基于候选框多步迭代优化的多阶段目标检测模型
2021-09-08赵钊龚霁程
赵钊 龚霁程


【摘要】 在解决目标检测任务的模型中,基于多阶段检测框架的模型相对单阶段和两阶段检测框架的模型具有明显的精度优势。该研究的主要目的是通过使用基于长短时记忆网络(Long Short Term Memory,LSTM)的多次迭代回歸模块来改进广泛使用的两阶段回归框架。在该研究中,基于LSTM的候选框迭代优化模块被设计用来不断优化候选框生成网络(Region Proposal Network,RPN)所提出的候选框。该模块不仅能够灵活的与各种框架进行集成,同时还可以根据训练和测试阶段对检测速度需求的不同而任意的配置迭代次数。为了验证该方法的有效性,该研究采用基于ResNet-50和ResNet-101为主干网络的多个检测框架,并在两个公开数据集上进行了大量实验。结果表明,该方法得到的所有类平均精度(mean Average Procession,mAP)明显高于基准模型R-FCN和FPN。同时,其效果优于目前最先进的级联(Cascade)R-CNN算法。
【关键词】 目标检测 长短时记忆网络 迭代回归 多阶段检测 候选框网络
引言:
随着深度神经网络的发展[1, 2],目标检测的性能[3, 4]有了显著提高。通常,目标检测模型将任务分解为目标定位与目标分类两个子任务。定位模块首先需要通过向给定图像分配和回归相应的边框来框选图像中的所有目标。然后,分类模块对每个边框中的目标类别进行分类预测。在目前主流的多阶段检测模型中,这两个模块通常作为两个子模块整合在主干网络上同时进行训练优化。因此,这两个子模块存在一定的相关性,同时也对检测模型的整体性能起着至关重要的作用。
学界常见的目标检测方法可以分为:(1)两阶段框架[5-12];(2)单阶段框架[13-17]。两阶段方法遵循由文献[13]提出的Faster-RCNN框架。此方法在第一阶段中生成了一组候选框,同时为每个框的内容给出了前景目标的置信度。然后,在第二阶段中对第一阶段筛选过后的候选框执行进一步的位置回归和类别细分类。相比之下,单阶段方法,例如YOLO[16, 18]或SSD[15],通过对多尺度特征图进行密集采样,直接进行锚定框的回归和分类。
一般而言,单阶段检测模型在速度上优于两阶段模型,但在检测精度上却不如后者[16]。该研究认为,两阶段模型能够产生更准确结果的原因主要在于(1)在第一阶段,候选框生成模块提供了正负样本均衡的候选框集。这有利于后续二阶段回归和分类模块的训练。(2)每个输出框对应的原始锚定框都经过了两阶段回归和分类,这进一步优化了输出包围框的精度。
除了单阶段和两阶段框架外,许多文献还提出了多阶段方法[5, 19, 20],这些方法通常比大多数两阶段方法进行更多的边框回归和分类,并且获得了更好的效果。因此,该研究提出了一种新的多阶段边框回归模块,该模块可灵活地执行回归操作。该研究的主要贡献可以概括为以下几点:
1.通过使用基于循环神经网络[21]的多步迭代模块对候选进行不断的细化回归,该研究中使用的是LSTM。
2. 迭代步数可以作为超参数进行任意设置,并且在训练和测试时可以有所不同。回归步骤越多,检测精度越高;反之,更高的检测速度可以通过设置更少的迭代步数来实现。
3. 该研究提出的模块可以自然的地扩展应用于各种两阶段检测框架中,通常只需替换其原始的检测回归模块即可。
基于R-FCN[6]和FPN[22]两大框架,该研究使用基于ResNet-50和ResNet-101的主干网络在PASCAL VOC[23]和MS COCO[24]数据集上进行了详细的实验评估。实验结果表明,该研究的模型大大优于原始的R-FCN和FPN,同时也优于现有的最先进的Cascade R-CNN方法。
一、相关文献
1.1 单阶段和两阶段目标检测模型
Faster-RCNN[12]在提高目标检测的速度和精度方面都取得了长足进步。该模型创新的提出了一个完整的可进行端到端学习的目标检测框架。该框架将候选框生成网络(RPN)和候选框分类模块整合到整个网络模型中。受Faster-RCNN的启发,学者们提出了许多其他方法来提高检测精度或计算速度,其中包括R-FCN[6]和FPN[22]。前者提出使用位置敏感型的卷积层代替全连接层来提高检测效率;后者将多尺度特征图层的检测结果进行串联,从而进一步提高精度。另一方面,SSD[15]等单阶段方法可以看作是一个独立的候选框生成网络,并利用相同的特征直接进行分类预测,并在不同的特征图层次上进行边框回归。RetinaNet[25]利用Focal Loss来平衡前景和背景类比例,取得了较好的效果。
1.2 多阶段目标检测模型
通常,由于两阶段框架比单阶段框架具有更高的检测精度,因此许多文献提出采用多阶段目标检测框架以达到更高的检测精度。在文献[26]中,作者将上一步的输出作为输入又迭代输入给回归模块,取得了较好的mAP。文献[17]在原有的SSD框架中增加了一个锚点优化模块,该方法比普通的单阶段法多出了一个边框细化步骤。AttractionNet[19]提出了一个目标位置细化模块,该模块可迭代地优化候选框的位置。Cascade R-CNN[5]对一些两阶段检测框架的回归模块进行多次级联,并获得了最优的结果。在文献[27]中提出了一种迭代细化方法,该方法首先通过合并重叠区域来确定搜索区域,然后在搜索区域内采用分治搜索。此外,为了细化多级边框检测过程,R-FCN-3000[20]提出了一种解耦的多阶段检测与分类框架。该方法对每个目标进行两步分类(超类分类和子类分类),结果表明检测精度也得到了提高。
1.3 基于RNN的目标检测模型
卷积神经网络已经被广泛应用于大多数目标检测框架中。基于卷积层构建的网络既可以用于特征提取[1],也可以用于回归和分类[6, 28]。另一方面,递归神经网络在自然语言处理领域[29, 30]取得了巨大的成功。并且,許多研究表明,RNN也适用于目标检测任务。例如,CTPN[31]使用LSTM[32]对连续的上下文信息进行编码,表明它可以减少错误检测并恢复丢失的文本。文献[33]的作者提出了一种高效的视频目标检测框架,该框架将ConvLSTM与SSD框架整合在一起。然后,LSTM模块可以在每次迭代对时空上下文进行编码,从而细化输入。文献[34]使用对应图像裁剪的特征表示作为输入,然后够通过ConvLSTM层预测目标形状。
二、基于LSTM的候选框优化网络
在本节中,该研究将介绍基于LSTM的候选框优化网络模块的结构。图1显示了整个网络的主要结构,实线框表示根据候选框生成网络(RPN)计算得出的初始候选框。根据候选框对应的空间位置,从CNN特征图中裁剪对应的3D特征向量。兴趣区域(Region of Interest RoI)池化层将每个向量调整为相同的形状。随后,该方法将3D特征展开为1D特征,并将其作为LSTM层的输入。解码后,模型输出对应图中虚线框的细化候选框。在下一次迭代中,虚线框将被作为下一步迭代的输入候选框,进行进一步的细化回归。这样的过程将重复t次,直到t满足预定义的迭代次数。
2.1 候选框选择
多次对候选框进行优化和迭代的计算量是比较大的。因此,该方法选择只细化具有较高的前景物体置信度的边框,以加快迭代过程。同时,该研究保留图像中所有不同目标的候选框,以保证位置的均匀分布。
该研究没有像文献[19]那样手动设定锚定候选框,而是使用候选框生成网络(RPN)[12]来选择候选框以进行进一步的细化。RPN为每个候选框提供前景置信度和四个坐标{x1,y1,x2,y2}。同时,该研究使用非极大值抑制(Non Maximum Suppression,NMS)以剔除高度重叠的边框。之后,该方法选择最高置信度最高的K个候选框作为下一步的输入,以进行进一步的优化迭代。
2.2 迭代边框回归
迭代回归任务可以看作是一个重复的重新采样过程,其目的是寻找最佳的假设分布。Cascade R-CNN模型[5]将两个检测模块与基础检测框架进行级联。此外,它在训练过程中提高了每个回归步骤的IoU阈值,使候选框的质量可以在每个阶段迭代步骤中改进。但是,此方法在训练和测试时都需要遵循固定的回归步骤,而这可能会导致模型的过度拟合。不仅如此,该模型也无法以端到端的方式反向传播整个候选框的损失函数值。因此,其候选框生成是通过多个单独的检测模块而不是单个模块来进行的。AttractionNet[19]使用单个CNN回归模块在所有训练步骤中以相同的IoU阈值迭代地优化候选框。但是,由于边框分布在每个回归步骤[5]上都发生了显着变化。因此,当使用固定的IoU阈值对其进行训练时,此单个回归模块可能会产生次优结果。
与以上方法不同的是,该研究将整个候选框迭代优化看作是一个连续的过程。在这个过程中,前一步迭代的结果会影响下一步迭代的优化。此外,候选框优化器需要适应每次迭代,并且能够通过这个序列化的过程反向传播损失函数值以进行整体模型的优化。因此,该研究使用递归神经网络,更具体地说是使用LSTM作为迭代优化模块的主要构建组件。
对于给定的边框B,该研究使用RoI池化层从给定的特征图中裁剪出固定形状的3D特征。经过池化的每个图像具有高度(H)×宽度(W)×通道(C)的形状特征。然后,该方法将三维特征展开成一维向量,再输入至LSTM层。LSTM层包含M(= 128)个隐藏单元,以及一个全连接的层。LSTM的关键模块如公式1所示。其中,xt表示裁剪的特征向量,而ht表示隐藏状态。U代表输入状态参数,W代表隐藏状态参数,i,f,o和Ct分别代表输入门、遗忘门、输出门和单元状态。⊙表示逐元素相乘。然后,两个全连接层将前面LSTM层的输出与两个预测模块连接起来,其中一个用于预测边框偏移量? = { δ x ,δ y ,δ w ,δ h },另一个用于预测前景目标置信度。
在每次迭代过程中,LSTM隐藏状态和候选框都会被更新。每个细化的候选框都将用于裁剪新的特征图,以便在下一次迭代中优化。整个过程一直持续到迭代次数达到预定阈值T。同时,边框偏移量和前景置信度等中间结果被保存起来,以便后续的损失函数计算。另外,在将细化的边框输入到分类器之前,该方法使用非极大值抑制来剔除高度重叠的候选框。
整体细化过程如算法1所示,其中F表示特征图,B0 表示RPN中的候选框。该研究从零状态初始化LSTM隐藏状态,并在每次迭代时对其进行更新。符号表示LSTM层
2.3 分类
除了检测模块,还需要应用分类模块来完成整个目标检测。该研究以R-FCN为框架,通过位置敏感的得分图与位置敏感RoI池化进行分类;此外,该研究同样参考FPN的设计方式,使用多尺度的特征图进行后续分类。同时,该方法选用全连接层作为最终分类器。为了获得更好的分类结果,并与原始的 R-FCN和FPN结果进行公平的比较,该研究在训练分类模块时使用了在线困难样本挖掘算法(Online Hard Example Mining OHEM)[35]。在超参数配置上,模型选择前K个分类损失函数值最大的候选框进行损失函数的反向传播。
2.4 损失函数
多步迭代的边框位置回归和目标分类的整体损失函数定义如公式2描述。其中,T表示总迭代次数,而t表示第t次迭代。x表示特征向量的集合,表示第t次迭代中的第i个候选框,而表示在第t次迭代中对应的候选框的特征向量。g表示真值框的集合,表示候选框数量,h表示分类器,f表示回归器。除了训练迭代候选边框的损失,该研究还联合训练了作为RPN的锚定框位置的回归和前景背景分类的损失,以及位置敏感分类器[6]的损失。
三、实验设计
3.1 数据集
该研究在Pascal VOC和MS-COCO 2017数据集上进行实验。对于Pascal VOC,该研究在一个由VOC2007和VOC2012的训练和交叉验证组合数据集上训练模型,该组合集包含约16K张的图片。训练好的模型在VOC2007测试集上进行评估,该测试集包含约5k张图像。类似地,该研究使用MS-COCO 的2017?118K训练集来训练模型,并在5k张测试集上评估模型。该研究使用与文献[21]相同的评估标准,类平均精度(mAP),来评估在不同的IoU下模型在两个数据集上的性能。IoU的取值范围为[0.5,0.95] ,间隔步长为0.05。
3.2 实现细节
该研究使用ResNet-50和ResNet-101作为模型的主干网络。对于图片数据的预处理,在PascalVOC数据集上,图片尺寸被调整为较短边具有600个像素;在COCO数据集上,图片尺寸被调整为较短边具有800个像素。在训练中,唯一使用的数据增广技术是左右翻转,没有任何其他的方法被调用。该研究使用5个尺度 以及3个宽高比{1:2, 1:1, 2:1}的预设锚定框尺寸。超出图像大小的锚点将被剪切。
RPN后的非极大值抑制的IoU阈值设置为0.7。同时,该研究选择置信度最高的前800个候选框进行进一步细化。在一些极端情况下,在非极大值抑制后候选框的数量可能少于 800个。此时,该方法会用零进行填充补位,以满足批处理时固定大小的要求。为了剔除高度重叠的边框,从而保证模型的有效训练,基于LSTM的迭代优化模块输出后的非极大值抑制的IoU阈值设置为0.8。
图2显示,预测框的平均IoU在每次迭代时都会增加。因此,在每步迭代后,该算法都会提高前景候选框筛选阈值u。如果预测框与真值框的IoU大于或等于u,则预测框为正样本。在实验中,训练时最大迭代次数T被设置为3,因此该方法设定u ={ 0.5,0.6,0.7}。图2显示IoU分布随着迭代逐渐趋近于0.9,这意味着较高的边框回归质量。
该研究使用动量值为0.9的动量离散梯度下降法(Momentum-Stochastic Gradient Descent-SGD)优化器。初始学习率设置为0.001,在VOC和COCO上分别进行了120K和530K次轮训练迭代后切换到0.0001。该研究选取置信度最高的前800个候选框进行迭代细化,并以1:1的正负采样比进行候选框采样和训练。
该研究的算法通过TensorFlow[36, 37]实现。该研究未能找到一个与R-FCN论文[6]的性能匹配的TensorFlow版本實现的R-FCN。因此,该研究从精度较低的R-FCN基线开始。但是,通过整合该研究提出的模块,最终的方法达到了与其他方法相当或更好的性能,这进一步证明了该研究提出的模型的有效性。
四、 实验
4.1 多阶段迭代次数的评估
如图2所示,该研究根据实验结果绘制了不同迭代阶段的预测框与真值框之间的IoU直方图。实验中的模型架构为整合了该方法提出的多步迭代回归模块的FPN框架,主干网络使用了ResNet-50。该模型在VOC2007+2012训练集上进行训练,并在VOC2007测试集上进行测试。在进行非极大值抑制之前,所有的候选框均用于计算IoU。从这些图中,可以看到候选框在每个阶段都朝着更高的IoU逐渐细化,这意味着候选框变得更接近于真值。在第一次和第二次迭代时,候选框精度可以迅速提高,并在第四次迭代时后逐渐趋于收敛。
该研究用APs@0.5表示IoU阈值为0.5时的AP。表1显示了基于ResNet-50主干网络的模型的APs@0.5-0.95,APs@0.5,APs@0.75,以及不同迭代次数时的测试精度和速度。从表1可以看出,结果与图2中的实验结果保持一致,即AP在第三、四次迭代时开始逐渐收敛稳定,然后小幅下降。另外,该研究在使用ResNet-101作为主干网络时也观察到了同样的现象。因此,后续实验的所有后续结果均使用三次迭代进行测试。同时,该研究发现模型在测试期间的时间成本与测试时细化迭代的次数成正比。该研究的模型需要117ms完成基于三次迭代的一帧图像检测。同样,更高的检测速度可以用轻量化的主干网络或更少的迭代次数来实现。
4.2 在Pascal VOC上的评估
在本节中,实验模型将该方法提出的多步迭代回归模块整合在R-FCN网络上,主干网络为ResNet-50和ResNet-101[1]。实验将原始的R-FCN网络和最先进的Cascade R-CNN网络与改进过的多步迭代的R-FCN(表中简称为LSTM-R-FCN)进行比较。该研究同样使用相同业界通用指标在Pascal VOC数据集上进行实验和评估。
从表2的结果可以看出,基于这两种主干网络,该研究的方法在AP@0.5-0.95 和AP@0.75的表现都远远优于基准的R-FCN。同时,在AP@0.5-0.95下,该研究的模型的mAP比对应同样使用两个主干网络的Cascade R-CNN的mAP均高出1.8%。此外,该研究在AP@0.75下使用ResNet-101进行对比时,其mAP值比Cascade R-CNN的mAP值高2.2%。综上所述,与其他方法相比,该研究的模型具有更好的检测精度和更高的检测质量。这进一步证明了该研究提出的多步迭代检测模块的有效性。
4.3 在MS COCO上的评估
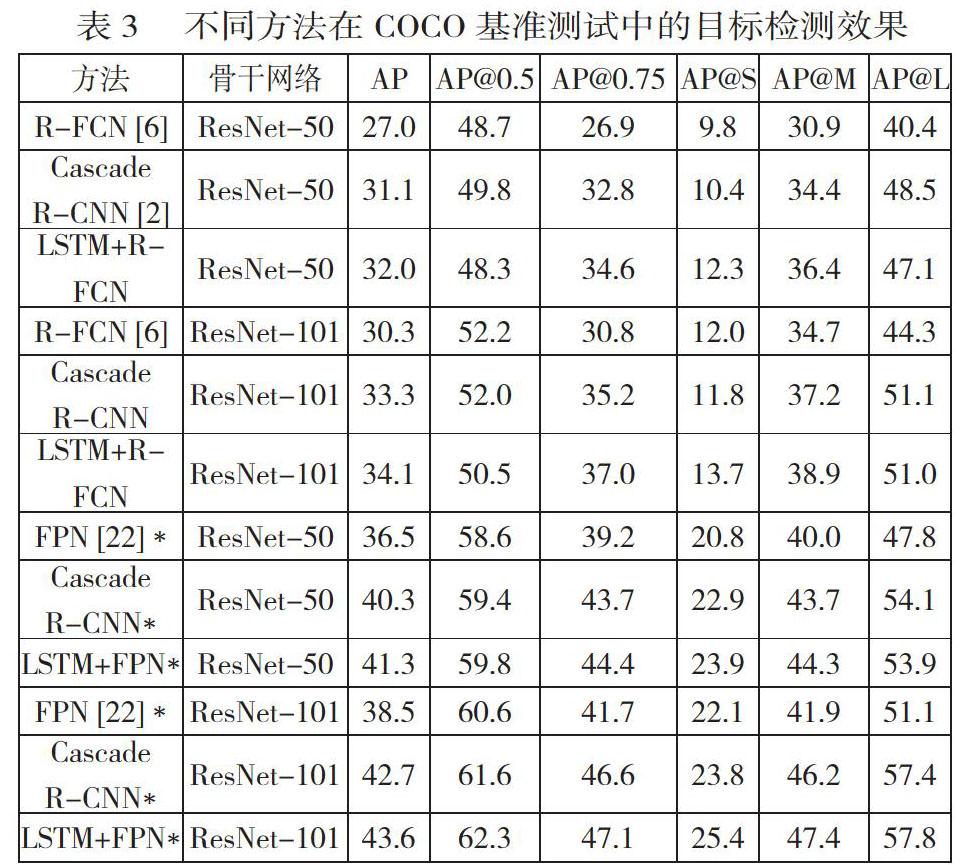
该研究也在MS COCO 2017数据集上评估所提出的方法,并将该研究提出的模块整合到R-FCN[6]和FPN[22]中。作为对比,该研究使用原始的R-FCN[6]、FPN[22]和Cascade R-CNN同时进行实验。表3的顶部显示了使用R-FCN作为基本框架时的结果。实验结果显示,当使用ResNet-50和ResNet-101时,该研究的模型分别比R-FCN的AP高出4.7%和3.5%。与Cascade R-CNN相比,该研究的方法在AP@0.5-0.95和AP@0.75下获得了更好的表现,这与Pascal VOC上的结果一致。表3中,用”*”表示的模型采用了FPN多尺度特征图的设计思路。与使用R-FCN的结果相比,所有指标下所有方法的表现均有更显著的提高。这表明更先进的基础框架让该研究提出的方法更加有效,因此在几乎所有不同的指标上都优于FPN和Cascade R-CNN。值得注意的是,该研究的模型在检测中小型目标时,即更难的任务方面,在所有情况下都比其他方法具有更高的AP。
4.4 進一步分析
为了进一步验证该研究的方法的确能够提高检测质量,该实验使用ResNet-101为主干网络以及R-FCN为主要框架,在Pascal VOC上对所有模型进行训练和测试。根据实验结果,图3中绘制了每个IoU阈值下所有模型的mAP。从这张图中,该研究发现所有模型在IoU为0.5、0.55和0.6时的mAP比较接近。然而,当IoU阈值大于0.6时,原始R-FCN的mAP开始迅速下降。当IoU阈值超过0.7时,该研究的方法开始优于Cascade R-CNN,并且IoU越高,改进幅度更大。特别值得注意的是,当IoU等于0.95时,该研究的方法得到的mAP比Cascade R-CNN的高2.5倍。这进一步说明该方法对模型生成高精度检测框有显著的性能提升,符合该研究的目的。
4.5 详细实验分析
为了进一步证实基于LSTM的回归模块的优点,该研究使用基于MLP的回归模块来替换原始模块并在Pascal VOC上进行对比实验,结果如表4所示。基于MLP的模块隐藏层维度与原始的LSTM的模块相同。MLP模块的第一层将形状为H*W*C的特征图编码成128维的向量,然后其输出层进行边框回归和前景-背景分类的置信度预测。表4的结果表明,基于LSTM的模块与基于MLP的模块相比具有明显的优势,特别是在AP@0.5-0.95下,基于LSTM模块的R-FCN与基于MLP模块的R-FCN 相比,其mAP提高了5.2% 。这显示了多步骤迭代回归模块引入LSTM层的优势:LSTM层通过单元内存和隐藏状态储存先前步骤的回归信息,这使其比MLP层更适用于前后步骤相关的迭代和回归。
五、 结束语
该研究提出了一个新的候选框迭代优化模块。在该模块中,RPN产生的候选框通过基于LSTM层的多步迭代优化模型进行不断细化和改进,直至收敛。实验表明,该模块可以自然而优雅的整合进类似于R-FCN和FPN的常见目标检测模型中,而无需进行过多的调整或结构修改,并且可以取代大多数两阶段框架的回归模块。实验结果表明,基准模型R-FCN和FPN通过引入该研究提出的细化模块,在Pascal VOC和MS-COCO基准数据集上的mAP均优于其对应的原始模型。不仅如此,优化后的模型也高于目前最先进的Cascade R-CNN目标检测模型。
参 考 文 献
[1]HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]//Proc of the IEEE conference on computer vision and pattern recognition. Las Vegas: IEEE Computer Society, 2016:770-778.
[2]HE K, ZHANG X, REN S, et al. Identity Mappings in Deep Residual Networks [C]//European conference on computer vision. Cham: Springer, 2016: 630-645.
[3]SZEGEDY C, TOSHEV A, ERHAN D. Deep neural networks for object detection [C]//Proc of the 26th International Conference on Neural Information Processing Systems. Lake Tahoe: Curran Associates Inc, 2013: 2553–2561.
[4]SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [J]. arXiv preprint arXiv:14091556, 2014.
[5]CAI Z, VASCONCELOS N. Cascade r-cnn: Delving into high quality object detection [C]//Proc of the IEEE conference on computer vision and pattern recognition. Salt Lake City: IEEE Computer Society, 2018: 6154-6162.
[6]DAI J, LI Y, HE K, et al. R-FCN: object detection via region-based fully convolutional networks [C]//Proc of the 30th International Conference on Neural Information Processing Systems. Barcelona: Curran Associates Inc, 2016.
[7]GIRSHICK R. Fast r-cnn [C]//Proc of the IEEE international conference on computer vision. Santiago: IEEE Computer Society, 2015: 1440-1448.
[8]GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]//Proc of the IEEE conference on computer vision and pattern recognition. Columbus: IEEE Computer Society, 2014: 580-587.
[9]JIANG B, LUO R, MAO J, et al. Acquisition of Localization Confidence for Accurate Object Detection [C]//Proc of the European Conference on Computer Vision. Cham: Springer International Publishing, 2018: 784-799.
[10]HE K, GKIOXARI G, DOLL?R P, et al. Mask r-cnn [C]//Proc of the IEEE international conference on computer vision. Venice: IEEE, 2017: 2961-2969.
[11]ZAGORUYKO S, LERER A, LIN T-Y, et al. A multipath network for object detection [J]. arXiv preprint arXiv:160402135, 2016.
[12]REN S, HE K, GIRSHICK R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks [J]. arXiv preprint arXiv:150601497, 2015.
[13]FU C-Y, LIU W, RANGA A, et al. Dssd: Deconvolutional single shot detector [J]. arXiv preprint arXiv:170106659, 2017.
[14]KONG T, SUN F, YAO A, et al. Ron: Reverse connection with objectness prior networks for object detection [C]//Proc of the IEEE conference on computer vision and pattern recognition. Honolulu: IEEE Computer Society, 2017: 5936-5944.
[15]LIU W, ANGUELOV D, ERHAN D, et al. Ssd: Single shot multibox detector [C]//Proc of the European conference on computer vision. Amsterdam: Springer, 2016: 21-37.
[16]REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real-time object detection [C]//Proc of the IEEE conference on computer vision and pattern recognition. Las Vegas: IEEE Computer Society, 2016: 779-788.
[17]ZHANG S, WEN L, BIAN X, et al. Single-shot refinement neural network for object detection [C]// Proc of the IEEE conference on computer vision and pattern recognition. Salt Lake City: IEEE Computer Society, 2018: 4203-4212.
[18]REDMON J, FARHADI A. YOLO9000: better, faster, stronger [C]//Proc of the IEEE conference on computer vision and pattern recognition. Honolulu: IEEE Computer Society, 2017: 7263-7271.
[19]GIDARIS S, KOMODAKIS N. Attend refine repeat: Active box proposal generation via in-out localization [C]//Proc of the British Machine Vision Conference. York, 2016.
[20]SINGH B, LI H, SHARMA A, et al. R-fcn-3000 at 30fps: Decoupling detection and classification [C]//Proc of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE Computer Society, 2018: 1081-1090.
[21]WILLIAMS R J, ZIPSER D. A learning algorithm for continually running fully recurrent neural networks [J]. Neural computation, 1989, 1(2): 270-280.
[22]LIN T-Y, DOLL?R P, GIRSHICK R, et al. Feature pyramid networks for object detection [C]//Proc of the IEEE conference on computer vision and pattern recognition. Honolulu: IEEE Computer Society, 2017: 2117-2125.
[23]EVERINGHAM M, VAN GOOL L, WILLIAMS C K, et al. The pascal visual object classes (voc) challenge [J]. International journal of computer vision, 2010, 88(2): 303-338.
[24]LIN T-Y, MAIRE M, BELONGIE S, et al. Microsoft coco: Common objects in context [C]//Proc of the European conference on computer vision. Zurich: Springer, 2014: 740-755.
[25]LIN T-Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection [C]//Proc of the IEEE international conference on computer vision, Venice: IEEE, 2017: 2980-2988.
[26]LI J, LIANG X, LI J, et al. Multistage object detection with group recursive learning [J]. IEEE Transactions on Multimedia, 2017, 20(7): 1645-1655.
[27]CHENG K-W, CHEN Y-T, FANG W-H. Improved object detection with iterative localization refinement in convolutional neural networks [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2017, 28(9): 2261-2275.
[28]DAI J, QI H, XIONG Y, et al. Deformable convolutional networks [C]//Proc of the IEEE international conference on computer vision, Venice: IEEE, 2017: 764-773.
[29]GRAVES A, JAITLY N, MOHAMED A. Hybrid speech recognition with Deep Bidirectional LSTM [C]//Proc of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding. Olomouc: IEEE Signal Processing Society, 2013: 273-278.
[30]SUNDERMEYER M, SCHL?TER R, NEY H. LSTM neural networks for language modeling [C]// Proc of the 13th annual conference of the international speech communication association, F, 2012.
[31]TIAN Z, HUANG W, HE T, et al. Detecting text in natural image with connectionist text proposal network [C]//Proc of the European conference on computer vision. Portland: Springer, 2016: 56-72.
[32]HOCHREITER S, SCHMIDHUBER J. Long short-term memory [J]. Neural computation, 1997, 9(8): 1735-1780.
[33]LIU M, ZHU M. Mobile video object detection with temporally-aware feature maps [C]//Proc of the IEEE conference on computer vision and pattern recognition. Salt Lake City: IEEE Computer Society, 2018: 5686-5695.
[34]CASTREJ?N L, KUNDU K, URTASUN R, et al. Annotating Object Instances with a Polygon-RNN [C]//Proc of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE Computer Society, 2017: 5230-5238.
[35]SHRIVASTAVA A, GUPTA A, GIRSHICK R. Training region-based object detectors with online hard example mining [C]//Proc of the IEEE conference on computer vision and pattern recognition. Las Vegas: IEEE Computer Society, 2016: 761-769.
[36]ABADI M, BARHAM P, CHEN J, et al. TensorFlow: a system for large-scale machine learning [C]//Proc of the 12th USENIX conference on Operating Systems Design and Implementation. Savannah: USENIX Association, 2016: 265–283.
[37]CHEN X, GUPTA A. An implementation of faster rcnn with study for region sampling [C]//Proc of the IEEE conference on computer vision and pattern recognition. Honolulu: IEEE Computer Society, 2017.
