融合样本相似性的弱监督多标签分类
2021-08-11罗森林王海州潘丽敏孙晓光
罗森林,王海州,潘丽敏,孙晓光
(1.北京理工大学 信息系统及安全对抗实验中心,北京 100081; 2.通号城市轨道交通技术有限公司,北京 100070)
提 要: 针对面向实际应用场景中数据标签易残缺导致有监督多标签分类方法可用训练数据量减少,未能利用大量标签缺失数据中蕴含的样本特征空间关联知识以最大化判别间隔,限制多标签分类效果等问题,本文提出一种融合样本相似性的弱监督多标签分类方法.该方法利用标签相关性和样本相似性恢复标签以提高数据利用率,并将标签恢复嵌入到训练过程中以便挖掘标签相关性,通过近端加速梯度法进行参数优化,建立弱监督学习场景的多标签分类模型.在真实数据集上的实验结果表明,该方法能够利用样本相似性有效提升模型在标签残缺时的分类能力,实用价值大.
多标签分类[1]是解决同时关联多个标签的样本分类问题的机器学习方法.近年来,由于在现实场景中多标签数据的广泛存在,关于多标签分类的研究受到越来越多的关注,不断有新方法被提出[2-3].然而在实际应用中通常无法保证标签的完整性,由于数据采集不严谨、标注成本过高等原因,大多数的样本只有部分标签被标注.
为了缓解标签残缺导致的多标签分类性能下降的问题,弱监督多标签学习[4-8]应运而生.通过在训练过程中挖掘数据集中的信息对样本标签进行恢复以提升模型训练中可用的有效样本数量,同时在训练中利用恢复后的标签可以获得更加真实的标签分布,挖掘得到更加准确的标签相关性,提升多标签分类效果.
弱监督多标签方法缺失问题按照其处理缺失标签的方式可将这些方法分为3类.
第一类方法将缺失的标签视为负类,在训练过程中使用负类标签对缺失的标签进行填补.Bucak等[9]提出的MLR-GL方法把缺失的标签标记为负类(-1),通过使用排序损失的Group Lasso回归构建分类器来实现对残缺标签数据的多标签分类.Huang等[10]提出的LSML方法在MLR-GL的基础上对目标函数进行修改,添加约束项以实现标签稀疏化,提高分类器的泛化性.
第二类方法将缺失的标签视为矩阵中的空缺值,将标签恢复转化为矩阵补全问题,基于标签矩阵的低秩假设,依照现有标签对缺失标签进行恢复.Xu等[11]提出的Maxide方法利用两个边信息矩阵来加速矩阵补全,并且假设目标矩阵和边信息矩阵具有同样的潜在信息.Zhu等[12]提出的GLOCAL方法通过分解标签矩阵获得标签的潜在表示,结合局部和全局的标签相关性建立特征到潜在标签的映射,依据该映射对标签矩阵进行补全.
第三类方法为缺失的标签定义了新的表示方法,标签由正类(+1)、负类(-1)和缺失(0)构成.Wu等[13]提出的ML-MG方法首先使用0表示标签缺失,利用混合图构建由标签依赖关系构成的网络,并将该网络转化为一个线性约束的凸优化问题,通过ADMM法进行求解,获得分类模型.Cheng等[14]提出的MNECM方法使用+1、0、-1来表示标签状态以便于计算标签密度,并根据标签相关性构建标签置信度矩阵,通过ELM方法利用标签密度和标签相关性构建分类模型.
现有的弱监督多标签学习方法的思路主要是通过对标签集进行处理使缺失的标签能够参与到训练过程中从而提高数据的利用率和分类准确率.其主要存在如下两个问题:第一,标签恢复利用的信息有限.多数方法只利用标签空间的信息(标签相关性)对缺失标签进行恢复,忽视了特征空间的信息(样本相似性),导致恢复的标签质量不高从而影响最终分类效果;第二,未考虑构建类属特征.现有方法大多只注重于标签的恢复过程,却没有关注在标签缺失情况下构建类属特征,限制了分类准确率进一步提升的空间.
基于上述分析,针对标签残缺条件下的多标签分类问题,研究融合样本相似性的弱监督多标签分类方法.本文的主要贡献如下:①利用样本相似性和标签相关性对缺失的标签进行恢复,并将标签恢复过程嵌入到模型训练过程中,以挖掘更准确的标签相关性;②利用L1正则为各个标签构建类属特征,提升模型分类性能;③使用近端加速梯度法对模型参数进行优化,实现在标签残缺状态下的多标签分类.
1 算法原理
1.1 原理框架
融合样本相似性的弱监督多标签分类WSML方法的核心思想是在训练过程中根据样本相似性和标签相关性对缺失的标签进行恢复,同时为每个标签分别构建类属特征.采用近端加速梯度法对目标函数进行优化,从而缓解由于标签缺失导致监督信息不完备引起的分类性能衰退的问题,获得较高的分类准确率.WSML方法的原理框架如图1所示.

图1 WSML方法原理图Fig.1 WSML algorithm principle diagram
WSML方法主要包括2个模块:构建目标函数和优化参数.在构建目标函数模块中,分别将标签相关性和样本相似性引入目标函数,并且通过对特征系数W和标签相关性度量C添加L1正则项,实现基于特征选择的类属特征构建和标签空间的稀疏化;在参数优化模块中,将目标函数拆分为光滑凸函数和非光滑凸函数,然后计算该目标函数的利普西茨常数,最后交替优化参数W和C.
1.2 构建目标函数
在多标签学习中,具有n个样本的训练集被表示为D={(x1,y1),(x2,y2)…,(xn,yn)},其中xi表示第i个样本的特征向量,yi表示第i个样本的标签向量,当yij=+1时代表第i个样本与第j个标签相关联,当yij=-1时代表第i个样本与第j个标签不关联,当yij=0时代表第i个样本的第j个标签缺失.
由于多标签数据的每个标签都有最有利于其分类的类属特征,这些特征与原始特征相比具有稀疏性.所以通过在目标函数中对特征系数矩阵W施加L1正则的方式构建类属特征,函数如下:
(1)
因为在标签缺失的情况下直接地使用不完整的标签矩阵进行学习会导致分类性能的显著衰退.为了应对这个问题,提出使用标签相关性和样本相似性分别从标签空间和特征空间获取信息来对缺失的标签矩阵进行恢复.引入标签相关矩阵C∈l×l,cij表示标签yi和标签yj的相关程度,假设任何缺失的标签都可以通过与之相关的其他标签的值来进行重建.考虑到通常并不是所有的标签之间都存在相关性,所以对标签相关矩阵C施加L1正则来获得一个较稀疏的标签相关矩阵,修改目标函数如下:
(2)
在多标签学习中,标签相关性被认为是提高多标签分类性能的重要手段,所以标签相关性在被用于重建标签矩阵的同时,也被用来对特征系数矩阵的学习施加影响.如果两个标签之间存在着较强的相关性,那么预测这两个标签的类属特征应该越相似,即特征系数的距离越接近.基于这种考虑修改目标函数如下:
λ3‖C‖1+λ4tr(WL1WT) s.t.C≥0
(3)
式中L1∈l×l为矩阵C的拉普拉斯矩阵.被用于进行缺失标签恢复的另外一个重要信息是样本相似性.如果两个样本的特征存在较强的相似性,那么它们所具有的标签也应该很相似.为了衡量样本之间的相似程度,采用邻域图来计算样本相似性,具体计算方式如下:
(4)
其中sij=1代表样本xi与样本xj具有相似性,sij=0代表样本xi与样本xj不具有相似性.根据样本相似性的假设,修改目标函数如下:
λ3‖C‖1+λ4tr(WL1WT)+λ5tr(WTXTL2XW)
s.t.C≥0
(5)
1.3 参数优化
由于目标函数中L1正则项的存在,使得目标函数为不光滑的凸函数.首先对目标函数进行拆分.为了表示方便,使用Θ来一起代表目标函数中的两个参数W和C,待优化函数表示如下:
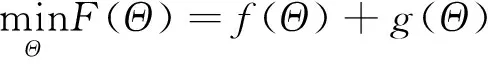
(6)
f(Θ)和g(Θ)表示如下:
λ4tr(WL1WT)+λ5tr(WTXTL2XW)g(Θ)=
λ1‖W‖1+λ3‖C‖1
(7)
式中:f(Θ)为光滑的凸函数;g(Θ)为非光滑凸函数.利用近端加速梯度法来解决该优化问题.先进行利普希茨常数的计算,给定Θ1=(W1,C1)和Θ2=(W2,C2),则有
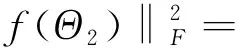

(8)
因此,该优化问题的利普西茨常数为
(9)
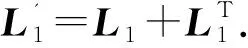
根据获得的利普西茨常数对W和C进行交替优化,交替优化过程如下.
输入:训练集D,模型参数λ1,λ2,λ3,λ4,λ5,利普希茨常数Lf输出:W,C
1.随机初始化W0,W1,C0,C1设为0,α0=1,α1=1,t=1
2.repeat

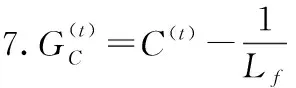
10.until收敛
11.W=Wt,C=Ct
2 实验分析
2.1 实验目的
为了验证WSML方法在弱监督多标签分类问题上的效果,在多个数据集上与LSML方法[10](2019)、GLOCAL方法[12](2018)、LLSF方法[13](2015)以及ML-kNN方法[14]进行对比分析.
① LSML方法利用标签相关性对标签矩阵进行恢复,并利用这种相关性指导模型训练过程,同时为每个标签构建稀疏的类属特征以提升分类能力.WSML方法与LSML方法的主要区别是,WSML在恢复标签矩阵以及模型训练的过程中额外引入了样本相似性以进一步提升分类能力.
② GLOCAL方法在训练模型的过程中挖掘标签间的全局和局部相关性以获得更好的分类结果,同时针对标签缺失情况依据标签矩阵的低秩假设恢复标签矩阵.
③ LLSF方法在目标函数中分别考虑类属特征和标签相关性,同时也使用近端加速梯度法进行参数优化,但是其没有考虑标签缺失的情况,可以看作是LSML方法的退化版本.
④ ML-kNN方法是对kNN方法在多标签学习领域的扩展,是多标签学习中一个经典的方法.
2.2 实验数据
选择采集自北京医院的diabetes数据集、临床病例medical数据集和文本分类enron数据集3个真实场景中的数据集进行实验.数据集的详细信息如表1所示.其中|D|,dim(D)和L(D)分别代表样本数量,特征数量和标签数量.

表1 数据集详细信息
2.3 评价指标
选择在多标签学习中常用的5种评价指标[15](汉明损失、排序损失、1-错误率、覆盖率和平均精度)对模型性能进行评价.
① 汉明损失α计算的是所有分类错误的标签占总标签数的比例,其定义如下:
(10)
式中:Δ表示对称差运算;h(xi)表示模型对xi标签的预测.根据定义,汉明损失的取值区间为[0,1],其值越小代表分类错误的标签越少,模型的准确性越高.
② 排序损失β计算的是模型将与样本不相关的标签排在与样本相关的标签之前的比例,是对模型输出结果置信度的评价指标,其定义如下:
(11)

③ 1-错误率υ计算的是模型预测样本中置信度排序最高的标签与真实标签不符的比例,其定义如下:
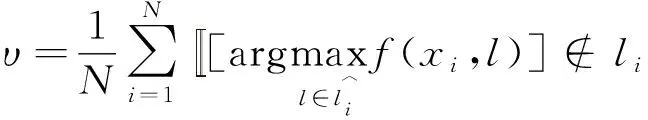
(12)

④ 覆盖率rc(Coverage)评估的是平均要在预测的标签中经过多少标签才能够覆盖该样本真正属于的标签,其定义如下:
(13)
其中rank代表排序操作,如果xi属于标签l的置信度越高,其排名就越靠前,rank(xi,l)的值就越小.该指标越小表示模型越能够将样本真正属于的标签找出来.
⑤ 平均精度η评估在给定一个标签时,比多少样本真正属于的标签的置信度比给定的标签更高,其定义如下:
(14)
与其他4个评价指标不同,平均精度的值越大代表模型的性能越好.
2.4 实验过程和参数
① 对训练集和测试集进行划分.
经过空缺值处理、SMOTE采样等数据预处理操作后,随机选择80%的数据作为训练集,剩余20%的数据作为测试集.
② 对WSML分类方法的参数进行选择.
采用5折交叉验证方法对WSML方法进行参数选择,将训练集随机地等分为5份,每次选择其中1份作为验证集,剩余4份作为训练集,随机抹除训练集中的标签以模拟标签缺失情况,抹除比例分别为20%、40%和60%,被抹除的标签的值被设置为0.在被抹除20%标签的训练集上训练模型,依据在对应验证集上的表现来选择模型参数,并将该参数固定,用于抹除40%和60%标签状态下的模型中.最终diabetes数据集实验中被选择的模型参数为λ1=10-5,λ2=102,λ3=10-3,λ4=10-5,λ5=10-5,学习率设置为1;medical数据集实验中被选择的模型参数为λ1=10-5,λ2=102,λ3=10-3,λ4=10-5,λ5=10-5,学习率为1;enron数据集实验中被选择的模型参数为λ1=10-5,λ2=102,λ3=10-3,λ4=10-1,λ5=10-5,学习率为1.
③ 对分类效果进行计算.
在测试集上计算各个评价指标,包括汉明损失α、排序损失β、υ、覆盖率rc和平均精度η,以表达不同标签缺失比例时分类方法的效果.
2.5 实验结果
不同标签缺失比例下的diabetes数据集实验结果如表 2[16-17]~表4所示.

表2 标签缺失20%的diabetes数据集实验结果

表3 标签缺失40%的diabetes数据集实验结果

表4 标签缺失60%的diabetes数据集实验结果
不同标签缺失比例下medical数据集的实验结果如表5~表7所示.

表5 标签缺失20%的medical数据集实验结果
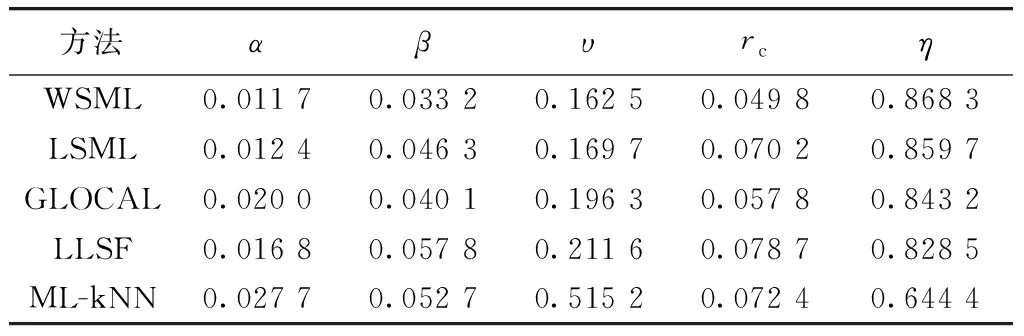
表6 标签缺失40%的medical数据集实验结果

表7 标签缺失60%的medical数据集实验结果
不同标签缺失比例下enron数据集的实验结果如表8~表10所示.
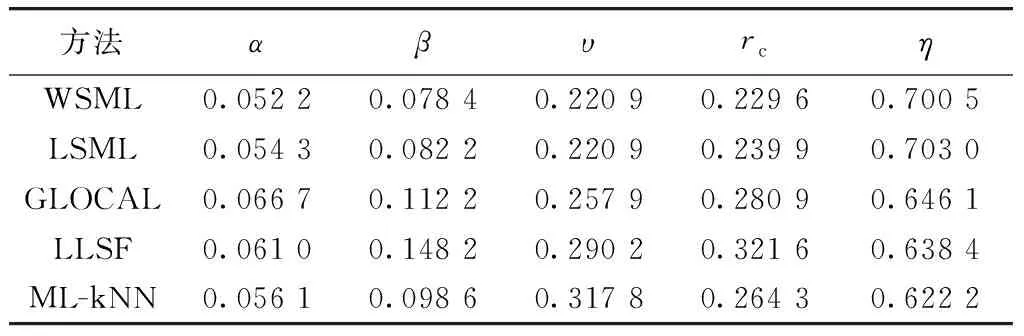
表8 标签缺失20%的enron数据集实验结果

表9 标签缺失40%的enron数据集实验结果

表10 标签缺失60%的enron数据集实验结果
从表2~表10中可以看出,WSML分类方法在标签缺失20%、40%和60%的情况下的表现都要优于其他4种对比方法,原因在于WSML分类方法能够通过标签相关性和样本相似性对缺失的标签进行恢复,纠正由于监督信息不完备产生的训练偏差,因此能够提升模型分类性能,保持较高的多标签分类准确率.但是不同于Ranking Loss等其余4个评价指标,WSML分类方法在Hamming Loss上的表现相较对比算法来说并不占优势,原因在于WSML算法融合了标签相关性和样本相似性,在某些标签相关性较强的数据集上容易得到强相关的预测结果,进而影响分类效果.
由实验结果可知如下结果.
① 同时使用标签相关性和样本相似性作为恢复缺失标签的依据能够获得更好的效果.WSML分类方法在不同标签缺失比例下相比于只使用标签相关性的LSML方法和GLOCAL方法在汉明损失、排序损失、1-错误率、覆盖率和平均精度5个指标上综合表现更优,说明在使用标签相关性的基础上考虑样本相似性能够获得更丰富的信息指导恢复标签矩阵以增加可用的数据量,从而更有效地进行模型训练,得到更好的分类性能.
② WSML分类方法能够有效提升在标签部分缺失情况下的模型性能.WSML分类方法相比于不考虑标签缺失情况的LLSF方法和ML-kNN方法,在不同标签缺失比例下均具有更好的综合表现,说明在模型训练过程中嵌入标签恢复的策略能够对标签相关性进行更准确的挖掘,提升分类性能.
③ WSML分类方法具有一定的通用性.WSML在diabetes、medical和enron三个来自不同场景的真实数据集上的综合表现均优于对比方法,说明WSML方法能够适应不同应用领域中的数据情况,实用价值大.
④ WSML分类方法具有一定的提升空间,引入标签相关性和样本相似性在提升缺失标签恢复指导有效性的同时会带来预测标签间的强相关性,一定程度上会提升预测结果的Hamming Loss,在未来的研究中可以尝试惩罚标签间的强相关性从而优化算法.
3 结 论
提出一种融合样本相似性的弱监督多标签分类WSML方法,该方法通过融合样本相似性和标签相关性进行高质量标签恢复以提高数据利用率,并将标签恢复过程嵌入训练过程以缓解标签残缺对模型的影响,实现在标签部分缺失情况下的多标签分类.为了评估该方法在多标签分类问题上的效果,将WSML同LSML、GLOCAL等多标签分类方法在3个真实数据集上进行对比实验.结果表明,WSML能够有效地提升在标签残缺情况下的模型分类效果,实用价值大.
