自定义模糊逻辑与GAN在图像高光处理中的研究
2021-08-24郭继峰庞志奇沈家友
郭继峰,李 星,庞志奇,沈家友,于 鸣
(东北林业大学 信息与计算机工程学院,哈尔滨150040)
1 引 言
在图像形成过程中,由于物体受到光照或者由于物体表面曲率过大,会在物体表面形成光斑,出现光斑的部分就是高光溢出的部分.高光溢出对于图像处理的影响主要表现在降低图像识别准确率、目标检测以及场景分析的精确度.
影响图像质量的主要因素有:光照不均匀、图像分辨率等.许野平等[1]人根据数字图像绘制亮度曲线,然后对高光溢出部分做非线性变换,压缩最大亮度值规定范围从而得到修复效果.高如新等[2]人通过双色反射模型变换得到图片的镜面反射和漫反射分量,再通过改进双边滤波器,然后对图像进行处理,去除图像的镜面反射,从而达到去除高光的效果.何嘉林等[3]人通过图片融合的方法去除图片高光,根据不同角度拍摄的图像亮度不同,通过对多张图片进行高光区域检测、图像融合、图像补色来消除高光区域[4].王祎墦等[5]人改进了图像的高光修复技术,使得对于存在饱和现象的高光区域的单一图像也能有较好的修复效果.这些方法对图像高光溢出的整体修复效果取得了良好的成效,但是对于图片的纹理修复效果并不理想,且获得的图片质量不高.
随着深度学习技术的不断发展,出现了一些使用卷积神经网络来对图像进行修复的方法.2014年,生成对抗网络GAN(Generative Adversarial Networks)面世,该网络由Goodfellow[6]等人根据博弈论中的零和博弈理论提出,引起了研究者们的极大关注,并对该网络模型做出改进,诞生了众多版本,其中影响较大的有CGAN(Conditional Generative Adversarial Nets)、DCGAN(Deep Convolution Generative Adversarial Networks)、Wasserstein GAN(WGAN)[7].其生成对抗网络的应用领域也在不断拓展,正是当前图像处理技术中的研究热点.
结合传统图像处理方法与生成对抗网络,本文提出了一种基于模糊逻辑与生成对抗网络相结合的图像高光处理技术,一方面利用模糊逻辑来模仿人脑的思维模式来对图像高光区域进行识别、判断,从而较好的实现对图像高光区域的划分;另一方面,引入生成对抗网络来修复图像,可以进一步提高在图像纹理修复方面的能力.
2 方法引入
2.1 模糊逻辑
2.1.1 模糊逻辑判断
图片高光区域部分通常是渐变式的,采用过去的方法——确定超过某一值的像素点划分为高光区域,很容易形成截断式分界线,而且对高光区域的划分效果不理想.为了解决这些问题,我们引入模糊控制的方法来对图像的高光进行阈值分割处理.
隶属度函数是模糊数学中的一个重要概念,模糊逻辑通过隶属度函数来确定集合所属范围[8,9].本文方法选取S型隶属度函数来进行处理.其表达式如式(1)所示.
(1)
由于本实验中对图片进行通道分离处理,因此在该式中,x表示连续通道中的亮度值,a,b,c是函数S的参数,a、c是亮度通道的取值范围,b表示划分为亮度区域的渡越点[10],通常取中点.使用该函数作为隶属度函数的优点在于能较好的区分出高光位置,不会导致大面积非高光区域被划分到高光范围内.准确的划分范围对后期图像修复的效果往往具有正向作用.
2.1.2 高光区域划分
本文通过模糊逻辑来对图片的高光区域进行分析,借助模糊逻辑模仿人脑不确定性的优点来精确定位高光区域范围.
在数字图像中,物体的颜色R、G和B分量都与照射到物体上的光相关联,使用RGB模型来对图像进行高光区域划分是较为困难的,因此本文中选用了HSV(Hue,Saturation,Value)模型来对图像进行处理.HSV是一种直观的颜色模型,它将颜色与强度分隔开的程度较其他模型更多,这对于图像高光区域的划分有很大的优势[11].
图像的高光区域划分完毕后,将本环节生成的高光区域划分以及二值掩码传入生成对抗网络模型中,在卷积神经网络中对图像进行后续处理.
首先将图片格式转换为HSV模型,将图片的三通道进行分离,对分离出来的亮度通道(V通道)进行模糊逻辑处理,图像传入模糊逻辑程序中后,使用上文中的S型隶属度函数对图像进行全局处理,从中选取属于高光部分的区域进行高光定位,取边界处位置进行框选,并生成二值掩码.至此高光区域的划分就结束,其流程图如图1所示.
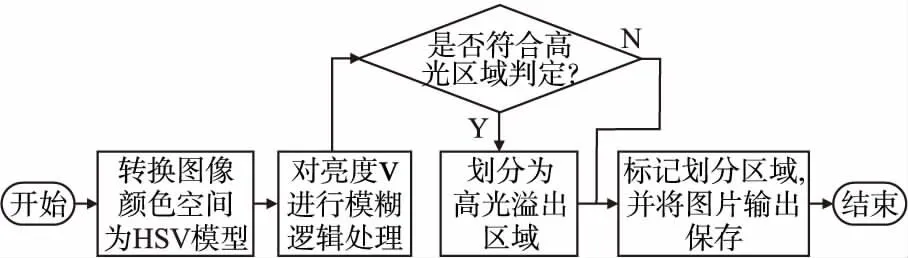
图1 高光区域划分流程图
2.2 生成对抗网络引入
划分高光区域后需要对高光溢出部分修复,常规方法是从高光溢出区域周围获取像素点的颜色来对溢出部分进行填充,但是这种方法生成的颜色通常不够自然,而且填充区域较为死板、不真实,用这种方法修复的区域通常没有原图像的纹理.本文使用基于深度卷积的生成对抗网络(GAN)来对图像高光区域进行修复,并在此网络的基础模型上做了一些改动.GAN的目标函数表示见式(2):

(2)
其中G表示生成器,D表示判别器,x表示来自于真实数据Pdata(x)中的部分采样,[·]表示期望值计算,Z表示经过模糊处理的数据,也就是输入到生成器网络中的数据,PZ(Z)表示原始的数据分布.生成对抗网络的框架主要有由一个生成器和一个判别器组成.两者互相对抗训练,判别器返回判断结果给生成器,生成器根据返回结果不断调整生成图像,最终当判别器难以区分生成器产生的数据时,该网络实现生成以假乱真的图像的目标.
2.2.1 生成器网络
本文的主要目的是通过该生成网络修复图像由于高光溢出导致的图像局部失真或缺失的问题,修复后的图像应尽量满足与真实图片在同一区域的相似度,并满足图像整体的完整性[12].本文生成器网络模型结构如图2所示.

图2 生成器网络结构模型
标准的卷积网络使用到的像素较少,难以完成大面积的图像修复[13],而扩张卷积能够扩大感受野区域[14],这对图像纹理以及图像的整体恢复发挥着重要的作用.
本文中对局部区域的恢复使用扩张卷积,改卷积方式可以通过使用更大的输入面积来计算每个输出像素,因此即使掩码部分图像有所缺失也能对图片进行良好的修复.选定区域的输入是具有二进制通道的图像,该通道标志着图像需要完成的掩码,而对于选定区域以外的其他部分,如果不希望它发生任何变化,则可以将选定区域以外的其他部分的输出像素改为输入RGB值.
对于一个大小是h×m卷积层,假设它的下一个卷积层大小是h′×m′,那么对于当前卷积层的扩张卷积计算公式可以表示为式(3):
(3)
其中kw和kh分别表示卷积核的宽高,η是扩张系数,xu,v和yu,v分别表示图层的输入和输出分量,σ(·)表示一个非线性传递函数,b是卷积层的偏置向量,W是内核矩阵,当η=1时该方程表示标准的卷积操作.
为了控制生成区域的光照强度,本实验在网络中引入一个亮度的参数l,该参数通过模糊逻辑计算获得.传入生成网络中的图片经过模糊逻辑获得当前图片x的亮度参数l,图片经过生成网络处理后得到图片x′,该图片再次经过模糊逻辑获得一个处理后的图片亮度l′,在本文中定义生成器部分的基本损失函数见式(4):
LossG1=logDG(x)+log(1-DG(G(MB,l′)))+αlog(-logDl(l′,l))
(4)
其中DG表示生成器网络的判别器,MB表示二值掩码,Dl是一个x和x′的亮度判断器,α是超参数,用来控制亮度的权重,本实验中取值为1.
为了使生成网络的效果趋于稳定,降低过拟合产生的可能性,本文还在均方误差(MSE)的基础上添加了L2正则项作为损失函数,并添加了二值掩码来代表需要生成的区域位置,其表达函数如式(5)所示:
(5)
其中MB表示二值掩码,⊙表示图像矩阵逐元素相乘,λ表示正则项系数,n表训练集中的样本数量,w表示生成器网络中的所有权重参数.
综上所述,生成器的损失函数可以表示为式(6):
LossG=LossG1+LossG2
(6)
2.2.2 判别器网络
本文判别器网络采用全局判别器和局部判别器网络两者相结合,两者协同工作来区分图像是来自真实数据分布还是由生成器生成.局部判别器也在其他一些论文中使用过,并且取得了良好的效果[15,16].
局部判别器主要识别缺失部分的结果是否正确,局部判别器的输入是原始丢失图像部分或者是被遮挡的部分,以及生成器的生成部分,局部判别器约束着图像的细节信息和局部一致性.而全局判别器需要判断整个图像的真实性,全局判别器的输入也分为两类:原始图像和由生成器生成的整个图像.判别器网络结构模型如图3所示.

图3 判别器网络模型结构
在判别器网络的体系结构中,全连接层都是标准的神经网络层.全局判别器和局部判别器处理完后,在判别器网络中通过一个连接层将两者的输出连接到一起,形成一个2048维度的矢量,再经过一个全连接层处理后得到一个连续的值.最后使用sigmoid函数作为转移函数,使该值的范围在[0,1]来表示图像是真实图像的概率.
判别器在评分过程中需要对真实图片x做出尽可能高的评分,对生成图像G(·)尽可能降低评分.因此将对判别器的损失函数进行优化见式(7)、式(8):
Lossglo=-logDglo(X,MB)+log(1-Dglo(G(X′,MG),MG)
(7)
Lossloc=-logDloc(x,MB)+log(1-Dloc(G(x′,MG),MG)
(8)
其中MB表示二值掩码,MG表示输入的图像,x′表示图像的缺失区域,Lossglo表示全局判别器的损失,Lossloc表示局部判别器的损失.
局部损失函数的主要作用是判断生成区域相对于原图像的区域相似度,使得生成区域的真实性更加接近原始图像,由于生成器部分亮度参数的存在导致生成的局部区域与原图像必然存在差异,因此需要全局判别器的来进行图像的整体判断.全局判别器需要判断包含掩码所在区域的全局图像的真实性,保障局部区域与全图的融洽性,进一步降低由于局部亮度差异而引起的误差.
3 实 验
3.1 实验环境
本实验运行在Ubuntu18.04 LTS操作系统,处理器为Intel®Xeno(R)CPU E5-2407,显卡为GeForce GTX TITAN X,运行内存16GB.实验使用pytorch 0.4.0框架,用python实现.
3.2 实验具体内容
在本文的实验中,关于实验中的部分数据搜集于Kaggle,数据包含人脸和一些水果的图片,其中人脸部分数据来自于CelebA数据集.训练使用的学习率是0.0002,上下文内容损失的权重λ是0.0001.
在训练开始之前为了保证实验的稳定性,需要对数据集图像进行统一预处理.本实验中通过预处理将实验图片处理为256×256×3的规格.此外为了使对图片的修复更加具有普遍性,在训练过程中,还需要对图像进行随机处理.即对于输入的图像,需要在图片主体部分随机生成一个需要修复的区域,并将该区域的大小限定在128像素之内.
3.3 实验结果分析
图4是根据本文算法获得的实验结果,对比最终的输出结果与原始图片,高光区域亮度有明显下降.

图4 部分实验结果
为了进一步评估图片的修复效果,本文引入峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)和结构相似性指标(structural similarity index,SSIM index)来评估图像修复质量,并对比了不同算法修复图像的耗时,来评估算法的工作效率.
峰值信噪比是一个表示信号最大可能功率和影响,是表示进度的破坏性噪声功率的比值的工程术语[17].结构相似性指标是一种用来衡量两张数位影像相似程度的真值表[18].本实验中使用峰值信噪比PSNR和结构相似性指标 SSIM两种数据作为图像修复的质量检测的指标.
PSNR一般使用均方误差(MSE)来进行定义.对于大小为m×n的两张单色图像I和k,如果I和k的噪声相似,那么可以将I和k的均方误差定义为式(9):
(9)
峰值信噪比定义为式(10):
(10)
其中MAXI表示像素点的颜色最大值,它由采样点的编码方式计算得来,当采样点使用N位线性脉冲编码调制表示时,MAXI的值为2N-1,,生活中的图像采样点通常用8位表示,MAXI的值为255.
结构相似性指标的范围在-1到1,该指标数值越大,则说明两张图片的相似度越高.对于给定的两个图片信号x和y,其结构相似性定义为式(11):
SSIM(x,y)=[l(x,y)]α[c(x,y)]β[s(x,y)]γ
(11)
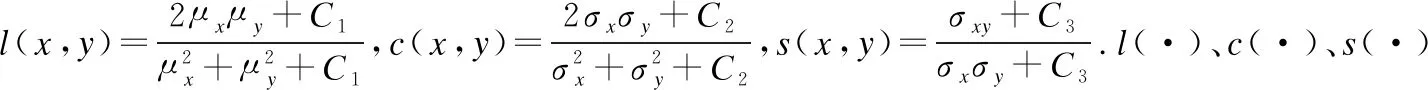
文献[5]中作者的主要目的是针对具有高光饱和现象的图片进行处理,其实现方法基本符合传统图像处理中先划分高光区域,再根据高光区域的邻域和边缘信息来修复高光部分的步骤.文献[19]根据WGAN网络来对图像进行修复,其主要面向对象是人脸修复.文献[20]的算法中仅仅使用了局部判别器而没有使用全局判别器,对于图像的修复效果并不稳定,容易出现模糊扭曲等现象,在纹理方面的修复效果较为微小.文献[21]的算法能在一定程度上修复图像的纹理,但是在某些场景下会出现不连续以及伪影的情况,修复效果不够稳定且图片质量不佳.本表格的数据通过使用以上4种修复方法得到的修复结果,再通过Scikit-image中的metrics库计算获得,其质量评价指标数据如表1所示.

表1 质量评价指标数据
分析表中的数据可以发现,相比于传统图像处理方法,使用生成对抗网络的方法都得到了显著的提高,特别是在结构相似性方面的提升尤为显著.本实验方法与其他生成对抗网络相比较,在PSNR方面平均提高了约23.41%,在SSIM方面提高了约19.49%,可以推断出本实验方法修复后的图像在视觉感受上明显优于其他3种方法.
除对PSNR和SSIM两个指标进行统计分析,表2中统计了文献[19]、文献[20]、文献[21]和本文算法在运行时处理单张图片所需要的平均时间.

表2 各算法消耗时间
分析表1和表2中的数据发现,文献[5]和文献[21]的处理时间相对较少,但是这两种算法的图像修复效果都不及本文的算法,运行时间较文献[21]减少了51.23%,并且本文算法的图片修复效果更加优秀.在图5的图像修复效果对比中恰好证实了本文算法的修复效果优于其他3种文献.
图5中的折线图表示,在不同大小的掩码下,本文算法的质量评估指标PSNR和SSIM的变化过程.随着掩码的增大,图像的修复质量有所下降,主要是因为,随着图片上的掩码区域扩大,图片上可供学习的区域越小,神经网络难以收集足够数据对进行良好的修复.当图片的掩码区域达到90(约占全图35%)时,图像PSNR值约为33,SSIM值约为0.953,对比其他文献,本文在PSNR方面提高约8%,SSIM提高约15%.可以推断出,本文在较大缺失区域的修复能力优于其他算法.

图5 PSNR和SSIM折线图
根据图6中不同算法的修复效果对比发现,在图片的纹理修复方面,本文有着极大的优越性,文献[19]和文献[20]对图片的修复能力较差,仅仅能恢复出少量的纹理,而且恢复的区域与原图像的契合度不高、过度不自然;文献[21]的纹理修复效果稍好一些,但是同样存在过度不自然的情况,本文算法在纹理方面的修复效果较前3种算法取得了极大的进步.

图6 图像修复结果对比
综合各种指标,经过大量的实验观察,本文在图像高光区域的修复效果良好,较传统的图像处理方法,本文的方法修复效果更加优秀,图片质量更高,不仅能有效降低高光区域的亮度,还能对部分图像纹理缺失的情况做出修复.此外在图像修复部分,与其他采用GAN的修复方法相比较,本文算法在运行时间上略微得到了提高,在图像质量方面,本文的修复质量更高,修复后的图像纹理更加清晰合理.
4 结 论
针对图像由于高光溢出导致的图像部分区域与纹理的缺失,提出了一种基于生成式对抗网络的图像高光修复方法.通过实验对比分析,本文方法较传统图像处理各方面都得到了极大的提高,尤其是图像质量方面,提高了约93%;对比神经网络的图像修复技术,本文修复效率提高了18.04%,修复质量提高了22.96%,综合以上信息可知,本文方法对图像高光修复做出了有效的改进.
但是这项研究任然带有一些局限性.首先本研究中提出的算法主要用于图像高光修复,对图像的高光区域有比较好的修复效果,但是由于本文没有对人脸关键标识性区域修复做出针对性训练,对于人脸关键位置的修复效果不够理想,在以后的研究中将对这一部分做出改进,提高本文算法在其他方面的图像修复效果;另外,本研究中的水果数据集只包含了常见水果,未来希望能够获取更多其他类型的水果数据,提高本实验的兼容能力.
