利用叶绿素荧光动力学参数识别苗期番茄干旱胁迫状态
2021-09-04马敏娟王英允宋怀波
龙 燕,马敏娟,王英允,宋怀波
(1.西北农林科技大学机械与电子工程学院,杨凌 712100;2.农业农村部农业物联网重点实验室,杨凌 712100;3.陕西省农业信息感知与智能服务重点实验室,杨凌 712100)
0 引 言
水分对作物的生长至关重要,水分亏缺会造成作物的水势和膨压低于正常水平,使其正常代谢机能受到干扰或破坏,严重威胁作物的生长发育[1]。干旱作为一种多维胁迫,可以引起作物表型、生理学、生物化学和分子水平的变化,严重时将导致光合作用终止和代谢紊乱,最终导致作物死亡[2]。因此,及时识别作物干旱胁迫程度,对作物生长发育、合理灌溉和产量提升都具有重大意义。
目前,检测作物所受胁迫程度的方法主要分为基于生理特性指标[3-7](植物茎流、水势、蒸腾速度、茎体水分)和基于形态[8-10](2D图像、3D图像、光谱特征)两类。虽然利用生理特征指标可以得到较高的检测精度,但其操作复杂,对作物会造成不同程度的损伤。而基于形态的检测方法以无损、快速的优点被广泛用于作物胁迫程度识别。其中叶绿素荧光成像技术能反映叶片对光能的吸收和转化、能量的传递和分配以及反应中心状态等作物光合作用信息[11],利用叶绿素荧光参数可在肉眼看到症状前就识别出胁迫特征,已广泛应用于植物各类胁迫状态的监测和预警[12]。翁海勇等[13]利用叶绿素荧光参数结合随机森林算法构建了柑橘不同程度黄龙病的诊断模型,其总体识别正确率为 97.50%。Wang等[14]首次利用叶绿素荧光成像技术和热红外成像技术完成对甘薯多种病毒感染的区分,并得到光化学淬灭系数是区分不同病毒的最敏感参数。Dong等[15]利用叶绿素荧光成像技术完成对番茄幼苗冷害的识别。通过计算荧光参数和冷害程度的Person相关性,得到实际光化学量子产量、稳态光适应光化学淬灭系数等 6个荧光参数,可用于评估番茄幼苗的冷害程度,并利用神经网络构建预测模型,其训练集、验证集的识别准确率分别为90.3%、90%。梁欢等[16]通过叶绿素荧光参数对不同品种的紫花苜蓿种质苗期抗旱性进行了对比,从 109份紫花苜蓿中筛选出了14份抗旱高光效种质。Zhou等[17]验证了叶绿素荧光技术能够识别植物不同水分和氮素的状态,并利用支持向量机(Support Vector Machines,SVM)、径向基函数(Radial Basis Function,RBF)和BP(Back Propagation)神经网络方法完成对9种不同水氮耦合状态的分类。Wang等[18]以大豆幼苗为研究对象,分析了在轻度干旱胁迫和重度干旱胁迫下叶绿素荧光参数的变化,得到实际光化学量子产量与干旱程度相关度最高,并利用实际光化学量子产量完成抗旱品种的筛选。
上述研究利用叶绿素荧光技术识别作物非生物胁迫取得一定的成果。但还存在如下问题:1)大部分研究只局限于对暗适应后最小荧光、最大光量子效率等荧光参数进行分析,未能充分利用叶绿素荧光参数信息;2)大部分研究未利用荧光图像信息,只采集某几个点的荧光参数作为整个植株叶片的荧光参数,不能完全代表整个植株的荧光信息。因此本研究以苗期番茄为研究对象,基于叶绿素荧光成像技术,采集植株冠层的荧光图像,将荧光图像均值作为该植株的荧光参数,从而更准确的代表植株叶绿素荧光信息。同时,研究与干旱胁迫相关的荧光参数选取方法,挖掘具有重要价值的叶绿素荧光参数,提高荧光参数的利用率。最后建立干旱胁迫状态识别模型,以期实现苗期番茄早期干旱胁迫的监测以及干旱胁迫状态的判定,为植物健康生长和合理灌溉提供理论依据。
1 试验和方法
1.1 干旱胁迫试验
干旱胁迫试验于西北农林科技大学旱区节水农业研究院人工气候室进行(北纬 34°07′39″,东经 107°59′50″,海拔648 m),室内光周期为昼/夜14 h/10 h,环境温度为昼/夜24 ℃/14 ℃,空气相对湿度为60%。采用盆栽土培法,试验土壤为进口泥炭土,土壤容重1.1 g/cm3,土壤养分含量为:磷1.52 g/kg,钾2.64 g/kg,镁0.28 g/kg,硝态氮0.78 g/kg,铵态氮 0.56 g/kg,pH值6.0,有机质质量分数64%。选取高13 cm,口径15 cm的塑料盆,每盆装土0.5 kg。于2020年7月选择长势、大小较为一致的70株番茄苗移栽到塑料盆中,每盆1株。移栽当天浇透水,缓苗2 d,第3天再次补充水分,后续不再浇水,直至番茄苗萎蔫。为方便后续建模分析,在每次荧光参数采集之前,使用土壤湿度传感器测量 3次土壤湿度取平均值作为所测样本土壤含水率的实际值,将土壤含水率为最大持水量的75%~85%、55%~65%、35%~45%、15%~25%分别记为适宜水分、轻度干旱、中度干旱和重度干旱[19]。
1.2 叶绿素荧光动力学参数采集
本研究使用PlantScreen植物表型成像分析系统(北京易科泰生态技术有限公司)测量叶绿素荧光参数,系统由测量光光源(610~620 nm,红光)、光化学光光源(610~620 nm,红光;470~480 nm,蓝光)、饱和光光源(470~480 nm,蓝光)、暗适应室、计算机以及控制软件等部件组成。将暗适应30 min的番茄幼苗放入检测箱中,通过计算机控制程序运行,并利用 FluorCam 7.0软件采集、分析数据。由于整个番茄植株的叶片高低不同,荧光激发的强度对不同位置的叶片也不同。为避免高低叶位对结果的影响,该研究只选取植株冠层最上层的 3片叶片的荧光图像为感兴趣区域,将感兴趣区域的像素均值作为该植株的叶绿素荧光参数值,图1为不同干旱胁迫状态下最小荧光参数感兴趣区域选取结果。每个样本共获取98幅荧光图像,即共有98个叶绿素荧光参数,参数符号和参数名称如表1所示。

表1 98个叶绿素荧光参数表Table 1 98 chlorophyll fluorescence parameter table
1.3 数据处理方法
1.3.1 数据归一化
数据归一化也就是数据无量纲化处理,主要解决数据的可比性。将原始数据均转换为无量纲化指标测评值,即各指标值都处于同一个数量级别上,可以有效提高数学模型的准确性[20]。本研究选择较为常用的线性归一化方法对各参数进行归一化处理[21]。
1.3.2 特征参数提取
对所获取的98个叶绿素荧光参数做Person相关性分析可得,98个荧光参数之间存在不同程度的相关性,如图2所示,其中相关系数绝对值大于0.6的占比大于40%,相关系数绝对值最高可达0.934。表明各参数间存在冗余信息。
为挖掘具有重要价值的荧光参数,并简化干旱胁迫识别模型复杂度,降低计算时间,增强模型泛化能力,提高识别准确率,本文分别采用连续投影法(SuccessiveProjections Algorithm,SPA)、迭代保留信息变量法(Iteratively Retains Informative Variables,IRIV)和变量空间迭代收缩法(Variable Iterative Space Shrinkage Approach,VISSA)对叶绿素荧光参数进行优选。
SPA算法是一种前向循环变量选择方法,能够有效的选择特征变量,降低数据维度[22]。该方法先设定选取参数个数的最大值和最小值,然后循环迭代,计算该变量在其他未被选入变量上投影的大小,将投影向量最大的变量引入到变量组合中,建立偏最小二乘(Partial Least Squares,PLS)回归模型,通过计算不同参数组合得到的均方根误差(Root Mean Square Error,RMSE),直至特征参数的数目达到最小RMSE对应的数值,循环结束[23]。
IRIV算法是云永欢等[24]于 2014年提出的一种特征变量选择方法。该方法通过模型集群分析(Model Population Analysis,MPA),将全部变量划分为强信息、弱信息、无信息和干扰信息变量。通过剔除干扰信息变量和无信息变量,保留强信息变量和弱信息变量,最后通过反向消除策略对剩下的强信息变量和弱信息变量进行反向消除,剩余变量即为特征变量。
VISSA算法是基于 MPA 和加权二进制采样(Weighted Binary Matrix Sampling,WBMS)。首先,使用WBMS从原始数据集中提取一些子训练数据集,然后建立变量子集的PLS模型。对不同子模型的交互验证均方根误差(Root Mean Square Error of Cross-Verification,RMSECV)值进行排序以获得最佳模型,提取最佳模型并获得新的子训练数据集。重复上述过程,直到所有变量的权重恒定(1或0)。最后得到最佳模型,选择最优变量集[25]。
1.3.3 建模方法及模型评价
本研究利用线性判别分析(Linear Discriminant Analysis,LDA)、支持向量机(Support Vector Machines,SVM)和k 最近邻(k-Nearest Neighbor,KNN)3种机器学习算法建立干旱胁迫状态识别模型,并分析其对识别准确度的影响。采用 K-折交叉验证(K-fold cross validation) 评价模型性能。该研究选择5折交叉验证法。在每一折交叉验证中,从样本数据中随机选择 80%样本构建训练集,其余 20%为测试集。对整个数据集计算RMSE,作为模型评估的指标。对所有样本的识别结果建立全局混淆矩阵,计算准确率。
2 结果与讨论
2.1 参数优选
该研究使用SPA、IRIV和VISSA算法对叶绿素荧光参数进行优选,图3为不同算法的优选过程,表2为不同算法的优选结果。
2.1.1 基于SPA的参数优选
该研究使用 SPA算法对叶绿素荧光参数进行优选时,考虑到计算效率,设定选取参数个数范围为1~38。参数个数与其对应的 RMSE如图3a所示。由图3a可知,RMSE随着参数个数的增加呈现先下降后基本不变的趋势,表明参数个数较少时(参数个数小于6),难以代表植物光合作用的全部信息,随着参数个数不断增加,RMSE不断减小,表明SPA所选取的荧光参数包含植物受水分胁迫的重要信息,在建模中起积极的作用。当选取的参数个数大于 12(图3a中方框所示)后,RMSE基本保持稳定,因此研究共提取12个叶绿素荧光动力学参数。SPA选取的12个参数如表2所示。
2.1.2 基于IRIV的参数优选
在IRIV选择参数的过程中,采用5折交叉验证的方式建立PLS模型,以RMSECV为评价指标选择特征变量。参数选取过程如图3b所示,经过第1次迭代,参数个数由98降为45,第2、3次迭代后,参数个数稳定在36。通过反向消除无关或干扰参数后,保留了29个叶绿素荧光动力学参数。IRIV选取的29个参数如表2所示。
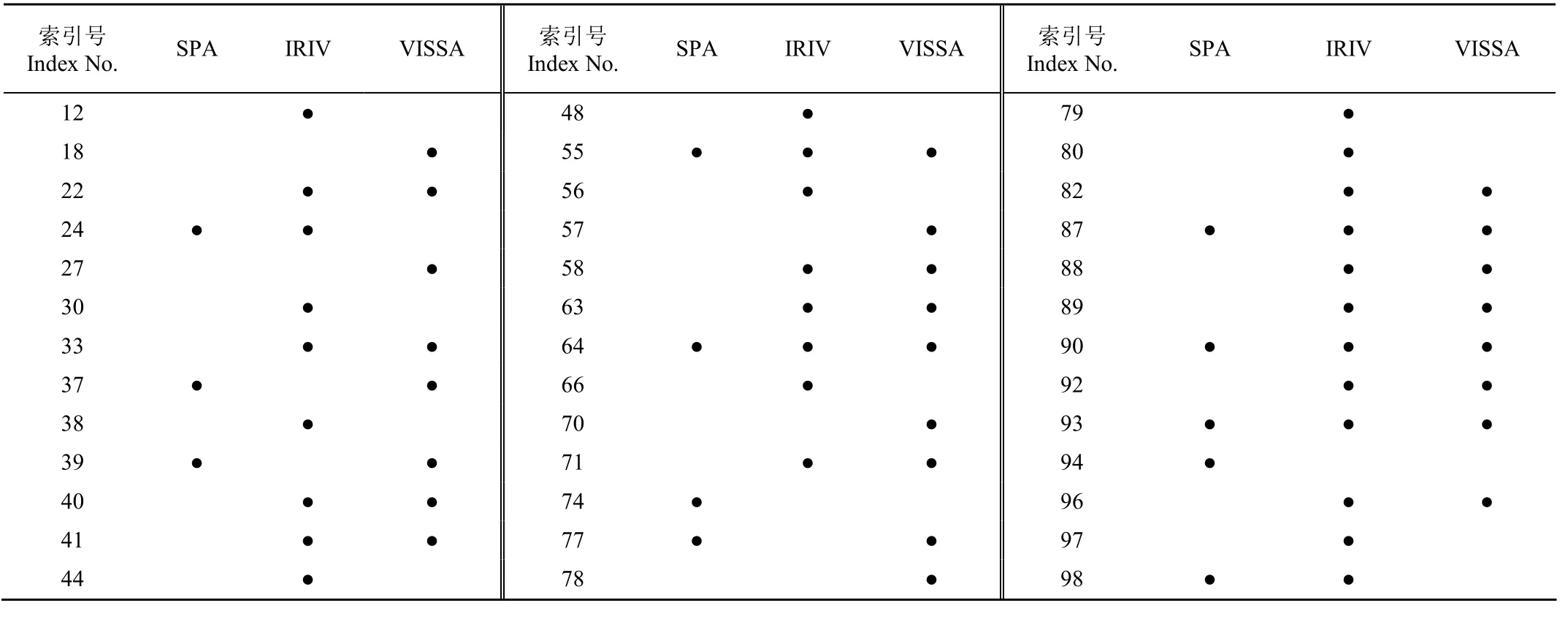
表2 3种参数优选算法结果Table 2 Three parameter optimization algorithm results
2.1.3 基于VISSA的参数优选
参考文献[25],设置VISSA算法中WBMS生成的变量个数为2 000,子模型比例设置为5%,变量的初始权重设置为0.5。并采用5折交叉验证的方式建立PLS模型,根据不同参数个数下的RMSECV确定最终变量个数。图3c是RMSECV随优选参数个数的变化趋势,由图3c可知,随着参数个数的增加,RMSECV呈现先大幅度下降后小幅度增加的趋势。较少的变量对应的RMSECV较大,表明较少的变量无法准确表达干旱胁迫程度。当参数个数过大时,RMSECV随之增大,表明此时的参数中包含冗余信息,对建模不利。该研究在RMSECV最小处(图3c中方框所示)选得25个叶绿素荧光动力学参数。VISSA选取的25个参数如表2所示。
2.1.4 叶绿素荧光参数选取结果分析
根据上述3种参数优选算法,得到了3种叶绿素荧光动力学参数的组合。表2是SPA、IRIV、VISSA所选叶绿素荧光参数的结果比较。可以看出不同算法选取的参数有部分重叠,其中 3种算法都选中的荧光参数有 5个,分别为55号QY_L2、64号NPQ_L3、87号qL_L2、90号 qL_Lss、93号 qL_D3。为更深层次的分析上述 5个荧光参数和干旱胁迫的关系,本文分析了不同干旱程度下这5个荧光参数的变化,如图4所示。
由图4可知,QY_L2随着干旱胁迫程度的增加呈现减小的趋势,说明干旱胁迫降低了叶片的光化学淬灭能力。NPQ_L3为非光化学淬灭,其反映了光系统Ⅱ吸收的能量用于耗散为热量的比例,也就是植物耗散过剩光能为热量的能力,即光保护能力[26]。NPQ_L3随着干旱胁迫程度的增强而上升说明叶片在干旱胁迫下天然色素通过热耗散的方式释放过多的热量,来减少 PSⅡ吸收的过多光能,从而减缓衰老[27]。qL_L2、qL_Lss、qL_D3均为光化学淬灭,其表明了光系统Ⅱ吸收的能量用于光化学反应的比例,开放态的光系统Ⅱ反应中心所占的比例,反应了光合活性的高低,除qL_Lss在轻度干旱状态下稍有上升外,其余均随着干旱胁迫程度增加而降低,表明干旱胁迫导致PSⅡ天然色素捕捉光能分配给电子传递速率的值减少[28]。
2.2 干旱胁迫识别模型建立
利用LDA、SVM和KNN建立作物干旱胁迫识别模型。SVM建模选择种类为二次SVM,核函数为二次方内核,选择一对一多分类方法。KNN建模选择种类为加权KNN,设置邻近数为 10。各建模方法的识别准确率如表3所示。从表3可以看出,98个荧光参数均参与建模时,LDA识别准确率最高,为94.2%;由SPA选出的12个荧光参数参与建模时,LDA识别准确率最高,为94.6%;由IRIV选出的29个荧光参数参与建模时,LDA识别准确率最高,为97.8%;经VISSA选出的25个荧光参数参与建模时,LDA识别准确率最高,为97.8%。仅用3种算法提取的 5个公共参数建模时,准确率最高可达83.7%,仍达到了较高的精度,表明这5个公共参数是与植物干旱胁迫程度高度相关的荧光参数。
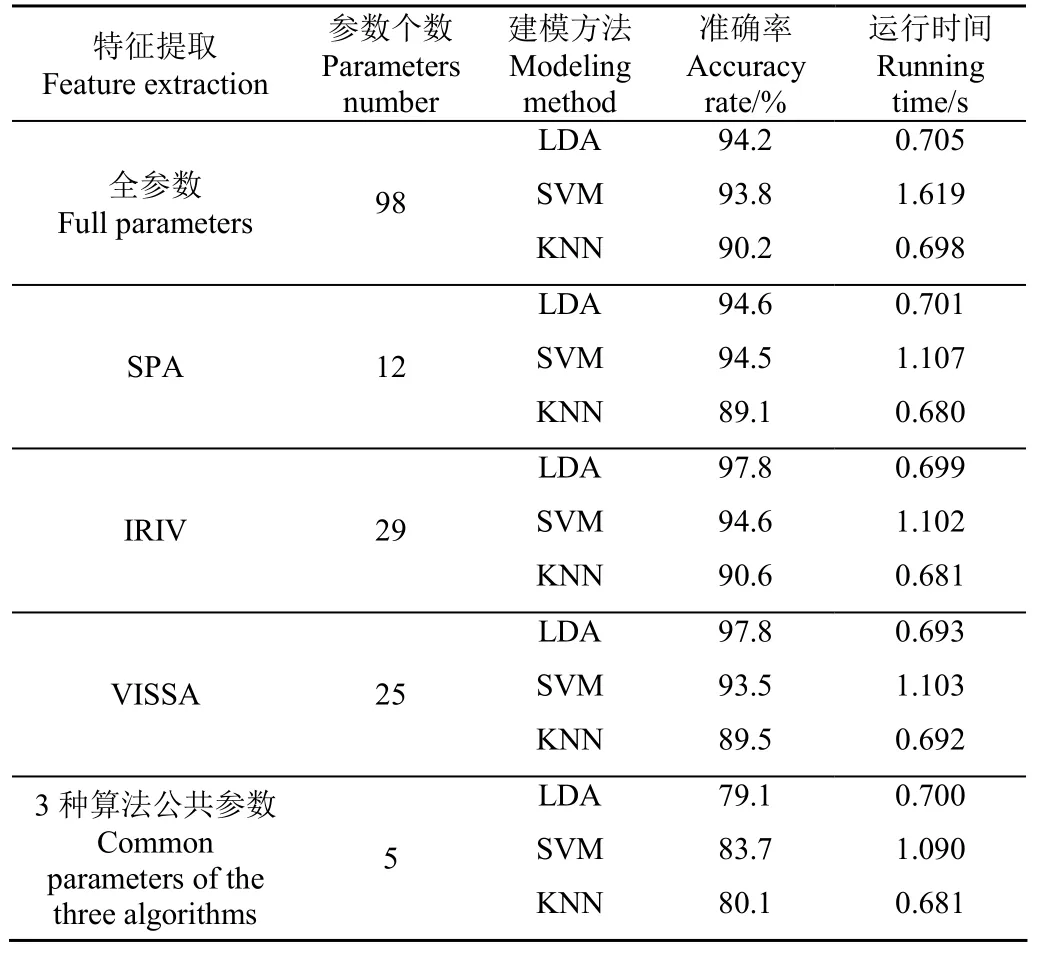
表3 不同建模方法下的干旱胁迫识别准确率Table 3 Model accuracy rate under different modeling methods
综上所述,LDA建立的苗期番茄干旱胁迫识别模型的平均识别准确度最高,SVM次之,KNN效果最差。SPA、IRIV、VISSA所选参数的建模准确度与全参数的建模准确度相当或略高,表明所选参数包含了植物干旱胁迫状态下的大部分光合作用信息,证明利用 3种参数优选算法提取荧光参数的有效性。
整体识别准确率虽然可以反映模型整体的分类效果,但无法得到不同干旱程度的分类效果,因此,需要通过混淆矩阵来分析具体的分类效果[29],本研究主要针对分类效果最好的LDA模型下不同参数提取方法对应的结果进行分析,其混淆矩阵如图5所示。可以得到IRIV-LDA对适宜水分、轻度干旱、中度干旱和重度干旱的识别准确率分别为 100%、95%、98%、98%,较全参数-LDA分别提高了6%、4%、2%和2%,建模效果良好。
3 结 论
以苗期番茄植株为研究对象,利用叶绿素荧光参数完成不同干旱胁迫状态下植株的干旱等级识别。使用连续投影法(Successive Projections Algorithm,SPA)、迭代保留信息变量法(Iteratively Retains Informative Variables,IRIV)和变量空间迭代收缩法(Variable Iterative Space Shrinkage Approach,VISSA)获取与干旱胁迫相关的荧光参数,通过线性判别分析(Linear Discriminant Analysis,LDA)、支持向量机(Support Vector Machines,SVM)和k 最近邻(k-Nearest Neighbor,KNN)算法构建识别模型。通过对比分析试验结果,确定最优干旱胁迫状态识别模型。主要有以下结论:
1)为降低模型复杂度和冗余度,使用SPA、IRIV、VISSA对获取的98个叶绿素荧光参数进行参数优选,分别得到12、25、29个荧光参数,并分析3种算法提取的5个公共参数(光适应过程中L2时刻的实际光量子效率、光适应过程中L3时刻的非光化荧光淬灭、基于“Lake”模型的光适应过程中L2时刻的光适应光化学淬灭、基于“Lake”模型的稳态光适应光化学淬灭、基于“Lake”模型的暗弛豫过程中D3时刻的光适应光化学淬灭)的变化趋势和其所反映的干旱程度对植株光合作用的影响。
2)基于上述荧光参数提取,分别使用LDA、KNN、SVM算法建立干旱胁迫状态识别模型,试验结果表明LDA算法建模准确度高于KNN和SVM算法,且参数优选之后的建模准确度与全参数建模准确度相当或有所提高,表明了参数优选方法的有效性。仅用三种算法提取的5个公共参数建模时,准确度最高可达到83.7%,表明这 5个公共参数是与植物干旱胁迫程度高度相关的荧光参数,包含了干旱胁迫下植物光合作用的大部分信息。
3)针对建模效果最好的 LDA模型,对不同荧光参数建模结果的混淆矩阵进行分析。可以得到 IRIV参数优选得到的LDA模型对适宜水分、轻度干旱、中度干旱和重度干旱的识别准确率较全参数分别提高了6%、4%、2%和2%,准确率分别达到了100%、95%、98%、98%。试验结果表明利用叶绿素荧光动力学参数对苗期番茄干旱胁迫状态识别是可行的。
