时间序列模型和LSTM模型在水质预测中的应用研究
2021-08-24胡衍坤姜秋俚
胡衍坤,王 宁,刘 枢,姜秋俚,张 楠
1(中国科学院大学,北京 100049)
2(中国科学院 沈阳计算技术研究所,沈阳 110168)
3(辽宁省生态环境监测中心,沈阳 110161)
4(阜新市生态环境保护服务中心,辽宁 阜新 123000)
1 引 言
河流为人类提供了赖以生存的水资源以及水产资源.工业化进程的不断加快,导致河流水环境受到严重破坏.由于河流水质变化与气候环境、季节更替以及人类活动密切相关,因此河流水质变化呈现出渐变性,非线性,和不确定性等特点[1].水质预测能够帮助我们更好地了解河流水质变化,从而更好的保护河流水资源.近年来,国内外很多专家学者已针对水质预测做了大量的研究,并取得了较好的成果.传统的水质预测模型主要包括时间序列模型、灰色系统理论模型、回归分析模型以及神经网络模型等.谢建辉等人[2]将ARIMA模型应用到对河流水质主要监测指标化学需氧量和氨氮的预测分析上,较为准确的反映了河流水质的变化趋势.赵林等人[3]使用BP神经网络模型对桃林口水库出库站7项水质指标进行预测,效果良好.此外,随着深度学习以及人工智能的快速发展,深度学习模型也越来越多的应用到水质预测研究中.涂吉昌等人[4]应用基于门控型循环神经网络(GRU)的水质预测模型进行水质预测,显著提高了水质预测精度.除单一模型外,组合模型也被应用到水质预测的研究.肖荣平等人[5]使用多算法组合的河流水质预测方法进行水质预测,结果表明,组合模型的预测精度显著提高,能够更好的适用于复杂水域的水质预测.
ARIMA模型是经典的时间序列预测方法,能够较好的体现时间序列数据中的线性特征.但是,单一的ARIMA模型对河流水质的非线性变化难以充分有效的处理,需要结合其他算法.在深度学习算法中,LSTM模型由于其特殊的网络结构,在处理时间序列问题时,比传统的神经网络更快更易收敛到最优解,非常适合处理河流水质指标这种时序数据[6].李艳萍等人[7]基于LSTM神经网络模型较为准确的预测了空气质量AQI指数.因此,本文建立了ARIMA与LSTM组合模型以及SARIMA与LSTM组合模型进行河流水质预测的研究,并结合实际河流监测数据,分析河流水质变化趋势.通过比较两种组合模型对河流水质预测的结果,探究更好的河流水质预测方法,从而更好的保护河流水环境.
2 研究方法
2.1 ARIMA和SARIMA模型
ARIMA模型全称为差分自回归移动平均模型(Autoregressive Integrated Moving Average Model,简记为ARIMA).其中AR是自回归,p为自回归项;MA为移动平均,q为移动平均项数;把非平稳的时间序列转化为平稳序列需要进行d阶差分[8].ARIMA模型的一般形式为:

(1)
该模型中包括自回归AR(p)和移动平均回归MA(q)两个过程.在上式中,γi(i=0,1,2,…,p)和θi(i=0,1,2,…,q)是待求参数,p为自回归过程的滞后阶数,q为移动平均过程的滞后阶数,μ为常数项系数,t为随机扰动项序列,通常要求为白噪声序列,表示为t~WN(0,σt2).ARIMA模型在建模时要求时间序列必须为平稳序列,对于非平稳时间序列数据要进行d阶差分后再进行建模.所以,完整的差分自回归移动平均过程ARIMA(p,d,q)在引入滞后因子后的模型表示为:
(2)
式(2)中L表示滞后因子,其定义为Lnyt=yt-n,(1-L)d为d阶差分运算.在建立ARIMA模型时首先要检测数据的平稳性,对于非平稳时间序列首先进行差分操作,从而确定d的值;然后根据自相关函数(ACF)和偏自相关函数(PACF)的截尾和拖尾性确定p值和q值;然后采用最小二乘法对参数进行估计;最后根据AIC、BIC、残差检验等方式确定最优的p、q值用于模型的训练.
SARIMA模型是在ARIMA模型的基础上添加了季节项,主要针对具有季节性或周期性变化的时间序列进行建模[9].SARIMA乘积模型的一般表达形式为:
SARIMA=(p,d,q)×(P,D,Q)s
(3)
式(3)中p为自回归阶数,q为移动平均阶数,d为差分阶数,P,Q,D分别为季节求和自回归移动平均模型中的自回归、移动平均回归和差分的值,s为季节周期和循环长度.在进行SARIMA建模时,首先进行差分操作,从而确定d和D的值;然后通过ACF来确定p和P的值,通过PACF来确定q和Q的值;然后采用平均法或者移动平均趋势剔除法对季节性时间序列数据进行分解,从而确定s的值;最后在得到所有参数后,使用参数估计模型进行模型校验,得到最终模型.
2.2 LSTM模型

图1 LSTM神经网络
LSTM模型在RNN的基础上添加了3个门控结构,分别为“遗忘门”,“输入门”和“输出门”[12].LSTM的第一步是确定将从节点状态中丢弃哪些信息,该判定由称为“遗忘门”的Sigmoid层决定.它查看ht-1和Xt,并为单元状态Ct-1中的每个数字输出0-1之间的数字,0代表“不允许任何量通过”,1代表“允许任何量通过”.Sigmoid函数的输出值决定前一个状态的值是否丢弃,表达式为:
ft=σ(Wf·[ht-1,xt]+bf)
(4)
下一步是确定我们将在单元节点状态中存储哪些信息,包含两个部分.“输入门”的sigmoid函数决定将更新哪些值,tanh函数创建可以添加到状态的新候选值C~t的向量(一个在-1与1之间的值)并与sigmoid函数的值相乘,最后输出确定要输出的那部分.其表达式为:
it=σ(Wi·[ht-1,xt]+bi)
(5)
(6)
最后我们需要通过“输出门层”来决定输出的内容.首先运行一个sigmoid层,它决定我们要输出的单元状态的哪些部分.然后将单元状态置于tanh(将值推到介于-1和1之间)并将其乘以sigmoid们的输出,最终得到将要输出的部分.其表达式为:
ot=σ(Wo·[ht-1,xt]+bo)
(7)
ht=ot*tanh(Ct)
(8)
2.3 组合预测模型
河流水质预测组合模型设计图如图2所示.

图2 组合模型
2.3.1 数据预处理
数据预处理过程主要处理原始数据中的缺失值以及异常值,首先对数据进行离群点检测,将异常值视为缺失值,从而使用拉格朗日插值法对缺失值进行填补.
处理措施:提前向海事部门申请《水上水下作业许可证》,并向港航局通航处申请发布关于“水上施工”的航行通告,及时将有关工程情况对相关单位进行宣传、报道,便于航运单位掌握信息,提高安全航行程度。加强同船闸管理处的联系与沟通,及时了解开闸通行、停运、高峰期等关键时间点,根据船闸管理处相关信息对钢板桩施工作业时间进行调整,尽量避免在船只通行时进行打桩作业。根据上下游船闸开放时间,尽量减少船只通行对施工造成的干扰,同时最大程度减少施工对通航的影响。在施工区域周围设置警示线,并在施工区靠航道一侧打设一排临时防护桩,将施工区域进行封闭。
水质监测数据具有线性特征以及非线性特征[13],将水质数据记为Zt,则可将其分解为线性部分Xt和非线性部分Yt,记为:
Zt=Xt+Yt
(9)
2.3.2 组合模型建模分析
1)时间序列模型建模

(10)
2)LSTM残差预测

3)模型组合
(11)
2.3.3 模型评价指标
本文对于ARIMA模型和SARIMA模型以及组合模型分别计算模型预测结果的均方误差(MSE)、均方根误差(RMSE)[14]和平均绝对百分比误差(MAPE),来量化模型预测的准确性.
MSE计算公式为:
(12)
RMSE计算公式为:
(13)
MAPE计算公式为:
(14)
其中pi为模型预测值,xi为训练集真实值,n为训练集个数.
3 实验分析
3.1 实验环境介绍
本次实验基于Windows操作系统,使用python语言进行编码,版本为python3.7,编程工具使用Jupyter Notebook,其中ARIMA与SARIMA模型使用statsmodels包实现,LSTM模型使用TensorFlow框架实现.
3.2 实验数据
实验水质数据来源于辽宁省阜新市细河高台子断面2013年1月-2020年3月监测数据,选取的污染物指标为化学需氧量(COD)和氨氮(NH3-N).取2013年1月-2018年12月数据作为模型的训练集,2019年1月-12月数据作为模型的测试集,2020年1月-3月数据作为模型预测的验证集.
3.3 ARIMA与LSTM组合模型建模实例
在ARIMA模型建模时,首先对时间序列训练数据进行ADF检测和白噪声检验,接下来绘制原始时间序列的自相关(ACF)图和偏自相关(PACF)图,观察可知模型p值为1,q值也为1.最后确定模型为ARIMA(1,0,1),进行模型训练、检验、评估及预测,得到ARIMA的拟合预测序列,然后使用原始数据减去拟合的预测数据得到ARIMA模型预测后的残差序列,并以滑动窗口的方式将残差序列切分成n段长度为t的序列,然后应用LSTM模型进行残差序列模型的训练和预测得到预测结果,最后将ARIMA模型预测结果与LSTM残差预测结果相加得到最终预测结果.结果如图3、图4所示.
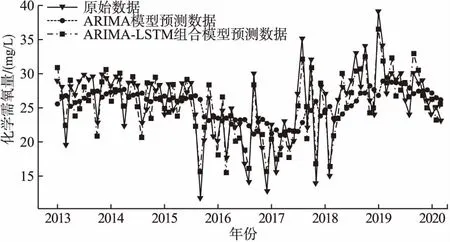
图3 ARIMA-LSTM模型预测结果

图4 ARIMA-LSTM模型预测结果
计算可得组合模型化学需氧量预测值均方误差和均方根误差分别为5.13和2.26,平均百分比误差为4.77%.氨氮预测值均方误差为0.14,均方根误差为0.19,平均百分比误差为5.26%,说明ARIMA和LSTM组合模型预测相较于单独使用ARIMA模型得到了很好的预测结果.
3.4 SARIMA与LSTM组合模型实例
在进行SARIMA建模时需要先提取时间序列数据中的趋势、季节和随机效应,从而判断残差序列的稳定性以及确定季节项系数.由ARIMA模型建模过程可知,原始化学需氧量和氨氮数据均为平稳数据;根据化学需氧量和氨氮数据自相关图和偏自相关可知,p值分别为1和2,q值都为1;根据从数据中提取的季节性可知,季节项系数都为12.通过网格搜索并依据AIC准则,可以得到化学需氧量序列SARIMA模型最优参数组合为SARIMA(1,0,1)×(1,0,1,12),氨氮序列SARIMA模型最优参数组合为SARIMA(2,0,1)×(2,0,1,12).进行SARIMA模型训练和预测得到预测值序列,并计算预测得到的残差序列,在此基础上继续建立SARIMA与LSTM组合模型进行预测,预测结果如图5、图6所示.

图5 SARIMA-LSTM模型预测结果

图6 SARIMA-LSTM模型预测结果
经计算可得SARIMA和LSTM组合模型对化学需氧量预测值的均方误差为3.17,均方根误差为1.37,平均百分比误差为2.81%,氨氮预测值的均方误差为0.10,均方根误差为0.13,平均百分比误差为3.16%.各模型预测结果对比如图7、图8和表1所示.

表1 各模型预测精度对比

图7 各模型预测结果对比

图8 各模型预测结果对比
综上可知,组合模型相较于单一时间序列模型在对河流水质指标中的化学需氧量和氨氮进行预测时的精度都有了明显提高.其中ARIMA和LSTM组合模型比ARIMA模型的预测精度提高了约7%,SARIMA和LSTM组合模型比SARIMA模型的预测精度提高了约6%,SARIMA和LSTM组合模型的预测精度比ARIMA和LSTM组合模型的预测精度提高了约2%.所以,经过试验分析,在本次试验数据集的基础上得到的河流水质预测最优模型为SARIMA和LSTM组合模型,该模型预测准确度较高,泛化能力强.
4 结 论
传统的时间序列模型ARIMA和SARIMA能够较好的体现时间序列数据中的线性特征,LSTM模型能够很好的处理时间序列数据中的非线性特征,本文在使用ARIMA模型和SARIMA模型建模的基础上提出了ARIMA和LSTM组合模型以及SARIMA和LSTM组合模型,并进行了实验分析.经过实验分析可知,组合模型对于河流水质指标中的化学需氧量和氨氮的预测精度优于单一时间序列模型的预测精度.SARIMA模型在ARIMA模型的基础上增加了季节项,由于考虑了季节性因素对河流水质变化的影响,SARIMA模型的预测精度优于ARIMA模型.SARIMA与LSTM组合模型的预测精度比ARIMA模型的预测精度提高了10%左右,能够较为准确的拟合以及预测河流水质参数指标,从而为保护河流水环境提供较为准确的参考依据.
