基于改进YOLO v4 的小目标检测方法
2021-08-02姚克明
魏 龙,王 羿,姚克明
(江苏理工学院电气信息工程学院,江苏常州 213001)
0 引言
随着机器视觉和深度学习的发展,目标检测算法应用越来越广泛,可进行工件检测[1]、布匹瑕疵检测、行人检测[2],车辆检测[3]以及医学影像分析[4]等。
目前常用的深度学习目标检测算法主要有:two stage方法,如Faster R-CNN[5]、Mask R-CNN[6]等通过对样本图像生成一系列预测框,利用卷积神经网络进行分类和回归实现预测;one stage 方法,如SSD[7]、YOLO[8]等直接对图像进行检测生成预测框,通过回归输出预测结果。后者在检测速度上有很大优势,对一些需要实时检测的场景十分有效。
一般目标检测通过多层卷积神经网络进行特征提取可以获取丰富的语义信息,进而实现对目标的检测。对于小尺寸目标,由于在图片中占有的像素点较少导致有效特征不足,检测往往比较困难并出现漏检情况。针对小目标检测精度不高的问题,Liu 等[9]提出图像金字塔和逐层预测方法对小目标特征层进行定位。但该方法对计算机硬件和计算能力要求非常高,因此使用较少;Bell 等[10]参考RNN 算法中的长短期记忆,记录多层的特征信息对小目标进行预测,但由于该方法固有速率比较慢而实用性不高。
本文基于YOLO v4 网络,对原网络的目标检测层和卷积结构进行改进,提出一种多尺度目标检测和深度可分离卷积的特征提取算法,对高分辨率大图片的检测进行优化,增加了一种自适应先验框,在保证检测速率的精度前提下,提升对高分辨率图片里的小目标和低分辨率图像检测效果。
1 YOLO v4 原理与结构
YOLO 算法本质是一种目标回归问题,其检测过程是将输入图像划分为一定的网格,对整个图片进行一次遍历,当每个网格中检测到目标时就根据当前网格的先验框绘制出预测框,进而直接预测出目标结果。
YOLO v1 算法将图像划分为7×7 的网格,每个网格有两个预测框,根据预测框的IOU 直接给出结果;YOLO v2[11]是将图像划分为13×13 的网格,每个网格有5 个先验框(an⁃chor box),根据先验框的结果进行边框回归最后绘制出预测框(bounding box);YOLO v3[12]和YOLO v4[13]在之前的基础上增加3 个不同尺度的预测网络,分别对应13×13、26×26、52×52 的网格,用来检测大目标中的中等目标和小目标,每个预测网络分别有3 个预设好的先验框。当检测到目标后在不同的预测网络上进行边框回归,最后输出预测框结果。
YOLO v4 的检测网络主要由CSPDarknet53 网络、SPP[14]和PANet[15]组成。CSPDarknet53为主干特征提取网络,主要由CBM 卷积网络模块、CBL 卷积网络模块和CSP[16]残差网络模块构成。SPP 为特征金字塔网络,将输入的任意图像大小最终统一到宽高大小由CBL 卷积网络模块和Max⁃pool 组成。PANet 为特征增强网络,主要采用上采样和下采样对不同的特征层进行特征融合,输出更高语义信息。
CBM 卷积网络模块由卷积网络、标准化和Mish[17]激活函数组成,如图1 所示。
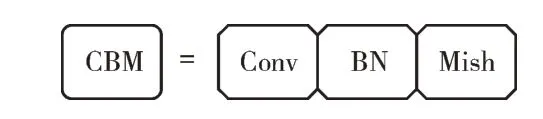
Fig.1 CBM convolution network module图1 CBM 卷积网络模块
CBL 卷积网络模块由卷积网络、标准化和Leaky Re⁃lu[18]激活函数组成,构成如图2 所示。

Fig.2 CBL convolution network module图2 CBL 卷积网络模块
CSP 残差网络由残差网络块(Res unit)、CBM 卷积块和大残差边组成,构成如图3 所示。
伴随企业的运行及发展,在企业集团运行中,战略性成本管理作为较为重要的内容,是企业经济发展的保障。在企业运行中,若只是依靠短期成本降低是无法满足企业发展需求的。在成本管理中,应该结合成本管理的理念,转变以往的成本核算以及成本经营控制机制,结合企业成本管理工作的特点,进行成本管理策略的完善,逐渐提高企业的经济性,为企业成本功能、成本质量以及成本管理的制度完善提供参考。
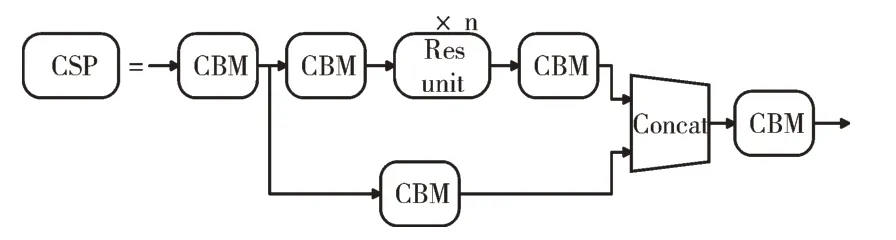
Fig.3 CSP residual network图3 CSP 残差网络
其中Res unit 为进行n 次残差网络的残差结构,构成如图4 所示。

Fig.4 Res unit图4 Res unit
2 YOLO v4 网络的改进
2.1 深度可分离卷积模块
YOLO v4 主干特征提取网络中,CBM 卷积模块通过多次下采样获取较高的特征信息。在特征融合网络中具有较高语义信息的特征层进行上采样融合时,CBM 卷积模块会有一定的信息丢失,因此对于小目标的检测准确度会降低,所以考虑在特征提取和特征融合网络中采用一种深度可分离卷积块替换原YOLO 网络中的普通卷积块,尽可能多地保留较高的特征信息。
深度可分离卷积[19]模块实现过程:对特征层所有的通道先进行1×1 的卷积升维,再进行一定大小的卷积得到所需要的特征大小。与普通卷积相比,深度可分解卷积在深层次网络中可以大大减少网络参数量,加快计算过程,并且可以同时考虑通道数和特征区域大小的改变,实现了通道和区域的分离。经过深度可分离卷积后进行标准化和Swish 激活函数过程,深度可分离卷积模块构成如图5 所示。

Fig.5 Depth separable convolution module图5 深度可分离卷积模块
在深度可分离卷积块完成后引入注意力机制(Atten⁃tion Mechanism)[20],对深度可分离卷积后的特征层实行通道注意力机制,同时在深度可分离卷积后引入残差边。
注意力机制过程:对输入的特征层进行全局池化操作,Reshap 后先进行1×1 的卷积对通道数降维,接着进行1×1 的卷积,使注意力机制的通道数与输入的特征层通道数相同。将两个通道数相乘即可成功加入注意力机制,对相乘的结果通过Sigmod 函数将输出值固定在0~1 的范围内。
对加入注意力机制的特征层进行1×1 卷积并进行标准化,同时判别是否满足残差条件,判别输入的特征层进行卷积时的步长是否一致。卷积的步长不同会改变特征层的长宽,造成特征层维度不同;另一个条件是特征层通道数必须相同,只有特征层的维度和通道数都相同时,将该残差边进行特征层相加,完成残差结构输出。
2.2 多尺度检测网络
在YOLO v4 网络中对小目标进行预测的特征层为52×52,当输入图片为416×416 时可以检测到的最小像素值为8×8,若输入的图片尺寸过小,YOLO 网络会将图像自动放大,图像中的小目标会产生失真导致无法准确检测。本文考虑在原预测网络中增加104×104 的特征层,将在主干特征提取网络进行两次下采样后得到的特征层,与其余特征层通过CBL 卷积块上采样特征匹配后进行向量融合,得到更丰富的语义信息。再将该特征层进行下采样传递,输出104×104 的特征层进行预测,这样可以使特征预测网络更加细致,检测范围更广泛。改进后的YOLO 网络结构如图6所示。
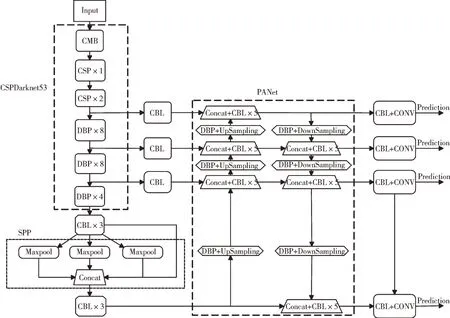
Fig.6 Improved YOLO v4 network图6 改进的YOLO v4 网络
2.3 自适应先验框
在YOLO v3 的预测网络中,每个预测特征层都有3 个预先设定好的先验框,在训练过程时根据训练图片中目标尺寸的大小选择合适的先验框进行边框回归输出预测框。YOLO V4 网络中加入了K-means 聚类方法,对所有预先标定好真实框的训练数据通过聚类到合适的先验框,再根据聚类后的先验框进行数据训练,使预测框的结果更接近标注的真实框。由于实际数据中小目标的标注在所有数据中占比不大,通过固定的先验框和聚类得到的先验框在预测时会忽略小目标标注框,所以预测框结果对小目标效果不佳。
2.4 对高分辨率图片检测优化
YOLO 检测过程:将输入的图像大小固定到一定尺寸然后进行目标检测,当YOLO 网络的输入为416×416 时进行采样。负责检测小目标的大特征层为52×52,每个特征网格对应图像的感受野为416/52=8,8×8 大小。当输入图像大小为1 920×1 080 时,通过YOLO 网络压缩对应长边为1 920/416×8=37,即当目标特征大小小于37 像素点时将无法学习特征信息。
对火灾进行远距离拍摄或者使用遥感图像时,为了获得更丰富的图像信息往往会采用高分辨率的大图片,而检测目标常常在大图像中存在的位置偏小,直接使用大图像进行YOLO 检测会将图像压缩从而使得小目标特性丢失,因此需要对大图像进行处理后再检测。
考虑到YOLO 网络是将图像固定到一定尺寸进行检测的,因此可将高分辨率的大图片进行分割,使用分割后的小图片进行检测。为了避免特征信息的遗漏以及检测目标被图像分割所截断,在图像分割时要设置一定的重叠区域。当分割后的图像大小为416×416 时,可以将重叠区域设置为416×25%=104 像素。对分割后的每张小图片分别进行检测,检测完成后对所有图像进行还原,再对原图进行非极大值抑制,剔除同一目标的重复检测框。这样小目标的特征就可全部学习,一定程度上提高了检测准确性,也可以避免小目标漏检,检测结果有很大提升。
3 实验结果与分析
3.1 实验环境
本文的实验环境为:处理器Inter® Core™i7-10875H CPU @2.3GHz,显卡NVIDIA GeForce RTX 2060,内 存16GB,Windows10 64 位系统。GPU 加速库为CUDA10.0 和CUDNN7.4.15;深度学习框架为PyTorch,版本:torch 1.2,torchvision:0.4.0;开发环境为Pycharm,编程语言Py⁃thon3.6。
3.2 数据集建立
使用YOLO v4 算法进行目标检测时需使用大量数据集进行训练。利用训练好的权重进行检测,本文使用布匹瑕疵检测和火灾检测验证改进后的算法对小目标检测的效果。
布匹瑕疵检测数据集选择公开的天池数据集,包含5 000 余张有瑕疵的图像,使用COCO 数据集进行整理归类后分为20个类别,将所有图片与标注好的XML 文件相对应,使用Python 文件生成包含标注信息的txt 文件进行读取。
3.3 数据训练
为了加快YOLO 模型训练引入迁移学习思想。迁移学习是将在已知源域进行训练学习后的模型迁移到具有相似特点的目标领域,使用迁移学习可以使网络模型快速在新的特征领域获取特征信息,减少数据集的网络初始化和训练时间,加快模型收敛过程。
使用YOLO v4 预训练好的权重进行迁移学习训练。整个训练过程分为50 轮,前25 个轮训练学习率设置为1×10-3,每次读取图片数量为4,同时冻结一部分网络参数,加快网络的初步学习;后25 轮训练学习率设置为1× 10-4,每次读取图片数量为2,并解冻所有网络参数使网络优化。将数据的90%进行训练,10%进行验证,训练过程具有反向梯度,验证过程无反向梯度。保存每一轮训练完成的权重并计算loss 值,训练集和验证集的loss 值变化情况如图7、图8 所示。

Fig.7 Changes of training loss value图7 训练集loss 值变化情况

Fig.8 Change of loss of verification set图8 验证集loss 值变化情况
由loss 曲线图可以看出,在训练了2 500 步后loss 值趋于稳定,在迭代了48 轮后验证集的loss 值具有较好的特征信息。将训练完成后loss 值较优的权重载入到YOLO 检测网络中即可使用YOLO v4 进行实时检测。
3.4 结果分析
对布匹瑕疵的识别中,由于布匹瑕疵种类繁多,背景比较单一,因此对检测图像亮度和清晰度有一定要求。本文方法在对布匹扎洞瑕疵识别中,识别准确率acc 可达89%,mAP 值为73.56%。在对视频图像的连续识别中,640×480 大小的视频识别帧率为20fps,可以达到实时检测效果。布匹瑕疵识别效果如图9 所示。

Fig.9 Recognition effect of cloth defects图9 布匹瑕疵识别效果
对火灾识别中,由于火焰图像特征信息丰富,本文方法对背景明显图像的识别准确率acc 可达95%,其mAP 值为88%。通过本文的改进,一些小特征和低分辨率图像也有很好的识别效果,如图10 所示。

Fig.10 Fire identification effect图10 火灾识别效果
4 结语
针对目前检测算法对小目标检测的不足,本文基于YOLOv4 网络通过对主干特征提取网络使用可分离卷积模块和增加多尺度检测网络的方法,提升对小目标的检测效率。同时改进自适应先验框,通过对高分辨率大图片的分割识别,使大图片里的小目标可以有效监测。通过本文的改进,在使用YOLO 算法进行检测时可有效检测出小瑕疵和目标。
由于在YOLO 网络中增加了多尺度计算,导致在训练过程中训练时间会略有增加,但对检测效率影响不大,可以达到实时检测效果。后续工作中要对网络进一步优化,使其可以搭载到移动设备或简易终端中,进一步提升检测精度和速度。
