基于Spark和深度神经网络的短期电力负荷预测方法
2021-07-19张思扬匡芳君周文俊
张思扬,匡芳君,周文俊
(温州商学院 信息工程学院,浙江 温州 325035)
0 引言
电力负荷预测是智能电网建设和规划的基础,负荷预测结果的准确性对电网的动态估计、负荷调度和降低发电成本具有重要意义,直接关系到电力投资的效益、供电的可靠性、电力需求的正常发展以及整个社会的经济效益和社会效益[1-3]。准确快速的短期负荷预测不仅可以有效降低发电成本,而且是电力企业在市场环境下实施需求响应工程、安排供电调度计划的前提。
面对海量、高维、异构的电力负荷数据,用传统数据挖掘方法进行负荷特性分析和预测,已难以满足需求,如何提高预测精度是研究负荷预测理论和负荷特性的重点内容,也深受学者们关注,近年来学者进行了大量研究[4-5],有静态短期电力负荷预测方法[6-8],这些方法不能准确预测非线性载荷和时间序列,但可以解释其物理特性。也有智能方法在处理STLF中的不确定性和非线性时间序列方面表现得更好[9-14],如秦昌平利用级联神经网络预测短期电力负荷[15];Ahmad等利用非线性自回归和随机森林模型预测中长期电力负荷[16];Suryanarayana等提出了一种用于热负荷预测的深度学习方法[17];Gou等利用深度前馈网络进行短期电力负荷预测[18];Chen等提出了一种能集成领域知识和研究人员理解的深度残差网络短期电力负荷预测模型[19];孔祥玉等提出了一种基于有监督和无监督结合的深度信念网络短期负荷预测模型[20];这些智能方法对高维数据的处理能力较强,
但存在共同问题是缺少考虑时序数据中的时间相关性,需要添加时间特征来确保预测效果。还有学者提出了提高预测精度的混合预测模型[21-29],如Ribero等提出了用于短期负荷预测的小波神经网络集成模型[23];Rafiei等提出了结合广义极值学习机、小波预处理和bootstrapping混合模型用于概率电力负荷预测[24]等。Hamed提出了基于Kalman滤波、小波和人工神经网络的短期负荷预测组合模型[25];Vrablecová等提出利用在线支持向量回归进行短期电力负荷预测[26];Sideratos等提出了基于人工神经网络和深度学习的混合模型,用于周负荷预测[27];Zhang等提出了基于长短期记忆的短期电力负荷组合预测模型[28];叶琳等[29]综述了深度学习在电力系统和负荷预测中的应用。这些方法中深度神经网络(Deep Neural Networks,DNN)由于其具有更多隐含层,并能通过强有力的训练程序重组,是电力负荷预测中相对较好的解决方案,但这些方法大多以集中式的迭代运算为基础,计算资源消耗很大,面对海量、高维、异构的电力负荷数据,已不能很好地满足负荷效率和预测精度要求。
针对短期电力负荷模型计算量大,维度高以及负荷数据采集越来越快,增大了数据规模,同时运用短期电力负荷预测的深度学习模型,在训练中需要进行系列复杂繁琐的大规模计算,并且还需要不断地调整超参数训练模型来得到相对最合适的预测模型。因此,短期电力负荷预测模型极需并行化实现方案来解决海量、高维和异构负荷数据下的负荷效率和预测精度要求。Liu等[30]分析比较了神经网络算法在Spark和Hadoop两种并行版本各种情况的性能,得出Spark在各种情况下是最有效。因此,本文从短期负荷预测模型规模和实际预测需求考虑,通过搭建分布式集群,利用Spark计算平台实现数据并行,在各节点上对数据进行计算和数据处理,即每个机器都拥有模型的完整副本,然后用不同的训练数据子集训练,得到的参数结果发送给中心参数服务器,由中心参数服务器组合每个节点的结果并更新模型后反馈最新模型的副本和新的数据子集给各个节点,并将每轮结果都被纳入预测模型,为下一轮做准备,从而提升运行效率。
1 粒子群优化深度神经网络的短期负荷预测模型
深度神经网络(Deep Neural Network,DNN)结构如图1所示[31],由1个输入层、1个输出层和多个隐含层组成,其预测性能影响的关键因素主要是模型构造和对模型的有效训练。

图1 深度神经网络结构图Fig.1 Structure of deep neural network
DNN的输入向量X=[x1,…,xm]T经输入层到达第1层隐含层,按式(1)处理后输出。

式(1)中,R1、W1、B1分别表示第1层隐含层输出矩阵及该层与输入层的权重和阈值。

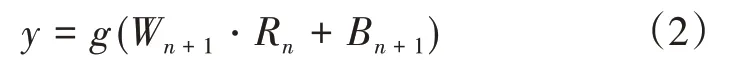
式(2)中,f、g分别表示隐含层和输出层的非线性激活函数,本文都使用sigmoid函数。
利用DNN进行电力负荷预测时,应先考虑DNN结构参数和各层间的最优权重和阈值参数,即判断DNN隐含层数量及层内节点数以及层间权重和阈值参数等,但考虑DNN的这些参数较难选择,需要对其参数进行优化处理后,再进行预测,以提升其预测性能。而粒子群优化算法(Particle Swarm Optimization,PSO)是一种群智能优化算法,它因原理简单、收敛快和易于实现的特点常被用于模型参数的选择和优化[32]。因此,本文采用PSO对DNN网络结构和参数进行优化,以提高模型的性能。限于篇幅,PSO算法描述在此不再赘述。
本文主要通过PSO优化DNN网络结构、权重和阈值参数,其实施方案如下:
1)通过PSO优化DNN结构隐含层数和层内神经元数,此过程可以看作离散性问题,让DNN结构与PSO粒子状态形成映射关联。用粒子位置取1与0来判断是否存在隐含层和层间神经元,当粒子的位置为1时表示存在神经元,当粒子位置为0时表示不存在神经元。
2)通过PSO优化DNN权重和阈值,通过让DNN各层权重和阈值与PSO中粒子状态形成对应关系,以便更新粒子状态时就能实现DNN参数更新,然后查找所有解空间中随机粒子位置,将DNN预测负荷值与实际负荷值间的平均绝对百分比误差定义为PSO粒子适应度F,即按式(3)计算适应度以便获取最优解。

式(3)中,N为测试样本规模;y(i)为实际负荷值;yˉi为预测负荷值。
2 基于Spark的粒子群优化深度神经网络短期负荷预测
对深度学习网络采用集群方式进行分布式训练,在Spark平台下构建基于改进群智能算法的深度神经网络短期负荷预测模型,其预测流程和运行机制如图2所示。首先将训练数据转换为支持并行操作的RDD格式训练副本,同时利用Spark计算框架使深度神经网络的训练过程在内存上运行,通过对深度神经网络训练过程的并行化,避免不必要的I/O操作以提升可拓展性,从而提高模型的性能和效率。同时,针对深度学习网络参数难以选择和隐含层层数难确定的问题,利用粒子群优化算法来优化深度学习模型参数和隐含层层数,以提高深度神经网络模型的性能,最后利用训练好的深度神经网络短期负荷预测模型去预测待预测日的电力负荷。
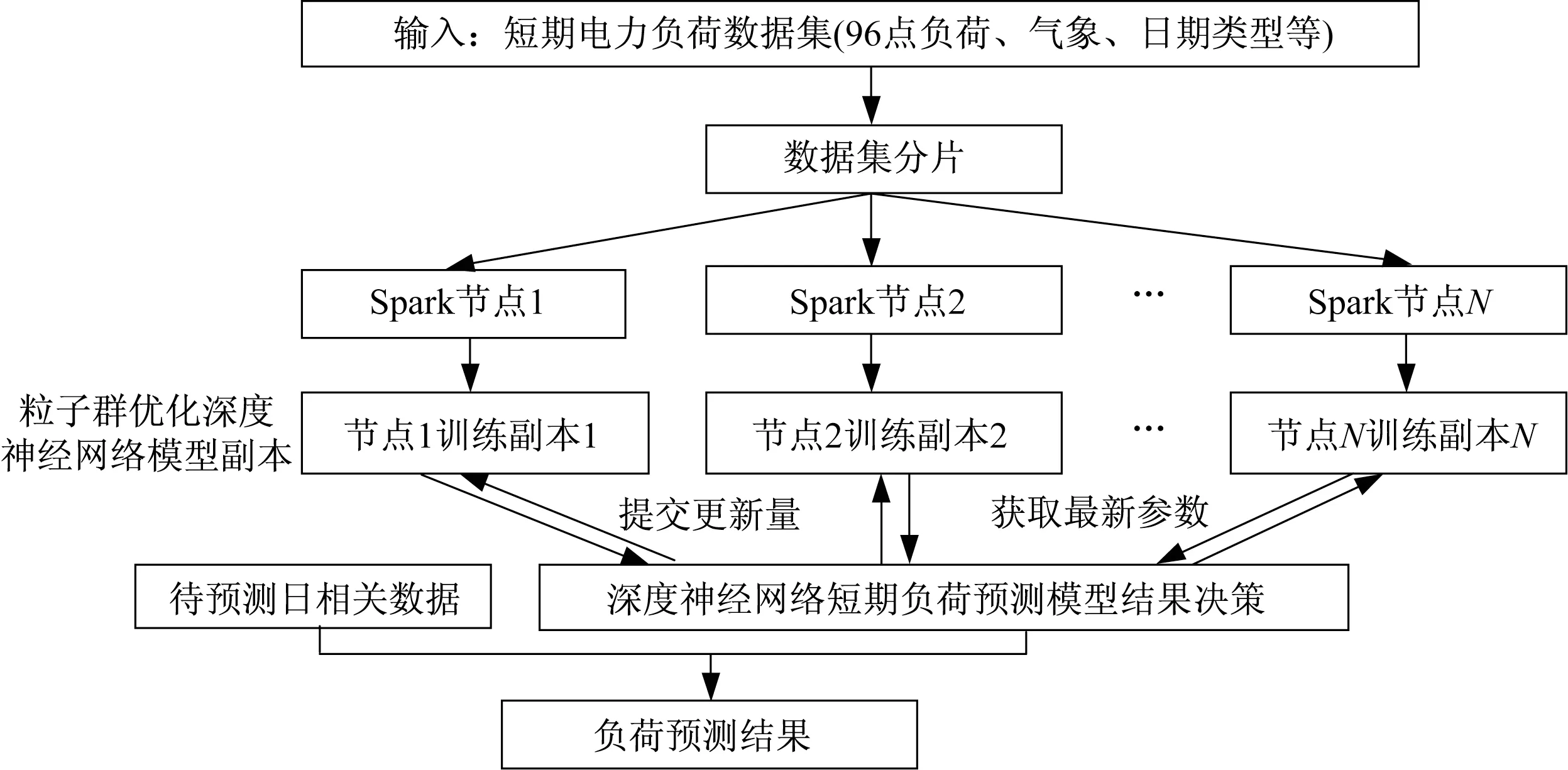
图2 基于Spark和深度神经网络的负荷预测运行机制Fig.2 Operation mechanism of load forecasting based on spark and deep learning
3 实验与分析
所有实验运行在搭建好的Hadoop2.6.0平台上,平台有16个节点,计算机配置内存8G,处理器为i7,主频为2.30 Hz,硬盘1 TB等。Hadoop版本为2.6.0,Spark版本为2.2.0,所有算法程序都是利用Python和MATLAB语言编程,仿真环境为Python3.6和MATLAB R2019b。
3.1 数据集
本文数据来源于第九届全国大学生电工数学建模竞赛所提供的标准数据集[33],即选取某地区2012年1月1日至2015年1月10日的电力负荷值、气象因素数据对电力短期负荷预测,其中,电力负荷值是每隔15 min采样1次,所以每天有96个采样时刻点,气象因素则包括相对湿度,降雨量,最高、最低和平均温度,日期类型等数据。
3.2 数据预处理
3.2.1 处理缺失数据
使用的数据集相对较规整,本文采用线性插值法填充缺失数据,公式如下:

式(4)中,fn和fn+1分别为n、n+1时刻的负荷值;fn+j为中间时刻n+j缺失的负荷值。
3.2.2 处理异常数据
在处理异常数据时,如果某一时刻的负荷值与前一时刻的负荷值偏差大于±10%,则采用水平处理。当某一时刻负荷值与前一天及前两天同期负荷值偏差大于±10%时,采用垂直处理。
1)水平处理:考虑到电力负荷的连续性,相邻时段的负荷不会发生突变,采用平均值方法对异常数据进行平滑处理。
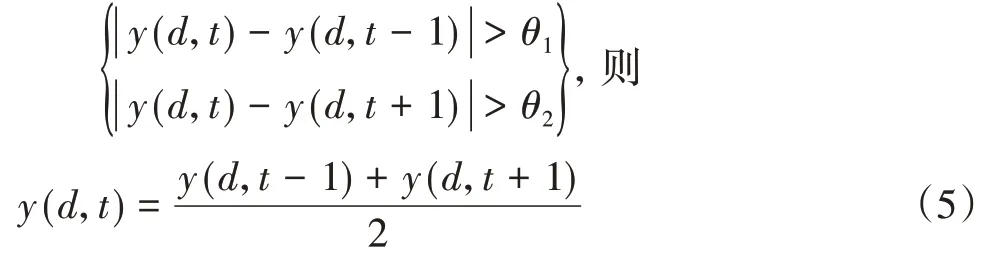
2)垂直处理:考虑电力负荷的周期性,对不在其范围内的异常数据进行校正。

3.3.3 数据标准化
1)利用对数对负荷数据进行标准化,公式如下:

式(7)中,xij,x′ij分别为原始负荷值和标准化后的负荷值。
2)用数字表示日期类型的标准化:根据负荷的周期性,周一取0.7,周二至周五取0.8,周六取0.4,周日取0.3。
3)采取离差标准化处理温度、湿度和降雨量数据:
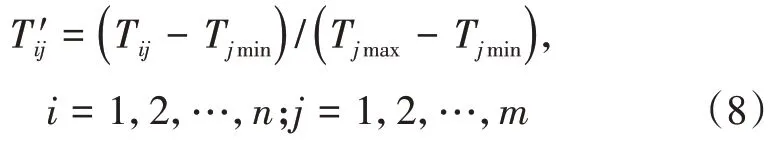
式(8)中,Tij为湿度、降雨量和温度的原始数据;Tjmin,Tjmax分别为湿度、降雨量和温度中的最小值、最大值;T′ij为标准化后的湿度、降雨量和温度数据。
3.3 性能评价指标
本文采用平均绝对百分比误差和均方根相对误差来评价模型的性能,公式如下:
1)平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)
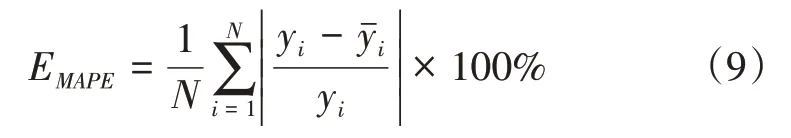
2)均方根相对误差(Root-Mean-Square Error,RMSE)
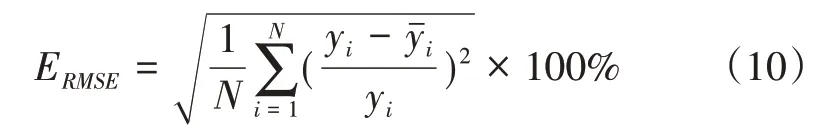
式(9)、式(10)中,yi为实际负荷;yˉi为预测负荷;N为预测负荷数据个数,N=96,即统计一天中96个时刻的绝对百分比误差对算法性能进行评估;MAPE和RMSE越小,说明算法的预测效果越好。
3.4 实验结果分析
在构建预测模型时,考虑到温度、湿度、降雨量、日期类型对短期负荷的影响,对每天96个预测点分别建立预测模型,即选用预测点前一天的气象数据、前一天的同期负荷数据、前两天同期负荷数据和当天的气象数据形成训练输入数据,得到预测点的输出数据,再将此输出数据对应预测点的同期负荷数据作为输入数据继续预测下一个预测日,直到完成全部日期的预测,得到预测模型,最后利用训练好的预测模型对待预测日进行预测。
3.4.1 模型性能误差对比分析
利用训练样本集对基于Spark的粒子群优化深度神经网络(Spark_DNN_PSO)短期负荷预测模型进行训练,并对预测日2015年1月10日的96个采样点的负荷进行预测,并与PSO优化支持向量机(SVM_PSO)、深度神经网络(DNN)、随机森林(Random Forest,RF)、支持向量机(SVM)5种负荷预测模型进行比较,不同模型算法运行30次后的负荷预测结果如图3所示。5种负荷预测模型在预测日上的MAPE、RMSE和运行时间(RunTime)如表1所示。
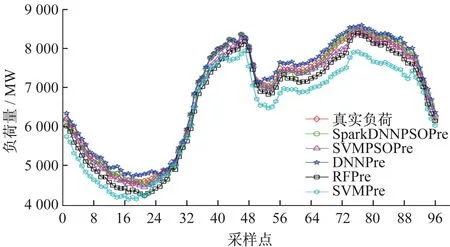
图3 各负荷预测模型预测结果Fig.3 Prediction results of load forecasting models
从图3和表1可以看出,本文提出的Spark_DNN_PSO预测模型与其他模型相比,具有更好的预测效果。预测负荷曲线更接近实际负荷曲线,其MAPE、RMSE和运行时间最小,而且拟合效果更好,尤其是在负荷变化的峰谷值时,本文提出的方法预测效果更能准确地捕捉负荷变化趋势。因此,该模型能较好地应用于短期电力负荷预测。

表1 各预测模型的预测误差和运行时间统计Table 1 Prediction error and running time statistics of models
3.4.2 算法并行性能分析
为了比较平台集群节点数以及数据集大小对短期负荷预测结果的影响,本实验设置节点数分别为4,8,16,观察模型预测结果的运行时间,并采用加速比来测试算法的并行性能。将原始数据扩大,采用不同大小的数据文件来检测算法预测精度是否受到影响,对各数据容量运行预测模型Spark_DNN_PSO,并计算其MAPE和运行时间,如表2所示。
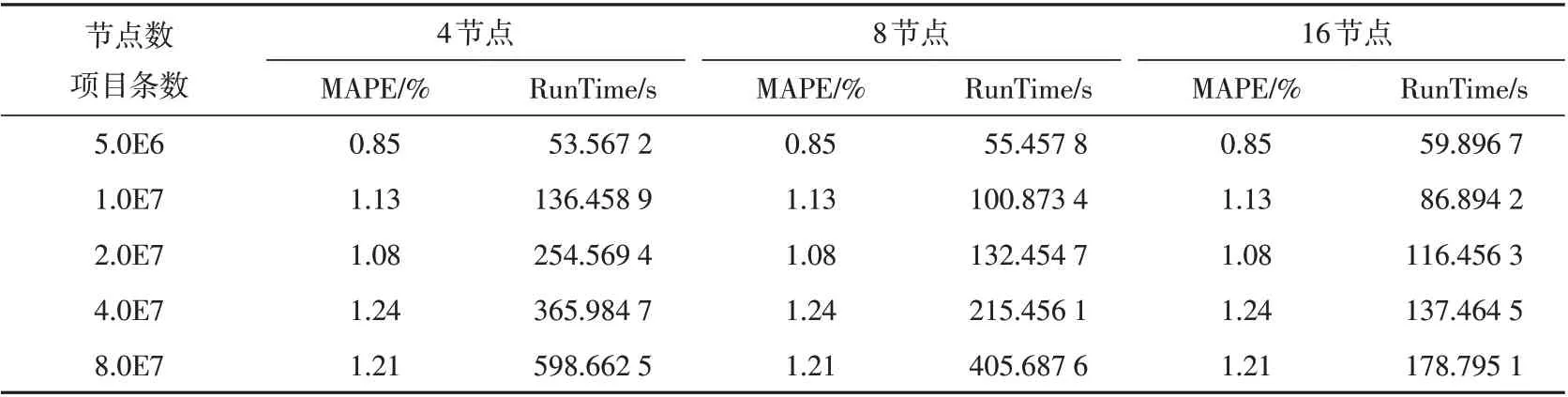
表2 不同数据文件大小的模型预测误差与运行时间Table 2 Model prediction error and running time of different data file sizes
由表2可以看出,当数据样本较大时,集群节点数大的预测模型运行时间相对较小,能有效缩短运行时间,而当样本数据量较小时,各节点数在运行时间上基本差不多,没有明显优势,而且节点数大的运行时间还稍长些,这是因为Spark在集群运算进行CPU和内存分配时所花时间占比较大,但随着数据量的增加,这种开销占比会越来越小,其集群性能优势明显,所以当数据集较小时搭建分布式集群环境进行预测时需要考虑成本和实际情况,而且并不是节点数越多越好。另外,随着数据项目条数增大,MAPE预测误差稍有增加,但波动范围较小,没有明显规律性,最大MAPE误差为1.24%,最小MAPE误差为0.85%。实验表明,Spark_DNN_PSO算法能较好地应用于电力大数据预测环境下进行短期负荷预测。
4 结语
针对单机电力负荷预测模型存在的问题,本文提出了基于Spark的PSO优化DNN负荷预测模型,通过Spark计算平台部署16个节点的集群来提升模型的运行效率,此外将负荷输入数据集分片成RDD数据集提高了算法的适应性和泛化能力,同时,通过PSO确定深度神经网络的隐含层层数和各层的神经元个数以及优化DNN权重和阈值参数能有效地提升模型的性能,减少预测误差。下一步将研究机器学习集成算法在Spark计算平台上的并行性,进一步提高并行算法的执行效率和负荷预测精度,以及研究轻量级的预测模型加快训练和预测速度,进而更好地应用于实际的电力大数据预测环境。
