一种改进的广域网低延迟分布式共识算法
2021-07-21牛保宁张栩豪
弓 婷,牛保宁,张栩豪
(太原理工大学 信息与计算机学院,山西 晋中 030600)
目前,Paxos[1]及其改进算法[2-9]已经被应用到全球式分布式系统[10-11]中。Multi-Paxos[12]是Paxos的改进算法之一,分两阶段执行,在第一阶段的准备阶段(Prepare phase),发起共识请求的节点(proposer)广播被赋予唯一编号的提案。收到提案的节点(acceptors)判断当前提案的提案号是否最高,若是,则向proposer回复同意信息,否则不同意该提案。proposer获得多数(51%)acceptors同意后,被确定为Leader,进入第二阶段。回复同意信息的acceptors构成第一阶段Quorum(Q1).在第二阶段的接受阶段(Accept phase),Leader将含有提案值的提案发送给acceptors.提案值获得多数acceptors同意后,对该提案值达成共识。回复同意提案值的acceptors构成第二阶段Quorum(Q2).Leader可以连续多次执行算法的第二阶段,确定多个命令。现有应用于广域网的分布式共识算法大多是以Multi-Paxos为基础。
在广域网中,分布式系统的节点被部署在各个不同的地理位置,通常以国家或地区为单位划分区域。Multi-Paxos的执行需要大量的跨区域通信,每个命令达成共识的延迟L由两部分构成:客户端与服务器节点(proposer或Leader)间的通信延迟Lc、服务器节点执行Multi-Paxos的延迟Le.由分析达成共识的过程可知,延迟最大的部分是Le.当系统中无固定Leader时,Le由第一阶段的延迟L1和第二阶段的延迟L2构成;当系统中有Leader时,Le主要由L2构成。减小共识延迟L的关键在于减小L1和L2.在此基础上,通过减小Lc可进一步减小L.
广域网中的通信代价是共识延迟的主要原因,Q1和Q2节点数量越少,L1和L2就越小。Quorum相交要求是保证算法安全性要求的关键,算法的安全性要求是指算法两阶段确定的提案值是唯一的。现有算法对Quorum的改进思路主要是减少Q2节点数量,增加Q1节点数量。在Leader频繁转移的系统中,Q1节点数量增大,导致第一阶段的执行代价也随之增加。
Lc的大小受客户端与服务器节点间的距离影响。若系统中无Leader,则客户端所在区域的节点发起第一阶段提案,成为Leader,Lc几乎为0.若当前系统有Leader,且与客户端不在同一区域,则会产生较大的Lc.在这种情况下,产生大量的跨区通信,导致通信延迟增加;当客户端频繁发起对某个数据操作的命令请求,产生所谓的hot-key现象,通信延迟更加严重。在Leader的改进方面,现有算法主要关注于Multi-Paxos中存在的单Leader瓶颈,采用Leader-Less和Multi-Leader方案,不考虑客户端与Leader之间的位置关系。如果能够动态优化Leader所在位置,使得Leader与发起操作的客户端处于同一区域,可以减少跨区通信,降低共识延迟及hot-key现象。
针对上述第一阶段执行代价大、Leader与客户端的位置关系问题,本文提出一种适用于广域网的分布式共识算法SQPaxos,分别从Quorum构成策略和Leader分配策略上对现有算法进行改进。本文的创新点总结如下:
1) 针对算法使用的Quorum,提出了最小Quorum实现方案。在Quorum的大小方面,根据系统容错能力和算法安全性要求,计算出两阶段所需的最小Quorum节点数量。在Quorum节点构成方面,考虑到提案号的唯一性,提出建立提案号与节点编号之间的映射关系。根据提案号为该提案分配固定的节点集,构成两阶段的Quorum,满足Quorum相交要求。
2) 针对客户端与Leader之间的延迟问题,提出自适应的Multi-Leader方案,为数据对象划分Leader,每个数据对象最多有一个Leader,实现不同数据对象的并行处理。同时优化客户端与Leader之间的位置关系,当所有区域的客户端对某个数据对象的操作次数超过某个固定值后,根据各区域客户端对该数据对象的操作频率,将Leader转移至操作频率最高的区域中。
1 相关工作
现有的广域网分布式共识算法大多是对Multi-Paxos的改进,主要针对Quorum构成和Leader分配进行改进。
在Quorum方面,现有算法提出不同的Quorum相交要求,主要思路是在满足算法安全性要求的基础上,减小Q1和Q2.这些算法实现了最小化Q2,却没有实现最小化Q1.目前有3种Quorum相交方案:Majority Quorum(Paxos[1]、Multi-Paxos[12])、Flexible Quorum(FPaxos)[13]、Expanding Quorum(DPaxos)[14].Majority Quorum的主要思想是保证任意两个Quorum相交不为空,由系统中的多数(51%)节点分别构成Q1和Q2.这是保证Quorum相交最直观的方式,但是这种方式导致达成共识的过程中通信节点数量多,广域网共识延迟大。Flexible Quorum要求不同阶段的Quorum相交,根据Multi-Paxos第二阶段使用频率比第一阶段高的事实,通过减少Q2节点数量,同时增加Q1节点数量,以降低总的延迟。但增大Q1,导致第一阶段选举Leader的代价增加。Expanding Quorum要求当前提案使用的Q1与之前提案使用的第二阶段Quorum(Q2′) 相交,proposer提前声明提案将使用的Q2,将提案与自己的Q2绑定在一起,方便其他提案获取当前提案Q2的同时,也方便当前提案通过该方法获取其他提案的Q2′.最坏情况下,DPaxos的第一阶段需要两轮广域网通信,导致Q1的节点数量增加。另外,提前声明Q2的方法增加了通信复杂度。
本文使用基于分区的Quorum模型实现Quorum相交方案,提出建立提案号与Quorum节点间的映射,根据提案号分配Q1和Q2节点,当前提案在发起第一阶段提案之前,获取到之前提案的Q2′,并将这些节点加入当前提案的Q1中,使用一轮通信完成第一阶段,实现了最小的Q1和Q2.
在Leader分配问题方面,现有的改进算法采用Leader-Less(EPaxos)[15]和Multi-Leader两种方法,其中Multi-Leader包括划分序列块领导权(Mencius)[16]和划分数据对象领导权两种实现方案。Leader-Less是由EPaxos提出的方案,所有节点都可以接收客户端命令,在各节点处理的数据对象不冲突的情况下只需要一轮通信就能达成共识,但是如果命令发生冲突,需要解决冲突,导致延迟增加。Mencius提出为节点划分命令序列实现Multi-Leader,节点轮流当命令序列中序列块的Leader,这种方法有效解决了Leader与其他节点负载不均衡的问题,但算法整体性能受单个节点处理能力影响。另一种Multi-Leader实现方案是将数据对象的领导权划分给不同节点,不同数据对象的提案可以并行处理,在此基础上,WPaxos[17]以定时转换的方法转移领导权,存在Leader转移不及时的问题。对此,本文提出了自适应划分数据对象的Multi-Leader方案。
2 SQPaxos算法
SQPaxos通过最小化两阶段Quorum节点数量和自适应转移Leader来降低共识延迟。围绕以上途径,2.1节介绍最小化Q1和Q2的思路;2.2节按照该思路,介绍如何构成Quorum;2.3节介绍如何自适应地转移Leader.
2.1 最小化Q1和Q2的思路
最小化Q1和Q2节点数量的前提是满足算法安全性和系统的容错要求。在此基础上,按照区域节点的分布选择节点,构成Q1和Q2,实现最小化Quorum.
基于分区的Quorum模型将系统中的节点划分到不同区域,模型如图1所示。为方便描述,不妨假设各区域的节点数量一样,圆代表节点,列代表区域。Q1的任务是选举Leader,为保证同一时刻,系统中的每个数据对象至多有一个Leader,要求任意两个Q1至少有一个公共节点,因此最小的Q1应该由系统中的多数区域,以及这些区域中的多数节点构成。对于Q2,需要满足系统的容错要求,即大于系统能够容忍的最大区域故障数和区域内的节点故障数。区域故障是指区域中的所有节点都不可用。除遭遇自然灾害,一般情况下,不会发生区域故障,因此Q2应该尽量由Leader所在区域内节点构成。如图1,系统中有8个区域Z1-Z8,每个区域中有5个节点,如图中实线框所示,最小的Q1由5个区域组成,每个区域中选择3个节点。注意,此时Q1中节点的数量是15个,少于全部节点数量(40)的一半。假定系统容错模型是最多允许0个区域故障,区域中允许1个节点故障,则如图中虚线框所示,最小的Q2由1个区域中的2个节点构成。
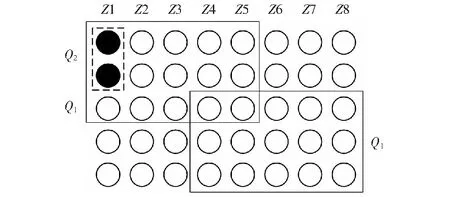
图1 分区Quorum模型Fig.1 Partitioned Quorum model
最小Q1和Q2不能保证两者相交,需要通过选择用哪些节点构成Q1和Q2来保证。按照DPaxos的Quorum相交要求,当前提案使用的Q1与之前提案使用的Q2′相交,这样做可以保证算法第一阶段的任务的正确完成。一是判断当前提案的提案号是否是最高提案号,只有提案号最高的提案才能继续执行算法;二是为了获取已经被acceptors接受的提案,proposer从这些提案中,选择具有最高提案号的提案值,将该值作为自己第二阶段的提案值。这提示我们:如果可以预先确定最高提案的Q2′的节点,就可以确定Q1.选举Leader时,把Q2′的至少一个节点作为Q1的节点,获取提案值,满足Q1与Q2′相交。因此,本文首先确定Q2,在此基础上确定Q1.
对于Q2的确定,我们注意到每个提案的提案号是唯一的,可以建立提案号与节点编号间的映射关系。也就是说,根据提案号,可以预先确定Q2的节点,从而按照上述思路为提案分配满足系统容错要求的Q2.需要注意的是,该映射关系为不同提案号分配不同的Q2节点,具有负载均衡的作用。
对于Q1的确定,根据上述分析,Q1应该包含Q2′中的至少一个节点。通过上一段的分析可知,满足该要求的关键是:新提案的proposer能及时获取到之前提案的提案号。实际上,新提案只需要获取到完成第一阶段并且开始第二阶段的提案中提案号最高的提案,而不是所有之前提案的提案号。因为这些提案中包含了第一阶段未成功执行和第二阶段未成功执行的提案以及过时的提案。为方便获取有效提案的提案号,可以为每个数据对象设立一个数据项BM,用来存放有效提案号。新提案可以直接获取BM,根据提案号与节点编号的映射关系,获取BM对应的Q2′,将其加入自己的Q1中。
上面分析了最小化Q1和Q2、并保证两者相交的思路。下面我们分析在优化Quorum的基础上,减少Leader与客户端间延迟的思路。要减少Leader与客户端间的延迟,需要分配与客户端相近的节点做Leader,即预测hot-key所在区域,自适应转移Leader.预测hot-key所在区域,可以通过统计各区域的客户端操作当前数据对象的命令数量,当Leader处理的总命令数量超过允许处理的最大数OP时,将领导权转移至发起操作命令最频繁的区域中。
为方便描述,给出以下符号,如表1所示。

表1 符号表Table 1 Symbol table
2.2 最小化Quorum
本节的讨论基于以下分区Quorum模型:一个分布式系统由N个节点构成,节点分布在Z个不同的区域中,假定各区域内的节点数量一致,为NZ,即
N=Z×NZ.
(1)
根据系统容错性,要求Z≥2ZF+1;NZ≥2NF+1.其中ZF和NF是用户自定义的容错标准。
根据上节的分析,为满足Quorum相交要求,proposer在第一阶段开始之前,获取BM使用过的Q2′,将这些节点加入本次提案的Q1中,保证相交。因此,我们先给出确定Q2的方案,在此基础上,再介绍如何构成Q1.
2.2.1第二阶段Quorum
为方便新提案获取之前使用过的Q2′,提出建立提案号与Q2节点之间的映射关系。提案号B由数值部分Bi和发起该提案的全局节点编号I组成,其中Bi是不断递增的数值,I由区域号IZ和区域内的节点编号IN组成,即B=Bi.I,I=IZ.IN.
第二阶段Quorum节点构成规则:
1) 确定区域,选择ZF+1个区域。若ZF=0,则Q2由Leader所在区域的节点构成;若ZF≠0,则Q2由Leader及离Leader近的ZF+1个区域中的节点构成;
2) 确定区域内节点数,在以上区域中选择NF+1个节点;
3) 选择节点,为保证各区域内节点的负载均衡,Leader根据Bi,选择以IN开始的NF+1个节点,其中
IN=[1+(Bi-1)(ZF+1)] .
(2)
例如,当系统模型为Z=8,NZ=5,ZF=0,NF=1时,每个提案的Q2由1个区域及该区域中的2个节点构成,即
|Q2|=(ZF+1)(NF+1)=1×2 .
(3)
根据提案号B=1.1.1可知Bi=1,I=1.1,分配区域号IZ=1开始的1个区域,由公式(2)计算出,在该区域中选择节点编号IN=1开始的2个节点,即Q21.1.1={1.1,1.2}.
2.2.2第一阶段Quorum
本节介绍Q1节点构成方法。为了保证系统中的每个数据对象在同一时刻最多只有一个Leader,Q1由多数区域中的多数节点构成,即
|Q1|=(Z/2+1)(NZ/2+1) .
(4)
发起第一阶段提案的proposer节点为候选Leader,候选Leader在发送第一阶段提案之前,先获取BM,根据第二阶段Quorum节点构成规则,获取到该提案的Q2′.
第一阶段Quorum节点构成规则:
1) 确定区域,Q1由Z/2+1个区域构成。当|Q2′|≥|Q1|时,将Q2′作为新提案的Q1;当Q2′的区域数ZF+1 2) 确定区域内节点数,每个区域由NZ/2+1个节点构成。当Q2′各区域内的节点数量NF+1 3) 选择节点,为实现区域内节点的负载均衡,选择以IN开始的NZ/2+1个节点,其中 IN=[1+(Bi-1)(NZ/2+1)] . (5) 例如,系统模型为Z=8,NZ=5,ZF=0,NF=1时,|Q2|=1×2,|Q1|=5×3.假设之前的提案号B=1.1.1,该提案使用的Q21.1.1={1.1,1.2}.当节点1.1完成提案后,区域5中的节点5.1发起第一阶段提案,成为候选Leader,节点5.1提出的提案号B=2.5.1,即Bi=2,IZ=5,IN=1,如图2所示,提案2.5.1的Q1由提案1.1.1的Q2和其他节点构成,首先获取B=1.1.1的Q21.1.1,Q2区域中的节点数为2,小于Q1区域中的节点数3,需要再扩展1个节点。除Q21.1.1包含的1个区域外,提案2.5.1还需要选择距离区域5近的其余4个区域:5、6、7、8,根据公式(5),在每个区域中选择以IN=4开始的3个节点,故Q12.5.1={1.1,1.2,1.3,5.4,5.5,5.1,6.4,6.5,6.1,7.4,7.5,7.1,8.4,8.5,8.1}. 图2 Q1的构成Fig.2 Composition of Q1 本节介绍在使用划分数据对象领导权方法实现Multi-Leader的基础上,将Leader自适应转移至操作频率较高的区域的机制。 Leader自适应转移规则如下:在Leader拥有数据对象领导权的期间,统计各区域对该数据对象的操作次数,当总操作次数超过固定值OP后,自适应地调整Leader的位置,将领导权转移至操作频率最高的区域中,由该区域中的节点发起第一阶段提案,申请成为Leader,获取领导权。OP的大小由请求流量、系统基本运行情况及Leader故障频率等参数共同决定,不同数据对象可设置不同的OP. 本节通过实验验证SQPaxos在Quorum性能和Leader性能两方面的有效性,其中Quorum性能是指在不改变Leader分配等其他配置的情况下,测试算法使用不同的Quorum构成策略时所需的共识延迟;Leader性能是指在不改变Quorum等其他配置的情况下,测试算法使用不同Leader分配策略时所需的共识延迟。 实验环境:本节模拟系统节点部署在加利福尼亚(CA)、俄勒冈州(OR)、弗吉尼亚(VI)、东京(TK)、爱尔兰(IRE) 5个不同的区域中,每个区域配置3个节点。节点配置如下:64位Ubuntu 18.04操作系统,2个CPU,8G内存。 测试指标:测试在系统平稳运行的状态下,算法对请求达成共识的平均响应延迟,包括算法整体、第一阶段Q1、第二阶段Q2,以及在不同的数据分布模式下使用Leader分配机制时的延迟表现。其中,响应延迟是指从客户端发起请求开始,到服务器对该请求达成共识,并向客户端返回结果结束,整个过程花费的时间一般以毫秒(ms)为单位。本节给出了算法在各区域的第95百分位数(95thpercentile)延迟,以表明平均延迟的有效性。 测试方法:采用YCSB Benchmark随机选择数据对象生成命令请求,生成的请求中,50%为读操作请求,50%为写操作请求,数据池中共有1 000个数据对象,对比各算法对请求达成共识的平均延迟测试算法性能。 度量标准:在保证数据一致的前提下,达成共识的速度越快,算法性能越好。通过检查各节点的工作日志确认数据的一致性,在此基础上,对比各算法达成共识的平均延迟,比较算法的优劣。 平均延迟是共识算法性能最直观的表现,其大小受节点规模、节点间的距离、通信轮次等因素的影响。首先,当前阶段需要通信的节点规模决定了该阶段的延迟。例如,SQPaxos的Q1大小为3个区域,每个区域2个节点,则将各区域内节点与候选Leader间的延迟按递增顺序排序后,第3小的区域内第2小的延迟影响了SQPaxos第一阶段的性能。因此,Quorum节点规模越小,延迟就越低。其次,节点间的距离以及客户端与Leader间的距离越近,延迟就越低。最后,广域网环境下,每一轮通信都会产生较大的延迟,通信次数越少,延迟就越低。例如,Multi-Paxos的第一阶段需要一轮通信即可选出Leader,而DPaxos的第一阶段使用第一轮通信中获取Q2′后,再发起第二轮通信。因此,DPaxos的第一阶段延迟高于Multi-Paxos. 对比算法:对于Quorum性能测试方面,分别对比SQPaxos、Multi-Paxos、FPaxos和DPaxos使用第一阶段转移Leader和使用第二阶段确定提案内容时所需的延迟;同时,对比系统正常运行时,各算法的整体延迟表现;对于Leader性能测试方面,对比在多种数据分布模式下,使用Multi-Leader自适应转移方案的SQPaxos、未使用Multi-Leader自适应转移方案的SQPaxos、使用定时Leader转移方案的WPaxos以及实现Leader-Less方案的EPaxos算法的延迟表现。 3.2.1整体性能 在Multi-Leader模式下,分别对比容错模式为ZF=0,NF=1时,SQPaxos、FPaxos、DPaxos、Multi-Paxos的延迟性能,结果如图3所示,其中柱状图表示平均延迟,误差线表示将所有请求的共识延迟排序后,第95%位延迟的大小。在本实验配置环境下,SQPaxos的第一阶段Q1大小为3个区域,每个区域2个节点(3×2),比FPaxos(5×2)和DPaxos(4×2)小,第二阶段Q2大小为1个区域中的2个节点(1×2),比Multi-Paxos(3×2)小,因此,SQPaxos的平均延迟均低于以上算法。实验结果表明,SQPaxos的平均延迟比FPaxos、DPaxos、Multi-Paxos分别低47.1%、39.6%、53.9%. 图3 整体性能Fig.3 Overall performance 3.2.2第一阶段Quorum性能 实验采用不固定Leader的方法,对比ZF=0,NF=1时,SQPaxos、FPaxos、DPaxos、Multi-Paxos转移Leader所需的第一阶段平均延迟,结果如图4所示。SQPaxos和Multi-Paxos的Q1大小一样,均为3个区域,每个区域2个节点(3×2),比DPaxos(4×2)和FPaxos(5×2)小,因此SQPaxos和Multi-Paxos的延迟低于以上两种算法。 图4 第一阶段Quorum性能Fig.4 Performance of Q1 SQPaxos的延迟略低于Multi-Paxos,因其将请求发送给固定节点集,而不是广播给所有节点,减少了通信量。综上,SQPaxos的第一阶段平均延迟比FPaxos、DPaxos、Multi-Paxos分别低47.6%、57.9%、6.0%. 3.2.3第二阶段Quorum性能 在确定Leader后,Leader可以连续多次执行第二阶段,对多个请求达成共识。本次实验将Leader分别固定在不同区域,测试各算法使用不同Q2时所需要的共识延迟,结果如图5所示。当容错模型为ZF=0,NF=1时,SQPaxos、FPaxos、DPaxos的Q2均为1个区域中的2个节点(1×2),Multi-Paxos的Q2不受容错模型影响,为3个区域,每个区域2个节点(3×2).SQPaxos的Q2比Multi-Paxos小,并且SQPaxos直接将请求发送给固定的目标Quorum,而不是广播给所有节点,减少了通信量,因此SQPaxos的第二阶段Q2性能优于其他算法。实验结果表明,SQPaxos的第二阶段平均延迟,比FPaxos、DPaxos、Multi-Paxos分别降低了3.9%、3.8%、93.8%. 图5 第二阶段Quorum性能Fig.5 Performance of Q2 由以上三组实验可知,实现最小化两阶段Quorum能够有效降低广域网共识延迟。 本文提出自适应Leader分配机制,减少达成共识的延迟。每个Leader最多允许处理OP个请求,当请求数量超过OP后,自动将数据对象的领导权转移至请求操作次数最多的区域中。 为了增强对比效果,算法的并行度为5,即Leader可同时处理5个数据对象的请求,并且设置了两种不同的OP值:OP=1 000、OP=10 000.测试在数据对象均匀分布模式(uniform distribution)、客户端请求操作的数据对象与本区域拥有的数据对象匹配度为70%(Maturity=70%)以及匹配度为90%(Maturity=90%)三种模式下,SQPaxos与WPaxos、EPaxos的性能对比。结果如图6所示。 图6(a)为uniform distribution模式下,各算法在5个区域中的平均延迟性能。SQPaxos(OP=1 000)比未增加Leader转移模式的SQPaxos、WPaxos、EPaxos的平均延迟分别降低了2.4%、73.7%、80.3%;SQPaxos(OP=10 000)比未增加Leader转移模式的SQPaxos、WPaxos、EPaxos的平均延迟分别降低了2.9%、73.1%、80.1%. 图6(b)为Maturity=70%模式下,各算法在5个区域中的平均延迟性能。其中SQPaxos(OP=1 000)比未增加Leader转移模式的SQPaxos、WPaxos、EPaxos的平均延迟分别降低了8.8%、62.6%、90.5%;SQPaxos(OP=10 000)比未增加Leader转移模式的SQPaxos、WPaxos、EPaxos的平均延迟分别降低了4.6%、60.9%、90.1%. 图6(c)为Maturity=90%模式下,各算法在5个区域中的平均延迟性能。其中SQPaxos(OP=1 000)比未增加Leader转移模式的SQPaxos、WPaxos、EPaxos的平均延迟分别降低了12.9%、56.2%、92.9%;SQPaxos(OP=10 000)比未增加Leader转移模式的SQPaxos、WPaxos、EPaxos的平均延迟分别降低了7.4%、53.8%、92.5%. 图6 (a)均匀分配模式;(b)数据对象匹配度为70%;(c)数据对象的匹配度为90%Fig.6 (a) Uniform distribution; (b) Maturity=70%; (c) Maturity=90% 分析实验结果可知,使用自适应Multi-Leader转移机制的算法能够有效降低共识延迟。当客户端操作的数据对象与本区域拥有的数据对象匹配度越高时,达成共识所需的延迟越低。 本文针对现有广域网分布式共识算法存在的不足之处,提出了SQPaxos算法。SQPaxos的主要目标是减少广域网共识延迟,分别从减少Quorum大小和Leader分配两方面实现此目标。在Quorum大小方面,在满足算法安全性要求的基础上,实现了最小的第一阶段Quorum和第二阶段Quorum;在分配Leader方面,自适应地将Leader转移至请求操作频率较高的区域,使客户端请求尽量由本区域的服务器节点处理,减少跨区域的通信。实验表明,与现有算法相比,SQPaxos具有更低的延迟性能。
2.3 Multi-Leader自适应转移方案
3 实验分析
3.1 实验设计
3.2 Quorum性能



3.3 Leader性能

4 总结与展望
