基于多路交叉的用户金融行为预测
2021-07-05程鹏超杜军平薛哲
程鹏超,杜军平,薛哲
(北京邮电大学 智能通信软件与多媒体北京市重点实验室,北京 100876)
随着人们生活水平的提高,人们更加关注对 生活质量的追求,在闲余的时间买卖基金、股票等以获取更多地利润。随着人们金融行为和意识的提升,金融领域的用户行为挖掘可以探究用户的行为规律,通过挖掘用户金融行为的规律与变化,为用户推荐或提供更好的服务。金融大数据中包括结构化文本数据、非结构化文本数据、数值数据等。挖掘金融大数据中用户的金融行为来改进金融领域服务模式,提高金融领域服务质量,已经成为了一个重要的研究方向[1]。
为了有效挖掘金融大数据中用户潜在的金融行为特征,提高金融领域的服务模式和服务质量,本文提出了一种基于多路交叉特征的用户金融行为预测算法(user financial behavior prediction algorithm based on multi-way crossing, MCUP)。首先,根据数据包含的属性构建训练的特征,利用因子分解机模型[2](factorization machines, FM)模型借助下游行为预测任务对金融数据的特征进行预训练,可以获取到数据中特征的隐含向量。对于文本特征而言,利用预训练模型对文本特征进行表示以获得语义丰富的特征向量。然后,引入特征交叉层来对金融数据的较高阶特征进行提取,解决FM线性模型只能提取低阶特征的缺点。同时,利用残差网络结构对金融数据的高阶特征进行提取,解决深度神经网络在提取金融数据高阶特征时会因为网络层数过深而导致梯度消失的问题。最后,利用将FM、特征交叉网络和残差网络结合在一起的多塔模型进行用户金融行为的预测,融合低阶特征与高阶特征进行实验。
本文的主要贡献如下:
1) 提出了一种基于多路交叉的用户金融行为预测方法,结合数据低阶特征和高阶交叉特征对金融大数据用户行为进行预测;
2) 使用预训练FM模型对训练特征隐向量表示进行初始化,加速训练和模型收敛,同时FM可以提取数据特征的一阶和二阶交叉特征;
3) 引入交叉特征层和残差网络提取数据高阶特征,将稀疏的身份(identity, ID)特征表示成稠密向量作为输入,同时考虑到高阶特征对用户行为的预测效果影响。
1 用户行为预测的研究现状
目前现有的用户行为的预测的方法一般分为2种类型,传统的机器学习方法和深度学习方法。对于传统的机器学习方法而言,FM在理论上可以进行任意阶特征的交叉,由于计算复杂度的限制,目前只是用来进行二阶特征交叉。FM核心在于提出了特征隐向量的概念,将原始特征的出现都作为一个特征,每个特征利用稠密的向量来进行表示,解决了多项式特征交叉时交叉系数更新慢的缺点。FM的不足之处在于所有特征对于行为预测的结果影响系数是相同的,导致数据各个特征之间没有区分性。为了解决FM无法区分特征对行为预测性能的影响,文献[3]提出了场敏感因子分解模型(field-aware factorization machines, FFM),FFM是在FM的基础上引入了域概念的行为预测模型。FFM将具有相同性质的特征归结于同一个域,每一维特征针对每一个域都会学习到一个隐向量,所以隐向量不仅仅与单个特征相关而且和域相关。FM和FFM仅仅考虑到了数据的低阶特征,而没有考虑数据高阶交叉特征,类似用户ID和物品ID特征需要深度网络才能提取高阶交叉特征[4]。随着深度学习技术的发展,深度学习在推荐、广告、计算机视觉、自然语言处理、语音识别等领域取得了重要进展,深度学习几乎无限的表达能力被广泛地研究[5]。文献[6]利用结构化和非结构化大数据对商品购买行为进行了预测。文献[7]基于用户行为序列数据和选择模型的方法,对用户金融行为选择出最优的因子模型并预测用户的行为。文献[8]利用支持向量机模型对用户的消费情况进行预测并获得了较好的预测结果。文献[9]结合支持向量机和逻辑回归模型进行了购买行为的预测,进一步提升了金融行为预测的准确性。文献[10]采用改进的决策树构建用户金融行为预测模型,实现了大数据环境下的模型构建和训练。文献[11]构建了Pareto/NBD模型,结合协变量进一步提升了用户购买行为预测的准确率。文献[12]通过改进了传统的预测模型,在产品购买行为数据集上验证了方法的有效性。文献[13]挖掘了用户购买行为规律,分析出了符合用户购买意愿的商品序列。文献[14]构建了线上消费购买率预测模型,预测了未来用户购买的行为规律。文献[15]结合遗传算法与传统算法进行最优模型组合,并通过实验验证了该方法的有效性。
深度学习技术同样也应用到了用户行为预测方面。文献[16]采用CNN-LSTM(convolutional neural network long short term memory)模型预测用户购买行为,利用卷积神经网络(convolutional neural network,CNN)进行特征抽取,通过长短期记忆网络(long short term memory,LSTM)[17]建立时间序列,实现对特征的自动抽取和行为预测。支持因子分解机的神经网络模型(factorization-machine supported neural networks, FNN)[18]就是来解决FM和FFM仅考虑一阶和二阶特征的问题,FNN利用FM作为预训练模型,将训练好的特征的隐向量作为后续深度神经网络的输入,来得到特征的高阶组合。它可以解决类似用户ID没有出现过的泛化问题,但是忽略了低阶特征的重要性,即在数据中频繁出现的低阶特征组合也能显示出用户行为。因此,低阶特征和高阶组合特征对用户行为的预测都很重要。深度因子分解模型(deep factorization machines, DeepFM)[19]提出了双塔模型分别对数据低阶特征和高阶交叉特征进行提取。利用FM模型自动地提取数据一阶与二阶特征,深度神经网络提取数据的高阶特征,通过融合数据低阶特征和高阶特征来进行用户行为的预测,利用FM天然可以自动组合二阶特征和一阶特征的优点来避免人工干预,并且在模型横向和纵向来共享FM的特征隐向量,真正实现了端到端的用户行为预测。DeepFM模型的输入对于连续特征是不友好的,需要把文本特征作为用户行为预测的特征之一,文本特征大多数情况会用一个低维稠密向量来表示。深度交叉网络(Deep&Cross network)[20]共享输入,即deep部分和cross部分输入是相同的,在其输入的时候对于类似文本特征而言会将其与其他特征进行连接作为输入。cross部分在理论上可以做到对高阶特征的组合,而且其参数随输入维度是线性增加的,FM要想对高阶特征进行组合其复杂度是呈指数增长的。Deep&cross虽然既有高阶特征又有低阶特征,但是对于输入的离散特征进行one-hot处理后,特征之间是同等重要的,没有field的概念。
2 基于多路交叉特征的用户行为预测的算法(MCUP)
基于多路交叉特征的用户行为预测的方法的框架如图1所示。
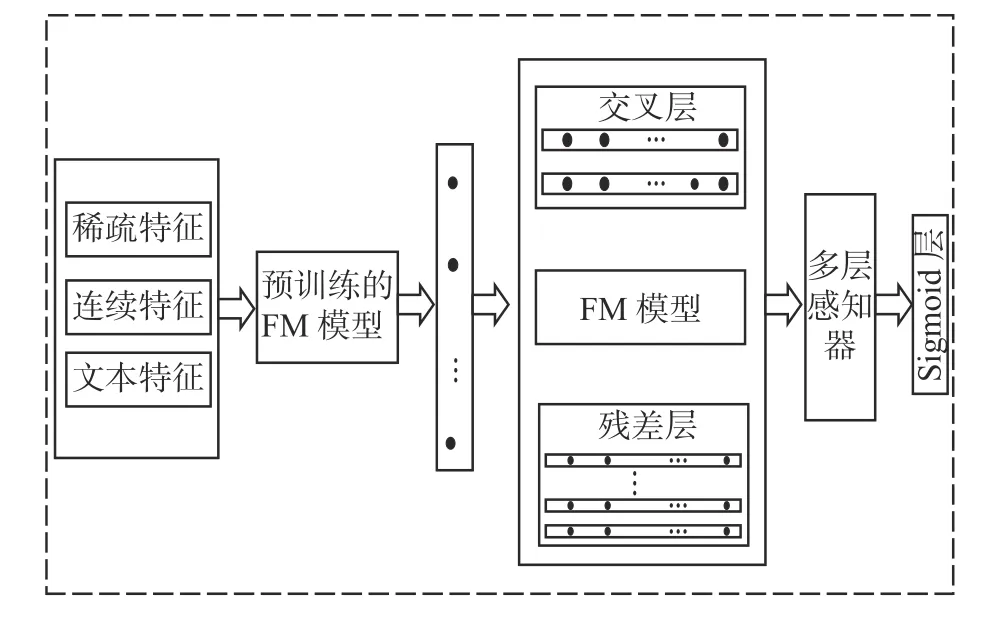
图 1 基于多路交叉特征的用户行为预测框架Fig. 1 The framework of user behavior prediction based on multi-way
模型由3部分构成,如图1所示,左侧模块表示利用预训练FM模型获取离散特征和连续特征的稠密向量表示;中间模块利用交叉层对输入特征进行特征交叉获得较高阶特征向量表示;右侧输入特征经过残差网络模块来提取高阶特征,得到特征的高阶组合。将3个模块的输出特征向量进行连接作为浅层全连接网络的输入,最后得到用户行为的预测结果。
2.1 基于多项式的交叉特征提取
FM模型在理论上可以拟合任意高阶特征,由于FM模型在拟合高阶特征的同时,模型复杂度将会成指数倍增加,所以一般只使用FM到二阶特征交叉。为了在保证模型复杂度低的情况下,对高阶特征进行交叉组合提取,引入基于多项式的交叉特征提取方法。
基于多项式的交叉特征提取方法核心思想是利用乘法计算来进行特征交叉。同样,在理论上基于多项式的交叉特征层可以拟合任意高阶组合特征。主要利用x0xlT这种表达方式来进行特征交叉,使用原始特征与基于多项式的交叉特征层进行乘法运算,使得特征交叉通过一个rank-one的数字来表示,大大减少了模型的参数量。具体为
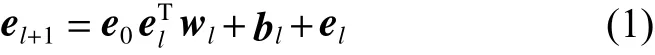
式中:el+1表示l+1层特征向量;e0表示模型原始输入特征向量;wl表示第l层模型参数;bl表示第l层偏移量;el表示第l层特征向量。
每一层的特征都由其上一层的特征进行交叉组合,并把上一层的原始特征重新加回来。这样既能特征组合,自动生成交叉组合特征,又能保留低阶原始特征,随着cross层的增加,可以生成任意高阶的交叉组合特征,且在此过程中没有引入更多的参数,有效控制了模型复杂度。
2.2 基于预训练的分解因子机
FM的核心在于提出了特征隐向量的概念,将原始特征的出现都作为一个特征,每个特征利用稠密的向量来进行表示,解决了由于数据稀疏导致多项式特征交叉时交叉系数更新慢的缺点。FM利用交叉的特征隐向量之间计算得分来代替多项式计算时的特征交叉系数,根据随机梯度下降的计算公式可以计算出参数的更新公式,由参数更新公式可以得出参数的更新只要交叉特征中的一个值不为0即可,从而解决了百万级的类别特征经过one-hot编码后数据特征稀疏的问题。本文提出利用下游任务去预训练FM模型,使用预训练FM模型对MCUP算法中FM模块进行初始化,以达到加速模型训练和收敛。
FM一般只用到二阶特征组合,为

式中:θ0表示偏置参数;θi表示一阶特征的参数;θij表示二阶组合特征的参数;xi表示第i个特征;xj表示第j个特征。

式中:vi、vj分别表示第i、j个特征对应的隐向量;其他表示含义同式(1)。
在MCUP算法中利用预训练FM模型对数据中的特征进行预训练,类似自然语言处理中词向量的操作方式,可以获得数据特征的隐向量表示。利用预训练FM模型对MCUP算法进行初始化,可以通过数据集对特征隐向量进行微调获得更好的用户行为预测的效果。
2.3 基于残差网络的高阶特征提取
线性回归(linear regression, LR)算法、FM算法等仅仅考虑到了低阶特征的组合,在下游任务中低阶特征可以记住用户历史行为,从而对下游任务的目标起到正向作用。但是在收集到的数据中存在大量的ID类特征,即One-hot操作后会得到离散稀疏的向量表示,通常ID类特征在特征组合中起到非常重要的作用。高维离散特征通用的处理方式是使用One-hot进行表示后,利用LR算法进行用户行为预测等下游任务。随着深度神经网络和嵌入方法的发展更新,高维离散特征不仅使用One-hot进行表示,后续还使用词嵌入的方法对ID类特征进行嵌入学习,使用低维稠密特征对ID类特征进行表示。
基于残差网络的高阶特征提取方法将ID类特征和连续型特征放在一起作为模型输入,利用深度神经网络中的残差概念来将网络做深。随着网络深度的增加,特征不断进行交叉组合,最后得到具有泛化能力的高阶特征。残差网络的计算为

式中:el表示第l层的输出特征;el-1表示第l层的特征输入;wl表示第l层的模型参数。
3 实验与结果
3.1 度量标准
评价用户行为预测结果好坏的指标一般可以使用精确率、召回率、F1。在实际场景中,也用AUC和MAP来表示模型效果的好坏。
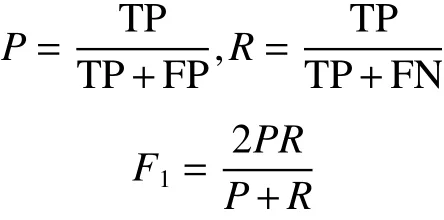
式中:TP表示标记为真正例;FP表示标记为假正例;FN表示标记为假反例;TN表示标记为真假例。
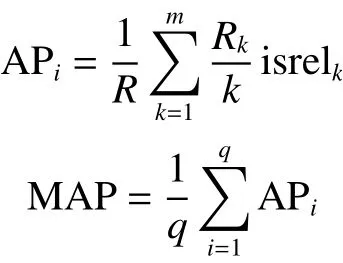
式中:m表示与第i个查询相关的数据数量;Rk表示相关性排序前k个数据中与查询数据相关的数据数量;isrelk表示第k个数据是否与查询相关,如果相关值为1,反之为0;q表示查询集合中数据数量;APi表示第i个查询的平均精确率。
3.2 数据集
实验数据为2019年天弘基金用户点击行为、2019年长信基金用户点击行为和鹏华基金用户点击行为。点击基金的用户行为表示用户在界面点击基金对基金基本信息进行查看。基金数据集详细描述见表1。

表 1 基金数据集Table 1 Fund dataset
3.3 实验和结果
为了验证基于多路交叉特征的用户行为预测(MCUP)算法的有效性,在3个不同的基金数据集上对用户点击行为进行预测。对于每个基金数据集设置3组对比实验,MCUP算法分别与FM算法、FNN算法和Deep&Cross算法。利用精确率、召回率、F1和MAP对MCUP算法的性能进行评测,特别地在计算MAP指标的时候选取前2、4、6、8和10结果来进行统计,从而验证MCUP算法在用户行为预测任务的有效性。
根据表2可以看出,MCUP算法在MAP@2、MAP@4、MAP@6、MAP@8和MAP@10指标均优于传统的FM与基于深度学习的FNN算法和Deep&Cross算法。在天弘基金数据集上,用户点击基金信息的行为预测任务中MCUP算法相较于Deep&Cross算法而言,在MAP@2、MAP@4、MAP@6、MAP@8和MAP@10上分别高0.7%、0.5%、0.8%、0.7%、1%。MCUP算法使用预训练FM模型对特征隐向量进行初始化,相对于Deep&Cross算法具有更好的收敛速度和预测效果。MCUP算法比起传统的FM算法在MAP@10提升最大,FM算法仅仅考虑到一阶和二阶特征对用户点击行为预测结果的影响,MCUP算法不仅考虑了低阶特征,而且使用残差网络来提取高阶交叉特征。

表 2 MCUP与对比算法在天弘基金数据集上点击MAPTable 2 MAP of MCUP and comparison algorithm click behavior on Tianhong fund dataset
根据图2可以看出,MCUP算法在前2、4、6、8和10的数据中F1指标均优于对比算法。在天弘基金数据集上,用户点击基金信息的行为预测任务中,MCUP算法相对于FM算法在top@2上提升最大,MCUP算法同时考虑了低阶特征和高阶交叉特征对用户点击行为预测的影响,利用残差网络隐式地提取数据高阶交叉特征和FM算法获取数据一阶和二阶特征。

图 2 MCUP与对比算法在天弘基金数据集上点击F1曲线Fig. 2 F1 curves of MCUP and comparison algorithm click behavior on the Tianhong Fund dataset
根据表3可以看出,MCUP算法在MAP@2、MAP@4、MAP@6、MAP@8和MAP@10指标均优于传统的FM与基于深度学习的FNN算法和Deep&Cross算法。在长信基金数据集上,用户点击基金信息的行为预测任务中MCUP算法在MAP@2、MAP@4、MAP@6、MAP@8和MAP@10上比FNN分别高1.8%、1.6%、1.9%、1.6%、1.7%。MCUP算法不仅使用预训练FM算法对特征隐向量进行初始化,利用FM提取低阶特征并且使用残差网络提取高阶交叉特征,而FNN算法只利用预训练的FM算法进行高阶交叉特征的提取,没有考虑低阶特征对于用户点击行为预测的影响。MCUP算法比具有相似结构的Deep&Cross算法在MAP@10提升最大,Deep&Cross算法没有考虑到一阶和二阶特征对用户点击行为预测结果的影响,MCUP算法利用FM来进行低阶特征的提取。

表 3 MCUP与对比算法在长信基金数据集上点击MAPTable 3 MAP of MCUP and comparison algorithm click behavior on Changxin fund dataset
根据图3可以看出,MCUP算法在前2、4、6、8和10的数据中F1指标均优于对比算法。在长信基金数据集上,用户点击基金信息的行为预测任务中,MCUP算法相对于Deep&Cross算法在top@6以后提升的幅度逐渐增大,相较于Deep&Cross算法的Deep神经网络,MCUP算法使用残差网络隐式地提取数据高阶交叉特征,具有更强的表达能力。

图 3 MCUP与对比算法在长信基金数据集上点击F1曲线Fig. 3 F1 curves of MCUP and comparison algorithm click behavior on the Changxin fund dataset
根据表4可以看出,MCUP算法在MAP@2、MAP@4、MAP@6、MAP@8和MAP@10指标均优于传统的FM算法、FNN算法和Deep&Cross算法。在鹏华基金数据集上,用户点击基金信息的行为预测任务中MCUP算法相较于Deep&Cross算法而言,在MAP@2、MAP@4、MAP@6、MAP@8和MAP@10上分别高0.3%、0.2%、0.3%、0.2%、0.4%。MCUP在MAP@10上的性能最好,说明MCUP算法能够尽可能地将用户点击过的基金数据排到前面。MCUP算法融合低阶特征和高阶交叉特征对用户点击行为进行预测,极大地挖掘了用户潜在的兴趣意图。

表 4 MCUP与对比算法在鹏华基金数据集上点击MAPTable 4 MAP of MCUP and comparison algorithm click behavior on Penghua fund dataset
根据图4可以看出,MCUP算法在前2、4、6、8和10的数据中F1指标均优于对比算法。在鹏华基金数据集上,用户点击基金信息的行为预测任务中,MCUP算法相对于FNN算法提升更加平稳且F1性能更优,MCUP算法利用特征交叉层显示进行数据特征的有限阶交叉,而且使用残差网络隐式地进行数据高阶特征的提取,同时考虑了低阶特征和高阶交叉特征对用户点击行为预测的影响。

图 4 MCUP与对比算法在鹏华基金数据集上点击F1曲线Fig. 4 F1 curves of MCUP and comparison algorithm click behavior on the Penghua Fund dataset
4 结束语
为了有效挖掘金融大数据中用户潜在的金融行为特征,本文提出了一种基于多路交叉特征的用户金融行为预测算法。首先,利用FM模型对金融数据的特征进行预训练,获取到数据中特征的隐含向量。然后,引入特征交叉层和残差网络结构来对金融数据的较高阶特征进行提取,解决了FM线性模型只能提取低阶特征、模型无法有效训练等问题。最后,将FM、特征交叉网络和残差网络结合为统一的多塔模型进行用户金融行为的预测。在多个金融行为预测数据集上的实验结果表明,本方法能够有效融合金融大数据的低阶特征与高阶特征,并准确地预测了用户的金融行为。
