基于随机搜索算法优化XGBoost的过热汽温预测模型
2021-08-09马良玉於世磊赵尚羽孙佳明
马良玉,於世磊,赵尚羽,孙佳明
(华北电力大学 控制与计算机工程学院,河北 保定 071003)
0 引 言
燃煤发电机组运行中,维持过热汽温恒定在目标值附近,对于最大限度地提高发电效率及锅炉汽轮机组的寿命至关重要[1]。火电主力机型向高参数、大容量超临界、超超临界机组发展,使得过热汽温系统的大惯性、大时延特性更加明显,加大了过热汽温控制难度[2]。随着区域电网风能、太阳能等可再生能源电源的比例不断增加,为消纳清洁能源并保证电网供电品质,火电机组参与AGC深度调峰频繁大幅变负荷灵活运行已成常态,这更加增加了汽温调控的难度。因此采用先进的汽温控制策略改善过热汽温控制效果一直是现场重要的研究课题。
随着智能控制技术的发展,模型预测控制受到越来越多学者的关注。而建立过热汽温对象的高精度预测模型,是实现过热汽温智能优化控制的基础,对此很多学者进行了研究。文献[3]采用具有外部时延的极限学习机建立过热汽温模型,并用改进烟花算法对模型进行优化,模型具有较好的预测精度和泛化能力。文献[4]分别采用BP神经网络和Elman模型对过热汽温进行建模,表明两种模型都可以较好地逼近实际输出,但模型的训练时间较长。文献[5]采用粒子群优化算法对支持向量机的参数进行优化,建立了基于PSO-SVM的过热汽温模型,但建模和测试样本集较少。
本文以某600 MW超临界机组为对象,基于仿真机获取机组大范围变负荷工况过热汽温系统的运行数据,尝试用机器学习领域的XGBoost(eXtreme Gradient Boosting)算法对过热汽温特性进行建模,并利用随机搜索算法寻找模型的最优参数,确立精度较高的过热汽温特性模型,为过热汽温智能预测控制奠定基础。
1 算法介绍
1.1 XGBoost算法原理
XGBoost算法集成思想为基础[6]。集成学习方法将多个学习模型组合,使组合后的模型具有更强的泛化能力,以获得更好的建模效果。XGBoost是在梯度下降树(Gradient Boosting Decision Tree,GBDT)的基础上对boosting算法进行的改进,由多棵决策树迭代组成[7]。其基本思想是:首先构建多个CART(Classification and Regression Trees)模型对数据集进行预测,随后将这些树集成为一个新的树模型。模型会不断地迭代提升,每次迭代生成的新树模型都会拟合前一棵树的残差。随着树的增多,集成模型的复杂度会逐渐变高,直到接近数据本身的复杂度,训练也达到最佳效果。
XGBoost算法模型如下所示:
(1)
式中:ft(xi)=ωq(x)为CART的空间;ωq(x)为对样本x的打分,累加得到模型预测值;q代表每个树的结构;T为树的数目;每个ft对应于一个独立的树结构q和叶子权重ω。
XGBoost内部决策树使用的是回归树,回归树的分裂结点对于平方损失函数,拟合的就是残差;而对于一般损失函数(梯度下降),拟合的就是残差的近似值,所以XGBoost的精度会更高。残差拟合的迭代过程如下:
(2)
(3)
(4)
……
(5)

根据残差的迭代过程,可以得到算法的目标优化函数,即损失函数:
(6)
对于一般损失函数,XGBoost会做二阶泰勒展开是为了挖掘更多关于梯度的信息,同时移除常数项[8],使得梯度下降方法可以更好地训练。第t步的损失函数为
(7)
(8)
式中:gi和hi分别为一阶和二阶导数。
与其它算法不同的是XGBoost算法中加入了正则化项Ω(f),以防止过拟合,更好地提高模型精度[9]。正则化项为
(9)
式中:Ω(f)是表示树的复杂度的函数,函数值越小则树的泛化能力越强[10]。其中ωj为树f中第j个叶子节点上的权重,T为树的叶子节点总数,γ为L1正则的惩罚项,λ为L2正则的惩罚项,是算法的自定义参数。因此得到目标函数:
(10)
(11)
(12)
式中:Ij={i|q(xi)=j}代表第j个叶子节点上的样本集合。
XGBoost模型会采用交叉验证的方式来提高预测精度,本文中采用K折交叉验证(K-fold Cross Validation,K-CV)对模型进行调优[11]。K-CV就是将数据集等比例分成K份,其中的一份作为测试数据,其它的K-1份数据作为训练数据。重复进行K次实验,得到K个模型,用这个模型最终的验证集的回归准确率的平均数作为此K-CV下回归器的性能指标,其原理如图1所示。K-CV可以有效地避免过拟合与欠拟合的发生,一定程度上提高模型精度,在本文中选取K=5。
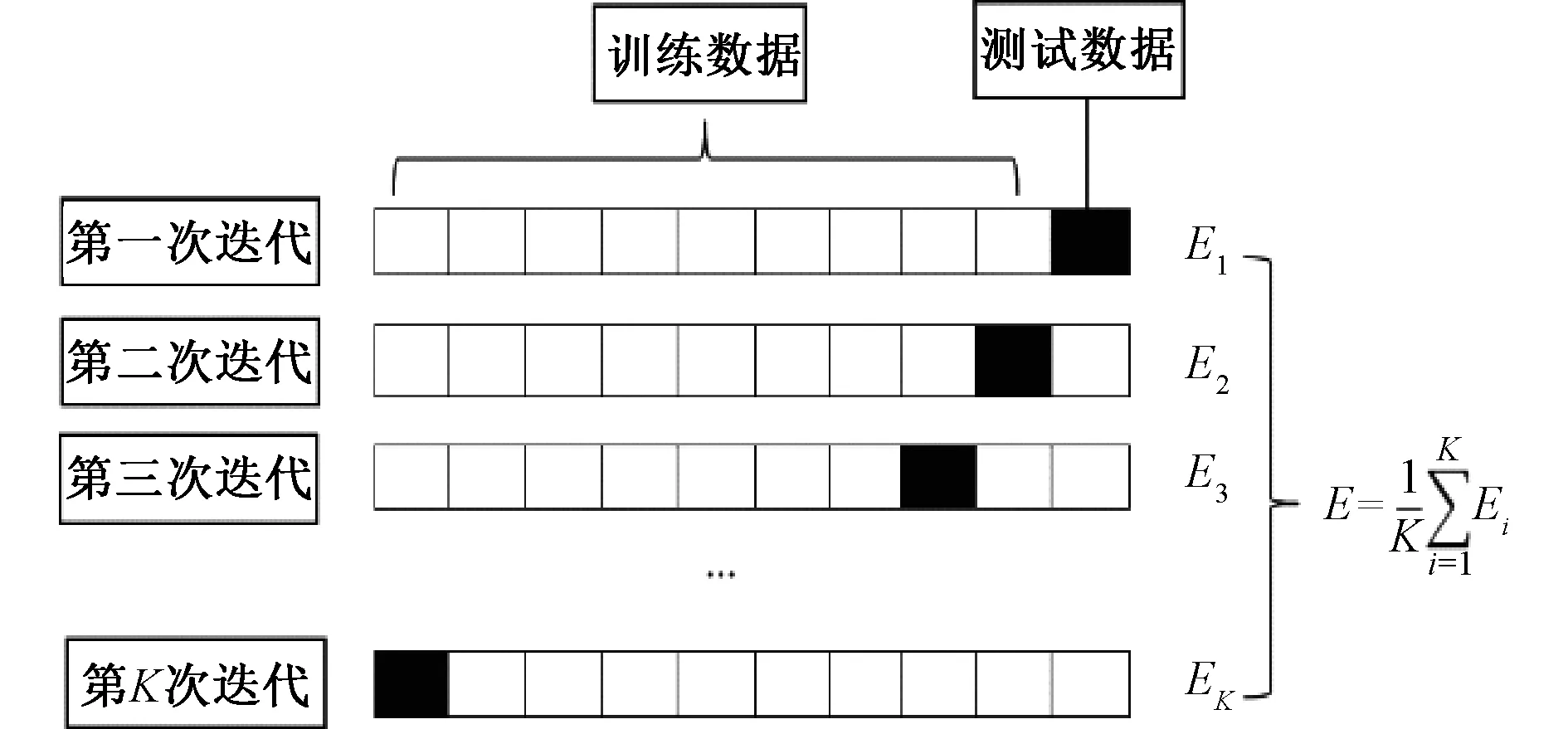
图1 K-CV方法示意图Fig.1 Schematic diagram of K-CV method
1.2 搜索算法
网格搜索算法(Grid Search Method,GSM)是一种寻找最优参数组合的方法,将搜索区域划分成网格状,依次对交叉点进行验证,选出最优参数组合[12]。GSM会提前对搜索区域进行划分,缺点是划分的网格越多等同于参数组合得越多,计算机的计算量越大,寻优时间就会越长。如果网格划分的不够细,很可能会搜不到最佳的参数组合,如图2(a)所示。
随机搜索算法(RandomizedSearch Method,RSM)与网格搜索类似,但不会遍历所有的参数组合,而是通过选择每个超参数的一个随机值进行随机组合,从而大大减少超参数搜索的计算量,缩短寻优时间,如图2(b)所示。可见,RSM以在参数空间中随机采样的方式代替了GSM的网格搜索,对于连续变化的参数,RSM将其当作一个分布进行采样,这是GSM做不到的。因此,GSM适用于三四个(或者更少)的超参数,当超参数个数不断增多时,其寻优所需时间将会呈指数级上升。相比之下,RSM更加高效。
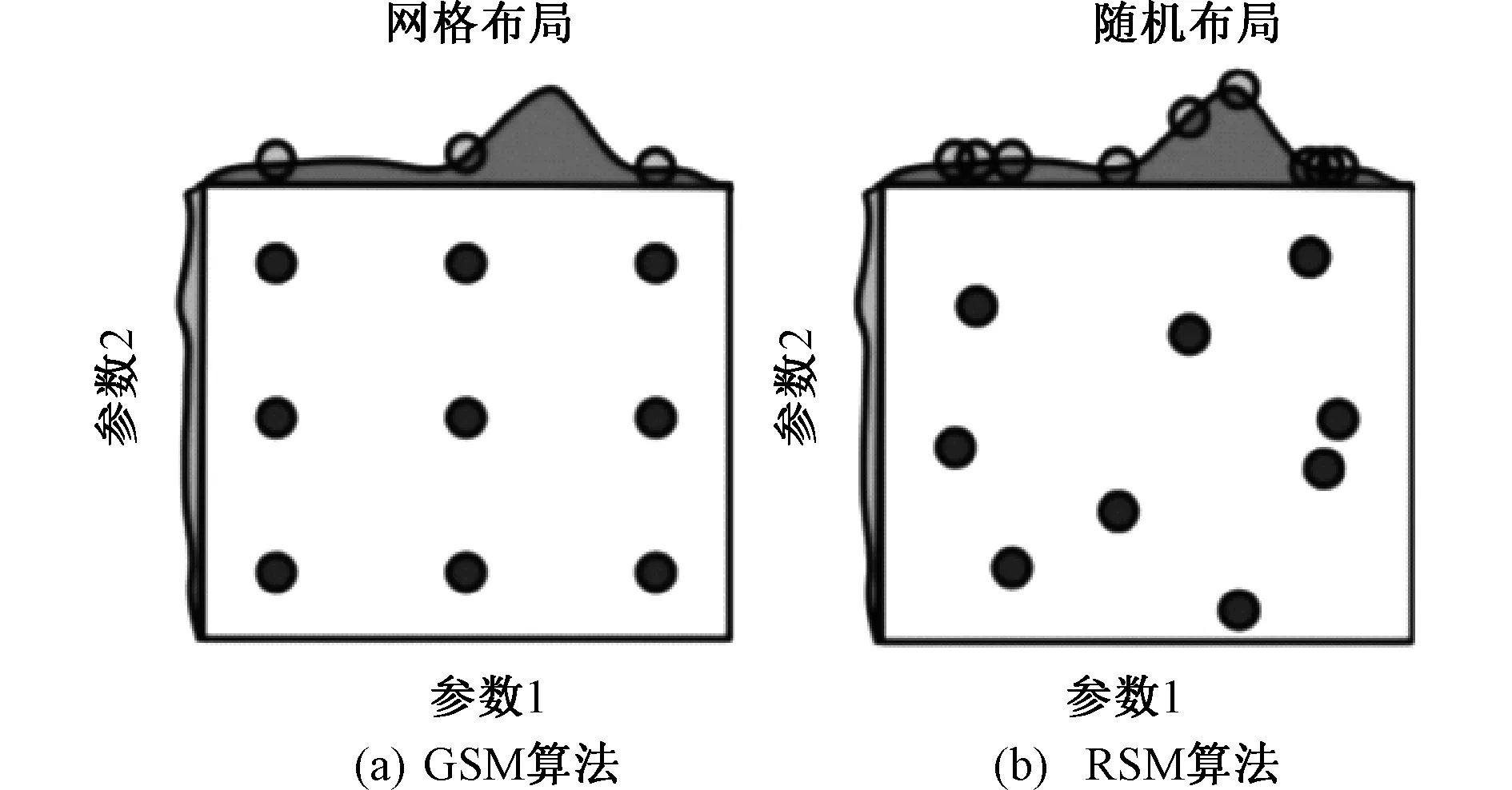
图2 两种算法示意图Fig.2 Schematic diagram of the two algorithms
2 汽温特性XGBoost模型结构确立
2.1 机组及过热器喷水减温系统简介
本文研究对象为某600 MW超临界机组,型号为DG-1900/25.4-Ⅱ,单炉膛、一次再热、平衡通风、固态排渣和全悬吊结构Π型锅炉。
该锅炉过热汽温采用两级喷水减温控制,各级喷水均分为左、右两侧,可以分别调节。第一级喷水减温器在低温过热器出口集箱与屏式过热器入口集箱之间,用于控制屏式过热器出口汽温。第二级喷水减温器在屏式过热器出口集箱与末级过热器入口集箱之间的连接管道上,用于精确控制末级过热器出口汽温,使之稳定在额定值。锅炉喷水减温系统如图3所示。
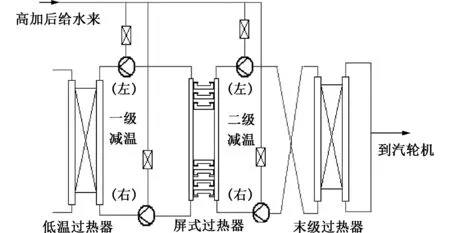
图3 喷水减温系统布置图Fig.3 Layout of water-spray desuperheating system
2.2 模型变量选取
火电厂锅炉机组变负荷运行过程中,煤量、风量、给水流量、给水温度及喷水减温等因素的变化对过热汽温均有影响[13]。综合考虑过热汽温的主要影响因素,最终选取表1所示参数建立过热汽温特性预测模型[14](以一级、二级单侧为例)。

表1 过热汽温系统模型变量Tab.1 Variables for superheater system models
2.3 模型结构
由于过热汽温具有大惯性和大迟延特性,且在不同负荷下具有较强的非线性,为提高模型的精度,选取具有输入时延和输出时延的XGBoost模型结构,将各输入变量的当前时刻值及其二阶时延值、以及输出变量的二阶时延反馈值作为模型的输入,将输出变量当前时刻的值作为模型输出[15]。这样,针对各级左、右两个过热器,每个模型均有26个输入变量、1个输出变量。模型结构如图4所示。

图4 XGBoost模型结构Fig.4 XGBoost model structure
3 模型训练与验证
3.1 模型的训练与验证
借助上述超临界机组的全范围仿真机,以5 MW/min的变负荷率,自600 MW分段降负荷至420 MW,再逐渐升负荷至600 MW,以1 s采样周期共获取12 000组数据用于模型训练。根据经验将所有数据归一化至[0,1]范围。本文建模采用Python语言编程实现,仿真平台为Pycharm。
根据表1、图4所示模型变量和结构,用XGBoost建立过热汽温性预测模型,并分别用GSM和RSM对模型参数进行优化,比较两种模型的优化效果。
由于XGBoost模型参数较多,全部进行优化会给计算机的内存增加挑战,大大增加寻优时间,最终选取如下4个主要参数进行优化:(1)树的数目n_estimators,此参数越大越好,但占用的内存与训练时间也会相应增长,本文寻优范围80~200;(2)树的最大深度max_depth,该参数用于避免过拟合,取值范围为5~10;(3)学习率learning_rate,取值范围为 0.05~0.3;(4)最小叶子节点样本权重min_child_weight,与max_depth的作用相似,用于避免过拟合,取值范围为1~9。
XGB的模型4个初始参数分别设置为100、5、0.1、1。此外GSM在寻优过程中需要设置各参数寻优步距(本文依次取5,1,0.01,1),RSM则需设置随机搜索的种子数(本文取10)。采用上述参数对一级、二级汽温模型寻优后,最终确定的GS-XGB和RS-XGB模型的参数见表2。

表2 两级过热汽温系统模型参数Tab.2 Model parameters of two level superheater system models
其中优化后的一、二级汽温系统RS-XGB模型对训练集的拟合结果见图5。可见,经RSM优化后的一、二级过热汽温XGBoost预测模型,针对训练样本集模型拟合值与真实值变化曲线基本重合,2个模型输出的最大误差均小于±0.2 ℃。

图5 一、二级过热汽温系统RS-XGB模型训练结果Fig.5 Training results of two RS-XGB models for the first and second stages of superheater system
为测试训练好的RS-XGB模型的预测能力,仿真系统以12 MW/min的变负荷率,自600 MW依次变负荷至500 MW、420 MW、550 MW、600 MW及540 MW,以1 s采样周期获取6 000组与训练样本不同的数据对模型进行验证。2个模型的预测结果及误差曲线如图6所示。可见,优化后的一、二级过热汽温XGBoost预测模型,汽温预测值与真实值变化曲线仍十分接近,2个模型输出的最大误差均小于±0.1 ℃。表明针对与训练样本不同的数据集,模型依旧具有较高的预测精度和很好的泛化能力。
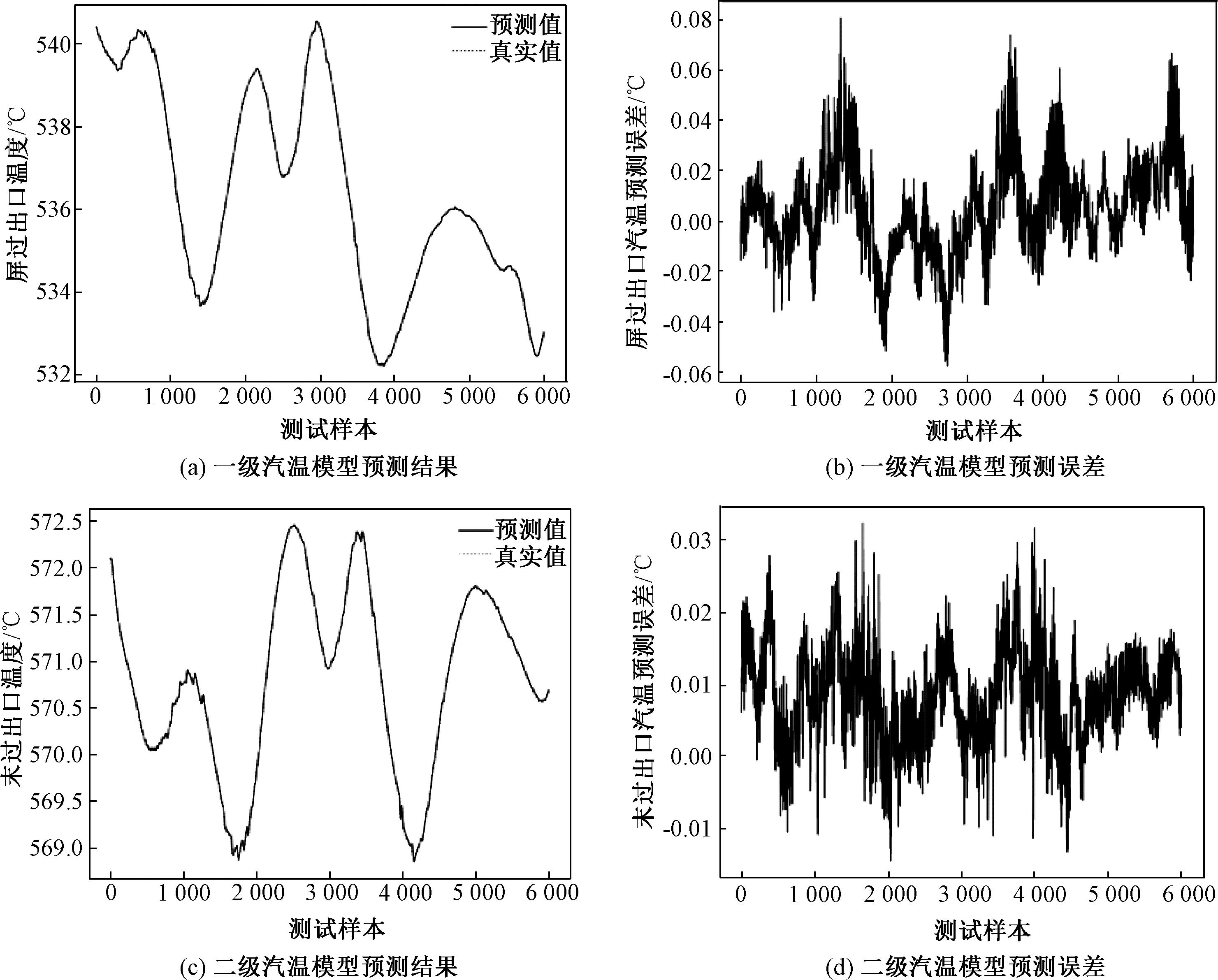
图6 一、二级过热汽温系统RS-XGB模型测试结果Fig.6 Testing results of two RS-XGB models for the first and second stages of superheater system
3.2 GSM和RSM模型优化效果比较
采用均方误差(MSE)、平均绝对误差(MAE)及寻优时间对两级过热汽温系统GS-XGB和RS-XGB模型的寻优效果进行评估,结果如表3所示。可见,RS-XGB模型针对训练集和预测集的预测精度均比GS-XGB更好,且寻优时间也大大缩短。

表3 过热汽温系统模型寻优结果评价Tab.3 Evaluation of superheater system models
考虑到本文只是对4个参数进行了寻优,随机搜索算法已体现出较大优势,当参数进一步增多时,网格搜索所需时间会呈指数增长,RSM寻优效率比GSM会更具优势。
通过多次试验发现寻优算法的种子数和步距对模型精度及寻优时间都有影响。对于GSM,本文要寻优的参数有4个,让其中的3个参数值保持不变,改变另一个参数寻优的步距。经对比发现,改变各参数的寻优步距,随着步距的增大,搜索时间会大大减小,但是模型精度会有下降。对于RSM,模型默认种子数为10。设置种子数从5开始增加,以5递增,随着种子数的增加,精度稍有提升,但寻优时间会大大增加。
4 结 论
针对600 MW超临界火电机组各级过热器系统汽温对象(含喷水减温器),建立了基于XGBoost的过热汽温预测模型。由于过热汽温具有大时延、大惯性的特点,为提高模型预测精度,采用具有二阶时延的XGBoost模型结构,并利用网格搜索和随机搜索两种算法对模型参数进行寻优。结果表明:RSM优化的XGBoost模型预测精度比GSM优化的XGBoost模型精度更高,寻优时间更短。本文建立的过热汽温特性模型,可以为过热汽温预测控制的进一步实现奠定基础。
