基于太阳黑子群数据的多模态太阳耀斑预报模型
2021-07-13马健石育榕罗冰显
马健,刘 柱,石育榕,罗冰显,郑 锋
(1.南方科技大学工学院,深圳 518055;2.中国科学院大学,北京 100049;3.中国科学院国家空间科学中心;4.中国科学院空间环境态势感知技术重点实验室:北京 100190)
0 引言
地球空间环境变化源于太阳活动,而太阳活动是指太阳大气局部区域能量辐射增强形成的许多瞬间变化现象。太阳活动分为缓变型和爆发型,缓变型活动包括太阳黑子、普斑和光斑等;爆发型活动包括耀斑、日珥、暗条和日冕物质抛射等。
太阳耀斑指太阳表面局部区域剧烈的能量释放过程,是最强烈的太阳爆发活动之一。太阳耀斑对地球空间环境安全造成很大威胁:耀斑爆发会增强到达地球的紫外线辐射,引起地球大气的温度和密度升高,影响航天飞行器的飞行轨道;耀斑粒子经过地球大气层时,和大气层的粒子碰撞,会破坏电离层结构,导致无线电波在电离层中反射失效,从而使无线电通信受到干扰甚至中断;耀斑爆发导致的地磁场强烈变化产生地磁感应电流,在长距离输电线路上产生直流感生电流,引发变压器大量发热造成变压器损坏;此外,油气管道等由于地磁场的变化也会产生感生电流,导致管道的流量表数据异常和侵蚀率增加。因此,太阳耀斑预报是太阳活动预测中十分重要的研究领域,一方面,太阳耀斑预报可以为人类活动提供预警信息,以便提前采取应对措施;另一方面,太阳耀斑研究对理解太阳活动的内在机理具有科学的指导意义。
太阳黑子群又称为太阳活动区,出现在太阳光球层,与耀斑、日冕物质抛射等太阳活动密切相关[1]。某些类型的太阳黑子群和太阳耀斑爆发有关[2-3],因此可以通过对太阳黑子群的分类来进行太阳耀斑爆发的预测。早期的太阳黑子群分类采用人工图像分类,但由于太阳黑子群数据内的特征信息没有被充分提取利用,造成误检和漏检,所以分类的准确率不高。
太阳黑子群的常见分类标准有McIntosh 分类、Wilson 分类和Zurich 分类[4]。太阳黑子群的结构越复杂,发生耀斑的概率越高。耀斑等级有A、B、C、M和X 级5种,其爆发能量依次增强。自1966年10月开始,美国空间天气预报中心对获得的太阳黑子群数据均采用McIntosh 分类规则,并逐渐被一些知名天文机构和单位所采用。目前,国内的太阳黑子群数据也使用这种分类系统,并已积累大量观察数据。
目前的太阳耀斑预报模型主要采用统计学方法和机器学习方法建立[5-6],通常分为两步——提取太阳黑子群的物理参量和建立这些物理参量与太阳耀斑爆发间的联系。在物理参量提取方面,McIntosh基于太阳黑子群磁场观测数据,提出用于刻画磁场偏离势场程度和磁场复杂性的物理参量,如磁场梯度、中性线长度等。然而,目前对这些参量的预报能力非常有限,因此常采用一些统计和机器学习方法来建立这些参量与太阳耀斑爆发间的联系,如泊松统计方法、回归分析方法等,虽然有一定进展,但准确率和实时性都不高。
近年来,深度学习方法发展迅速,为许多领域提供了具有促进性的研究方法。其中卷积神经网络可以通过学习自动提取图像中的相关特征,特别是提取出抽象的高层语义信息,直接利用图像和相对应的类别标签建立预报模型,而不需要设计复杂的算法来提取特定的物理参量,降低了模型设计的难度,准确率也可得到大幅提升。
本文以太阳黑子群磁图和磁特征参量为输入,利用卷积神经网络和全连接神经网络,训练出黑子群磁图分类模型和磁特征参量分类模型,并对这2种分类模型的分类结果进行融合。
1 建模
模型输入包含2种类型数据——太阳黑子群磁图和磁特征参量。对于太阳黑子群磁图数据,采用由2种卷积神经网络组成的图片分类模型进行特征提取和分类;对于磁特征参量,采用由2层全连接神经网络组成的磁特征参量分类模型进行数据分类。在得到这2种数据的分类结果之后,针对太阳耀斑爆发事件的连续性和这2种分类模型各自的优点,融合分类结果,以进一步提高太阳耀斑预报的准确率。
1.1 多模态太阳耀斑预报模型整体架构
多模态太阳耀斑预报模型主要由2个模块构成——黑子群磁图分类模型和磁特征参量分类模型,如图1所示。黑子群磁图分类模型将太阳黑子群磁图作为输入,经过模型推理后输出磁图的类别标签;磁特征参量分类模型以10种磁特征参量作为输入,输出类别标签。

图1 多模态太阳耀斑预报模型结构Fig.1 Structure of multi-modal solar flareforecasting model
黑子群磁图分类模型由ResNet34[7](deep residual network,深度残差网络)和Inception V4[8]两种卷积神经网络构成,提取出高区分度图像特征进行分类。但是太阳黑子群外观、形状、粒子分布迥异,不同区域的黑子群磁图分布差异巨大,即使在同一个区域内,黑子群的外在表观也会随时间的推移产生显著的变化;此外,黑子群由于内部磁场、外部环境的不同,拥有各自不同的特性,不同区域的黑子群衍变发生太阳耀斑事件的速度、条件等也有巨大差异。因此,仅仅通过黑子群磁图分类模型得到的分类结果精度有限。
磁特征参量分类模型输入的是人工提取的特征参量,其特征鲁棒性相对更高,故可以对最终分类结果起到一定的指示作用。
在模型融合阶段,分别利用这2种分类模型的优点,对它们的分类结果进行融合和后处理。即在太阳黑子群磁图分类模型预测的分类结果中保留那些由磁特征参量分类模型预测为发生太阳耀斑事件的观测对象,再根据太阳黑子群衍变过程具有连续性的特点对模型融合后的结果进行后处理校正。
1.2 黑子群磁图分类模型
目前,太阳耀斑爆发的物理机理并不完全清晰,无法建立精确的物理模型来对未来是否发生太阳耀斑事件进行精确判断,因此太阳耀斑预报本质上还是以太阳黑子群特征为基础的概率预测。一般而言,机器学习方法可以较好地找出物理参量与太阳耀斑爆发间的关系,但是传统机器学习方法的瓶颈在于黑子群特征提取,而太阳物理学家人工提取黑子群物理参量的能力有限,因此本文采用经训练的卷积神经网络自动提取图像特征,建立预报模型。
计算机视觉领域研究人员设计出多种结构的神经网络,常用的有LeNet[9]、AlexNet[10]、VGGNet[11]、GoogLeNet[12]、ResNet、DenseNet[13]等,还有为了减少模型参数量而设计的SqueezeNet[14]、MobileNet V1[15]、MobileNet V2[16]、ShuffleNet[17]等,使卷积神经网络模型的性能持续提高,而模型需要的参数量和计算量大规模减少。
不同区域太阳黑子群磁图的外在特征变化巨大,从磁图中提取出的低级和中级特征无法拥有良好的分类性能,因此太阳黑子群磁图分类模型需要提取出足够多的高层语义信息,且这些语义信息要具有强鲁棒性。本文采用比较流行的2种卷积网络结构——ResNet34和Inception V4作为太阳黑子群磁图分类模型的骨干网络。
ResNet 可以解决深度卷积神经网络难以训练的问题,其根据卷积层数的不同分为ResNet34、ResNet50和ResNet152等结构。在本文的数据集中,由于训练集和测试集的分布差异,采用较大的模型会使卷积神经网络在训练集中产生过拟合现象,即在训练集中性能非常好,然而在测试集中性能产生断崖式下跌。因此,本文选取参数量和卷积层数适中的结构——ResNet34,既可防止过拟合现象的发生,又可提取鲁棒的高层语义信息,以平衡训练集和测试集间的分布差异。
在黑子群磁图中,由于不同观测点的黑子群发生的条件和状态等不同,所以不同区域的黑子群尺寸会有剧烈的变化;而ResNet 基本只采用1种尺寸的卷积核,因此感受野比较单一,提取的特征多样性较差,不能提取出足够多形态的黑子群特征。为此,本文在黑子群磁图分类模型中同时采用了Inception V4网络。Inception 结构的主要特点是:采用多种尺寸的卷积核,拥有多种感受野,可提取不同尺度物体的特征,并对特征拼接进行不同尺度特征的融合;可以更方便地实现特征对齐。
在本文多模态太阳耀斑预报模型中,ResNet34和Inception V4组合为太阳黑子群磁图分类模型,在分别得到2种卷积网络的分类结果后,将结果进行第一步融合。这一步融合过程采用比较激进的策略,即这2种卷积网络中只要任何1个网络的分类结果为发生太阳耀斑事件,融合输出结果即判定为发生太阳耀斑,如图2所示。
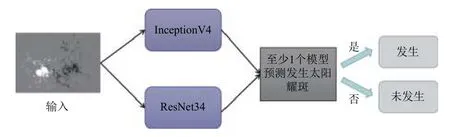
图2 太阳黑子群磁图分类模型的融合策略示意Fig.2 Fusion strategy of magnetogram classification network of sunspot group
1.3 磁特征参量分类模型
磁特征参量数据是由太阳物理学家在太阳黑子群磁图中人工提取出的物理参量,这些参量特征鲁棒性强,本文设计了一个2层全连接神经网络进行训练。
磁特征参量分类网络包括输入层、隐藏层和输出层,同时在神经网络层间采用常用的ReLU 激活函数增加网络的非线性,将神经元的输出限制在一定范围内。
如1.2节所述,由于数据集中训练集和测试集分布差异巨大,如果采用较深或者较宽的网络结构会出现过拟合现象,所以磁特征参量分类网络的神经元节点数较少。磁特征参量共有10种物理参量,故输入层节点数为10,每个节点接收1 个参量作为输入;隐藏层的节点数仅为200;输出层节点数为2,代表着太阳耀斑是/否发生的2种类别,类别标签分别为“1”—是、“0”—否。
1.4 模型融合
由太阳黑子群磁图和磁特征参量2种数据对应训练出来的模型特点不同,主要表现为:太阳黑子群磁图分类模型的召回率较高,但是精确率低,且预测出的观测对象很分散,即该模型预测为发生太阳耀斑的图片数多,但是其分类正确率较低;而磁特征参量分类模型的精确率较高,召回率较低,且预测出的观测对象比较集中,即该模型预测为发生太阳耀斑的图片数目较少,但是其分类正确率较高。简单来说就是,太阳黑子群磁图分类模型的泛化性能较好,但是特征区分度相对较差,而磁特征参量分类模型区分度较好,但是泛化性较弱。
因此综合利用这2种模型的优点,在分别得到太阳黑子群磁图分类模型和磁特征参量分类模型的分类结果后,对这2种结果进行融合,具体步骤如图3所示,包括:
1)在磁特征参量分类模型的结果中,不对单张图片的分类结果进行处理,只提取分类为发生太阳耀斑且图片数量超过5张的观测对象,并将这些观测对象预测为最终发生太阳耀斑的太阳黑子群。
2)在太阳黑子群磁图分类模型的结果中,如果分类为发生太阳耀斑事件的观测对象不在第1)步得到的太阳黑子群当中,则其最终分类结果为未发生太阳耀斑事件。

图3 模型融合示意Fig.3 Schematic diagram of model fusion
1.5 后处理
太阳耀斑事件一般是连续的多张图片,经过统计,发生了太阳耀斑事件的观测对象的图片数量绝大多数都会超过5,其中少于和多于5张图片的观测对象的数量比约为1∶17.5。因此,本文在最终结果中会剔除“孤岛”事件——预测出发生太阳耀斑而其图片数少于5的观测对象,将其分类为不发生太阳耀斑。同时,利用太阳耀斑事件的连续性剔除另一种“孤岛”事件,将预测出发生太阳耀斑事件的观测对象但中间结果有间断的事件予以校正,例如,在连续多张图片的预测为发生太阳耀斑事件的结果中,若中间有图片预测为未发生太阳耀斑事件,则将该图片预测类别校正为发生太阳耀斑事件,即将其类别标签由“0”校正为“1”,如图4所示。

图4 “孤岛”事件处理策略示意Fig.4 The strategy of handling the “isolated island” event
2 数据
目前,太阳黑子群数据主要有SDO/HMI 数据和SOHO/MDI数据。自1996年来,这2 种数据提供了持续、高质量的太阳黑子数据。其中,SOHO/MDI的数据起止时间为1996年1月1日—2011 年4 月12日;SDO/HMI是SOHO/MDI的继任者,自2010年4月30日开始日常观测至今。SOHO/MDI数据可以在Joint Science Operations Center(JSOC)网站上获取[18],其采样频率为96 min-1;SDO/HMI数据自2010年5月1日开始收集后,已积累10余年的数据,其采样频率为12 min-1。一个黑子群的磁图展示该区域的磁通分布。
本文最终采用图像数据质量较高的SDO/HMI数据,同时为了减少数据量,将其采样频率降到96 min-1,采取了2010年—2019年约10年的数据;并将2010年—2015年的数据划分为训练集,2016年—2019年的数据划分为测试集。以未来48 h 是/否发生太阳耀斑事件作为类别标签。
该数据存在以下特点:
1)数据分布不平衡。由于太阳耀斑事件的自然特性,发生太阳耀斑的样本量远远小于未发生太阳耀斑的样本量,在训练集中,这2种类型的数据样本数分别为2837和56 869。
2)训练集和测试集的样本分布存在很大偏差,如图5所示,同一类别中不同观测对象的黑子群磁图尺寸、外观、不同磁极的分布等差异巨大,当模型参数量较大时,极易出现过拟合现象。

图5 训练集和测试集的样本分布差异示意Fig.5 Differences of sample distributions between training set and test set
3)由于太阳黑子群的活动是连续的演化过程,所以同一个观测对象的数据存在着时序连续性。
3 模型评价指标
由于太阳黑子群数据的不平衡性,仅通过单一的评价指标难以评价模型的优劣。本文同时采用F1 score、召回率(Recall)、虚报率(FAR)和正确率(PC)这4种指标综合判断模型性能,各评价指标的优先级顺序为:F1 score>Recall>FAR>PC。各指标的计算式如下:


式中H、M、F、CN的含义参见表1。

表1 混淆矩阵Table 1 Confusion matrix
4 实验验证
图像分类模型的数据增强策略包括:1)调整输入图片尺寸,将ResNet34的图片尺寸调整为(128,128),Inception V4的图片尺寸调整为(512,512);2)水平翻转输入图像;3)竖直翻转输入图像。每批量数据大小设置为64,优化器采用随机梯度下降,损失函数为交叉熵损失函数,初始学习率为0.01,并且在第20、30个回合时将学习率分别调低为原来的0.1倍,共训练40个回合。
对于磁特征参量分类模型,由于样本的不平衡,在训练模型的过程中,先利用SMOTE[19]方法对少数类进行过采样(TOTUSJH 和AREA_ACR 参数的SMOTE过采样如图6所示),以平衡数据集类别;然后将SMOTE 后的数据按特征进行归一化后输入磁特征参量分类模型中进行训练。每批量数据大小设置为10,优化器采用随机梯度下降,损失函数为交叉熵损失函数,共训练100个回合。

图6 TOTUSJH 和AREA_ACR 参数的SMOTE 过采样示意Fig.6 SMOTE oversampling diagram of TOTUSJH andAREA_ACR parameters
本文同时采用传统的Sigmoid 对图片进行分类,并对比多个模型的分类结果,见表2。表中指标箭头向上代表该指标值越大越好,反之代表该指标值越小越好,并以红色粗体突出显示了各评价指标中的最优值。

表2 多个模型的分类结果对比Table 2 Comparison of results obtained with various models
从表2中可得:
Sigmoid 函数对磁特征参量的分类能力较强,但是只能利用1种数据,不能充分有效地利用太阳黑子群磁图信息,提升空间有限;ResNet34模型召回率较低,虚报率较高,太阳耀斑的分类准确率较低,性能较差;Inception V4模型虽然召回率较高,但虚报率也很高,相应的,其F1 score 结果也很低;磁特征参量分类模型召回率最低,但是其虚报率也最低,综合性能在5种模型中最差。
ResNet34 和Inception V4这2种卷积神经网络提取出的高层语义信息对模型分类结果贡献巨大,相应模型的性能均超过仅利用磁特征参量的分类模型。
多模态太阳耀斑预报模型综合利用了太阳黑子群磁图和磁特征参量信息,对不同类型数据建模,既利用全连接神经网络对数据信息的建模能力,又利用卷积神经网络对图片数据的强大特征表达能力,尤其是在提取高层语义特征方面。因此从实验结果看,多模态太阳耀斑预报模型的F1 score结果比其他模型至少提高了7.8%。
需要说明的是,本文采用未来48 h 是/否发生太阳耀斑事件的数据,在应用于24 h、72 h 等数据上时,需要对模型参数设置进行调整;并且由于数据量有限,在应用较大深度学习模型时易出现过拟合现象。
5 结束语
本文基于深度学习方法,建立了一个多模态太阳耀斑预报模型。与传统的机器学习相比,该模型不仅利用从太阳黑子群磁场中提取的物理参量,而且直接利用太阳黑子群磁图自动提取太阳黑子群的特征,使模型的预报性能获得了有效提升。本工作验证了深度学习在太阳耀斑预报中的有效性,间接说明了高层语义信息在太阳黑子群磁图分类中的重要作用,也证明了传统人工提取的物理参量同样具有一定的分辨能力。同时,由于本文中采用的实验数据限制,若应用到更广泛的场景中,需要对模型的一些设置进行适当的调整。在未来的工作中,可以使用多种太阳黑子群磁图信息,比如24 h、72 h 的数据,并且利用深度学习的特征表达,提取太阳黑子群特征并建立模型,同时针对该数据的特点设计专门的卷积神经网络结构,来进一步提高太阳耀斑预报的准确率。
