基于GBDT+LR 模型在个人信用风险评估中的研究
2021-07-16张丽娟
◆张丽娟
(安徽大学经济学院 安徽 230601)
随着经济的发展和个人消费观念的改变,信贷业务逐渐进入人们的日常生活,在商业银行以及很多金融机构中都是一项重点发展的业务,信用风险分析在信贷行业至关重要,信贷机构对借款人的还款能力和还款意愿进行评估,判断是否对借款人进行贷款发放以及借贷金额和贷款期限,这有利于信贷平台有效地减少潜在的风险。机器学习中的一些算法例如逻辑回归,决策树,随机森林等都被应用于个人信用评估中,但是在数据集的维度较复杂时,这些算法如果不能进行很好的特征选择和特征组合,且不能很好的处理一些敏感信息,那么模型的预测准确率会大大下降。
本文所提出的一种基于GBDT与LR算法构建的一种用于个人信用评估的风险控制模型,首先利用GBDT 分类器构造新特征,再用逻辑回归模型进行预测分析,有效地解决了特征选择和异常值问题,在一定程度上避免了模型过拟合问题。通过全球最大的P2P 平台LendingClub 的信贷数据进行实证分析验证了该模型在个人信用评估上具有更好的适用性和稳定性。
1 相关研究
个人信用风险评估是一个二分类问题,即对借款人进行分类判断是否发放贷款。传统的信用风险评估主要是依靠有丰富经验的专业人员的人工审核借款人的基本信息。随着数据时代和业务数量的增长,传统人工审核方法不再适用。秦宛顺[1]等构建了基于Logistic 回归的个人信用评分模型,对客户进行‘好坏’的分类。宋丽平[2]等重要考虑借款人的个人基本信息等指标,建立基于BP 神经网络的个人信用评估模型,研究发现BP神经网络在个人风险评估问题上具有可优化性。Zhang,Lian Z 等[3]认为对于个人贷款信用评估是复杂的非线性问题,通过构造个人贷款信用指数,然后利用SVM 模型进行识别分类,进而认为SVM 在个人贷款风险评估上具有重要作用。
单一的模型在计算速度、预测效果等方面各有优缺点,将不同的模型结合起来,可以充分发挥模型之间的优点,取长补短提高模型的泛化能力。王黎[4]利用GBDT 处理混合数据类型的优点,提出基于GBDT 的个人信用评估方法,通过UCI 公开数据的验证认为GBDT的信用评估具有更好的稳定性和适用性。王小俐等[5]从P2P 网贷平台运营风险预警指标角度进行模型研究。陈启伟等[6]利用bagging 方法将基本分类器集成构建基于Ext-GBDT 集成的类别不平衡信用评分模型。Maoguang Wang 等[7]利用XGBoost 在特征变化上的强大功能,构建了XGBoost-LR 混合模型,有效提高了模型的预测精度。
本文在此基础上,提出了一种集成GBDT 与LR 算法的个人信用风险评估模型,利用GBDT 对数据进行特征变换,再输入到LR 进行分类训练,充分利用了两种算法的优点,并有效提高了模型的预测精度和稳定性。
2 GBDT+LR 融合模型介绍
2.1 GBDT 算法
梯度提升决策树(Gradient Boosting Decision Tree,GBDT)是Friedman 在1999 年提出的一种Boosting 类集成学习算算法[8]。它的主要思想是每一次建立模型是在之前建立模型损失函数的梯度下降方向。在GBDT 模型中常选用GART 回归树作为基学习器,每一棵树的生成都是基于上一个回归树分类结果的残差,以串行的方式向残差减小的方向梯度迭代,最后累加所有树的结果加权求和作为最终结果。GBDT 算法的流程如下:
第一步:取训练集T={(x1,y1),(x2,y2),...,(xn,yn)},迭代次数M和损失函数,初始化弱分类器:
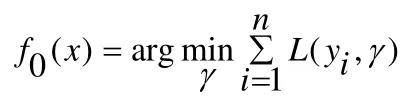
第二步:对m=1,2,...,M,执行以下步骤:
1)对i=1,2,...,n,计算近似残差:
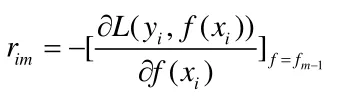
2)对近似残差rmj拟合一棵回归数,得到第m棵树的叶节点域Rjm,j=1,2,...,Jm,即一颗由J个叶节点组成的树。
3)对j=1,2,...,Jm计算最佳拟合值:
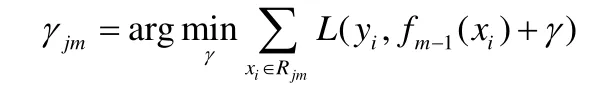
4)更新分类器:
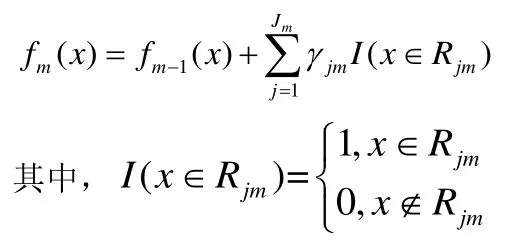
第三步:得到最终强学习器:
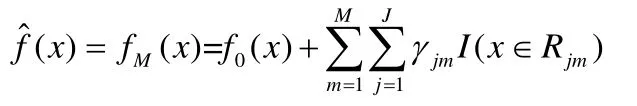
2.2 LR 算法
逻辑回归算法(Logistics Regression,LR)是一种基于回归分析的分类算法[9]。线性回归模型能够很好处理数值问题,其公式如下:
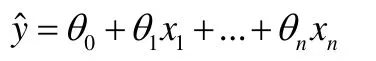
LR 是在线性回归的基础上加上了Sigmoid 函数映射到(0,1)上,并划分一个阈值,大于阈值的分为一类,小于等于阈值的分为另一类,使得逻辑回归成为非常好的二分类算法。Sigmoid 函数表达式如下:
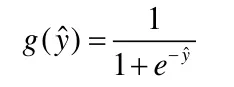
逻辑回归假设数据服从伯努利分布,通过极大化似然函数的方法,运用梯度下降来求解参数以达到数据分类的目的。
2.3 GBDT+LR 融合模型
LR 算法作为广义线性模型,模型简单可解释性好,计算时间小,能用于海量数据,但是LR 算法学习能力有限,对数据特征的要求比较高,容易导致欠拟合。因此在进行分类训练之前,需要有效的特征工程对原数据进行特征提取,进而得到较好的分类结果。Facebook在2014年提出GBDT+LR的组合模型来进行CTR预估,利用Boosting Tree 模型本身的特征组合能力进行特征工程[10]。Boosting Tree 模型本身具备特征筛选的能力以及高阶特征组合能力,通过GBDT 来进行特征筛选和组合,进而生成新的离散特征向量用于LR 模型的输入,能够得到更好的预测效果。
首先将训练集通过GBDT 构造一系列的决策树,组成一个强学习器,每棵树根节点到叶子节点的路径可以看成是不同特征进行特征组合,某个叶子节点对应一个离散特征,然后通过one-hot 编码对特征处理传入到LR 分类器进行二次训练。GBDT+LR 融合模型的训练过程如下[11]:
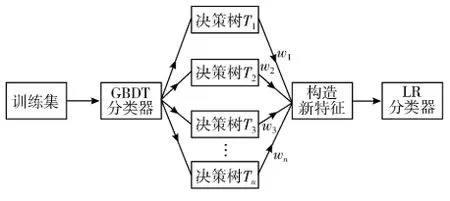
图1 GBDT+LR 模型训练示意图
由GBDT 构建新离散特征如图2 所示,假设fm-1和fm为GBDT算法训练过程中生成的2 棵决策树,分别有5 个叶结点,其中数字1表示训练样本x通过该决策树预测的结果落在该叶结点上,那么对于树fm-1,其预测的结果可以用One-Hot 编码表示为 [ 0,1,0,0,0]。假设GBDT 算法迭代次数为x,且所有弱分类器共具有y个叶结点,对于m条原始数据,每一条都会被转化为y维的稀疏向量,其中x个元素为1,y-x个元素为0,那么最终会形成维度为m×x×y的新训练集。
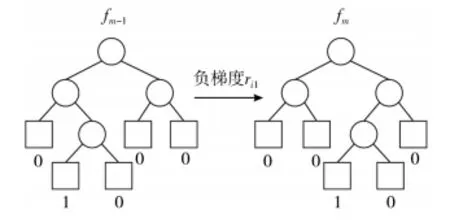
图2 GBDT 算法构造新特征示意图
3 基于GBDT+LR 模型的个人信用风险评估模型
本文中选取了全球最大的P2P借贷平台美国LendingClub 提高的公开数据作为实证数据集,选用了2019 年第一季度的数据115779条有效个人贷款数据,每个数据包含有148 个特征变量和1 个标签变量(违约和不违约)。建立了基于GBDT+LR 融合模型的风险评估模型,该模型的主要工作流程如下图所示。
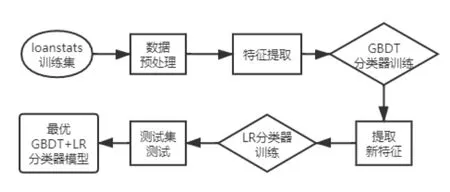
图3 GBDT+LR 分类器工作流程图
3.1 数据预处理
首先对原始数据集进行数据清洗,了解数据的目标变量、分类变量以及连续性变量信息特征分布;数据集中存在严重的缺失值问题,对于缺失值比例大于60%的特征变量进行删除处理,对于其余含有缺失值的特征变量进行众数填充;数据集中特征变量的观测值90%以上为相同特征的变量,结合变量实际意义进行筛选删除;最后特征由148 个减少到89 个。
3.2 特征提取
通过对于文本变量进行特征编码,将有序变量通过映射为数值型,对无序变量进行one-hot 编码;由于模型中使用到梯度下降法,为了加快迭代速度,所以对数据进行标准化处理。
由于数据中的很多变量存在较强的相关性,通过Wrapper 方法逐步剔除不相关特征降低模型学习难度,将自变量从94 个降到30 个。在此基础上通过皮尔森相关性图谱找到冗余特征并将其剔除,通过相关性的图谱进一步确定特征选择的方向。最终筛选出18 个特征变量用于模型训练。
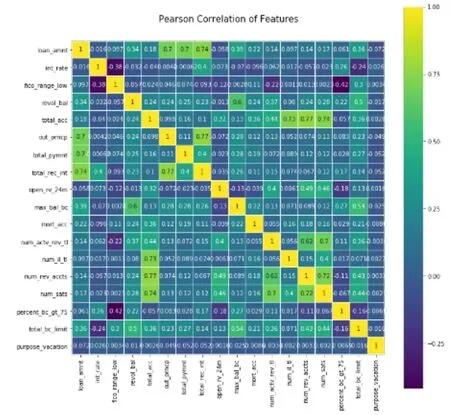
图4 入模训练的18 个变量相关图
3.3 实验及结果分析
本次数据中目标变量‘loans_status’正常和违约两种类别存在较大的数量差别,采用了SMOTE 方法对样本进行不均衡处理,将数据集中正负样本分布比例通过采样调整为1:1;采用交叉验证方法划分数据集,将数据集划分为训练集和测试集;在模型优化中采用网格搜索调优参数,进行构造参数候选集合,选出最好的一组参数用于构建最优分类器模型。
本文中贷款评估为二分类问题,目标变量用0 或1 表示,将正常定义为正,违约定义为负,其混淆矩阵见表1 所示。

表1 分类结果混淆矩阵
本次实验中,为了评估GBDT+LR 模型在贷款评估中的性能,选取了LR(逻辑回归)、DT(决策树)、RF(随机森林)、GBDT(梯度提升决策树)等四种机器学习模型进行对比分析,选用的分类器性能评估指标为Accuracy(准确率)、Recall(召回率)、F1 值、AUC值。实验结果如表2 所示。
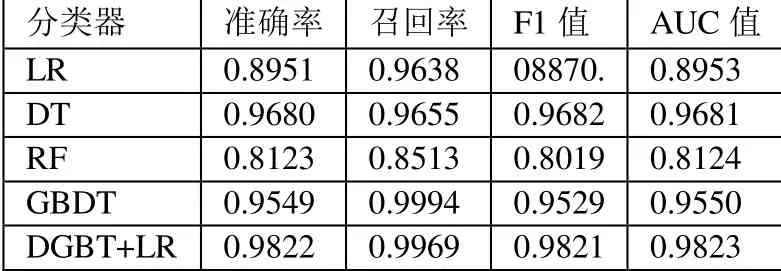
表2 不同机器学习模型的结果对比
从上表中可以看出GBDT+LR 模型的分类效果总体上要优于其他4 类模型。通过准确率看GBDT+LR 分类器的预测准确率最高为98.22%,其中单独的GBDT 分类器的预测准确率为95.49%,而单独的LR 分类器的预测准确率为89.51%,均低于GBDT+LR 分类器的预测准确率。AUC 值代表模型的分类效果,五种模型中明显可以看出GBDT+LR 分类器的预测效果AUC 值远远大于其他四种分类器,说明GBDT+LR 的分类效果最优。在召回率和F1 值的得分中GBDT+LR 的分值也是最高的,说明该模型具有很好的预测性能。
4 结论
为了金融借贷机构更好更精准地对借款人的状态进行评估,本文基于GBDT+LR 算法建立个人信用风险控制评估模型,并利用全球最大P2P 平台LendingClub 公司2019 年第一季度真实数据进行实证分析,与常见的LR、DT、RF、GBDT 等模型进行比较,在AUC 值、准确率等各项性能指标数据可以看出基于GBDT+LR 的融合模型在个人信用风险评估上,具有更好的预测性能和稳定性。此项研究更有利于金融借贷机构有效避免潜在风险,进而更好地进行管理运营。
