基于Faster R-CNN和数据增强的棉田苗期杂草识别方法∗
2021-07-24李开敬周建平樊湘鹏魏禹同
李开敬,许 燕,周建平,樊湘鹏,魏禹同
(新疆大学 机械工程学院,新疆 乌鲁木齐 830047)
0 引言
为了推动农业绿色发展,降低环境污染,越来越多的国内外学者提出将机器视觉与农业结合[1]的方式对农田中的杂草进行快速识别、分类,从而为农业除草剂的快速准确选择提供依据,减少农药的误用[2].机器视觉识别杂草主要利用杂草图像的纹理特征、形状特征、颜色特征[3−4]等综合信息来实现.机器视觉技术首先被纳入作物检测算法,以识别作物和杂草[5−6].Piron等[7]将结构光投影到图像采集区域,并与多光谱图像信息融合,从而提高多光谱视觉系统分辨作物和杂草的准确率,该方法对杂草的正确识别率为86%.Herrmann等[8]利用高光谱成像技术获取麦田图像,并设计了基于偏最小二乘法的分类器,分割小麦与杂草,对田间图像中苗、草的分类准确率大于72%.Jafari等[9]通过设定亮度阈值,将图像中的植物分成阴影部分和非阴影部分,在RGB空间内利用判别分析法分别对两个部分的作物和杂草进行分离.该方法对阳光下和阴影中的甜菜、杂草的分类准确率分别为88.5%和88.1%.然而在棉田中,由于作物与杂草的大小相类似,上述传统的机器视觉方法的有效性难以保证.目前,深度卷积神经网络方法取得了良好成效,2016 年,YOLO算法[10]将目标检测任务转换成一个回归问题,这样的单阶段检测的思路大幅提高了检测速度.在农业目标检测方面,孙哲[11]等以西兰花幼苗为研究对象,提出了一种基于Faster R-CNN模型的作物检测方法,在Dropout值为0.6的基础上以ResNet101网络为特征提取网络,达到了91.73%的平均精度.周云成等[12]提出一种基于深度卷积神经网络的番茄器官分类识别方法,在番茄器官图像数据集上,应用多种数据增强技术对网络进行训练,测试结果表明各网络的分类错误率均低于6.392%.上述识别方法主要是以农作物为研究对象,特征单一,识别对象多为单独个体.实际农田中普遍存在棉花幼苗与杂草交叉生长的现象.因此,为解决交叉生长环境下棉花幼苗与杂草的识别难题,本文以棉花幼苗和七种杂草为识别对象,提出基于Faster R-CNN和数据增强[13−15]的棉田苗期杂草识别方法.根据杂草的特点,优化网络模型,建立一种对多种杂草进行识别的适用型深度网络模型.
1 材料与方法
1.1 图像采集与建立
本文以棉花幼苗和田间的杂草(田旋花、灰绿藜、小蓟、硬草、马唐、马齿苋、播娘篙)作为识别对象.2019年5月至7月在新疆五家渠市102团2连的试验田,分12个阶段(每阶段相差5~8天),总共拍摄4 694张样本图像.拍摄使用索尼IMX386设备,采用垂直方式拍摄,距离地面70 cm,图像分辨率为1 079×1 157,格式为JPEG.为了研究不同光照影响下的各种杂草图像识别问题,分别在晴天、阴天、雨天进行了杂草图像采集.为使研究问题更加贴合实际,在采集样本图像前未对图像背景做任何人工处理.所采集的部分样本图像如图1所示,不同环境下所采集样本集数量如表1所示.采集到的样本中70%作为样本训练集,30%为测试集.

图1 杂草与棉花幼苗交叉生长Fig 1 Weeds and cotton seedlings cross growth
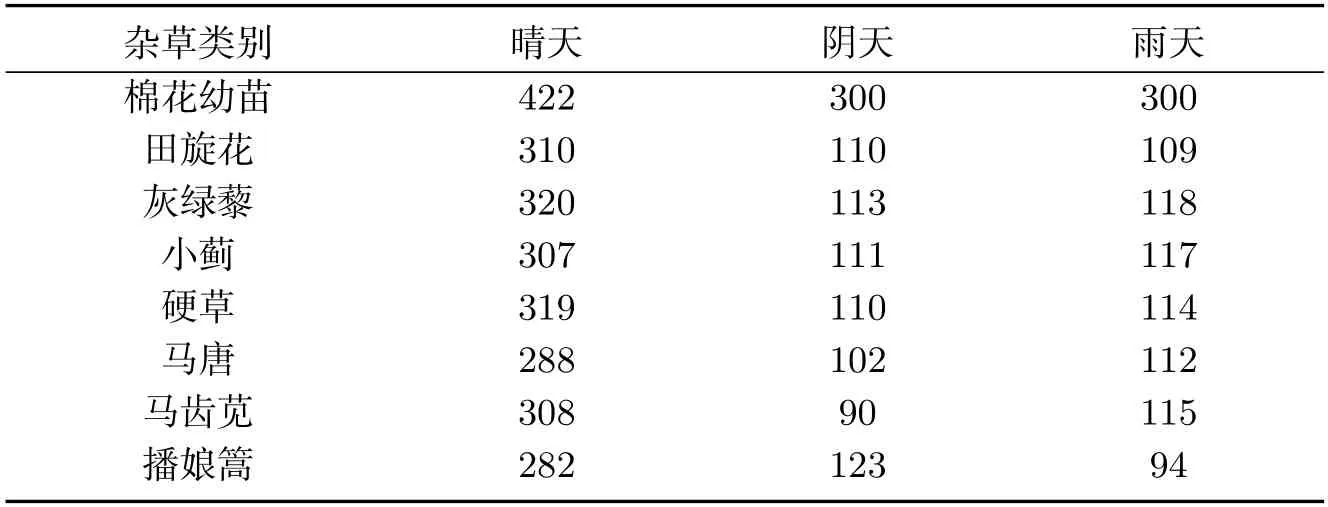
表1 不同环境下样本数量Tab 1 Number of samples in different environments
1.2 数据增强
为使Faster R-CNN模型达到更好的识别效果,需要在大量数据集基础上进行样本训练.手动收集的数据集有限,为了进一步丰富图像训练集,更好的提取图像特征,数据集可以通过数据增强技术扩展.主要是通过对样本图像进行平移、旋转、放缩、错切、垂直或者水平镜像等基本变换.在一些样本图像缺失的情况下,通过基本变换可以增加样本数量,而且还可以避免因为样本大小或者尺度等问题造成样本图像识别过程中出现的失真或过拟合等问题.另外,数据增强技术还通过增强样本图像的对比度,改变样本图像的亮度,消除一些图像噪音来改变图像的视觉效果.通过数据增强后,样本由最初的4 694张扩大到四倍,变成18 776张,对样本图像进行的数据增强具体方法如下:
(1)平移是将图像水平或者垂直移动一个相关因子,为了适应像素、拓展适应性,这里使用三位的向量组成三维矩阵为相关因子.然后,我们在任何情况下水平和垂直地移动图像,给定一个数字X,图像的宽度和长度将在区间[0,X]中选择一个随机因子移动.本文将X值设为10,对样本图像进行平移.
(2)缩放是把样本图像缩放到一定范围内.先给定值X,每个图像将在区间[1-X,1+X]中调整大小.本文将X值设为0.2,将样本图像进行缩放,以增加样本数量.
(3)旋转包括将图像随机旋转一定角度.同样给定值X,每个图像将以[0,X]的角度旋转.本文中对样本图像进行了0◦,45◦,90◦,135◦,180◦旋转.
(4)镜像就是水平或者垂直翻转.本文中的镜像是将方法(3)中旋转各自角度后的图像进行镜像.
(5)样本图像的饱和度和亮度调整主要是先计算图像的RGB像素均值-M,对图像的每个像素点Remove平均值-M,对去掉平均值以后的像素点P再乘以对比度系数.然后对处理以后的像素P加上M乘以亮度系统,对像素点RGB值完成重新赋值.
以小蓟与棉花幼苗交叉生长图像为例,通过上述方法得到的图像如图2所示.

图2 图像数据增强效果Fig 2 Data enhanced image effects
1.3 Faster R-CNN
Faster R-CNN网络是将RPN检测对象的关注区域进行分类,本文利用Faster R-CNN实现杂草与棉苗的识别分类,通过以下两个核心模块完成:(1)区域建议网络(RPN),用于识别可能包含关注对象的区域(ROI);(2)Fast R-CNN,用于对提取的区域建议进行分类并细化相应对象的边界框.这两部分共同使用和共享一组基本卷积层(转换层).激活函数(ReLU)和池化层用来提取图像特征映射,产生ROI.然后RPN输出到第一卷积层,再从第一卷积层产生的特征图中裁剪出相应的区域.使用SoftMax回归来确定锚点是属于前景或者背景,最后使用边界框回归来纠正锚点以获得准确的建议,同时获得检测框的最终精确位置.Faster R-CNN主要用于目标检测,其最大的亮点在于提出了一种有效定位目标区域的方法,然后按区域在特征图上进行特征索引,生成建议框.其流程变得越来越精简,精度越来越高,速度也越来越快.适用于复杂环境下的小型目标检测研究,因此本文选择Faster R-CNN算法对新疆复杂棉田环境中的幼苗与杂草分类.图3展示了棉花幼苗与杂草识别分类的技术路线.
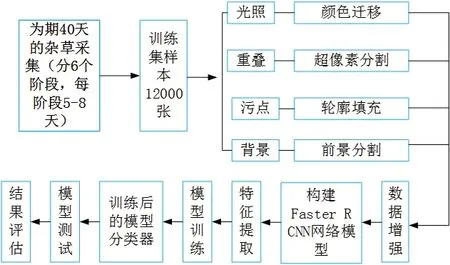
图3 技术路线Fig 3 Technical routes
在Faster R-CNN框架下,本文采用ResNet-101[16]网络作为特征提取网络,由于Resnet101网络具有跳跃连接操作,可实现特征重用,与使用单一卷积操作,网络从前到后依次进行特征提取的网络相比,可以减少在卷积过程中导致的信息丢失.因此,ResNet101网络对于其它特征提取网络而言,具有优异的性能表现.ResNet101网络前四个卷积神经网络被用作Faster R-CNN共享卷积层的初始化参数,以提取图像的特征,最后一级用作Fast R-CNN检测器的初始化参数.
1.4 锚(Anchor)
生成区域建议之前需要确定图像的最佳锚尺度.RPN以16像素的步幅评估图像每个位置的不同边界框,产生的不同边界框形成的盒子称为锚,其特征是由它们的比例(盒子面积)和纵横比决定.由于本研究中的对象大小不一且种类多,为了能够更好的检测识别到目标,本文测试了三种不同的纵横比,确定了纵横比1∶2与1∶1为锚的最佳尺度.虽然输入图像的像素为500×375,但网络会在最短的一侧将输入图像的大小调整为400像素.因此,最短边为400像素而不是375像素,如图4所示.

图4 测试锚点与图像大小进行比较Fig 4 Test anchor point compared to image size
2 结果与分析
整个实验过程的运行环境为Windows7(64位)操作系统,Anaconda 3.5.0,Python 3.5.6,CUDA 8.0,cuDNN 6.0,搭载Intel(R)Xeon(R)CPU E5-2630 v4@2.20GHz处理器.使用开源深度学习框架Tensorflow作为开发环境,计算机内存16GB.
为提升模型性能,减少过拟合,以本文预训练模型进行参数初始化设置,使用SGD(Stochastic Gradient Ddescent)随机梯度下降法改善模型.dropout设置为0.6,动量因子设置为0.9,最大迭代次数为60 000步,学习率最初设为0.01,迭代次数是20 000步时,降为0.001,40 000步时降为0.000 25,直到迭代次数达到最大值后停止训练.得到训练好的网络模型,使用测试集对模型效果进一步验证,输出识别结果.
由于不同评价指标对实验结果的评估意义不同,所以本文使用了常用的识别时间和精准率两种评估指标对实验结果进行评估.为了使实验更加简洁易懂,我们将使用表格将每一类数据的分类结果展示出来.其中识别时间,精准率定义如公式(1)、公式(2)所示:

式中:TP表示把正样本预测为正样本的样本数量;FP表示把负样本预测为正样本的样本数量,TP+FP表示预测为正样本的全部样本数量;t表示平均识别时间;T表示所有类别识别总时间;M表示所有类别图像总张数.
识别效果如图5所示,在目标较少的情况下可实现较高的识别率,目标较多的情况下识别率虽然有所下降,但仍可保持在90%以上.图中出现识别率较差的情况主要是由于棉花叶片受病害影响,造成叶片信息不全,从而导致识别率有所下降.试验结果表明:Faster R-CNN模型在新疆复杂棉田环境下,对伴生的棉苗与杂草都实现了较高的识别率.

图5 杂草与棉花幼苗交叉识别Fig 5 Identification of weeds and cotton seedlings
为研究杂草识别过程中光照环境对识别率的影响,对不同天气,不同光照影响下的相同杂草进行同等数量划分,晴天、阴天和雨天的不同杂草图像各1 000张,将以上图像分别采用之前训练好的分类器进行识别.由表2可以看出识别时间分别为0.28 s、0.34 s和0.359 s,识别率分别为96.02%、92.77%和90.34%,即雨天环境下的识别时间最长且识别率最低,在晴天环境下识别时间最短且识别率最高,其效果最佳.

表2 不同光照影响下的杂草识别率Tab 2 Weed recognition rate under different illumination
为了充分体现所使用方法的有效性,在保证相同的图像处理方法和ResNet101特征提取网络下进行Faster R-CNN模型与YOLO模型进行比较,两种方法的损失(Loss)曲线(无量纲)和精度(precision)(无量纲)随迭代次数的变化情况如图6所示,两种模型的最终试验结果如表3所示.在精度方面,Faster R-CNN的精度曲线始终处在YOLO方法的精度上方,准确性明显高于YOLO模型方法,Faster R-CNN的最终识别率可达92.01%,而YOLO模型方法的最终识别率为89.47%;在损失值方面,Faster R-CNN收敛更快,且较为平缓,损失值低于YOLO方法的损失值.Faster R-CNN模型的平均识别时间为0.261 s,在单张图像检测上,比YOLO模型方法节省53 ms.这是因为Faster R-CNN模型采用RPN(Region Proposal Network)代替选择性搜索(Selective Search),利用GPU进行计算大幅度缩减提取region proposal的速度并优化了建议区域的产生方式,实现端到端训练,从而缩短了识别时间、提高了识别效率,对田间杂草的识别性能更优.试验表明,Faster R-CNN模型比YOLO模型更适用于棉花幼苗与多种类杂草交叉生长的识别研究.

表3 两种方法试验结果对比Tab 3 Comparison of experimental results of two methods
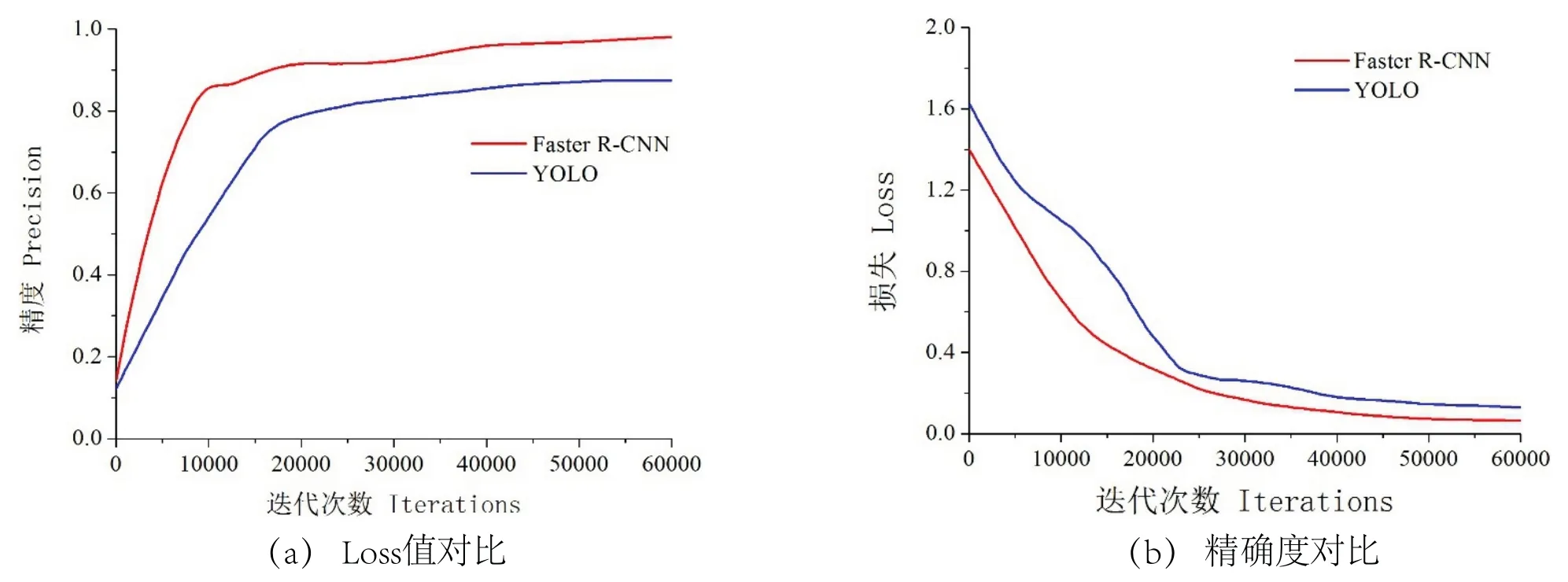
图6 两种方法的损失及精度对比Fig 6 Comparison of loss and precision of two methods
3 结论
本文针对不同光照环境下的各种杂草图像提出了基于数据增强和Faster R-CNN的棉田苗期杂草识别方法,得到如下结论.
(1)采用数据增强增加杂草的多样性和样本数量.通过Faster R-CNN模型对样本图像进行训练,能够将与棉花幼苗交叉生长的各种杂草进行定位、识别和分类,增强了模型的识别能力.
(2)通过对比各种光照影响下的杂草识别率,得出雨天对杂草识别率的影响最大.晴天识别效果最佳,且识别率最高.将Faster R-CNN与YOLO进行比较,可知本文方法识别率较好,平均识别率为92.01%,明显优于YOLO方法.
