提高驾驶注意力的个性化训练方案生成方法
2021-08-11梁玮王钰廖章梁李湘媛
梁玮,王钰,廖章梁,李湘媛
(1.北京理工大学 计算机学院,北京 100081; 2.湖南省军区数据信息室,湖南,长沙 410011; 3.北京林业大学 艺术设计学院,北京 100083)
提 要: 驾驶注意力是影响驾驶安全性的重要因素之一,但驾驶注意力的训练由于存在高危险性很难开展. 针对此问题,本文提出了一种虚拟现实平台下的提高驾驶注意力的个性化训练方案生成方法,该方法借助虚拟现实头盔的眼动跟踪技术,采集用户的注意力习惯特性,针对用户的习惯特性,自动优化生成个性化驾驶训练方案. 在实验中,用户可以在已生成的训练方案中进行个性化驾驶注意力训练,并进行训练后的水平评估,通过对比训练前与训练后的效果评价本文提出的方法,实验结果表明,该方法可有效提升用户的驾驶注意力水平,并且优于传统训练方法.
驾驶注意力与驾驶安全之间有着密切的关联. 据世界卫生组织统计,每年有125万人在交通事故中死亡,其中有很大部分是由于驾驶人注意力不集中或者分心造成的,注意力分散已成为了继超速行驶和酒后驾车的第3大危险驾驶行为[1-2]. 缺失注意力的危险驾驶行为中,有些是由驾驶员的疲劳或外界因素干扰导致,还有部分是由于驾驶员的驾驶技巧不当而引起的,比如车辆右转弯时需看车前右侧区域是否有危险目标. LESTINA等[3]分析了1 396份警察事故分析报告,发现注意力不仅是引起交通事故的重要因素,并且新手司机比有经验的司机在注意力分散而导致的交通事故中的所占概率更高. 由驾驶技巧不当引起的注意力缺失可通过注意力训练得到提升,但驾驶注意力训练由于其危险性和复杂性等问题,一直未得到很好的解决. 传统驾校并未设置相关培训环节,多数驾驶员依靠考取驾照后在真实道路上积累经验提升该水平. 然而这个过程极易发生交通事故[4-5],此类驾驶员也经常被称作“马路杀手”. 因此分析驾驶注意力与驾驶安全之间的关系,针对影响驾驶安全的由驾驶技巧引起的注意力缺失问题,实现具有安全性、可行性、及时性的驾驶注意力水平的训练,对于提升驾驶安全有重要意义.
近年来,随着虚拟现实和智能优化技术的不断发展,仿真建模方法逐渐被应用,如Li等[6]使用仿真的建模方法来解决人与物体交互识别. 在驾驶方面,驾驶模拟器也应运而生,在多个方面得到广泛应用[7-9],虚拟驾驶训练也是其中一个重要领域[10-11]. 虚拟现实的沉浸式体验为驾驶训练提供了一个可行、安全的训练环境. 早期的研究工作中驾驶训练主要在基于桌面显示屏的模拟驾驶软件中进行,例如Gugerty等[12]使用基于桌面显示屏的模拟驾驶软件研究驾驶者对危险车辆位置的意识.
现在,驾驶模拟器的发展使驾驶训练能够利用驾驶模拟器提升驾驶水平. 如Crundall等[13]使用驾驶模拟器对在包含9种危险事件的虚拟路线上模拟驾驶的学习者进行驾驶能力评估. 此外,个性化训练也被广泛的应用到驾驶训练中,并被证明具有更明显的训练效果. Cao等[14]提出了一种基于智能教练头像的一对一虚拟驾驶训练系统. 孙博华等[15]提出一种驾驶能力评价方法,为评估驾驶注意力水平提供了参考;Lang等[16]提出了个性化的驾驶习惯纠正的训练方案生成方法,该方法利用虚拟现实头盔评估用户的驾驶习惯,利用驾驶习惯的评估结果引导训练路线的优化生成,以体现路径的个性化,为虚拟驾驶训练提供了新的思路. 但这些方法未涉及驾驶注意力相关的训练内容.
基于对虚拟驾驶训练及驾驶注意力训练现有工作的总结,本文提出了一种个性化的驾驶注意力训练生成方法. 该方法在虚拟环境中设置危险交通事件,如在路口突然出现异常驾驶车辆,通过获取个体注意力数据评估个体在危险事件中的驾驶注意力水平. 在搭建虚拟场景的基础上,系统框架分为三部分,包括:个体驾驶注意力获取、训练方案生成和个性化驾驶注意力训练,如图1所示. 用户在设置好的虚拟场景中首先进行虚拟驾驶,驾驶过程中个体驾驶注意力数据将被记录与分析,系统将根据记录的个体驾驶注意力数据计算可代表用户的注意力水平的分数. 此分数作为训练方案生成模块的输入,输入到路径优化算法中,通过优化算法生成针对不同个体的最优路径,形成个性化虚拟驾驶注意力训练方案. 最终用户在优化生成的个性化训练路径中进行个性化虚拟驾驶注意力训练. 此方法不仅有效降低了真实环境中注意力训练的危险性,提出了可行的训练方案,并可通过分析不同用户的驾驶注意力特点自动生成最优个性化训练方案. 经实验证明,本文的方法相较于传统的训练方法效果更好.

图1 虚拟驾驶的个性化注意力训练方法的框架图Fig.1 Framework of personalized attention training method for virtual driving
1 场 景
为了渲染出的更逼真的驾驶场景,本文使用Unity 3D游戏引擎进行场景搭建和交通事件的模拟仿真. Unity 3D 具有可跨平台的优点,可以渲染出接近照片级真实感的图像,并且内置了英伟达的PhysX物理引擎,可以有效地模拟出逼真的刚体碰撞、车辆驾驶等物理效果,使搭建的场景互动更贴近于现实. 本文构建的场景包括静态场景和动态场景两部分.
1.1 静态场景
静态场景主要给用户提供一个沉浸式的驾驶环境,更贴近真实的驾驶场景. 本文收集了多种驾驶场景元素,包括城市建筑物、城市道路、交通标志、多种类型的车辆、绿色植被、交通信号灯、路障、行人等. 系统使用建筑物、道路、植被、交通信号灯4种元素搭建出静态场景. 搭建好的场景概况如图2所示,图2(a)为场景概况,图2(b)为搭建场景元素示例.

图2 静态场景概况Fig.2 Static scene overview
1.2 动态场景
动态场景主要包括用户车辆、事件车辆、行人、交通标志等交通事件元素. 目标事件指的是为获取和评估个体驾驶注意力水平所设置的特定事件. 例如,当一辆车从交叉路口驶出,可能与主车辆发生碰撞. 用户需在驾驶中注视到目标车辆,避免碰撞. 动态场景使用C#语言编写的脚本控制主车辆的行驶,使用itween插件控制目标事件的行动路线.
为更好地评估个体驾驶注意力水平,根据日常驾驶注意力事件的观察总结,抽象出了六类目标事件:规则行驶车辆、异常行驶车辆、规则行走行人、异常行走行人、限速标志、交通信号灯,如表1所示. 现按元素具体描述六类目标事件在场景中的设置情况.

表1 六类目标事件的描述
1) 事件车辆. 带有触发器的目标车辆. 事件车辆分为规则行驶与异常行驶两类. 规则行驶车辆主要设置为在道路上直行或在交通路口停止的车辆,在事件车辆后方30~10 m处设置安全触发区域,当用户车辆驶入安全触发区域内,事件车辆的触发器将被触发,用户注视射线将被记录,在此区域内事件车辆被用户注视视为注视成功,如图3(a)所示. 异常行驶车辆主要设置为在路口处不按规则行驶的情形,在交通路口前30 m~前10 m设置安全触发区域,触发方式同理,如图3(b)所示.

图3 目标车辆设置情况Fig.3 Target vehicle setting
2) 事件行人. 带有触发器的目标行人即为用户的事件行人. 事件行人分为规则行走与异常行走两类. 规则行走行人设置为在交通路口沿人行路正常行走的情形,在交通路口前30 m~前10 m设置安全触发区域,当用户车辆驶入安全触发区域内,事件行人的触发器将被触发,用户注视射线将被记录,在此区域内事件行人被用户注视视为注视成功,如图4(a)所示. 异常行驶行人设置为在道路上横穿马路的情形,在主车辆驶近事件行人前30 m~前10 m设置安全触发区域,触发方式同理,如图4(b)所示.
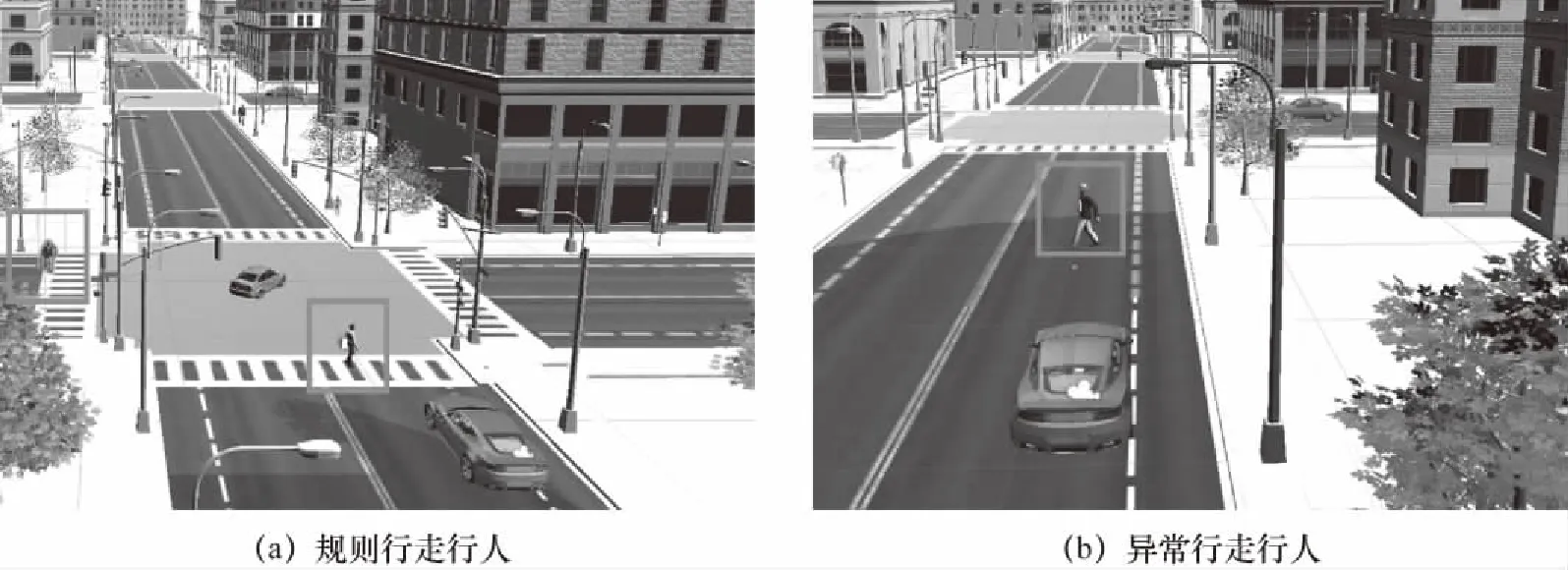
图4 目标行人设置情况Fig.4 Target pedestrian setting
3) 交通信号灯与限速标志. 交通信号灯均设置在交通路口,在交通路口前30 m~前10 m设置安全触发区域,当用户车辆驶入安全触发区域内,用户注视射线将被记录,在此区域内交通信号灯被用户注视视为注视成功,如图5(a)所示. 限速志设置在用户车辆行驶车道的右侧道路旁,在驶进限速标志前30 m~前10 m设置触发区域,当用户车辆驶入安全触发区域内,用户注视射线将被记录,在此区域内限速标志被用户注视视为注视成功,如图5(b)所示.

图5 静态目标设置情况Fig.5 Static target setting
2 个体驾驶注意力获取
2.1 个体驾驶注意力数据获取
系统使用虚拟现实眼球跟踪头盔FOVE获取个体驾驶注意力数据. 用户佩戴头盔,系统通过头盔实时跟踪获取用户驾驶主车辆模拟器的个体注意力数据. 首先设置FOVE眼球跟踪头盔插件参数,并将插件模块嵌入虚拟场景得到眼球位置与场景坐标的关联,眼球的落点在虚拟场景中被可视化为一对双色球. 如图6(a)中所示,图中框内双色球是用户此刻视线,右边代表用户右眼瞳孔视线,左边代表左眼瞳孔视线. 再使用触发器原理,在场景的目标事件中嵌入触发器,通过设置触发器与FOVE功能脚本,使眼球视线在通过特定触发器时触发脚本自动记录并有所提示. 当用户驾驶模拟器的过程中,触发目标事件发生,系统将检测用户是否成功注视目标事件区域,若用户成功注视目标事件区域,目标事件的触发器将会触发光源,提示用户已看到该目标,并将记录保存. 如图6(b)所示,图中框图内的行人被用户成功注视,该目标区域被触发光源.

图6 注意力数据获取方式Fig.6 Attention data acquisition method
由于,触发器捕捉射线的前提是感知眼球视线坐标,而触发器收取坐标的范围有限,所以眼球跟踪头盔对眼球视线跟踪的准确性会在一定程度上影响数据的有效性. 随着虚拟现实眼球跟踪头盔眼球跟踪精度的进一步精细,个体驾驶注意力的获取会更为精确和敏感,这也是本方法未来的潜在价值.
2.2 个体驾驶注意力评估方法
本文定义了6种如表1所示的目标事件,将每一项事件被成功注视的次数与固定路径下该项事件的总数量的比值作为驾驶注意力的评定标准,由pi表示,取值为[0~1]的连续值,i为事件序号,见表1.pi越大,表明个体在第i项方面的驾驶注意力水平越高.
(1)
式中:pi为用户成功注视此项事件的次数与固定路径下该项事件的总数的比;mi表示第i项目标事件在固定路径下成功被注视的数量;Mi表示第i项目标事件在固定路径下的总数.
3 训练方案生成
本文训练方案由系统针对不同个体驾驶注意力水平特点自动生成,方案最终形式为一条最优路径. 该路径下有符合个体注意力训练的最佳交通事件组合. 事件组合的原则为使最优路径中第i项目标事件的数量同第i项注意力水平分数成反比,例如用户在个体注意力水平获取的测试中第6项交通信号灯的得分为0.6,第5项限速标志的得分为0.7,则生成的最优路径中第6项交通信号灯的事件数量多于第5项限速标志的事件数量,即具有针对性的提升个体注意力的薄弱环节. 路径优化工作由模拟退火算法实现,算法不断迭代生成新的路径,并用代价函数评价生成的新路径,决定是否接受新路径. 最优路径即为使代价函数最小化的最优结果. 具体实现细节如下讨论.
3.1 代价函数
定义了一个代价函数作为优化目标,找到一个路径R*,使该函数值最小. 代价函数的设置如下:
C(R)=∑i|Li(R)-(1-pi)
(2)
式中:R表示每一次迭代生成的路径,R=(r1,r2…rn…rN),n∈[1,N],rn由每一个结点连接而成,表示组成路径的结点,Li(R)表示路径R中第i项事件占路径R全部目标事件数量的比值,即占比率:
(3)
式中:hi(rn)表示第i项目标事件在结点rn中的数量;∑nhi(rn)表示第i项目标事件在路径R所有的结点中的数量之和;∑i∑nhi(rn)表示路线R中所有的目标事件数量. 例如,表1中第1项规则行驶车辆,在路径中R所有的结点中出现的数量为10,而路线R中所有的目标事件数量为50,则Li(R)=10/50=0.5.
3.2 场景的离散化表达
为实现优化模型,受Huang等[17]工作的启发,本文将场景道路等分成25个单元块,模型中表示为5行5列的矩阵,则每个单元块可包含表1中6项目标事件的数量信息,hi(rn)(i=1,2,…,6)代表每一个结点中第i项目标事件的数量. 除目标事件信息,单元块还可存储该结点在布局中的位置信息. 根据单元块的位置信息,便可采用在矩阵中选取结点的方法采集路径,前提是相邻结点块可形成一条联通的路径,采样后的路径为带有目标事件数量信息的结点队列.
图7为场景离散化情况示意,图7(a)为场景离散化后路径与交通事件的分布示意图,线条表示场景道路. 在图7(a)中可见场景被分成25个单元格,每个单元格有道路与设置好的目标交通事件,圆点为目标交通事件. 可按选取单元格的方法来选取路径,如图7(a)中被选中的单元格. 图7(b)为本文虚拟场景的俯视图,路径与交通事件分布示意图可与之相对应.

图7 场景离散化概况Fig.7 Scene discretization overview
3.3 路径优化
路径优化中使用了模拟退火优化方法. 首先随机采样一条初始路径,然后根据算法进行迭代,每次迭代在现有路径上随机选取邻近点,以邻近点为新的起点与终点再次随机采样子路径,后比较新采样的子路径与原子路径的代价函数值,若新子路径的代价函数值更小则接受新子路径;否则,按一定的概率接受新子路径. 新路径将作为下一次迭代的已知路径进入迭代循环,依次类推,直至迭代结束取得最优解.
图8模拟了某一次迭代的具体过程. 首先,一条已知起点和终点路径R为这一次迭代的初始路径,如图8(a)所示. 然后,在已知路径R上随机采样新路径R′.

图8 路径优化算法随机选取邻域子路径示意图Fig.8 Path optimization algorithm randomly selects neighborhood subpaths
新路径R′的随机采样过程如图:在路径R中随机选择两个邻近点ra和rb,在以ra和rb为起点与终点再次随机采样一条子路径,前提是ra和rb仍能形成一条路径,然后将随机采样的子路径(ra…rj…rb)同原有子路径(ra…ri…rb)比较代价函数值大小,该路径是否被接受取决于Metropolis准则,如下所示:
(4)
df=C(R)-C(R′).
(5)

4 实 验
4.1 实验环境
使用C#语言与Unity5.6实现系统. 实验环境搭载了16 G内存、Nvidia Titan GPU、2.60 GHz Intel i7-5820 K处理器的服务器. 用户将通过FOVE虚拟现实眼球跟踪头盔与场景互动并完成实验. FOVE虚拟现实眼球跟踪头盔是一款消费级的虚拟现实头盔,它可以跟踪用户的视线,并查看用户的视线时候在目标注意力区域.
4.2 实验设置与指标评估
为讨论个性化训练方案的有效性,本文共设置3组对比实验:①个性化虚拟驾驶注意力训练,每名实验者在完成个体注意力水平初步评估后,根据系统为其自动生成的个性化训练方案进行训练. ②非个性化虚拟驾驶注意力训练,每名实验者在完成个体注意力水平初步评估后,在一条由现有虚拟驾驶场景随机生成的通用训练路径上进行注意力训练. ③传统训练,因传统驾驶训练未有系统训练教材,本次实验为同虚拟训练形成对比,设置了经验传授方法来模拟传统驾驶者提升注意力方法. 每名实验者在完成个体注意力水平初步评估后,由一名驾龄10年的驾驶教练,向实验者讲授行驶道路上应注意的事件和问题. 3组实验在训练内容完成后,每名实验人员都将再次在进行初步评估的虚拟场景的固定路径上完成注意力训练后评估测试. 评估测试的结果形式为表1中6项注意力水平的分数. 其中,每一项的分数为[0~1],每个测试者的综合分数为[0~6]. 本文选取了30名实验人员,其中有10名为新手驾驶员,年龄在20~25岁,驾龄为1~2年;10名为较熟练驾驶员,年龄在26~30岁,驾龄3~5年;10名为熟练驾驶员,年龄在30~35岁,驾龄6~8年. 这30名实验人员将被随机分成3个小组,3组实验人员分别在虚拟现实环境中进行相同的15 min注意力水平初步评估. 之后,第一组测试人员完成实验①,第二组测试人员完成实验②,第三组测试人员完成实验③.
5 实验结果分析
5.1 个性化虚拟驾驶注意力训练方法
如实验设置中所描述,实验①共有10人完成个性化虚拟训练,每人评估两次,每次6项数据. 实验共记录120项数据. 本文取10名实验人员的每项目标事件分数的平均值,取值[0~1],每项交通事件分数分为训练前评估与训练后评估,统计结果如图9所示. ①从直方统计图中可以看到每项目标事件的在训练前评估与训练后评估分数变化情况,数据显示,训练后评估的单项平均分数均比训练前高. 可见每一项水平都得到了提高. ②图9中训练前评估的单项平均分数最低项为“规则车辆”0.33分,训练后评估该单项提升至0.66. 说明通过个性化的训练,个体的最薄弱环节得到明显的提升. ③在个性化虚拟现实训练方法实验中对训练前评估分数与训练后评估分数进行了T检验统计,在所有的统计测试中都使用∂=0.05显著性水平. 个性化虚拟训练中训练后单项平均分数高(平均值M为0.764 4,标准差SD为0.071 544)比训练前单项平均分数高(平均值为0.497 5,标准差为0.097 96,T检验结果为P=0.000 485),证明使用本文方法训练后注意力水平比训练前有显著的提升,方法有效.

图9 个性化训练实验测试与评估分项平均分对比直方图Fig.9 Personalized training experiment test and evaluation item average score comparison histogram
5.2 各类实验对比结果分析
本文共进行了如实验设置所描述的3个实验. 目的是对比本文方法与其他方法的效果. 非个性化虚拟驾驶注意力训练与传统经验讲授训练实验的实验数据统计同个性化虚拟驾驶注意力训练实验同理. 在3类实验的结果对比分析中,本文选取每类实验的各单项平均分数总和即综合分数对各类实验效果进行分析比较. 综合分数的取值为[0~6]. 统计分数如表2所示. 个性化虚拟训练的训练后水平综合平均分数是4.67,非个性化虚拟训练的训练后水平综合平均分数是3.81,传统训练的训练后水平综合平均分数是3.82. 本文针对个性化虚拟训练与非个性化虚拟训练的训练后综合分数做了T检验,个性化虚拟训练后综合分数(平均值M为4.67,标准差SD为0.522 1)比非个性化虚拟训练后综合分数高(平均值M为3.81,标准差SD为0.507 5,T检验结果P=0.002 295),证明个性化虚拟训练方法比非个性化虚拟训练的综合效果要明显好于非个性化虚拟训练的综合效果. 同时对个性化虚拟训练与传统训练的训练后综合分数做了T检验,个性化虚拟训练后综合分数(平均值M为4.67,标准差SD为0.522 1)比传统训练(平均值M为3.823 3,标准差SD为0.655 96,T检验结果P=0.007 098)高,证明个性化虚拟训练方法比非个性化虚拟训练的综合效果要明显好于非个性化虚拟训练的综合效果.

表2 各类驾驶注意力训练方法实验分数对比
在3种实验的提升幅度统计上,也进行了统计分析,如表2所示,个性化虚拟训练的训练前评估水平综合平均分数是2.985,平均提升比例为165.26%. 其他两种方法的平均提升比例分别为127.49%和127.41%. 对每一个实验者的训练前的综合分数与训练后的综合分数进行比值,得到每一个实验者的训练后与训练前的综合分数涨幅百分比,并进行T检验,选取0.05的检验水平. 个性化虚拟训练的涨幅(平均值M为1.65,标准差为0.375)比非个性化虚拟训练(平均值M为1.274 9,标准差为0.109,T检验的结果P=0.009 5)高,说明个性化虚拟训练方法比非个性化虚拟训练方法具有较为显著的涨幅效果. 个性化虚拟训练的涨幅(平均值M为1.65,标准差为0.375)比传统训练(平均值M为1.274 1,标准差为0.148,T检验的结果P=0.011 4)高,说明个性化虚拟训练方法比传统训练方法具有较为显著的涨幅效果. 从表2中的综合统计分数对比中可以说明个性化虚拟训练方法的提升幅度是最明显的.
综合个性化虚拟训练方法实验结果分析,可以看出,个性化虚拟训练方法,总体具有更明显的提升效果,在个体注意力水平特点上也能够实现根据不同个体注意力水平的情况,强化弱项,保持优势,达到整体水平的平衡.
6 结 论
为解决安全有效提升驾驶注意力训练问题,本文提出了一种虚拟环境下的个性化的驾驶注意力训练生成方法. 该方法使用unity3D游戏引擎搭建驾驶的静态场景与动态场景;利用虚拟现实眼球头盔获取个体注意力数据;建立模型优化个性化方案;设置3类实验,共360条数据,数据统计分析后显示个性化虚拟驾驶注意力训练方法具有有效性,可明显提升个体的驾驶注意力水平,并可根据个体注意力水平特点提升其薄弱环节,训练更有针对性. 通过3类不同训练方法的实验对比数据证明,个性化虚拟驾驶注意力训练方法在提升驾驶注意力整体水平上优于非个性化虚拟训练方法和传统讲授训练方法. 实验结果表明,个性化虚拟驾驶注意力训练方法能够无危险性的情况下实现驾驶注意力水平的提升,效果优于其他训练方法.
