基于Java 的SEED 文件解析
2021-09-10刘静闻卢燕红蔡宏雷
张 帆,刘静闻,付 琦,卢燕红,蔡宏雷
(1. 吉林省地震局,吉林 长春 130117;2. 辽宁省地震局,辽宁 沈阳 110034)
0 引言
自1985 年以来,国际地震学和地球内部物理学协会(IASPEI) 制定了国际数字地震数据交换标准SEED 文件格式,SEED 格式已经成为地震行业最具权威性的国际通用标准。为了规范我国地震台网波形数据管理,2017 年中国地震局发布了中华人民共和国地震行业标准中的《地震波形数据格式交换》白皮书,结合我国现状,对《国际地震数据交换标准》进行解读。在地震行业中,SEED 格式文件分为现场台站卷、台站台网卷和事件台网卷三种[1]。本文从实际应用出发,介绍最常用的事件台网卷SEED文件的解析和使用。解析此类SEED 文件,需要了解SEED 格式文件的存储结构和规范,针对这些问题,本研究利用Java 语言的跨平台性[2],与大数据技术无缝整合的特点研发一套能提供快速稳定准确的SEED 格式地震波形数据解析软件,支持WINDOWS、LINUX 等操作系统,并作为基础软件包应用于东北地震与火山大数据平台业务中。
1 SEED 结构
通过“九五”和“十五”项目建设,JOPENS系统在地震行业推广使用,解决测震多数据源的难题,提供统一准确高效的测震实时流平台[3],以 SEED 或者 MINSEED 文件格式[4]对测震实时流数据进行数字化存储,如:连续波形数据、事件波形数据等。MINSEED 可以理解为SEED 格式的简化版,和SEED 格式的主要区别是不包含头文件信息,主要存放数据体内容。因此,本软件以SEED 文件为研究对象,并兼容MINSEED 格式的解析。
SEED 文件属于科学类特有的国际通用型数据文件,不单单应用于地震领域,还在重力、卫星、气象等领域广泛应用。为了满足这些条件,SEED 文件每部分的存储方式都不同,但是都遵循计算机国际统一的多种编码规范来达到通用性的效果。想要解析并读取SEED 格式文件,不仅要了解SEED 文件底层内部结构,还要了解SEED 格式文件在地震行业的应用结构。
1.1 SEED 文件底层结构
SEED 格式文件底层结构如表1 所示。

表1 SEED 格式文件结构说明
表1 是SEED 文件的整体结构,包含序号、控制头段类型码和延续码,也就是通常所说的头文件。类型A 代表字母数字字段,是固定长度的ASCII 码串;D 代表十进制整数。V-可变长度的ASCII 码串,用“~”表示结束。
SEED 除了V、A、S、T 控制头段逻辑记录外(每个卷都是4096 字节),数据记录的卷(4096 字节) 包含了 8 个 MSEED 数据结构体。MSEED 结构体存储的内容就是带时间片的数据,与头文件的S 和T 对应匹配。
SEED 文件格式含控制头端(ASCII) 和时间序列(二进制) 两种格式体,如图1-2 所示。
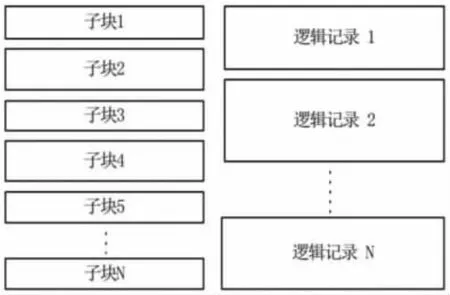
图1 控制头段格式体Fig.1 SEED header format
从图1 可以看到,每个控制头段由多个子块组成,每个子块包含子块标识符、长度、若干个数据字段。
从图2 可以看到,数据体由多个记录文件组成,每个文件记录包含多个逻辑区域。每个逻辑区域包含多个数据记录,每个数据记录由标识块、一个固定头段、一个可变头段和数据区组成。每个数据记录都有一个数据记录标识块与控制头相对应。文件的整体结构是以一种可扩展的链式方式进行数据的存储。
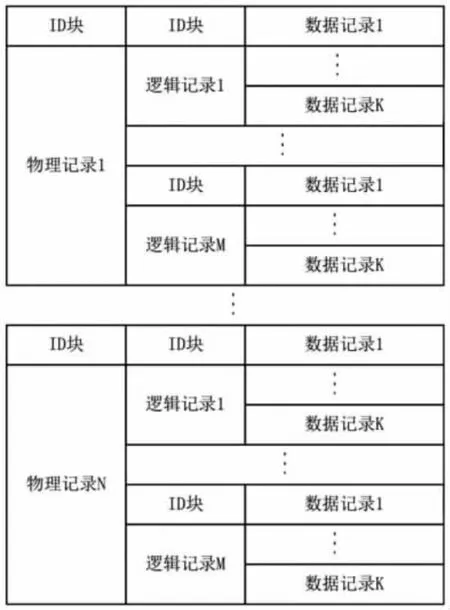
图2 时间序列格式体Fig.2 Time series format
1.2 SEED 文件应用结构
SEED 文件地震应用结构图:
从图3 可以看出,SEED 格式文件分为头文件和数据体文件两大部分[1],其中头文件采用ASCII 编码方式对台网编码、台站标识码、位置标识、通道标识码、采样率、灵敏度、正则化因子、零极点、零极点单位、时间序列等重要信息。其中,时间序列拆分为N 组,每一组称为时间切片。数据体部分采用计算机十进制编码方式,分成八个数据块存储数据记录,每一个数据块为4096 个字节,也可以理解为常用的MINSEED 格式文件。

图3 SEED 地震格式体Fig.3 SEED seismic format volume
头文件与数据体文件通过时间序列进行匹配,才能将记录的数据与对应台站关联起来,时间序列中每一个时间切片会形成唯一的索引值,这个索引值是与数据体中数据块的索引值相对应还原出完整的地震事件信息。一个完整SEED 文件包含的主要元素有台网编码、台站标识码、位置标识、通道标识码、数据头段/数据质量标识、记录开始和结束时间、偏移量等。其中,采样率表示仪器1 秒钟采集数据的个数,通道标识码表示地震仪的三分项 (东西、南北、垂直),零极点是地震仪线性动态系统传递函数的参数,分子项是零点,分母项是极点,与正则化因子功能一样,主要用于去仪器响应及波形仿真。
2 解析流程
利用Java 的I/O 流技术[5]读取SEED 台网事件卷,解析头文件和数据体文件。头文件参数涉及到数据仿真和量纲转化重要信息。数据体记录的数据体量大小是由采样率的大小决定,模拟短周期DD-1 一般采样率为100Hz,所以数据体量庞大,需要利用缓存技术进行存储。利用地震学研究联合会(Incorporated Research Institutions for Seismology) 发布的 SEED 软件包进行SEED 文件的读取和解析处理。解析SEED 文件分为头信息和数据体两部分。
2.1 头文件解析
头信息解析流程如下:
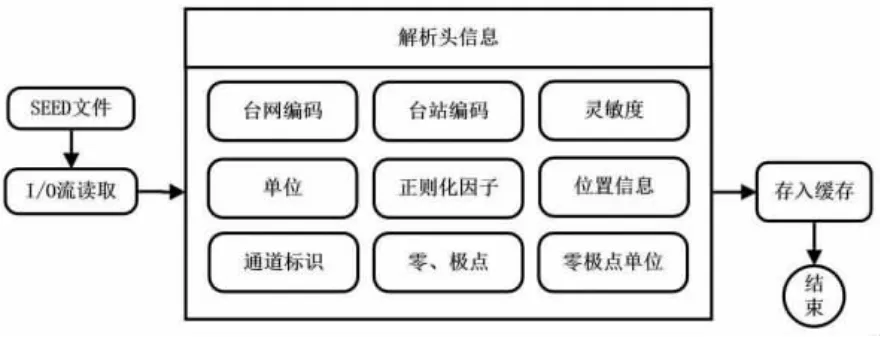
图4 解析读取SEED 头信息流程Fig.4 Analysis of SEED header information process
根据《地震波形数据格式交换》白皮书读取SEED 头信息,台站编码的卷索引标识为“011”,通过索引标识可以提取出台站编码。通过卷索引标识“052”来获取通道信息(Z、N、W 三分项)、采样率、位置(台站经度和纬度)、灵敏度、T-时间片控制字段等信息。这些信息与数据体相匹配,得到台站完整的波形数据。


此流程只是将数据体进行分类处理,要想得到按照时间排序的正确的数据格式,还需要数据体解析流程。
2.2 数据体解析
读取SEED 数据体过程中,由于数据体分块存储,还需要根据时间序列(即:T-时间片控制字段) 来判断数据块的连续性和时序性,解析流程图如图5 所示。
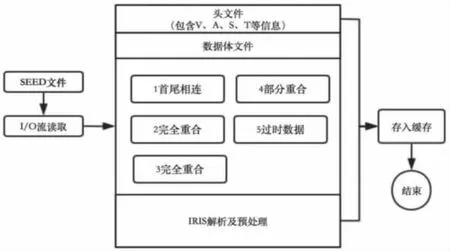
图5 解析读取SEED 数据体流程Fig.5 Analysis of SEED data process
利用Java 的I/O 流技术将SEED 格式文件转换成byte [] 数组结构,将SEED 头文件解析存储以后,根据解析出的头信息再去与数据体索引的时间片控制字段相匹配,对SEED 数据体内容进行分块读取和解析,这样就能将一个地震事件的数据全部匹配解析出来。在采样率一致的前提下,判断SEED 数据块在程序中是否进行拼接解析处理,大致有5 种情况:
(1)源数据块和新数据块时间连续刚好可以拼接,即:首尾相连。程序根据时间进行排序,直接将数据块进行合并。
(2)源数据块和新数据块时间完全重合或者新数据在源数据时间段内,即:完全重合。程序从连续率、完整性、稳定率三方面选取数据质量较好的记录纳入处理流程。
(3)源数据和新数据中存在漏包,即:不连续。程序会自动根据时间序列对漏包的部分进行补零填充处理。如果漏包严重,程序不会将记录纳入处理流程。
(4)源数据和新数据存在部分重合,即:部分重合。程序从连续率、完整性、稳定率三方面选取重合部分数据质量较好的记录纳入处理流程。
(5)源数据块比新数据块时间还大,这时新数据为过时包,不进行拼接操作。即:过时数据。
程序对以上5 种情况处理以后,才保存到缓存中。
虽然上述情况不是很多,经过初步分析,主要是因为网络延时、地震仪故障或老化等客观因素。为了能准确顺利的读取SEED 信息,程序对上述情况做了相应预处理。
3 大数据结合应用
吉林省大数据应用采用的是基于Java 语言的Hadoop 技术[6],此项技术是针对海量存储及计算问题的最佳解决方案,Hadoop 的框架最核心的设计就是:HDFS 和MapReduce。HDFS 为海量的数据提供了存储,而MapReduce 则为海量的数据提供了计算,是大数据时代最重要的技术。大数据平台解决了传统存储的弊端,实现数据实时安全存储、处理、解析、共享、运算、公共服务等问题。
基于Java 的I/O 流技术SEED 格式文件解析程序是波形仿真、P 波拾取、定位、震级计算等一系列自动处理环节中最基础的部分,此程序直接影响自动处理过程中的准确性和时效性。与大数据技术一脉相承,大大地提高了系统的稳定性。已经应用于东北地震与火山大数据平台业务中,为地震分析预报和应急提供重要的参考依据。
4 应用效果
SEED 格式文件解析在大数据平台中的应用效果,通过Echart 画图工具即可在浏览器中显示完整的事件波形,如图6 所示。

图6 解析SEED 文件效果图Fig.6 Analysis of read SEED file rendering
以 2018 年 5 月 18 日凌晨 1:50 分,松原5.7 级地震为例,SEED 解析在大数据平台自动定位应用中的效果,如图7 所示。
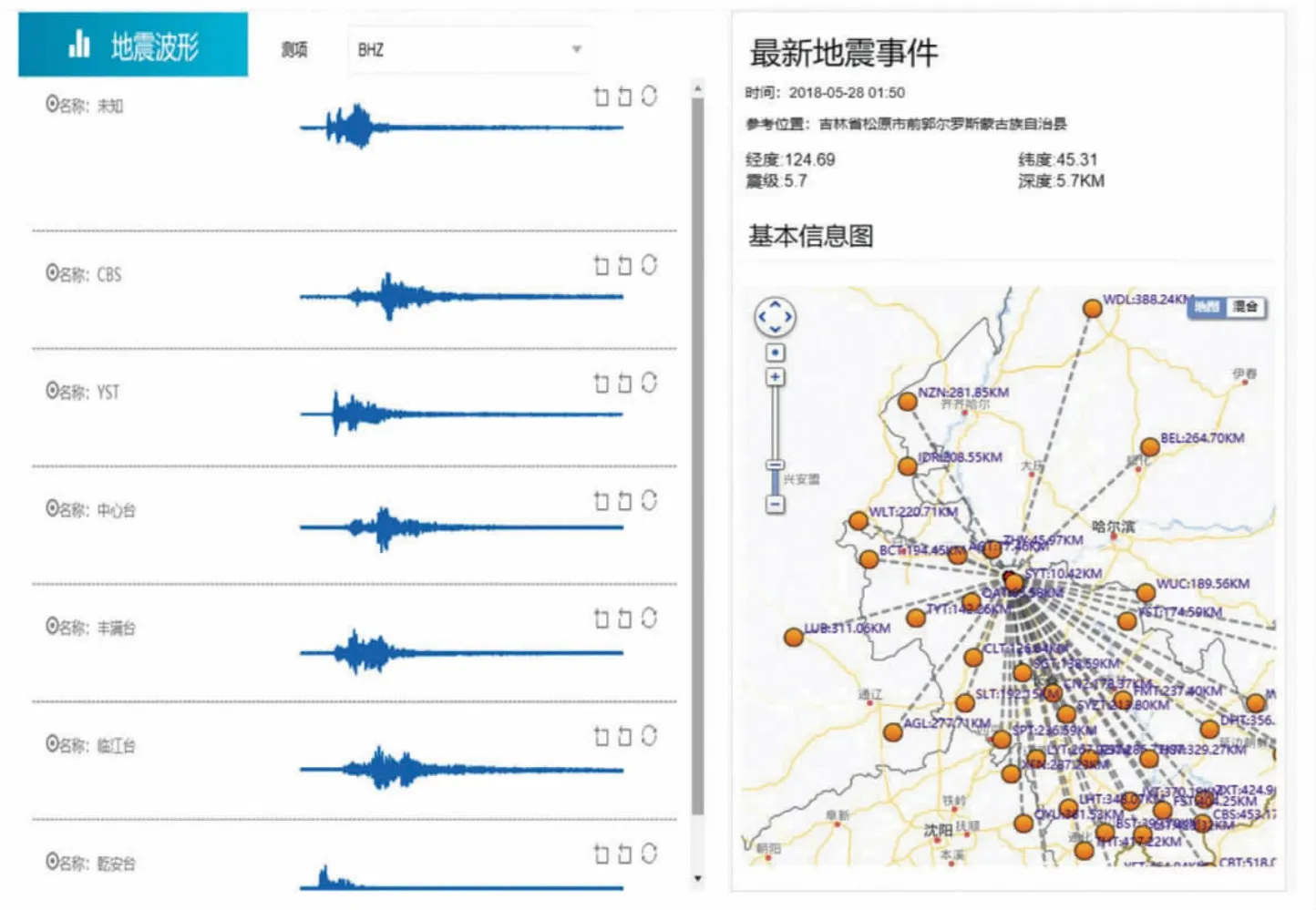
图7 震例效果图Fig.7 Earthquake case
图7 中,左侧为此次地震事件自动拾取的波形记录,右侧为记录台站到地震的距离。该软件通过基于Java 技术解析SEED 文件的处理方法和流程,以及对数据体部分特殊情况的预处理方法,对SEED 文件读取达到准确、快速、稳定的要求,与Hadoop 技术[5]实现无缝集成,已经应用于大数据平台实际业务中,并通过多次实际震例检验。为大数据平台后续业务:波形的实时解析、存储、地震自动处理流程(地震自动定位、震级自动计算)、烈度图的快速自动产出等功能,提供底层支撑。
5 结论
SEED 文件的读取和解析程序是实现地震自动处理环节中最基础的部分,也决定了自动定位和震级计算的准确性,通过波形展示和多个真实震例(M2.0 以上) 的计算验证,定位误差10 公里以内,震级误差0.1~0.3 之间,震级越大,参与的台站越多,误差率越小,与人工审核后的地震信息越接近吻合,完全可以应用在实际业务中,为地震速报及震后快速产出烈度图提供重要的参考依据。程序具有良好的跨平台性和移植性,也可以作为独立的子程序,为其他应用提供基础服务,也可以作为服务提供给其他程序使用。
