医学图像配准的深度学习方法综述
2021-08-24莫晓盈尹梦晓石华榜
莫晓盈,杨 锋,2,尹梦晓,2,石华榜
1(广西大学 计算机与电子信息学院,南宁 530004)
2(广西多媒体通信与网络技术重点实验室,南宁 530004)
1 引 言
图像配准是图像处理的一个重要领域,配准指的是将两个或多个图像进行几何对齐,使源图像(移动图像)上的每一个点在目标图像(固定图像)上都有唯一的点与其对应,旨在寻找不同图像之间的空间变换关系,其目的是去除或者抑制待配准图像之间的几何不一致.图像配准是图像分析和处理的关键步骤,是图像融合、分析和目标识别的必要前提.
现代医学技术飞速发展,医学影像学可以用于筛查疾病和检测治疗效果,为疾病诊断做出了巨大贡献.常见的医学影像技术有:计算机断层扫描成像(CT)、磁共振成像(MR)、正电子发射断层成像(PET)等.每种医学影像技术都有其各自的优点与缺点,比如:MRI核磁共振图像对人体的软组织器官有极佳的成像效果,而且其图像质量很好、分辨率高.但是体内带有金属异物的患者不能接受核磁共振检查,而且核磁共振有检查扫描时间长、器官的周期性运动易造成伪影、价格昂贵的缺点.CT成像逼真、清晰,对于血管和骨头的造影效果非常好,可以用来突出解剖结构,将解剖结构与周围其他组织区分开来.但CT成像过程中需要暴露在X射线下,有致癌的风险.PET可以检测人体的代谢情况,但其分辨率低、采集时间长.这些医学影像是无法相互取代的,若能够结合他们的优点将会对诊断治疗工作提供很大的帮助,因此配准技术的出现至关重要.
配准技术可以提高检测治疗效果的效率,同时,该技术可以最大化地将不同模态或时间的医学图像融合,提高信息利用率和诊断的准确性.配准算法包括了变形模型、目标函数、优化算法3个组成部分.其中,配准算法的效果主要依赖于定义变形模型和目标函数.
传统的配准方法为一个迭代优化的过程:通过特征匹配将图像进行匹配变换,首先提取图像中的特征信息,然后选择空间变换方式,计算图像之间相似性,最后选择合适的优化方法不断迭代优化,使得配准后的图像相似性最高.若需要提高配准的准确度,首先要将图片的像素信息转换为更低维度的特征信息,然后再进行特征提取,因此特征提取尤为重要.常用的特征包括:角点、LPB、SURF、质心或模板[1].提取特征信息的方法中,有一部分使用了自动的特征提取方法,另外还有一部分是将手动描述特征与自动化特征提取相结合,通过手动或自动化提取图像中的明显结构特征.常见的空间变换模型有刚体变换、仿射变换、投影变换、弯曲变换等.相似性度量是衡量移动图像与固定图像间的相似程度,常见的相似性度量指标有:差值平方和(SSD)、绝对误差和(SAD)、归一化互相关(NCC)及互信息(MI)[2]等.
基于深度学习的方法大致可以分为两类:1)利用深度学习网络估计两幅图像的相似性度量,驱动迭代优化;2)直接利用深度回归网络预测变换参数.上面所描述的两类基于深度学习的方法中,第1类方法只利用了深度学习进行图像的相似性度量,仍然需要传统配准方法进行迭代优化,其计算要求高、迭代慢,只减轻了非凸导数的问题,在深度相似网络训练中,仍然难以获得对齐效果良好的图像对[3].因此本文将重点介绍第2类方法.
自从2012年AlexNet[4]在ImageNet挑战中大获成功以来,深度学习开始被广泛地应用到计算机视觉研究与应用中.机器学习具有自组织、自学习和自适应性和很强的非线性特性[5].同时,处理速度与内存容量的提升为高强度配准方法提供了计算环境,GPU大大提升了基于深度学习的配准算法的计算速度.传统的配准方法可能会存在需要手动配准的缺点,虽然已经开发出了很多自动配准的方法,但目前传统的配准方法在处理速度和效果上有待提升.由于可以克服一些传统的配准方法存在的缺点,同时提高配准的准确度与效率,基于深度学习的配准方法具有广大的发展前景与提升空间.
目前2D-2D的图像配准已逐渐不能够满足临床诊断的需求,而3D-3D图像的配准通常需要大量计算,运用于3D图像上的配准对于准确度和效率要求都很高,因此人们提出了很多方法来解决这些问题,比如:Demons[6]、ELASTIX[7]、微分同胚、基于样条的方法等.但是传统配准方法仍存在一些局限性,比如:适用范围较窄、可能只适用于某一些特定模态的图像.深度学习可以充分利用各种海量数据,包括标注数据、弱标签数据或者仅仅使用数据本身,自动地学习到抽象的知识表达[8].有许多研究团队致力于提升单模态医学图像的配准效率与准确度,但是单一模态的医学影像为诊断提供的信息是有限的,而多模图像配准有利于反映病变区域空间位置的对应关系和综合评价病人病理特性,在疾病诊断、手术规划、放射治疗和疾病治疗跟踪等应用中都起到重要作用,可以提供更全面、互补的信息.因此深度学习的方法逐渐影响着医学图像配准这一研究领域,人们开始尝试着提升基于深度学习的图像配准精度,其准确度已经能够与传统配准方法媲美,并且引入深度学习用于研究多模态医学影像的配准问题.
本文的目的在于阐述基于深度学习的医学图像配准领域发展现状,同时讨论目前为止所遇到的问题与挑战.在对基于深度学习的医学图像配准进行讨论之前,介绍一下文章的结构:首先阐述配准的定义与基于深度学习的配准方法存在的必要性.然后介绍有监督变换估计、无监督变换估计和使用生成对抗网络的3类配准方法目前的部分科研成果与发展现状,并介绍配准常用的数据集、评价指标,基于相同数据集对几种配准方法进行效果分析与对比.最后对配准领域的发展趋势进行讨论并对本文进行总结.
2 基于深度学习的配准方法
如引言所介绍的那样,基于深度学习的方法大致可以分为两类:第1类是利用深度学习网络估计两幅图像的相似性度量,驱动迭代优化;第2类是直接利用深度回归网络预测变换参数,本文主要介绍第2类方法.下面将分别介绍3种基于深度学习的医学图像配准方法:监督变换估计、无监督变换估计和配准中使用生成对抗网络的方法.
2.1 监督变换估计
基于监督变换估计的配准,就是在训练学习网络时需要提供与待配准图像对应的标准标签数据.常见方法是以两幅图像对应坐标为中心点进行切块,将图像块输入深度学习网络(通常为卷积神经网络),输出图像块中心点对应的形变向量.获取标准标签数据有两种方式:1)是利用传统的经典配准方法进行配准,得到的变形场作为标签;2)是对原始图像进行模拟变形,将原始图像作为固定图像,变形图像作为移动图像,图像对的模拟变形场即为标签.
若已经知晓需要得到的输出结果,即拥有了已经标记好的数据集,那么就称该神经网络的学习过程是被监督的.弱监督的配准方法使用标准标签数据和一些其他的相似性度量指标来训练模型,双重监督则意味着网络同时使用监督和无监督损失函数进行训练.
变换估计方法为配准研究提供了新的思考方向,让配准从传统走向深度学习,在机器飞速发展的条件下能够更好地将计算机资源利用起来.基于监督的方法还是存在一定的缺点,这种方法需要大量已经被标注好的图像用于训练,虽然弱监督和双重监督的方法能够一定程度上减轻对于标签数据的需求,但是它们仍然无法摆脱对标签数据的需求.从另一个方面来说,拥有标签数据为实验提供了可参考的标准结果,有益于后期进行实验效果的比较.
下面将分别介绍配准研究中已经实现的基于完全监督估计、弱监督估计和双重监督估计的配准方法.
2.1.1 完全监督估计
常见的有监督配准方法的基本流程如图1所示,首先将固定图像和移动图像输入网络中获得变换参数,根据标准标签数据与变换参数的差值获得损失值,然后将损失值反向传播至网络中迭代以获取更好的效果,最后得到效果良好的输出值.下面将介绍一些使用完全监督估计的配准方法,下文所提到的方法的概览如表1所示,表1展示了各个方法所适用的维度、变换形式、图像类型和部位.

表1 基于监督的配准方法概览
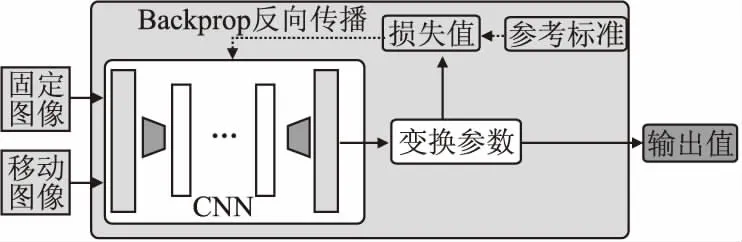
图1 监督配准方法框架图
Miao等人是第一个使用深度学习算法来预测图像的配准变换参数的团队.现有的配准方法局限性在于计算速度慢、捕获变形的范围小,针对这些局限性他们构造了一个5层的卷积神经网络(Convolutional Neural Network,CNN)结构,用CNN回归器直接估计变换参数,对3D的CT图像与2D的X射线脊柱图像进行刚性配准.该方法相较于部分传统的基于强度的配准方法来说,效果有显著的改善[9].后续的工作中[10],Miao等人提出了一个新的6层CNN网络结构,直接根据数字重建射线照片(DRR)和X射线图像来估计变换参数,该方法可以使用少量的DRR渲染实现精确的2D/3D配准,具有很高的计算效率,更适用于实时配准.
Cao等人使用了一个9层的CNN模型[11],将CNN模型以逐块方式设计,对块的外观信息和局部位移进行编码,从不同图像的相同位置提取两个补丁,然后使用CNN产生的位移向量对齐两个补丁,这些位移向量的总和构成了密集变形场(Dense Deformation Field,DDF),即图像的变形场,DDF被用于配准3D的脑部MR图像.据他们称,这个方法的效果优于SyN[12]和Demons[6].除此之外,Cao等人使用了一种基于深度回归网络的方法来预测图像之间的变形场[13],并提出使用局部相似度图(similarity maps)提高基于深度学习网络模型的准确性、鲁棒性和泛化能力.
Salehi等人旨在实现实时的3D胎儿脑部MR图像的刚性配准,并提高配准的变形捕获范围[14].Salehi等人使用图像特征来预测3D旋转和平移的角轴值,他们将图像随机旋转,然后将其与原图像之间的形变用于训练网络,将测地距离与均方误差值(Mean squared error,MSE)用于计算损失函数.
Uzunova等人使用了FlowNet框架[15],同时使用了3种方法用于生成标准标签数据[16]:仿随机生成、仿射配准生成和统计外观模型(SAM)生成变换,然后利用合成变形场对脑部和心脏的2D MR图像进行配准.Uzunova等人的文章表明,这3种方法中,基于SAM生成的标准标签数据进行的CNN的学习和训练效果是最好的.
相似地,Sentker等人也使用了生成标准标签数据的方法来进行配准[17].有一部分学者利用传统的配准方法对图像对进行配准,然后生成标准标签,比如Sentker等人利用DIR生成的变形向量场(Deformable vector field,DVF)作为标准标签,将预测值与标准标签之间的均方误差值作为损失函数,用于配准肺部的3D CT图像.
Eppenhhof等人针对肺部的配准问题,也提出了一种基于CNN的方法[18]估计3D图像的非线性配准中的配准误差.此外,Eppenhhof等人对U-Net架构[19]进行改造,并使用训练图像的合成几何变换来训练网络,对肺部的3D CT的可变形图像进行配准[20].
多尺度随机变换减少了对于手动标注的标准标签数据的需求,可以在训练网络中以较少的数据获得良好的性能.这个方法的提出也进一步证实了使用深度学习进行直接变换预测的可能性.在后续的工作中,Eppenhhof等人提出使用逐步训练神经网络来解决[20]中无法估计复杂变形场中较大位移的问题.他们提出,先在低分辨率上训练较小的网络,再在高分辨上训练较大的网络,这样的做法可以有效解决大型网络不敏感的问题,同时可以有效地提高配准精度[21].
2.1.2 弱/双重监督估计
双重监督通常是指使用标准标签数据和一些图像相似性度量共同产生的损失函数对网络进行训练,双重监督可以减轻对标准标签的依赖性.弱监督通常指的是在训练数据集中提供精确输出以外的标准标签数据值并用于计算损失函数.弱监督方法是用于多模式图像配准的无监督方法的变体,对网络进行训练以优化一个辅助任务,但该辅助任务不会受到模态差异的影响.
Hu等人利用标签相似性替代图像相似性用于训练网络,他们构建了一个30层的全卷积神经网络(FCN)[22]网络,对前列腺的MR-TRUS图像进行配准.在训练中通过输出密集变形场(DDF)来优化卷积神经网络,变形场会扭曲来自移动图像的一组可用的解剖学标签,以匹配固定图像中的相应解剖标签[23].在后续工作中,Hu等人提出从解剖标签中包含的更高级别的对应信息中推断体素级别的转换,并介绍了一个框架,该框架使用解剖标签和完整的图像体素强度作为训练数据,旨在实现全自动的、可变形的图像配准[24].
Fan等人将监督与无监督损失相结合,利用双重监督来预测脑部的3D MR配准的变形场.Fan等人使用了分层双监督的FCN[22]来解决缺少标准标签数据的问题[25].该网络使用了标准标签数据和图像相似性度量两种监督方式,同时在网络的每一层中都加入一个损失函数,使得一些层更容易收敛.同时,在U-net[19]框架基础上使用间隙填充,提出了一个网络架构“BIRNet”,将预测变换与标准标签数据变换之间的均方误差(MSE)作为损失函数,并使用预先配准的标准标签数据和图像相似性来训练网络.
Cao等人使用了MR-MR损失和CT-CT损失两种损失来进行双重监督配准[26],即他们使用了同模态内的图像相似性来进行监督配准.Cao等人提出在测试阶段根据输入的CT和MR图像直接预测变换场.他们通过预对齐图像,将多模态配准转换为单模态配准,用于MR-CT配准.他们使用标准标签数据与预测变换扭曲待配准图像之间的归一化互相关(Normalized cross-correlation,NCC)作为损失函数.相似地,Liu等人也使用监督合成变换和非监督描述图像相似性进行训练[27].
与Liu等人使用全局语义的方法相似,Hering等人结合全局语义信息(带分割标签的监督学习)和从经典医学图像配准中获得的支持局部结构对齐的局部距离度量的互补优势,构造了基于标签和相似性度量的损失函数[28],通过2D造影MR图像的可变形配准对心脏运动进行追踪.据他们称,该方法的效果优于一些多级配准方法的效果.
2.2 无监督变换估计
相较于监督学习,基于无监督学习的配准方法就是在训练学习网络时,只需要提供配准对,不需要标准标签数据(即真实的变形场).因此,该类方法在训练与测试阶段,均不需要依靠传统的配准方法进行辅助.以二维图像配准为例,无监督配准方法的流程如图2所示,下文所提到的方法的概览如表2所示.

表2 基于无监督的配准方法概览

图2 无监督配准方法框架图
无监督变换预测目前为主有两种常见的方法:第一种是基于相似性度量的无监督变换估计,通常使用图像的相似性度量与常见的正则化策略来定义损失函数[29].第二种是不需要标准标签数据的、基于特征的无监督变换估计.
通常,基于非监督学习的配准将配准对输入网络,获得变形场,对移动图像进行变形插值,即得配准图像.三维图像与之类似,将三维图像输入网络,获得变形场,再插值得到配准图像.无监督变换预测的难点在于:若缺少具有已知转换的训练数据集和标准标签数据变换,难以定义网络的损失函数.然而2015年Jaderberg等人提出了空间变压器网络(STN)[30],STN在训练过程中可以进行图像相似性的损失计算,而且它可以插入到现有的CNN框架中.STN的提出启发了众多研究者们对于无监督变换预测的新思路:使用无监督变换预测网络获得密集变形场,然后使用STN生成扭曲图像,将其与固定图像进行比较,用于计算图像相似性损失.
de Vos等人提出了一个无监督的图像配准框架“DLIR”[31],该框架利用固定图像和移动图像之间的相似性来训练网络,通过优化神经网络来间接优化变换参数,预测的变换参数用于构建密集位移矢量场.在另一项工作中,de Vos等人提出了可用于可变形图像配准的深度学习网络“DIRNet”[32].DIRNet由卷积神经网络回归器、空间变换器和重采样器组成,通过直接优化固定图像和移动图像之间的相似性来学习配准图像,从而实现心脏MR图像的配准.
Li等人也利用了图像相似性进行配准,他们通过最大化固定和移动图像之间的图像相似度来直接估计图像对之间的空间变换[33,34].Li等人通过对FCN[22]架构进行改造和采用多分辨率策略,优化、学习不同分辨率下的空间变化,并将使用移动图像与固定图像之间的NCC和其他的一些正则项构造该方法的损失函数.
相似地,Yoo等人[35]提出将卷积自动编码器(CAE)和STN[30]相结合,计算得到了图像对之间基于特征的相似性,利用自动编码器(CAE)以无监督的方式训练网络,实现对神经组织电子显微镜(ssEM)图像的无监督变换估计.
Krebs等人提出了一种无监督学习的可变形配准算法[36],该方法使用了随机潜在空间学习方法,这一做法不需要进行空间正则化,与Yoo等人[35]引入自动编码器(CAE)的做法相比,Krebs等人通过使用条件变分自动编码器(cVAE),生成网络对移动图像的编码器和解码器进行约束,同时引入求幂层来制造微分同胚变形,对3D脑部和心脏MR图像进行可变形的无监督配准.
Balakrishnan等人设计了一个配准框架“VoxelMorph”[37,38],该配准框架由一个配准网络与一个分割网络组成,框架由U-Net[19]改造而成.该框架的损失函数由图像相似性与分割值的重合度组成,分割结果在一定程度上能够帮助提高配准的准确度.该网络是一个无监督图像配准的通用框架,不需要标准标签数据或其他监督信息,适用于单模态或多模态的图像配准.他们将配准公式化为一个函数,该函数将输入图像对映射到对齐这些图像的变形场,通过卷积神经网络对函数进行参数化,并在一组图像上优化神经网络的参数.每当提供一对新的图像时,VoxelMorph将通过直接评估函数快速计算变形场.Balakrishnan等人称VoxelMorph模型性能与ANTs[12]方法的性能相当,而且只需要更少的计算时间.在后续的工作中,Dalca等人利用微分同胚来预测变形,将MSE用作相似性度量并与正则项相结合来构造损失函数,用于对脑部MR图像的无监督配准[39].
Kuang等人受STN[30]方法的启发提出了一种无监督配准方法“FAIM”[40],该方法利用CNN和STN对脑部MR进行可变形配准,并使用NCC和正则项构造损失函数.与基于U-net[19]结构的配准网络相比,比如Balakrishnan等人提出的VoxelMorph[37,38],Kuang等人提出的FAIM需要训练的参数更少,获得的配准精度更高.
Ferrante等人使用了类似U-Net[19]的网络结构和STN[30]执行特征提取和变换估计,将NCC用于构造损失函数,利用基于迁移学习的方法对骨头和心脏造影的X射线、MR图像进行可变形配准[41].
Zhang等人基于FCN[22]提出了一个新的网络结构——网络逆一致深度网络(ICNet)[42],以用于解决不同模态间的非刚性图像配准问题.该方法引入了反一致和反折叠约束,促使一对图像朝着彼此对称变形,直到两个变形图像匹配为止.逆向一致的深度网络(ICNet)[43]可以对脑部MR图像的DIR进行端到端的DVF预测.Zhang等人不仅使用了常规的平滑度约束,还提出了一种抗折叠约束,以进一步避免变换中的折叠.Zhang等人的方法效果优于基于SyN的方法[12]和基于Demons[6]的方法.类似地,Kim等人提出利用循环一致性训练CNN来对3D体积的可变形配准[44],利用周期一致的损失来实施DVF正则化.
Ghosal等人基于FCN[22]构建了一个无监督可变形配准框架,最小化移动图像和固定图像的平方差总和的上限(upper bound to the sum of squared differences UB-SSD),并将该方法称为“DDR”[45],用于配准脑部的MR图像.
Jiang等人提出了一个用于肺部CT图像的可变形配准的模型[46],该模型整合了3个CNN,网络通过使用图像补丁来优化图像相似性损失和减小变形场的平滑度损失.与基于完全监督的Liu等人[27]提出的方法相比,Liu等人摒弃了补丁的做法而使用了全局语义,Liu等人将来自不同模态的图像映射到公共表示空间,以促进模态之间的语义比较,然后对通过对特征图的不确定估计发现感兴趣的区域,通过在该架构中集成可微分的几何约束完成传统的匹配步骤.
2.3 基于生成对抗网络的配准方法
配准中使用生成对抗网络(Generative Adversarial Networks,GAN)的方法一般可以分为两种:提供预测变换的额外正化或执行跨域图像映射.目前常见的方法是:通过引入基于网络的损失来训练对抗网络,训练鉴别器区分输入类型,区分该变换是预测还是真实标签、图像是真实还是由预测变换扭曲的图像、图像对齐是正对齐还是负对齐.
常见的基于生成对抗网络的配准方法流程如图3所示,基于生成对抗网络的配准方法概览如表3所示.

图3 基于生成对抗网络的图像配准框架图

表3 基于生成对抗网络的配准方法概览
Yan等人提出了使用GAN对3D的前列腺的MR和TRUS图像进行刚性配准的配准方法“AIR-net”[47],Yan等人借鉴了Arjovsky等人改进的Wasserstein GAN(WGAN)版本[48],鉴别器用来识别图像是使用标准标签数据进行变换对齐还是预测对齐,生成器用来估计刚性配准.Yan等人提出的方法不仅提供配准估计器,同时提供质量评估器,质量评估器可用于质量检查以检测潜在的配准失败.
Hu等人使用传统的配准方法生成一个局部的变形场,然后构建一个GAN框架来实现MR-TRUS图像的局部变形的正则化[49].Hu等人用对抗性损失替代了平滑性损失,在损失函数中添加了预测变形场的L2范数,最大化标签相似性、最小化对抗性损失项,最大程度地提高促使图像对齐的解剖标签之间的相似性,减少对抗生成器的损失,以测量预测变形与模拟变形之间的差异.
Fu等人提出了一种无监督的3D肺部CT图像的配准方法“LungRegNet”[50],由两个子网“CoarseNet”和“FineNet”组成.两个网络均包含一个生成器和一个鉴别器,生成器可以直接预测变形场使移动图像变形,鉴别器可以区分变形的图像与原始的图像.使用CoarseNet训练可以使移动图像变形,然后将变形后的图像用于FineNet训练.CoarseNet在粗略图像上预测较大的肺部运动,FineNet在细度图像上预测局部的肺部运动.
Fan等人使用GAN对3D脑部MR图像进行无监督的可变形配准[51].鉴别器鉴别一对图像是否足够相似,其结果反馈用于训练配准网络.其他的GAN网络大多用于确保预测变形真实,Fan等人提出的配准方法不需要真实的形变或预定义的相似性度量,而是基于判别网络自动地学习相似性度量.
Mahapatra等人使用了GAN和cycleGAN[52]进行图像的合成和转换,损失函数中增加了结构相似性指数度量(Structural Similarity,SSIM)损失和特征感知损失项[53].在另一项工作中,Mahapatra等人提出使用GAN同时分割和配准胸部X光图像,用归一化互信息(Normalized Mutual Information,NMI)、SSIM和特征感知损失项训练生成器,用3个鉴别器来评估生成的变形场、变形图像和分割图像的质量[54].
Lei等人利用无监督的CNN实现了3D的腹部CT图像配准[55],他们提取多尺度运动功能来预测变形场,为变形场正则化提供额外的对抗性损耗,并通过鉴别器来判断扭曲的图像是否足够逼真.
3 配准数据集、指标与方法效果比较分析
本章节将介绍配准领域常见的数据集、目前主流的评价指标,通过对相同数据集的不同方法的实验结果来分析目前配准方法的特点.
3.1 主要数据集
目前用于医学图像处理领域的数据集很多,较常见的数据集有 DIRLAB、LPBA40、Sunnybrook cardiac cine(SCD)、ADNI、OASIS、POPI、NIH和LUNA16等,下面将简单介绍DIRLAB、LPBA40、SCD、ADNI和OASIS这5个数据集.
DIRLAB数据集是由得克萨斯大学M.D.Anderson癌症中心获得的10幅胸部4D-CT图像组成的,其中包括5名无疾病和5名胸椎恶性肿瘤患者的4D-CT扫描序列数据集,包括了患者的4D CT图像,其中4D-CT图像又包含5个3D-CT图像,包括了从吸气结束到呼气结束的完整呼吸循环.
LONI概率脑图集(又称作LPBA40数据集)[56]是由40位志愿者的全头部MRI图像和大脑中56个结构的手动标记轮廓线组成,大部分结构位于皮质层内.
Sunnybrook心脏数据(SCD)也被称为2009心脏MR左心室分割挑战数据,由45个电影MRI图像组成,其中包括了4种病例类别:健康、肥大、心力衰竭与梗死,心力衰竭但未梗死.该数据集分为训练集、验证集和评估集,每组都包含了15个扫描件,且病理类别均等,同时为使用者提供手动分割的左心室舒张末期(ED)和收缩末期(ES)体积用于评价.该数据集首次被用于MICCAI研讨会于2009年举办的心肌MRI自动分割挑战赛中.
ADNI数据集包括了临床数据(Clinical Data)、MRI数据(MR Image Data)、PET图像数据(PET Image Data)、遗传数据(Genetic Data),生物样本数据(Biospecimen Data)以及标准化MRI成像数据集(Standardized MRI Data Sets).ADNI包括4个子集:ADNI-1、ADNI-GO、ADNI-2和ADNI-3.
ADNI-1的建立是为了开发生物标记作为临床试验的结果指标.ADNI-GO的建立是为了检查疾病早期阶段的生物标记,为此招募了200名阿尔茨海默氏病症状轻微患者进行研究,同时还对来自ADNI-1的约500名受试者继续进行研究.ADNI-2旨在确定阿尔茨海默氏病的临床、影像学、遗传和生化生物标志物特征之间的关系,开发生物标记作为认知发展的预测指标,除了继续提取ADNI之前的700名受试者这5年的DNA与RNA进行研究,还加入了500名受试者进行研究.ADNI-3大多用于在临床试验中使用tau PET和功能成像技术的研究.
OASIS是一个旨在免费提供脑补核磁共振数据集的项目,OASIS数据集至今已发布了3个版本,最新版本的OASIS-3包括了两个数据集:横截面数据集(OASIS-Cross-sectional(Marcus et al,2007))和纵向数据集(OASIS-Longitudinal(Marcus et al,2010)).OASIS-3数据集的受试者包括609名认知正常和489名处于认知衰退阶段的人,该数据集包括了2000多个MR图集和来自3个不同的示踪剂、超过1500个原始扫描图像的PET图像,其中许多MR图集都包括了使用FreeSurfer处理生成的分割文件[57].
3.2 评价指标与金标准
常见的性能评价指标有:鲁棒性[58]、精度、抗噪性等.鲁棒性(robustness)是指配准算法精确度的稳定性,也可以认为是算法的可靠性.精确度是指进行配准计算后得到的估计值与金标准之间的差异,差值越小说明配准效果越好.
金标准是用来衡量配准算法实验效果的重要依据,它可以评价配准方法是否达到临床需求以及方法的性能优劣.但是由于医学影像的成像条件是不同的,因此没有一个绝对正确的标准,即使是同一张图像,由不同医生进行手动注释也会存在差异.配准方法的效果与具体的实践方法息息相关关,对于配准算法,业界内尚无一致肯定的评价标准,这是由医学影像的模糊性和来源不一致所导致的.
现阶段许多基于深度学习的研究是直接利用深度回归网络预测变换参数,当进行监督变换估计时,其数据集大多为已经标记好的数据集,大部分实验会将该数据集上的标准标签数据定义为“金标准”.而无监督变换估计大多采用无标记的数据集,可以通过使用配准软件进行处理后或其他方法处理过的标签数据作为金标准.
目前,配准方法使用的评价指标有:目标配准误差(target registration error of landmarks,TRE)、DICE相似性系数(dice similarity coefficient,DSC,DICE)、HD95(Hausdorff_95)、雅可比行列式(Jacobian determinant)等,下面将简单介绍这几种常见指标的计算方法.
目标配准误差(target registration error of landmarks,TRE)指的是配准后基准点与相应点之间的距离,对于规则网格或均匀分布上固定的3D点,通常建议使用金标准的点和与之对应转换的点用于计算TRE值.
DICE相似性系数是一种集合相似度度量指标,通常用于计算两个样本的相似度,值的范围为(0,1),其值越趋于1时两个样本的重合度越高.假设有两个集合A和B,计算A与B的DICE相似性系数的方法为:DICE=2(A∩B)/(A+B).
Hausdorff距离是用于描述两组点集之间相似性程度的一种度量,假设有两个集合A={a1,a2,…,an}和B={b1,b2,…,bn},则双向Hausdorff距离的一般形式为:H(A,B)=max(h(A,B),h(B,A)),其中h(A,B)=max(a∈A)min(b∈B)||a-b||,h(B,A)与h(A,B)计算方式相同,由Hausdorff距离公式可以看出它可以度量两个点集之间的最大不匹配程度.HD95指标计算的是Hausdorff距离值乘以95%,目的是为了消除离群值的一个非常小的子集的影响.
一般在配准后会得到图像的变形场,即图像的每个像素的位移形变的场,简称为密集变形场(dense displacement vector field,DVF).以三维数据为例,假设DVF上存在点J(i,j,k),则雅可比行列式可以写为:
通过计算雅各比行列式的值可以判断该点是否发生折叠,从而量化DVF的质量、判断配准结果的优劣程度.
以上几种指标中,DICE相似系数用于评价配准方法效果的频率最高,DICE相似性系数对于内部比较敏感,而Hausdorff距离则对边界比较敏感.
3.3 效果比较与分析
下面,本节将针对相同的数据集对第3章提出的部分方法进行效果比较.
针对肺部配准问题提出新方法的Eppenhof等人[18,20]、sentker等人[17]、de Vos等人[32]、Fu等人[50]和Jiang等人[46]都使用了DIRLAB数据集对网络进行训练和测试,其中Eppenhof等人[18,20]和Sentker等人[17]使用的是有监督的配准方法,de Vos等人[32]和Jiang等人[46]使用的是无监督的配准方法,而Fu等人[50]使用的是基于生成对抗网络的方法.将上述的配准方法应用于公开提供的10个DIRLAB数据集,使用每个DIRLAB数据集提供的300个点对来评估方法的准确性,文献[50]与文献[59]实验对比部分,表4展示了上文描述的几种基于深度学习的配准方法在DIRLAB数据集上的目标配准误差值(TRE),同时展示了Heinrich等人提出的传统的配准方法[60]和ANTs方法[12]在DIRLAB数据集上的TRE值,单位均为毫米和秒.
从表4的数据可以看出:传统配准方法ANTs的TRE值为2.43±4.1,相较于ANTs来说,使用基于深度学习的配准方法中,Eppenhof等人[18,20]、Jiang等人[46]和Fu等人[50]提出的方法都达到、甚至超过了ANTs[12]方法的效果,但尚未能够与Heinrich等人提出的改良方法[60]媲美.从另一方面来说,基于深度学习的配准方法在处理速度上明显快于传统的配准方法.

表4 各方法在DIRLAB数据集的目标配准误差值概览表
目前不管是有监督配准方法还是无监督配准方法都逐渐达到、甚至超越了传统配准方法的性能.上述几种方法中,基于生成对抗网络的配准方法尤为亮眼,在计算速度和效果上取得了优异的成绩.
针对心脏图片的配准问题,Mahapatra等人[53]和de Vos等人[32]将Sunnybrook cardiac数据集平均分为15个训练扫描集、15个验证扫描集和15个测试扫描集用于训练和测试.下面将他们提出的配准方法与传统的Elastix[7]方法进行对比,这些方法在Dice、HD95和MAD指标上的表现情况如表5所示,时间表示配准一个测试图像对所需的时间,单位为秒.
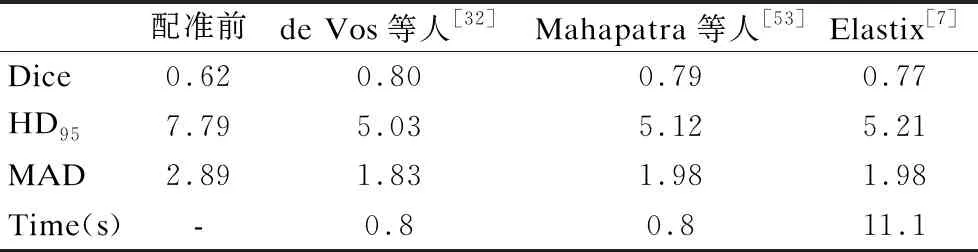
表5 心脏图像配准前后不同方法的平均性能比较
基于表5数据不难看出:相较于传统的配准方法来说,基于深度学习的配准方法运行时长上取得了非常明显的进步,在各项指标中也获得了不俗的成绩.De Vos等人[32]和Mahapatra等人[53]提出的方法不仅在Dice、HD95和MAD指标上逐渐达到传统方法Elastix[7]的效果,在运行时间上已经取得了很好的成绩,这充分说明了基于深度学习的配准方法的可行性与进步性.
在上述描述的比较中,虽然基于深度学习的方法取得了一定的效果,但是也暴露了配准领域现存的缺点——目前配准领域中尚未出现一个非常权威的、海量的数据库供各种配准方法使用,各种配准方法用于训练和测试使用的数据集参差不齐,用于评判配准方法的指标也尚未统一,针对不同的医学图像和不同的部位无法使用单一的指标来绝对衡量配准方法的效果.
4 未来发展趋势
基于深度学习的方法目前大多尚未在精度上优于传统的图像配准方法,但是由于基于深度学习的配准方法借助GPU进行直接估计,在计算成本和效率上,基于深度学习的方法比传统的配准方法要有优势得多.
由于基于深度学习的配准方法近几年的快速发展,使用直接变换预测的配准方法数量显著增多.有监督的配准方式存在一定的局限性:基于有监督的配准方法所生成的变换可能无法反映真正的生理运动、无法捕捉实际图像记录场景中的较大形变.
目前为止,有监督的配准方法受限于缺少手动标记的标准标签数据集,虽然双重监督和弱监督大大减缓了对于标准标签数据的限制,但是对于手动标记数据集的需求仍未降低.针对这一问题,目前大多有监督的配准方法采用了数据增强的方式扩充数据集,或使用迁移学习来解决这个问题.
与监督变换预测相比,无监督方法有效地缓解了缺乏训练数据集的问题,因此吸引了很多的学者的关注.但由于不同类别图像之间的相似性难以量化,无监督的配准方法在处理多模态配准问题上比处理单模态配准问题要难得多,所以目前无监督配准方法仍多用于处理单模配准问题,在处理多模态图像配准问题时趋于使用半监督的配准方法.
近些年来,许多研究者将GAN的鉴别器用来辨别图像对是否对齐,并使用GAN确保预测变换真实.同时,因为GAN不仅可用于引入额外的正则化,还可用于执行图像域转换,因此有的研究者使用GAN将多模态的配准问题转换为单模态的配准问题,基于GAN的配准研究方法也成为了热门研究方向.
目前基于深度学习方法进行配准是大势所趋,配准方法逐渐由部分依赖深度学习转向完全依赖深度学习,其性能和效果由逐渐达到传统配准方法的效果逐渐转为超越配准方法的效果.然而,对于配准方法的性能进行评判的标准还需进一步研究,不仅缺少包括具有代表性、专家标注的图像公共数据集,也缺乏一个业界统一的评估标准,但目前已有不少学者正在研究该问题,这一问题在未来有望得到解决.
