基于改进天牛群算法优化SVM的个人信用评估
2021-07-06陈静静
陈静静,刘 升
(上海工程技术大学 管理学院,上海 201620)
0 引 言
随着P2P网贷——新型金融服务模式迅猛发展,风险也逐渐显露,其中个人信用风险在众多风险中占据主导地位。因此,个人信用评估是保证这一行业健康发展的关键。近年来,人工智能逐渐兴起,基于机器学习的评估模型逐渐成为信用评估的趋势[1],常用的模型有贝叶斯网络[2]、决策树(decision trees,DT)[3]、神经网络[4]和支持向量机(support vector machine,SVM)[5]等。由于SVM在解决小样本、非线性问题上具有独特的优势,且能够在样本信息有限的情况下化解训练精度与泛化能力之间的矛盾,因此被广泛应用于信用评估领域。SVM的评估性能和泛化能力受参数的影响较大,到目前为止还没有一套完备的理论去解决SVM参数优化问题。
近年来,随着智能算法的飞速发展,越来越多的学者开始将智能算法应用到对SVM参数优化问题上。文献[6]提出了遗传算法优化SVM,但复杂的编码解码过程限制了该优化算法的适用性。文献[7]提出收敛速度快的粒子群(PSO)算法优化SVM的参数,但算法存在易陷入局部极值的问题。文献[8]利用能够跳出局部极值的蚁群(ACO)算法对SVM的参数进行寻优,由于其庞大的计算量,在处理复杂问题时的效果并不佳。文献[9-11]对上述基本算法进行改进,但是这些算法仍然存在容易陷入局部最优、寻优速度慢、对初始值敏感等问题。
天牛群算法[12](beetle swarm optimization,BSO)自提出以来,在众多领域得到广泛应用,如文献[13]用BSO算法来规划三维路径,文献[14]利用BSO算法优化对光伏最大功率点追踪的速度和精确度。该文将天牛群算法用于对SVM参数优化的问题。为了改善传统BSO算法迭代速度慢、寻优精度低等问题,该文对BSO算法进行了改进。为了协调寻优速度与解精度,引入了正态函数对步长进行优化;天牛速度更新时,不仅仅考虑了其向全局最优和个体最优学习的因素,还考虑到天牛通过自身判断对速度更新产生的影响,并利用改进的收缩算子对学习因子进行了调整。最后将改进的天牛群算法用于SVM的参数寻优,将SVM训练集分类准确率作为优化目标建立目标函数,选择最优的SVM惩罚因子和核参数。利用UCI中的Wine、Iris、Ionosphere、Breast Cancer(BC)对改进模型的有效性进行了验证。最后利用随机森林算法,在不影响评估结果精度的前提下,剔除干扰数据,选取关键特征,并将处理过的信用数据German作为IBSO-SVM模型的输入数据进行实例分析。
1 改进的天牛群算法(improved beetle swarm optimization,IBSO)
天牛须算法(beetle swarm algorithm,BSA)是基于天牛觅食规律而开发的一种新的人工智能算法,天牛觅食时,通过它的两根触须感受的食物浓度不同来决定下一步的运动方向,若左须感受到食物气味较右须强,则天牛向左须方向移动。反之,则向右须方向移动。
1.1 天牛群优化算法
随着研究的不断深入,学者发现BSA算法处理高维函数时的性能并不强,且对初始位置敏感。受群体优化算法的启发,将粒子群的思想融入到BSA算法中,提出了天牛群算法。用粒子群的飞行速度来代替天牛的方向,产生天牛种群并加入了向个体极值和群体极值学习的思想。生成的n只天牛用X=(X1,X2,…,Xn)表示,在m维空间中的第i只天牛的速度可表示为vi=(vi1,vi2,…,vis),第i只天牛的个体极值为pi=(pi1,pi2,…,pim),全局极值为pg=(pg1,pg2,…,pgm),第i只天牛的位置更新如公式(1)所示:
(1)

(2)
(3)
公式(2)中的c1和c2为学习因子,取值为2,r1和r2为[0,1]范围内的随机数。w为惯性权重,更新公式如式(4)所示:
w=wmax-(wmax-wmin)*t/maxt
(4)
其中,wmax=0.9,wmin=0.4,maxt为最大迭代次数。
1.2 改进的天牛群算法
传统的天牛群算法在速度更新时只考虑个体向全局极值和局部极值学习的行为,而忽略了天牛个体对周围环境所做出的判断,该文在对天牛速度更新时综合考虑了各种影响因素。为了更好地协调全局和局部搜索,引入了改进的收缩因子对学习因子进行调整,速度的更新表达式如公式(5)所示,收缩因子的表达式如公式(6)所示。
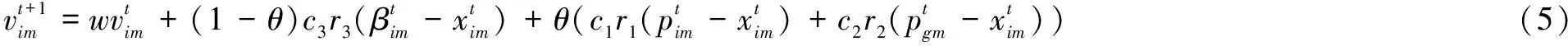
θ=1-1/(e-1)*(et/maxt-1)
(6)
为了兼顾寻优速度与解精度,该文引入正态分布函数作为调整步长的算子。该函数前期缓慢减少,有利于提高寻优速度,后期高速下降,达到提高解精度的目的,函数表达式如公式(7)所示:
g(t/maxt)=e-π*t/maxt
(7)
改进后的步长调整公式可表示为:
δt+1=δt*e-π*t/maxt
(8)
2 IBSO-SVM及混合模型的建立
2.1 IBSO优化SVM的参数
由于该文主要优化的参数为惩罚因子(C)和核参数(g),因此将IBSO种群放置到二维空间进行寻优,每个天牛的位置都代表着一对参数(C,g),将分类正确率作为寻优的目标函数,利用IBSO算法优化SVM的参数,选取最优的(C,g)组合来训练SVM,使得训练后的模型在测试集上能取得较高的分类准确率。
2.2 随机森林特征选择
随机森林(random forest,RF)在以决策树为基学器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。
利用随机森林计算某个特征的重要性的具体步骤如下:
(1)计算每棵决策树的袋外数据(out of bag,OOB)误差,记为erro1。
(2)对所有OOB数据的特征X加入干扰信息,重新计算袋外数据误差,记为erro2。
(3)特征X的重要性为∑(erro2-erro1)/k,k为袋外数据的个数。之所以这么表示特征重要性,是因为加入噪声之后,OOB的准确率若出现大幅度减少,则说明该特征对预测结果有很大的影响,即该特征的重要性较大。
2.3 随机森林融合IBSO-SVM
由于信用数据纷繁复杂,特征多且有连续与离散两种类型,故从高维数据中挑选出有效的特征对最终的信用评估结果起着至关重要的作用。该文首先利用随机森林对信用数据进行预处理,剔除干扰特征,而后将处理过的数据作为IBSO-SVM模型的实验数据。混合模型进行信用评估的具体步骤如图1所示。
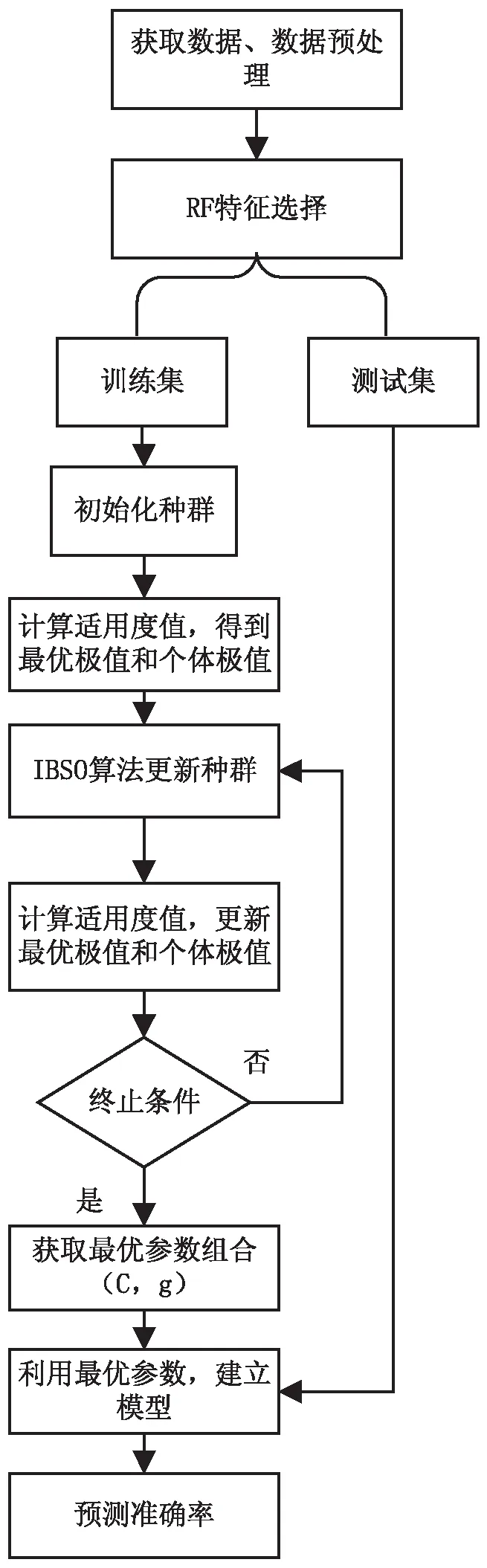
图1 随机森林融合IBSO-SVM的流程
步骤1:获取信用数据German,设置种群数量n、最大迭代次数maxt,设定C和g的取值范围。
步骤2:数据预处理。预处理数据是为了消除量纲,规范化数据。
步骤3:利用随机森林进行特征筛选。
步骤4:数据集划分。将数据集划分为训练集和测试集两部分。训练集用于选择较优性能的SVM模型;测试集用于检验优化后的SVM模型的分类性能。
步骤5:初始化天牛群位置。由于该文需要优化的参数为SVM的惩罚参数(C)和核参数(g),因此将天牛群搜索的空间设置为二维,每个天牛的位置代表一对参数(C,g)。
步骤6:由K折交叉验证法计算每个天牛个体的适应度值,记录当前个体及种群最优值。
步骤7:利用改进后的IBSO对天牛位置进行更新。
步骤8:计算位置更新后的适应度值,通过适应度值的比较,更新个体位置,并获取新的种群。
步骤9:判断算法是否满足终止条件;若满足,则转到步骤10,否则,转到步骤7。
步骤10:获取最优参数(C,g)。
步骤11:采用最优参数对训练样本进行训练建模。
步骤12:采用建好的模型对测试样本进行检测。
步骤13:输出最优参数(C,g)及分类准确率。
3 仿真实验及分析
为了验证IBSO优化SVM参数的有效性,与遗传算法(GA)、粒子群算法(PSO)、乌鸦算法(CSA)、天牛群算法(BSO)的SVM参数寻优性能进行对比。利用UCI中公开的信贷数据对随机森林融合IBSO-SVM的模型进行实例分析,并将实验结果与基本算法及其他文献算法进行对比分析。
3.1 实验数据来源
实验数据来源于UCI库中的公开数据。实验环境为Windows 10操作系统,CPU为 Intel 3.20 GHz,8 GB内存,编程工具为Matlab 2018b。所有的实验都采用了5折交叉验证。数据集描述如表1,考虑样本差距较大,对数据进行归一化处理。德国的信贷数据特征描述如表2所示。

表1 数据集描述

表2 德国信贷数据集描述
3.2 参数设置
种群数量的大小均为20,最大迭代次数为100。BSO初始步长step=10,两须间距d=2,速度范围V=[5.12,-5.12];GA算法的交叉率为0.8,变异率为0.05;PSO算法的惯性权重、学习因子与BSO算法的设置相同;CSA飞行长度F=2.5,辨识率AP=0.1。
3.3 评价标准
对IBSO-SVM模型的评价主要以分类正确率为依据,将混淆矩阵作为混合模型的评估工具,混淆矩阵见表3。依据混淆矩阵,该文选取整体正确率(Accuracy)、Recall值、特异度(Specificity)三个评价指标来评估模型的效果。指标的计算方法如下:

表3 混淆矩阵
3.4 实验结果及分析
通过随机森林挖掘出了German中的重要信用评估指标,各个指标的重要性排序如图2所示,其中X轴表示占比值,Y轴表示变量。

图2 随机森林挑选出的German特征及其重要性排序
该文选取的特征为:A1(0.147 7)、A2(0.139 2)、A3(0.077 7)、A4(0.216 9)、A5(0.066 6)、A6(0.039 7)、A8(0.033 7)、A9(0.060 0)、A10(0.135 9)、A12(0.013 0)、A13(0.021 6)、A16(0.013 191 985)、A17(0.014 9)。
表4所示为GA-SVM、PSO-SVM、CSA-SVM、BSO-SVM、IBSO-SVM在UCI数据上的分类正确率。IBSO-SVM基于随机森林处理过的German数据进行信用评估,并选取SVM、KNN、朴素贝叶斯、决策树、Bagging、AdaBoost、随机森林、信用评分的多目标粒子群优化[15](multi-objective particle swarm optimization for credit scoring,MOPSO-CS)、BP神经网络与AdaBoost混合模型[16](hybrid model of AdaBoost and BP neural network,BP-AdaBoost)作对比实验,得到相应的评价指标数据如表5所示。

表4 各算法的测试集准确率 %
由表4可知,文中算法IBSO-SVM对UCI库中挑选的四个标准数据的分类正确率最高,对数据Wine和Iris的分类正确率甚至达到了100%,可见该改进算法的有效性。
如表5所示,使用上述不同的算法,得到德国信用数据集验证结果。文中提出混合模型的信用评估总精度优于其他算法。在Specificity准确率方面,与其他分类算法相比,提出的混合模型表现最好,即在对德国数据集预测“坏”客户方面,提出的混合模型是最好的,具有令人满意的准确率。对比文中使用所有模型的Recall值和Specificity值,Recall精度明显优于Specificity精度,说明由于信用风险的复杂性,将信用状况较差的客户与信用评价模型良好的客户进行分类比较困难。
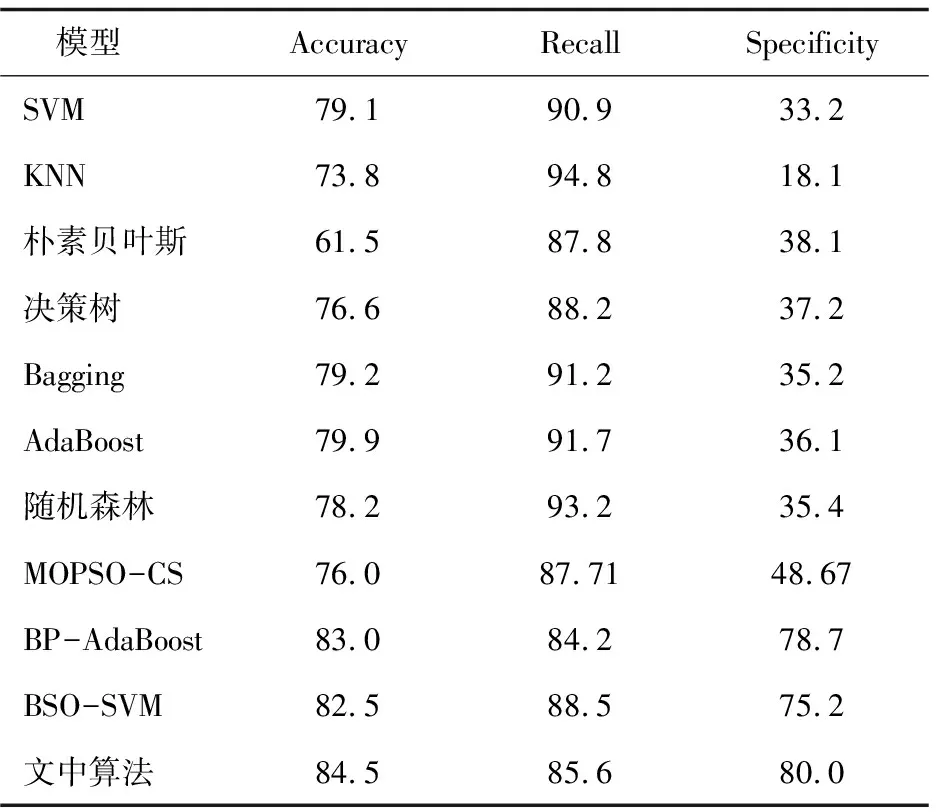
表5 各算法对信用数据的评估结果 %
4 结束语
由于参数选取对SVM的预测性能影响较大,提出改进的天牛群算法(IBSO)优化SVM的参数。速度更新时,增加了天牛的自身判断,并加入改进的收缩因子对学习因子进行调整;利用正态分布函数自适应地调整寻优步长,既保证了寻优速度也提高了解的精度。最后将IBSO参数寻优性能与基本的BSO、GA、PSO和CSA的参数寻优性能进行对比,结果表明IBSO算法具有较好的寻优能力,IBSO-SVM的分类准确率明显高于其他算法。为解决信用风险评估问题,首先利用随机森林对信用数据的特征进行了筛选,并在此基础上,运用IBSO-SVM模型对复杂的信用数据进行评估,实验结果证明了混合模型的有效性,为个人信用评估提供了一种新的可行方法。
