的响应关系,所以本区块更适合使用机器学习方法识别煤体结构,考虑到本区块三类煤体结构数量不均衡且样本量不大,BP神经网络方法并不适用,故选择随机森林算法进行建模。由于自然电位与煤体结构没有明显关系机理,前人在机器学习的输入特征选择上也没有予以考虑,故本次实验选择与煤体结构相关的8条测井曲线,即井径X(CALX)、井径Y(CALY)、GR、RD、RS、DEN、AC、CNL建立煤体结构与测井曲线之间的随机森林分类模型。 图2 不同煤体结构测井曲线交会图 建立随机森林分类模型之前,需要确定两个超参数:决策树个数以及节点分裂时选取的特征个数,在MATLAB中,分类模型的特征个数m默认为{sqrt[max(M,2)]},M为样本的特征总数。特征个数的选取决定随机森林不同决策树之间的关联性,关联性越大越不利于发挥随机森林算法的优势;决策树的个数直接影响模型的好坏,决策树个数太少会导致模型泛化误差无法收敛,影响模型精度;决策树个数过多直接影响模型的训练速度,对精度没有提升且效率降低。所以为了建立可靠的分类模型,需要选择合适的特征个数和较优的决策树个数。 将本研究区块209个煤体结构样本分成训练样本和测试样本,其中训练样本为180个,测试样本为29个,测试样本不参与模型建立的任何过程,仅用于模型评估。为确定节点分裂时的特征个数,用随机森林算法对训练样本进行建模,通过尝试选择不同的特征个数值,进行平均袋外误差的计算,具体结果如图3所示。可见,节点分裂的特征个数为2时,误差最小,本模型中的特征个数选择为2。 图3 特征个数与其平均袋外误差的关系 节点分裂时的特征个数确定后,再确定决策树的个数,将采用交叉验证的方式优选决策树个数。交叉验证(cross validation)是机器学习中评估模型性能的有效手段,有简单交叉验证、K折交叉验证(K-CV)和留一法交叉验证。其中,K-CV交叉验证是比较常用的交叉验证方法,能有效评估模型的泛化性,其基本思路为:将原始训练集分成k组,每组子集分别作为一次验证集,其余k-1组子集作为训练集,能得到k个模型,然后用k个模型分别对相应的验证集进行测试得到结果,k个误差和平均即为k折交叉验证误差[22]。在分类问题上,误差用分类错误率表征,本文在优选决策树个数时,选择三折交叉验证。 研究区块主要包含三类煤体结构:原生结构、碎裂结构和碎粒结构,鉴于煤体结构样本量不大,如果直接使用袋外数据作为验证集,训练数据量和验证数据量都会减少,直接影响验证结果,不利于决策树个数的优选,因此选用交叉验证方法。将180个训练样本分成A、B、C共3组,每组60个样本,每组都涵盖三类煤体结构且依比例均匀分布,进行三折交叉验证,验证标准为分类错误率,达到交叉验证的有效性。这样,最终会得到3个最优决策树个数,然后求其均值确定随机森林模型的决策树个数。具体实现时通过MATLAB软件运行完成,交叉验证结果如图4所示。 图4 随机森林决策树个数和交叉验证误差的关系 图4为3组数据分别作为验证集时的型对其预测的错误率,从交叉验证的结果来看,A组和C组在决策树个数在400以上就非常稳定;B组在300个树以后大致稳定,在400~500颗数阶段有一小部分有所波动,大体保持稳定,不过500颗树以后也达到稳定。综上分析,随机森林算法在决策树合理的情况下是一种非常稳定的算法,决策树个数太少会严重影响预测结果,波动较大,这也和随机森林原理对应。分析结果认为,决策树个数为500较为合适。 确定决策树个数后,开始建立测井曲线与煤体结构的随机森林模型。将180个样本全部作为训练样本建立模型,500棵树时随机森林分类模型的袋外误差如图5所示,随着决策树个数的增加,袋外误差不断下降最终稳定,其实本质上来说树的个数增加,参与训练的样本更多,数据利用率越高,模型会更加可靠。最终袋外误差稳定在0.2,证明此模型泛化性较好,预测可靠。用训练好的随机森林模型对测试样本进行预测,具体结果如图6所示。 图5 随机森林决策树个数与袋外误差的关系 研究区块三类煤体结构在MATLAB软件中表征方式为:1表示原生结构、2表示碎裂结构、3表示碎粒结构。图6为随机森林分类模型对测试集预测结果同实际煤体结构的对比,测试样本为29个,且三类煤体结构分布不均,主要以碎裂结构为主;预测正确的样本数为27个,总体正确率为93.1%。各类结构的具体预测情况如表1所示,碎裂结构和碎粒结构正确率为100%,原生结构正确率为60%,有两个原生结构被错误预测为碎裂结构,可能是由于本区块碎裂结构的煤体破碎程度变化幅度较大,有的碎裂结构受外力作用小,形变相对于原生结构不明显导致其测井响应同原生结构的测井响应相差不大;而有的碎裂结构破碎程度就相对明显,孔裂隙结构相对于原生结构明显发育,所以会出现原生和碎裂之间的误判。不过碎粒结构煤体相对于原生和碎裂结构煤体,构造作用明显更强,能从煤样取心图片看出差距,所以其测井响应特征相较于原生、碎裂结构煤体有较大区别,能正确进行识别。其次,针对研究区块三类煤体结构分布不均衡问题,随机森林算法能够较为准确的进行煤体结构的识别。 图6 实际煤体结构与预测煤体结构的对比 表1 测试集混淆矩阵 (1)通过分析本区块煤样特点及具体测井数据,认为常规测井方法以及BP神经网络方法识别煤体结构在本区块不适用。随机森林算法更适合本区块,井径曲线(井径X和井径Y)、自然伽马曲线、电阻率曲线(深侧向和浅侧向)、补偿中子曲线、声波时差曲线和补偿密度曲线与煤体结构关系密切,选择此8条测井曲线作为特征曲线参与随机森林分类模型的建立。 (2)通过计算不同特征个数的袋外误差确定节点分裂的最优特征个数为2;通过三折交叉验证确定决策树个数为500较为合适,并以测井曲线为输入、煤体结构类别为输出建立随机森林分类模型。袋外误差稳定在0.2,证明模型可靠且具有良好的泛化性。 (3)通过对实际测试样本分析,认为随机森林算法适用于类别不均衡且样本量不大的数据,并且预测精度较高。随机森林算法在煤体结构分类问题上表现良好,为煤体结构识别方法的发展提供思路,为煤层气开发提供帮助。1.2 随机森林分类算法流程图

2 煤体结构随机森林分类方法
2.1 煤体结构测井曲线相关性分析

2.2 随机森林分类模型


3 结论
