基于噪声估计的改进能量熵语音端点检测算法*
2021-08-30蒋学仕
蒋学仕
(中国西南电子技术研究所,成都 610036)
0 引 言
语音端点检测是用来区分语音与非语音的一种技术,在语音通信、语音识别、语音编码等方面都有重要作用。准确的语音端点检测技术既可以提高语音通信系统的传输效率,避免传输非语音数据造成的带宽与功率的浪费,也可以在语音识别、语音编码中提高算法对语音特征的提取效率。
现有的语音端点检测算法主要分为基于特征参数的检测算法、基于统计模型的检测算法、基于神经网络的检测算法。基于特征参数的端点检测算法由于不用建立模型,不需要大量数据进行训练,具有运算量与复杂度较低等优势,应用范围更为广泛。常用的基于特征参数的语音端点检测算法[1-2],随着信噪比的降低,提取的语音特征参数准确度逐渐恶化,检测性能下降。谱熵[3-4]由于对语音幅值不敏感,只与语音信号与噪声信号在频带上的分布差异与能量占比有关,作为特征参数,对噪声具有一定鲁棒性。但在低信噪比下,由于噪声对谱线的损伤,谱熵的准确度开始下降。文献[5]提出在谱熵计算时引入正常量 K 到能量概率分布公式中,得到改进的子带能量概率分布密度公式,提升谱熵的性能;文献[6]采用加权系数与丢弃损伤子带的方式来进一步改善谱熵的鲁棒性。但以上方法比较粗略,低信噪比下性能提升有限。文献[7]通过结合语音短时能量的凸性与子带谱熵的凹性,构造出了鲁棒性更好的能量熵。在能量熵算法的基础上,文献[8]对短时能量求解对数,平衡不同幅度信号下短时能量差异过大的问题。文献[9]采用中值滤波来缓解能熵比曲线不平滑的情况。文献[10]则将改进子带能量概率公式、对数能量特征值、中值滤波进行了结合,提出了改进的子带能熵比。
综上所述,现有基于能量熵的端点检测改进工作并未对噪声这一导致短时能量、子带谱熵性能下降的直接原因给予准确的分析与处理,所以现有改进措施对噪声的适应性较差,低信噪比下端点检测性能提升有限。另外,在端点检测算法中,判决门限的抗噪性能也至关重要,但现有文献对判决门限的研究往往不够充分。
针对上述问题,本文提出利用噪声估计值来剔除短时能量中的噪声,提升短时能量的凸性;计算语音存在概率作为加权系数引入能量概率分布公式,提升语音段子带谱熵的凹性,然后将凸、凹性得到增强的短时能量与子带谱熵结合,构造出鲁棒性更好的改进能量熵;得益于对噪声的准确估计,本文进一步构造出具备较好抗噪性能的动态门限,并给出基于改进能量熵与动态判决门限的实时端点检测策略。本文利用噪声估计值与语音存在概率对短时能量、子带谱熵、判决门限都进行了优化,增强了特征值与判决门限在低信噪比下的抗噪声性能,而且运算复杂度低,适合实时处理。
1 传统能量熵端点检测算法
传统能量熵算法[7]的基本思路是计算短时能量与子带谱熵两个特征值,然后再将两者结合,构造出能量熵。
1.1 短时能量
语音属于时变信号,但在几十毫秒的短时范围内可以按稳态处理,考虑到帧间语音特征参数的平稳性,还需要在帧间重叠一部分数据。对语音信号S(n)按N个点分帧,帧间重叠50%。分帧后的信号为S(n,l),l代表帧数,n(1≤n≤N)代表帧内的点。对S(n,l)加汉宁窗h(n)做预加重处理,求其短时傅里叶变换,得第l帧的频谱函数为
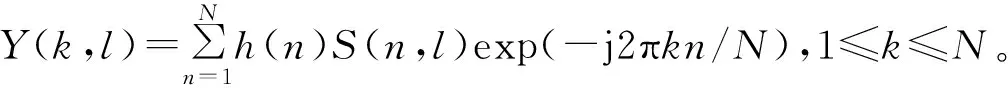
(1)
在频域求得短时能量为
(2)
考虑到实数信号频谱的对称性,为了减少运算量,这里只取一半的点。短时能量计算简单,高信噪比下,靠语音段与非语音段的能量差异,通过设置固定门限,能够实现语音端点检测。
1.2 子带谱熵
对语音信号S(n)一样的分帧加窗快速傅里叶变换(Fast Fourier Transformation,FFT)处理,得到第l帧的频谱函数Y(k,l),将4个谱线组成一个子带,一帧分成Nb个子带,计算得到得子带能量为
(3)
子带能量概率为
(4)
子带谱熵为
(5)
因为语音的频谱呈带状特性,功率谱分布集中,子带谱熵较小,而非语音的功率谱在各频段的分布相对分散,子带谱熵较大,因此可以通过计算子带谱熵来对语音段与非语音段进行区分。
2 改进能量熵算法
2.1 噪声对短时能量与子带谱熵的影响
随着噪声的增大,计算的短时能量会随着噪声能量的变化而变化,语音段与非语音段能量上的差异变小,导致短时能量性能下降。另外,随着噪声增大,语音段频带内总能量也随着增大,公式(4)计算的语音能量概率值下降,导致谱熵性能下降。
2.2 噪声估计修正的短时能量
2.2.1 噪声能量初估计
采用基于最小时间递归平均算法进行噪声谱估计,首先对短时傅里叶变换的幅度的平方分别进行时频域平滑,得到带噪语音的短时局部能量谱值。
用汉宁窗进行相邻频点间的平均:
(6)
式中:b(i)为局部窗函数,用于在相邻频点间求平均,窗长最小取3;|Y(k-i,l)|为第l帧的第k-i个频点的幅度谱。然后用平滑因子在时域进行一阶平滑:
S(k,l)=asS(k,l-1)+(1-as)Sf(k,l)。
(7)
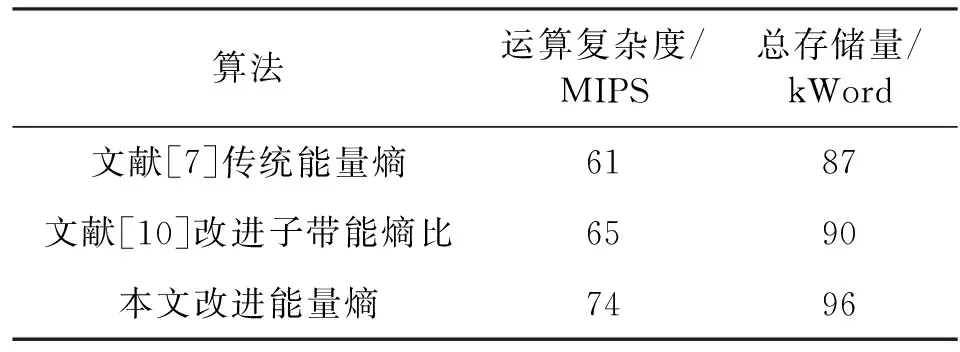
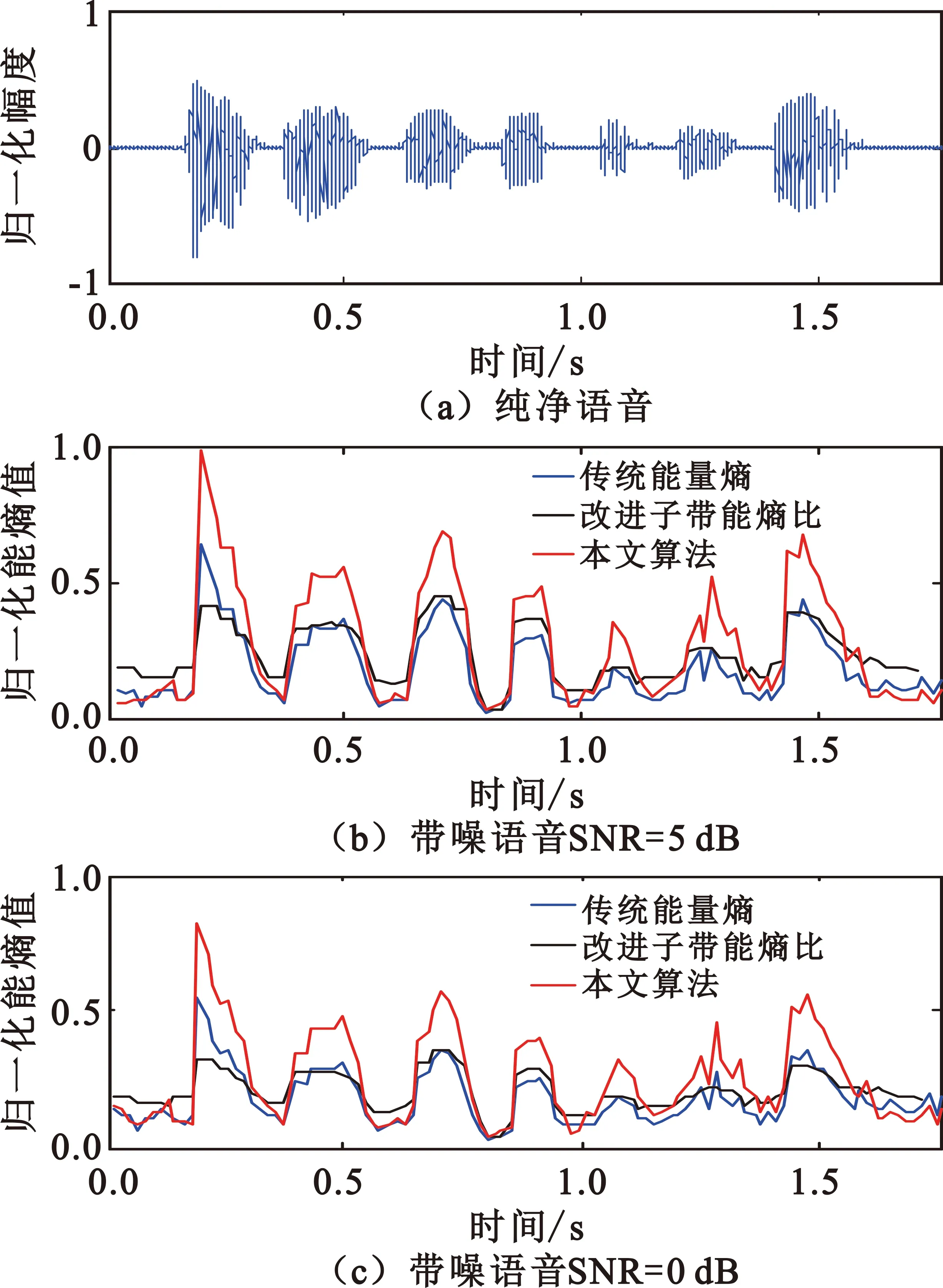
式中:S(k,l)为第l帧第k频点的短时局部能量谱;as为谱平滑因子,取值应接近于1,当出现局部突变点时,S(k,l)取值依靠权重较大的前一时刻S(k,l-1),缓解短时局部能量谱的突变。搜索窗长为L的窗内局部能量谱最小值作为纯噪声能量初步估计值。为了覆盖一个完整音节,L的长度一般为500~1 500 ms。该搜索窗为滑动搜索窗,滑窗间隔为n(n Smin(k,l′)=min{S(k,l′)|l-L+1≤l′≤l}。 (8) 2.2.2 根据门限判决更新噪声能量 求能量谱值与局部最小值的比值: Sr(k,l)=S(k,l)/Smin(k,l′)。 (9) 将比值与设定的门限δ进行比较。δ作为能量比值的门限,对噪声类型和环境不敏感,只与设定的信噪比有关。如果Sr(k,l)小于门限δ,则认为此时频带上不包含语音能量,可以更新噪声,得到一个控制因子: (10) 继续利用时域平滑因子αp、αd与控制因子I(k,l)进行平滑,首先得到 p(k,l)=αpp(k,l-1)+(1-αp)I(k,l)。 (11) 然后再进一步平滑得到噪声估计的更新因子 (12) (13) 式中:Y(k,l-1)为公式(1)计算的频谱函数。 2.2.3 修正短时能量 利用噪声能量估计值修正短时能量,将带噪语音中的噪声能量剔除,得到噪声估计修正的短时能量: (14) 对一段信噪比0 dB的带噪语音分别计算传统短时能量与噪声估计修正的短时能量,如图1所示,传统短时能量值随着噪声的增大而抬高,固定检测门限失效,检测门限设置变得困难。噪声估计修正的短时能量由于已将估计的噪声能量剔除,受噪声的影响小,固定检测门限仍然适用,低信噪比下鲁棒性更好。 图1 噪声估计修正的短时能量 2.3.1 求解先验信噪比 采用基于先验信噪比时频域分布特性的局部语音存在概率与全局语音存在概率两个参数来计算语音存在概率。首先基于噪声估计值,先求得后验信噪比 (15) 式中:λd(k,l)是噪声估计值,|Y(k,l)|是带噪语音幅度谱。再用α对其进行平滑,为了缓解短时局部突变,α取值应接近于1,得到先验信噪比 ξ(k,l)=αξ(k,l-1)+(1-α)max(γ(k,l)-1,0)。 (16) 2.3.2 求解语音存在概率 利用β对先验信噪比做平滑,得到先验信噪比的递归平均值ψ(k,l): ψ(k,l)=βψ(k,l-1)+(1-β)ξ(k,l)。 (17) 再利用先验信噪比的递归平均值ψ(k,l),并结合频域局部窗和全局窗来计算局部以及全局递归先验信噪比 (18) 式中:hη(i)为汉宁窗,窗长η可以取不同值,窗长小代表局部,窗长大代表全局。求得对应ψη(k,l)后,根据以下不等式,得到全局与局部语音存在概率: (19) 式中:ψmin和ψmax是经验值,其作用是作为门限,尽可能地在保留弱语音成分的同时削弱噪声,其值分别为0.1(-10 dB)和0.8(-1 dB)。 联立局部与全局语音存在概率,得到最终的语音存在概率: prob(k,l)=plocal(k,l)pglobal(k,l),prob(k,l)∈[0,1], (20) 即只有当局部语音与全局语音都同时存在时语音才存在。 图2的(a)、(b)、(c)分别是一段信噪比5 dB的带噪语音时域图、语谱图、计算的语音存在概率分布图。可以看到图(b)语谱图中呈现带状特性的就是语音的频带,其对应的时间与频带映射到图(c)语音存在概率分布图上,语音概率基本都接近1,而非语音部分对应到图(c)语音存在概率分布图上,语音概率基本都接近0。计算的语音存在概率能够比较精准地反映语音在时域与频域的真实分布情况。 图2 语音存在概率分布 2.3.3 语音存在概率加权的子带谱熵 语音存在概率是对每帧每个频点上语音概率大小的估算,将语音存在概率作为加权系数与计算的幅度谱平方相乘,既保留了频带中语音频点的能量,又削弱了噪声频点的能量,减轻了噪声对语音段能量概率分布的影响,提升了谱熵的抗噪性能。 将语音存在概率作为加权系数与幅度谱的平方相乘,得到语音存在概率加权的幅度谱平方 Yenergy_p(k,l)=prob(k,l)|Y(k,l)|2,1≤k≤N/2。 (21) 因为子带能量既能降低噪声对单一谱线的损伤,也能降低单一谱线语音存在概率出现偏差的影响,所以对加权后的幅度谱平方求子带能量: (22) 语音存在概率加权的子带能量概率: (23) 语音存在概率加权的子带谱熵: (24) 如图3所示,对一段信噪比0 dB的语音分别计算传统子带谱熵与语音存在概率加权的子带谱熵。语音存在概率加权的子带谱熵在非语音段的大小与传统子带谱熵基本保持一致,而在所有的语音段,加权的子带谱熵计算的谱熵值更小,凸性更好,即加权的子带谱熵在低信噪比下语音与非语音的区分度更高,准确度更好。 图3 优化的子带谱熵 由图1可知,经过噪声估计修正后的短时能量在非语音段比较平,在语音段向上凸起;又由图3可知语音存在概率加权的子带谱熵在非语音段比较平,而在语音段向下凹陷,将两者联立计算,可以进一步放大语音段与非语音段的差异,增加语音段与非语音段的区分度,使得端点检测更容易。 联立修正后的短时能量与语音存在概率加权的子带谱熵得到改进能量熵 (25) 式中:Ei(l)为噪声估计修正的短时能量,Hb_p(l)为语音存在概率加权的子带谱熵。 相比现有能量熵算法在一次语音端点检测中只能利用前导无话段或者噪声帧进行噪声能量估计,进而计算门限,本文算法首先对前导无话段功率求平均,作为噪声初始值,然后在语音段与非语音段一直按照本文所提方法继续进行噪声估计,保持对噪声的跟踪,适应噪声的非平稳变化,进而保证计算的动态门限的适应性。 联立噪声能量估计值与语音存在概率加权的子带谱熵得到自适应噪声变化的动态门限 (26) 在非语音段,Ei(l)=λ(l)-λd(l),λ(l)代表实际的噪声能量值,显然此时噪声估计值λd(l)应该大于修正后的短时能量值Ei(l),所以Ts(l)>Ei(l);在语音段,Ei(l)=S(l)+λ(l)-λd(l),S(l)代表实际的语音能量值,此时除非语音处于极低的负信噪比下,否则噪声估计值λd(l)应该小于修正后的短时能量值Ei(l),所以Ts(l) 本文的端点检测策略,能够按帧对语音进行实时的处理,即根据每帧的计算结果更新参数,更新门限,并对当前输入帧是否为语音给出实时的判决。算法实现流程图如图4所示。 图4 算法流程图 流程具体实现过程如下: Step1 对输入信号进行分帧加窗,以及短时傅里叶变换得到频谱信号。 Step2 对每一帧频谱信号进行噪声估计。 Step3 根据噪声估计值计算语音存在概率。 Step4 根据噪声估计值与频谱信号计算噪声估计修正的短时能量。 Step5 根据语音存在概率与频谱信号计算语音存在概率加权的子带谱熵。 Step6 求得改进能量熵,求得自适应动态门限。 Step7 将改进能量熵与动态门限逐帧进行比较,为了防止突发的非平稳噪声造成的干扰,连续3帧改进能量熵大于门限时判定这些帧为语音帧,这3帧中的第1帧判定为语音的起点否则为噪声帧。同时为了避免语音间隙不必要的频繁切换,在检测到语音后如果连续3帧改进能量熵比小于门限值则判定为非语音帧,否则仍然认为是语音帧。 能量熵算法的运算量主要集中在对语音数据分帧加窗后的FFT变换、谱能量求和与能量概率之间的运算。本文的改进能量熵算法虽然增加了噪声估计与语音存在概率计算,但以上运算可以与谱熵运算共用FFT变换,相比传统能量熵算法,改进能量熵算法额外增加的运算量并不大。 在TI的定点DSP芯片TMS320C64xx上分别实现文献[7]传统能量熵算法,文献[10]改进子带能熵比与本文的改进能量熵算法,运算量与存储量见统计表1。文献[7]的传统能量熵算法需要的运算量与存储量最小;文献[10]的改进子带能熵比算法需要把短时能量特征值转换为对数,而且增加了中值滤波,运算量与存储量居中;本文改进能量熵算法虽然在运算量与存储量上都有所增加,但相对嵌入式处理器几百兆的时钟频率与几十兆的片内RAM来说,算法复杂度基本属于同一个量级。 表1 算法运算量与存储量 仿真使用TIMIT语音库中100条连续语音作为纯净语音样本,采样频率8 kHz。加噪数据使用Noisex-92标准噪声库,分别添加白噪声、汽车噪声、人嘈杂噪声至纯净语音样本中,形成5 dB、0 dB的含噪语信号各300条。 计算传统能量熵[7]、改进子带能熵比[10]与本文的改进能量熵,归一化处理后比较以上特征值对语音与非语音的区分度。如图5所示,在信噪比5 dB、0 dB的平稳白噪声环境下,传统能量熵[7]对语音与非语音有一定的区分度,但是随着信噪比的降低,部分语音的特征值变得愈发不明显;改进子带能熵比[10]在计算短时能量时采用了对数能量特征值,缓解了能量差异的影响,所以各语音段的子带能熵值差异更小,中值滤波处理也使得子带能熵值的曲线更平滑,但除此之外改进子带能熵比的区分度并没有得到特别大的改善;本文算法按照2.2节和2.3节对短时能量值与子带谱熵中的噪声进行了优化处理,由此构造的改进能量熵受噪声影响更小,在非语音段更低更平稳,在语音段更高更突出,语音与非语音的区分度更好。 图5 白噪声下特征值区分度对比 如图6和图7所示,在信噪比5 dB、0 dB的汽车噪声和人嘈杂噪声等非平稳噪声环境下,改进子带能熵比相比传统能量熵,区分度优势并不明显,受噪声影响,两者都出现非语音段计算的特征值超过语音段的值,以及部分语音段的特征值不明显等严重影响端点检测准确性的情况,而本算法计算的特征值在非语音段依然比较平稳,语音段也未受明显影响,语音与非语音的区分度更好,算法性能受噪声影响更小。 图6 汽车噪声下特征值区分度对比 图7 人嘈杂噪声下特征值区分度对比 图8所示是一段带噪语音分别在5 dB、0 dB时归一化后的改进能量熵与动态门限值,可以看到动态门限值能跟随噪声水平的变化而变化,具备与能量熵一样的鲁棒性。 图8 动态门限 对添加白噪声、汽车噪声、人嘈杂噪声信噪比5 dB、0 dB的含噪语音样本各300条进行端点检测,得到语音端点检测的准确率如表2所列,端点检测正确率定义如下: 表2 端点检测准确度 正确率=(总帧数-(语音误判为噪声的帧数+噪声误判为语音的帧数)) / 总帧数。 由表2可见,在白噪声环境下,相比传统能量熵算法[7]、改进子带能熵比算法[10],本文的改进能量熵算法检测的平均正确率提升4.75%,在汽车噪声与人嘈杂噪声环境下端点检测的平均准确率分别提升8.1%和9.1%。 针对传统能量熵的短时能量与子带谱熵低信噪比下性能下降的问题,本文利用噪声估计修正短时能量,提升短时能量的凸性,利用语音存在概率优化子带谱熵,提升子带谱熵的凹性,并将凸、凹性得到增强的短时能量与子带谱熵结合得到鲁棒性更强的改进能量熵,通过将改进能量熵与基于噪声估计的自适应动态门限做比较,完成实时的语音端点检测。仿真实验表明,在多种噪声类型与信噪比下,相比现有能量熵算法与改进子带能谱比算法,本文构造的改进能量熵对语音与噪声的区分度更好,算法的端点检测准确率也更高。优异的性能、较低的计算复杂度、端点检测的实时性,使得该算法具备较为广阔的应用前景。如何进一步改进自适应动态门限,使其能更好地工作在负信噪比环境中将是下一步的研究内容。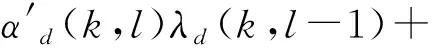

2.3 语音存在概率加权的子带谱熵


2.4 改进的能量熵
2.5 自适应动态门限
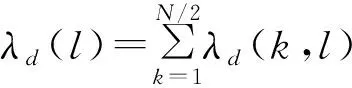
3 实时的端点检测策略与算法复杂度分析
3.1 实时的端点检测策略

3.2 算法复杂度分析
4 性能仿真与分析
4.1 特征值区分度比较


4.2 动态门限鲁棒性

4.3 检测准确度对比

5 结束语
