机考口试评分方式对比研究
2021-07-28吴泓霖
吴 泓 霖
(教育部考试中心,北京 100084)
一、研究背景
(一)口语测试
口语能力是交际语言能力的重要组成部分,对口语能力的测试也一直是语言测试研究的重点和热点。口语测试属于行为表现评估(performance assess-ment),传统上以面试型口试为主,也称为直接型口语测试(direct speaking tests),由一位或多位考官对一位或多位考生进行面对面的口语测试[1]。这种测试方式20世纪50年代发源于美国,并得到了广泛应用,其主要优点在于真实性,能够反映出现实生活中口语交际的特点。但是,它也有明显的缺点,包括测试效率较低、经济成本较高、测试标准难以统一、对考官的能力和经验要求较高等。随着口语测试研究和实践的发展,半直接型口语测试(semi-direct speaking tests)开始出现,通过播放录音指令、提供试题册或其他“非真人考官参与”的方式进行口试,极大地提高了口语测试的效率,因此该测试方式迅速地发展起来。后来,计算机技术和非直接型口语测试相结合,产生了基于计算机的口语测试(computer-based speaking tests),简称为机考口试。它是一种将考试内容以计算机形式呈现,将考生作答以电子形式记录下来并进行评分的口语测试方式[2]。与面试型口试相比,机考口试具有多种优势,包括不同场次的测试标准和流程一致、测试效率高、评分信度高、可实现自动评分等。
目前依然采用面试型口试的考试并不多,机考口试已经成为主流的口语测试方式,包括国外的托福网考、培生学术英语考试、领思考试,国内的大学英语四、六级考试等高利害考试。此外,国内有些省市(比如广东省和上海市)还在高考英语中实施了机考口试,并将分数计入高考总分。
(二)口试评分
口语测试一般采用的题型都是主观题,因此需要有评分员对考生表现进行评判。在面试型口试中,大部分情况下由考官担任评分员,在口试现场对考生表现进行评分,即评分过程和考生作答同时进行;在机考口试中,一般先通过计算机考试系统收集考生作答录音,再另外组织评分员进行评阅,即评分过程和考生作答从时间和空间上分离。
口语测试有不同的评分方式,而且对各种评分方式的定义也存在差别。通过文献梳理,本研究认为常见的口试评分方式可分为整体评分(holistic scoring)、分项评分(analytic scoring)、任务评分(part scoring)三种[3]。整体评分指评分员基于对考生整场口试表现的总体印象,按照评分标准给出一个分数,如香港英语口试。分项评分指评分员基于考生整场口试的表现,从评分标准(即口语能力的各个方面)给出若干项分数,然后根据各项评分标准上的分数算出最后得分,如大学英语四、六级考试的口试。此外,口语测试往往包含多项任务,为了在评分过程中更好地体现任务特征,有时评分员会基于考生在每项任务上的具体表现,结合评分标准分别给出分数,然后根据各项任务上的分数算出最后得分[4],即任务评分,如托福口试。任务评分还可以进一步分为任务整体评分(每项任务只有一个整体评分标准)和任务分项评分(每项任务有多项评分标准)。
以往研究表明,不同的评分方式会影响评分员评分[5]。整体评分和分项评分是行为表现评估中最常采用的评分方式,因此有不少关于两者的对比研究[6],而针对任务评分的研究则相对较少[7]。另外,有关评分方式的对比研究多见于写作测试,而关于口试评分方式的研究相对较少。
本研究参考中国英语能力等级量表,设计了分项评分和任务评分两种方式,分项评分以考生整场口试的综合表现为评分依据,任务评分以考生在每项口试任务上的具体表现为评分依据。采用多面Rasch分析、概化分析、描述性统计分析和相关分析等方法,从评分员、评分标准、考生能力三个层面,对分项评分和任务评分进行综合对比分析,以探索两种评分方式在实际应用中的区别和联系。
(三)多面Rasch分析
多面Rasch分析主要应用于主观性评价的客观化分析[8],是进行评分效应研究的重要手段。在口试评分研究中,多面Rasch分析认为测试结果受评分员、评分标准、考生能力三者共同影响,并将这三者放在同一能力量尺上进行比较,从而不仅可以估计评分员严厉程度的差异,并能够校正这种差异对测试结果的影响,还能够分析评分标准和考生能力不同所导致的差异。
(四)概化分析
经典测量理论可以通过信度系数来衡量测试结果的稳定性程度,以及反映测试过程中所存在的随机误差大小程度[9],但却无法有效地分离各种误差的来源,这是其在实际应用中的缺陷之一。概化理论用“概化系数”代替经典测量理论中的信度指标,指一项测试的受试者得分的平均分在所有条件下概括的精确性,或者从样本到可接受的观察全域的概括程度[10]。针对经典测量理论无法有效分离各种测量误差的缺点,概化理论通过方差分析将各类误差的方差进行了分离,从而可以直接比较不同方差成分的大小。此外,概化理论不仅能够对主效应进行评估,还能对交互作用效应进行评估,这一估算各项方差成分相对大小的过程,被称为概化理论的概化研究阶段或者G研究阶段。此外,概化理论还可以通过实验性分析模拟出不同条件下概化系数的变化情况,为设计决策提供参考,这个过程被称为概化理论的决策研究阶段或者D研究阶段。
二、研究设计
(一)研究问题
本研究主要从定量角度回答以下3个问题:
(1)两种评分方式对整体统计分析结果有何影响?
(2)两种评分方式对评分员严厉程度、评分标准使用、考生能力区分有何影响?
(3)两种评分方式对考试分数差异来源有何影响?
(二)测试任务
本评分研究(针对某试验性机考口试)包含4项测试任务:朗读短文、听录音后回答问题、阅读短文后发表评论、两人讨论。其中前三项任务由考生独立完成,最后一项为交互性任务,由考生随机配对完成。
为了从地域、学科、水平等方面保证样本的代表性,参加本次机考口试的考生来自11所高校,地域上涵盖华北、华东、中南、西南片区,专业上覆盖综合类、理工、政法、财经等学科类型,有效样本共925份。
(三)评分设计
本研究设计了两种评分方式:分项评分和任务评分。分项评分根据考生整场口试的表现,分别从5项评分标准上进行打分,包括语音清晰度、语法准确度、内容相关度、语篇连贯度、策略灵活度。任务评分根据考生在每项口试任务上的具体表现进行打分:朗读短文任务包括语音语调一项评分标准,回答问题任务包括词汇语法、口头叙述两项评分标准,发表评论任务包括语法语篇、口头论述、表达策略三项评分标准,两人讨论任务包括词汇句法、口头互动、讨论策略三项评分标准。两种评分方式每项评分标准的打分区间均为0~4分(不设半分),考生总分为各项评分标准或任务得分之和,因此分项评分满分为20,任务评分满分为36。
本次机考口试评分共有32名评分员参加,来自东北某省份的985高校。他们都有丰富的口试阅卷经验,连续参加近3年大规模口试的评分工作(如大学英语四、六级机考口试)。评分员先采用分项评分,再采用任务评分。为避免评分员差异对研究结果造成影响,采用任务评分时,每位评分员都需要评阅所有4项任务。
评分时采用双评的方式,即每位考生的作答都由两位评分员评阅,两人所给总分的平均分为考生最终成绩。当两位评分员所给分数差异超过阈值时,则由评分组长进行仲裁。采用分项评分时,各项评分标准分差阈值为4分;采用任务评分时,朗读短文任务分差阈值为1分,回答问题任务分差阈值为2分,其余两项任务分差阈值均为3分。此外,由于采用双评的方式,考生最终成绩有可能不是整数。
为便于进行更加深入的数据分析,本次评分还从考生作答样本中抽取了30份代表不同口语水平的锚卷,将其随机派送给32位评分员,每位评分员都需要用两种评分方式评阅每份锚卷。
(四)数据分析
本研究采用SPSS 20软件进行描述性统计分析和相关分析,数据来源为全体考生样本(925份);采用FACETS软件进行多面Rasch分析,使用了包括评分员、评分标准、考生三个侧面的测量模型[11];采用EduG 6.1软件进行概化分析。多面Rasch分析和概化分析的数据来源为锚卷样本(30份)。此外,在评分工作结束之后,笔者还对评分员进行了访谈。
三、结果分析
(一)描述性统计分析
采用分项评分时,考生总分平均分为11.44,得分率为57.20%,标准差为2.52。考生在各项评分标准上的得分率最高的是语音清晰度(59.75%),最低的是语法准确度(55.25%)。
采用任务评分时,考生总分平均分为20.59,得分率为57.19%,标准差为3.84。考生在4项任务上的得分率最高的是朗读短文(60.25%),最低的是回答问题(55.25%)。考生在各任务所包含的评分标准上的得分率最高的是语音语调(60.25%),最低的是词汇语法(54.75%)。
对比两种评分方式的总分得分率可以看到两者几乎是一样的。具体到各项评分标准上的得分率,虽然两种评分方式各不相同,但大致可以看出考生在语音等方面表现较好,而在语法等方面表现稍逊一筹。
(二)相关性分析
分项评分内部相关性(即各分项之间的相关程度)见表1。从中可以看出,分项评分的内部相关性在0.60到0.71之间(p<0.01),说明评分员能较好地将各项评分标准区分开,并没有出现明显的“晕轮效应”[12]。

表1 分项评分内部相关性
任务评分内部相关性(即各项任务之间的相关程度)见表2。从中可以看出,任务评分的内部相关性较低,介于0.39到0.48之间(p<0.01),这说明各项任务考查了考生不同方面的口语能力,而且评分员能将不同任务的考查目标比较清晰地区分开[13]。
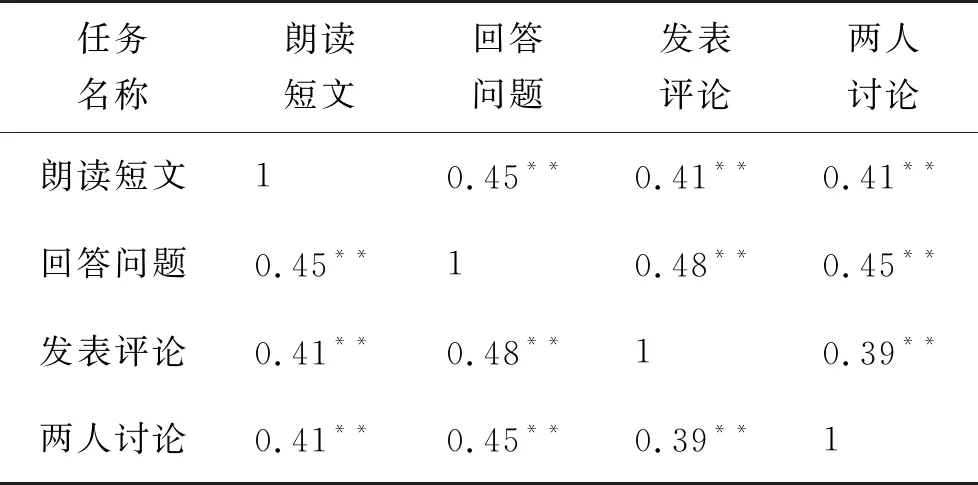
表2 任务评分内部相关性
进一步分析可知,两种评分方式在总分上的相关性为0.75(p<0.01),说明采用不同的评分方式对考生得分产生了一定的影响。虽然前文提到两种评分方式的总分得分率几乎相同,但在对考生口语能力的排序上还是存在一定差异的。
(三)多面Rasch分析
1.评分员侧面
分项评分的评分员侧面统计结果显示,32位评分员的严厉程度不一。17号和21号评分员最严厉(1.47 logits),28号评分员最宽松(-1.16 logits),最严厉和最宽松评分员之间严厉程度相差2.63 logits。所有评分员平均严厉程度为0 logits,标准差为0.68,其中有16位评分员的严厉程度小于0 logits,评卷尺度偏宽松。此外,分隔信度(reliability=0.95)、卡方系数(chi-square=596.7,p=0)、分隔比率(separation=4.22)也都表明评分员的严厉程度有显著差异。但所有评分员的加权均方拟合度(Infit Mnsq)都在可接受的拟合值范围之内(平均分±2SD)(McNamara, 1996),表明评分员评分具有良好的内部一致性,即每位评分员自身的严厉程度保持稳定,评分结果可信。
任务评分的评分员侧面统计结果显示,32位评分员采用任务评分时严厉程度也不一致。29号评分员最严厉(1.17 logits),11号评分员最宽松(-0.92 logits),最严厉和最宽松评分员之间严厉程度相差2.09 logits。评分员平均严厉程度为0 logits,标准差为0.45,有17位评分员的严厉程度小于0 logits,评卷尺度偏宽松。此外,分隔信度(reliability=0.95)、卡方系数(chi-square=607.2,p=0)、分隔比率(separation=4.24)也都表明评分员的严厉程度有显著差异。所有评分员的加权均方拟合度(Infit Mnsq)都在可接受的拟合值范围之内,表明评分员评分内部一致性良好,评分结果可信。
对比两种评分方式下的分隔比率,分项评分(separation=4.22)和任务评分(separation=4.24)十分接近,说明两种模式下评分员之间都存在严厉程度的差别,而且这种差别很接近,从多面Rasch的分析结果暂时看不出区别,需要进行概化分析才能比较出结果。
2.评分标准侧面
根据Rasch模型的估算,采用分项评分时,在各项评分标准中难度最高的是语法准确度(0.44 logits),最低的是语音清晰度(-0.50 logits),两者相差0.94 logits,平均难度为0 logits,标准差为0.30。采用任务评分时,在各项评分标准中难度最高的是表达策略(0.20 logits),最低的是语音语调(-0.38 logits),两者相差0.58 logits,平均难度为0 logits,标准差为0.17。标准差和难度差异的对比表明,任务评分各项标准之间难度差异小于分项评分。
多面Rasch分析还显示,无论使用哪种评分方式,评分员使用2分和3分的频率都是最高的,分项评分时评分员使用2分和3分的比例为77%,任务评分时该比例为79%,表明评分员打分时的趋中现象比较明显,这与以往有关评分标准的研究结论一致[14]。此外,除了趋中,这其实也反映出考生群体无论在整体口语能力还是在口语能力的不同侧面上均呈现“中间大、两头小”的特点,该现象符合一般的语言学习规律。
3.考生侧面
锚卷样本共包含30位考生。多面Rasch分析显示,采用分项评分时,12号考生口语水平最高(5.77 logits),20号考生口语水平最低(-2.13 logits),两者相差7.90 logits,说明考生口语水平有明显差异。考生平均能力值为1.28 logits,标准差为2.17。分隔信度(reliability=1.00)、卡方系数(chi-square=5903.1,p=0)、分隔比率(separation=14.22)表明分项评分能较好地区分不同层次口语水平的考生。采用任务评分时,12号考生口语水平最高(3.79 logits),20号考生口语水平最低(-1.66 logits),两者相差5.45 logits,考生平均能力值为0.63 logits,标准差为1.44,这些都表明考生口语水平有明显差异,但差异程度不如分项评分。分隔信度(reliability=1.00)、卡方系数(chi-square=6203.1,p=0)、分隔比率(separation=14.46)表明任务评分也能较好地区分不同层次口语水平的考生。
(四)概化分析
概化理论可以从宏观的角度对分数差异来源进行分析和对比。根据概化理论,测试结果的分数差异(即方差)有多种来源。具体到口语测试,分数差异分别来自评分员严厉程度、评分标准设置、考生能力等因素,以及这些因素的相互作用。因此,本研究基于锚卷样本的数据,通过评分员、评分标准、考生的完全交叉设计,用概化分析统计了方差来源(见表3)。概化理论包括概化研究(G研究)和决策研究(D研究)两种,出于研究目的,本文只进行概化研究。
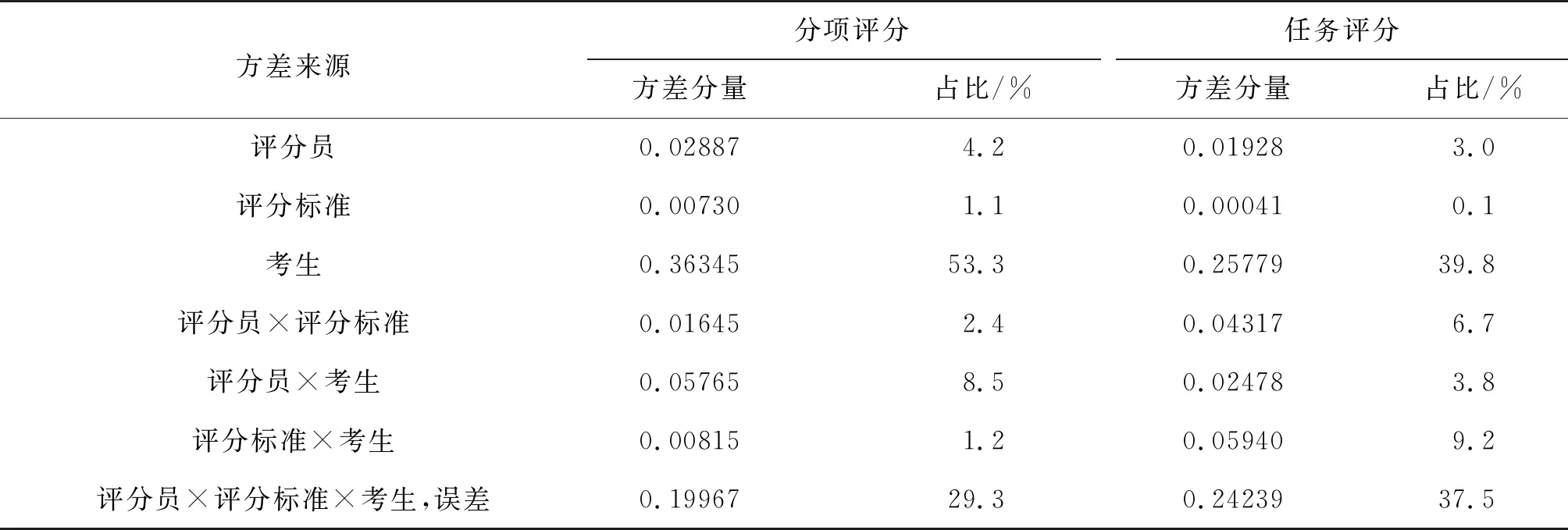
表3 方差来源统计结果
方差来源的统计结果显示,从占总方差的比重(占比)来看,两种评分方式最大的方差来源都是考生能力差异,说明考生能力差异是分数差异最主要的来源。采用分项评分时,考生能力差异占总方差的53.3%;采用任务评分时,考生能力差异占总方差的39.8%。可以看出,考生能力差异在分项评分中所占方差比重大于任务评分,说明分项评分对考生口语能力差异的区分程度高于任务评分。两种评分方式第二大方差分量都是评分员、评分标准、考生之间的交互效应及其他随机误差,任务评分中的占比(37.5%)高于分项评分中的占比(29.3%),说明任务评分的评分误差大于分项评分。
其他方差来源所占比重相对较小。分项评分中评分员和考生的交互效应占总方差的8.5%,而任务评分中只占3.8%,表明在不同评分员对同一考生的评分严厉程度差异方面,分项评分大于任务评分。分项评分中评分员严厉程度差异占总方差的4.2%,而任务评分中评分员严厉程度差异占总方差的3.0%,表明评分员对分项评分的影响大于对任务评分的影响。分项评分中评分员和评分标准交互效应在总方差中的占比(2.4%)小于任务评分中相应的占比(6.7%),表明不同评分员在对同一标准的严厉程度差异方面分项评分小于任务评分。分项评分中评分标准和考生的交互效应在总方差中的占比(1.2%)小于任务评分对应的占比(9.2%),表明同一考生在不同评分标准上体现出来的能力差异方面分项评分也小于任务评分。
(五)评分员访谈
评分工作结束之后,笔者对评分员进行了访谈,进一步了解他们对两种不同评分方式的使用感受,以及对评分方式设计的建议等。
在使用感受方面,评分员普遍认为分项评分更有利于从整体上评价考生的口语能力。在实际评分过程中,他们一般先对考生整体口语水平进行基本判断,而分项评分比较符合他们的评分习惯。由于评分员经常参与大学英语四、六级机考口试的评分工作,对分项评分方式更加熟悉,因此工作效率更高。此外,虽然以往研究指出分项评分可能忽略考生在不同任务上表现不均的情况[15],但有评分员认为自己在评分时会考虑任务完成度,当有些考生在个别任务上表现明显不同于其他任务时,评分员会进行综合考虑,再给出分数。
在设计建议方面,对于本研究中的任务评分,部分评分员认为它实际上也是一种分项评分,但和任务结合更加紧密。有的评分员认为,任务评分更加凸显任务设计的特点,评分过程更加聚焦,对于有些考查综合技能的任务,例如回答问题(听、说结合)和发表评论(读、说结合),这种评分方式增加了口语能力之外的因素对任务表现造成的影响,可能会对综合能力较弱的考生不利。还有的评分员指出,由于任务评分的过程更加聚焦、精细,当使用不同的试卷时,试卷差异给考生表现带来的影响可能会更加显著,这将给命题带来更大的挑战,特别是要谨慎评估考生对每个任务话题的熟悉程度,否则考生可能会因为在个别任务上表现不佳而明显影响整体得分。
此外,有评分员认为,双评的方式很大程度上会导致趋中现象,因为评分员都想避免自己的分数与他人相差过大而导致仲裁。也有评分员建议,双评是一种很好的评分质量监控手段,但其分差阈值不宜设置太小,否则评分趋中现象很可能更加明显。
四、结 论
基于多种数据分析结果和评分员访谈,关于分项评分和任务评分两种方式的对比研究主要有以下发现:
在分数可比性方面,虽然两种评分方式的总分得分率基本一样,对考生整体口语水平的排序存在一定差异。这种差异可能主要来源于评分标准设置上的差异:首先,分项评分有5项标准,任务评分则有9项标准,相比较而言任务评分对口语能力不同方面的区分更为细致;其次,分项评分的5项标准区别明显,而任务评分的9项标准中有些比较接近,比如语法和口头表达方面的标准就有6项,这使得语法和口头表达方面的分数在任务评分中占了较大的比重。
在评分员一致性方面,两种评分方式下评分员评分都具有良好的内部一致性,但评分员之间也存在严厉程度不一致的问题,这与以往大部分研究结论类似[16]。总体而言,分项评分时评分员的严厉程度差异大于任务评分。这可能是因为分项评分的标准数量比任务评分少,所以评分员严厉程度差异所造成的影响更加明显。
在评分标准方面,两种评分方式的各项标准难度都存在差异,但分项评分各项标准之间的难度差异比任务评分大。在评分标准的使用上,两种评分方式都存在明显的趋中现象,2分和3分使用最为频繁,且明显高于其他分数。这可能有三方面原因:首先,评分标准区间较小,评分员只能从0~4分的区间里选择分数,可选项不多,造成中间的两个分数使用频率较高。其次,由于采用了双评的方式,为了避免分差过大而进行仲裁,有些评分员便从策略上倾向于打中间分数。最后,大部分考生的口语表现处于中间水准,因此中间分数段使用频率比较高。至于主要原因是哪种,还需要利用定性研究等方法进一步探析。
在考生能力测量方面,考生口语水平差异在分项评分的总分变化中所占的比例高于任务评分,说明分项评分对不同层次口语水平的考生区分程度优于任务评分。在访谈中,有评分员提到,分项评分依据的是考生在整场口试中的表现,而任务评分依据的只是考生在具体任务上的表现,因此分项评分收集到的考生表现的依据相对更加充分,对考生能力的区分也更加准确。
从本研究的结果上看,分项评分在考生整体口语能力区分程度和测试结果的准确程度上都优于任务评分。此外,不同于以往的一些研究[17],本研究中分项评分各项标准没有出现明显的“晕轮效应”。这可能是因为评分员都有丰富的口试评分经验,而且对分项评分方式很熟悉,又经过了周密的培训,所以能清楚地区分各项标准的评判重点。
本研究的不足之处在于任务评分设计相对复杂,每个任务都包含了分项评分标准,而非针对任务采用整体评分。在今后的研究中,可按任务设计整体评分标准,再与分项评分进行对比,以更全面、深入地探析不同评分方式的特点。
