面向推荐系统的分期序列自注意力网络
2021-07-05鲍维克袁春
鲍维克,袁春
(1. 清华大学 计算机科学与技术系,北京 100084; 2. 清华大学 深圳国际研究生院,广东 深圳 518000)
随着互联网的普及,互联网应用的用户数量空前增长,阿里巴巴集团公布截至2019年12月31日的季度业绩显示[1],其中国零售市场移动月活跃用户达8.24亿,创12个季度以来新高。诸多互联网公司在庞大的用户数据之上采用智能推荐算法提高产品的可用性和用户体验。然而经典的推荐算法往往存在一些问题:1)对于用户反馈(user-item interactions)数据表现出的相互依赖和序列性分析不足;2)对反馈数据和上下文的动态性应对不足;3)模型往往固定表达了用户的长期/一般偏好,而非基于反馈数据对长期/一般偏好进行表达。
为此,本文提出了一种面向推荐系统的分期序列自注意力网络(long-term & short-term sequential self-attention network,LSSSAN)。“分期”表示将用户的反馈数据分为长期和短期,用户的长期反馈数据反映了用户的长期/一般偏好,用户的短期反馈数据反映了用户的短期偏好和序列性偏好;注意力(attention)机制,可以为不同的数据赋予不同的权重,帮助模型动态捕捉数据中重要的信息,自注意力(self-attention)机制在此基础上,可以有效地捕捉长序列数据之间的相互依赖。本模型中,自注意力机制从用户长期反馈数据提取用户的长期/一般偏好,GRU(gate recurrent unit)从用户短期反馈数据的提取用户的序列性偏好,最后由以上所得综合用户短期反馈数据表现出的短期偏好参与注意力机制,得到了用户的综合偏好。总体来讲,本文模型的亮点如下:
1)采用注意力机制为不同的反馈数据赋予不同的权重以动态捕捉重点信息,同时也考虑了不同用户和不同item候选集对推荐结果的动态影响;
2)自注意力机制捕捉了长期反馈数据之间的长期相互依赖,准确地表达了用户的长期/一般偏好,而非基于用户特征固定地表达长期/一般偏好;
3) GRU捕捉了短期反馈数据的序列性并参与注意力机制赋权,GRU层输入数据的顺序相关性的强弱会影响注意力机制赋予序列性表示的权重,进而准确表达了用户的序列性偏好;
4)在数据集上实验的评价指标整体优于主流的推荐算法。
1 研究背景
1.1 推荐系统的一般任务
通常来说,推荐系统的一般模型可以用以下形式表达,如图1所示。

图 1 推荐系统一般模型的结构Fig. 1 Structure of general recommendation system model
图1中,item表示推荐系统中的项(item可以为商品、视频等),一个用户的反馈数据记录由多个item组成,Model表示推荐模型,推荐系统的任务是将合适的item推荐给用户。u表示用户 u 的特征表示;Lu表示用户 u 的用户反馈数据序列,由多个item组成,为用户 u 的用户反馈数据序列Lu中的一项;表示可能被推荐的候选item集合中的某一候选item;推荐系统基于以上内容,计算用户 u 的综合偏好表示并通过计算用户 u 对候选item的偏好得分,得分越高说明用户 u 越倾向于选择候选item
1.2 相关工作
传统的推荐系统如基于内容推荐和协同过滤推荐,均是以静态方式对用户反馈数据进行建模,对用户反馈数据的信息提取不够充分。而序列推荐模型将用户反馈数据视为序列,考虑了用户反馈数据的序列性和相互依赖,进而准确估计了用户的偏好[2-4]。
在序列推荐模型中,用户反馈数据序列由较长的用户反馈数据组成,使得用户反馈数据序列具有更复杂的依赖特性。对于用户反馈数据序列的处理,其中两个主要的难点[2]是:
1)学习高阶顺序依赖
高阶顺序依赖在用户反馈数据序列中普遍存在,低阶依赖的可以用马尔科夫模型[5]或因子分解机[6-7]解决,高阶顺序依赖由于反馈数据的多级级联,模型往往难以表达。针对此问题,目前主要的两种方案:高阶马尔科夫链模型[8]和RNN(recurrent neural network)模型[9]。但是,高阶马尔可夫链模型因参数数量随阶数呈指数增长,其分析的历史状态有限;而单一的RNN模型难以处理具有非严格顺序相关性的用户反馈数据序列。
2) 学习长期顺序依赖
长期顺序依赖指序列中彼此远离的用户反馈数据之间的依赖性。文献[9-10]分别使用LSTM(long short-term memory)和GRU(gate recurrent unit)来解决这个问题。但是,单一的RNN模型依赖于序列中相邻项的强相关性,对于弱相互依赖性和非严格顺序相关性的数据处理表现不佳。文献[11]通过利用混合模型的优势,将具有不同时间范围的多个子模型组合在一起,以捕获短期和长期依赖关系。而注意力机制考虑了用户反馈数据之间的联系却不依赖于数据的相邻关系,阿里Deep Interest Network[12]、Next Item Recommendation with Self-Attention[13]、Sequential Recommender System Based on Hierarchical Attention Networks[14]等,通过注意力机制,模型能够计算出用户反馈数据的相对权重以动态捕捉重点信息,进而准确估计了用户的偏好表示。
2 分期序列自注意力网络
本文提出了一种分期序列自注意力网络(longterm & short-term sequential self-attention network,L SSSAN)进行序列推荐。
2.1 问题表述
在基于LSSSAN的推荐系统中:u表示用户 u的特征表示;Lu表示用户 u 的用户反馈数据序列,如用户点击、购买的item序列;vuj∈Lu表示用户 u 的用户反馈数据序列Lu中的一项item;Lucand表示可能被推荐的候选item集合;vu3j∈Lcuand表示候选item集合Lucand中的一项。
文献[6, 9]表明短期反馈数据对推荐结果有着重要影响,结合长期和短期反馈数据能够准确反映用户的综合偏好;文献[14]的工作利用用户长期反馈数据充分表达了用户的长期/一般偏好,并结合短期反馈数据表达的短期偏好准确估计了用户的综合偏好。基于此,本文将用户反馈数据Lu划分为用户长期反馈数据Lluong和用户短期反馈数据Ls
uhort(在本文的实验环节,将一天内的反馈数 据为短期反馈数据)。长期用户反馈数据Lluong反映了用户的长期/一般偏好,短期用户反馈数据反映了用户近期的短期偏好和序列性偏好。举例来说,用户A是个运动爱好者,平时喜欢购买一些运动设备,有一天,用户A由于手机损坏,购买了手机和手机保护膜。此时如果基于用户A的长期/一般偏好,推荐系统会更偏向于给用户A推荐运动相关的item,而如果基于用户A的短期偏好,推荐系统则会偏向于给用户A推荐手机相关的item,考虑到用户A短期购买日志(先后购买手机和手机保护膜)的序列性,推荐系统则可能会向用户A推荐手机保护壳。
LSSSAN基于以上内容,估计用户的综合偏好,并利用用户u的综合偏好计算用户 u 对候选项itemv3jcand的偏好得分,得分越高说明用户 u 越倾 向于选择候选项itemv3jcand。
2.2 模型结构
在序列推荐的场景中,用户偏好往往有以下的特点:1)用户反馈数据往往是长序列,用户反馈数据存在着复杂的相互依赖关系;2)短期用户反馈数据和其表达的序列性,影响推荐结果的重要因素;3)相同的item,在不同的候选item集合或不同的用户下,对于推荐结果有不同的影响;4)在考虑不同的item对于结果的影响时,应对不同的item赋予不同的权重以动态捕捉重点信息。
基于此,本文设计了LSSSAN模型,网络结构如图2所示。
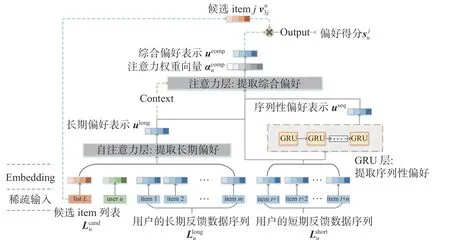
图 2 分期序列自注意力网络的结构Fig. 2 Structure of LSSSAN
Embedding层:对用户、可能被推荐的候选item集合、用户反馈数据的特征的稀疏表示进行embed,转化为稠密的embedding表示。
自注意力层:在推荐系统中,应用注意力机制,可以为不同的用户反馈数据赋予不同的权重,以动态捕捉重点信息,反映了不同的用户反馈数据对推荐结果影响的差异性。自注意力机制是一种特殊的注意力机制,由于在机器翻译领域的成功表现,自注意力机制逐渐走入研究者们的视野[15]。自注意力机制在动态赋权的同时,捕捉了用户反馈数据之间的相互依赖,并且自注意力机制在长序列的数据上表现出色。文献[13]的工作将自注意力机制应用于从用户短期反馈数据上提取用户的短期偏好,但这项工作忽视了用户长期反馈数据在序列推荐中的作用,同时自注意力机制对短期反馈数据的序列性分析不足。基于此,本文考虑将自注意力机制应用于用户长期反馈数据,结合用户和候选item集作为上下文,得到用户长期/一般偏好的表示。

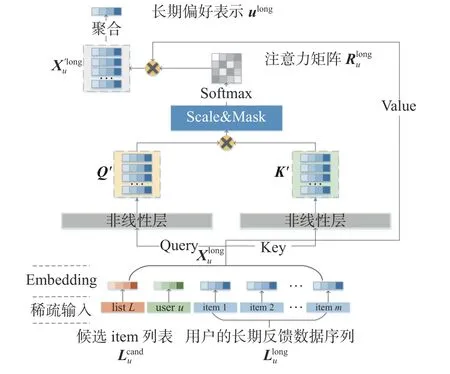
图 3 自注意力层的结构Fig. 3 Structure of self-attention net


式(1)和(2)中的,WQ∈Rd×d=WK∈Rd×d分别为Query和Key非线性表示层的权重参数,ReLU(·) 在本模型中表示Leaky_ReLU激励函数,Q′和K′分别表示Query和Key的非线性表示。Leaky_ReLU是ReLU的变体,解决了ReLU函数进入负区间后,导致神经元不学习的问题。




式中,对Xu′long聚合(如sum、max,这里采用均值),得到了用户长期/一般偏好的表示ulong∈R1×d。
GRU(gate recurrent unit)层:与利用自注意力层提取用户长期反馈数据之间的相互依赖不同,用户短期反馈数据的重点是提取用户短期反馈数据中的序列性偏好。GRU是RNN的一种,解决了长期记忆和反向传播中的梯度等问题,且易于计算[16]。模型将用户短期反馈数据Lsuhort输入GRU,计算得到短期反馈数据表现出用户的序列性偏好表示useq。模型GRU层的公式化表示如下:
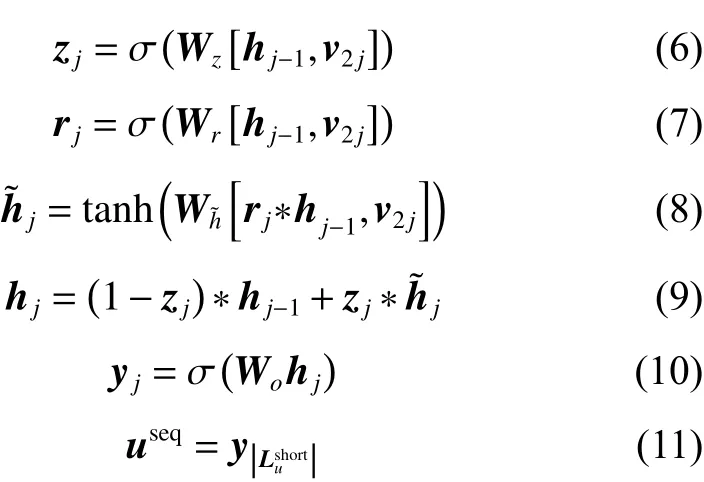



2.3 模型的参数学习
由模型的前向传递得到了用户综合偏好的表示ucomp,现在用内积方法如式(15)所示,表示ucomp和候选item v3j∈Lcuand的相似度,以表示用户u 对候选item v3j的偏好得分 suj:

在隐反馈的推荐系统场景中,用户往往没有对item的具体评分,而只是交互记录。这种情况下,推荐系统只有正样本而缺乏负样本,模型的训练效果会因此受到影响[17]。
可以简单地将与用户没有交互记录的item作为用户的负样本,从而构造负样本集。而模型只需要和正样本集差不多大的负样本集,这种做法会造成负样本集庞大,且负样本集的质量低下。
BPR方法[18]是一种基于矩阵分解的方法,一对用户交互与未交互的两个item项构成偏序关系对,一个用户下item之间的偏序关系形成偏序矩阵,遍历用户集建立预测排序矩阵,BPR方法对预测排序矩阵分解生成用户矩阵和item矩阵,用户矩阵和item矩阵相乘可以得到用户对每个item偏好程度。利用BPR方法生成低偏好程度的负样本集,大小与正样本集等同,参与训练。
模型的Loss函数定义如下:

式中:D 表示用户、正样本、负样本构造的训练集;suj表示用户 u 对正样本候选item j的偏好得分;s′uk 表示用户 u 对负样本候选item k的偏好得分; σ (·) 表示sigmoid函数。第一个加号后的3项为正则项,Θe表示embedding层的权重参数;ΘA表示自注意力层和注意力层的权重参数;Θseq表示GRU层 的权重参数,λe、λA、λseq为对应的正则项系数。
3 实验分析
3.1 实验概述
数据集:本文选择Tmall数据集[19]和Gowalla数据集[20]为模型进行训练和测试,其中Tmall数据集是在中国最大电商平台Tmall.com场景下的用户行为日志数据集,Gowalla数据集是在社交签到类应用Gowalla场景下的用户行为日志数据集。
在实验过程中,仅考虑7个月内在两个数据集上生成的数据,并将1天内的用户反馈数据视为表示短期反馈数据序列。
评价指标:选择召回率(Recall)和AUC作为评价指标。召回率表示为用户推荐偏好程度排序前N项的样本为预测的正样本,计算被正确预测的正样本在原始正样本集中比例;而AUC衡量了模型对样本正确排名的能力。
方法对比:与其他先进模型在Tmall数据集和Gowalla数据集上的表现为对比[6,8,13-14,18,21](以其他文献在Tmall数据集和Gowalla数据集上给出的实验数据,或在Tmall数据集和Gowalla数据集复现的结果为准),以验证模型的有效性:1) BPR是一种基于矩阵分解的方法,BPR方法对useritem偏序关系矩阵分解得到user矩阵和item矩阵,user矩阵×item矩阵得到用户对每个item偏好程度,依据偏好程度排序得到推荐列表;2) FOSSIL利用马尔科夫链估计用户的短期和长期偏好;3) HRM对用户偏好进行层次表示,捕获用户的长期/一般偏好和短期偏好;4) FPMC通过矩阵分解、马尔科夫链提取序列信息,以估计用户偏好,最后以线性方式计算得到推荐列表;5) AttRec利用自注意力机制在分析用户短期反馈数据之间的相互依赖的同时,动态提取了用户的短期偏好;6) SHAN利用注意力机制对长期和短期反馈数据建模,准确表达了用户的长期/一般偏好;7) LSSSAN是本文的模型,利用自注意力机制和上下文估计长期/一般偏好,利用GRU分析短期反馈数据表现出的序列性偏好,并综合长期/一般偏好和短期反馈数据序列参与注意力机制加权得到用户的综合偏好;8) LSSSAN1和LSSSAN2为本模型消融实验的对照,LSSSAN1表示LSSSAN模型消去自注意力层后的模型(同时将长期反馈数据接入注意力层,自注意力层的上下文向量接入注意力层),LSSSAN2表示消去GRU层的模型。
3.2 方法对比
图4和图5展示了以召回率(N为10~60)和AUC为评价指标,各方法在Tmall数据集和Gowalla数据集上的表现。

图 4 各方法在Tmall和Gowalla数据集上表现的对比Fig. 4 Performance comparsion of methods on Tmall and Gowalla datasets
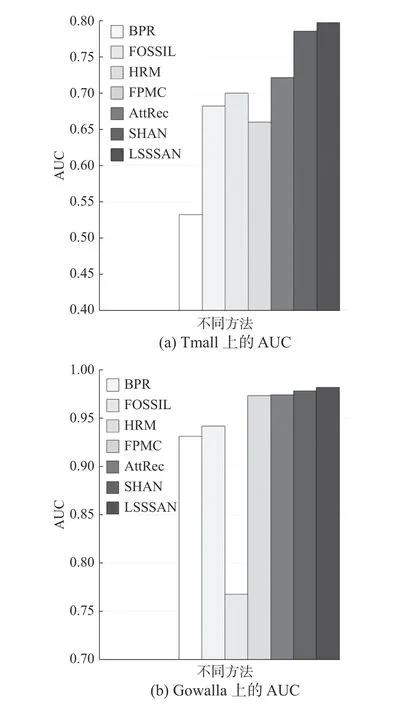
图 5 各方法在Tmall和Gowalla数据集上表现的对比Fig. 5 Performancecomparsion of methods on Tmall and Gowalla datasets
1) LSSSAN在整体上优于基于自注意力的AttRec模型,LSSSAN在Tmall数据集上召回率(N为20)和AUC分别为0.126、0.797,在Gowalla上两个指标分别为0.461、0.982。相比AttRec模型,LSSSAN在两个数据集上指标召回率(N为20)分别提升了6.07%和20.49%,在两个数据集上AUC指标分别提升了10.45%和0.81%。表明相比AttRec模型固定表达用户的长期/一般偏好、忽视序列性偏好,LSSSAN的Self-Attenion层从长期反馈数据中提取了用户的长期/一般偏好、GRU层从短期反馈数据中提取了用户的序列性偏好、并从结构上赋予了短期反馈更高的权重,对推荐结果更有利。
2) LSSSAN在Gowalla数据集上的表现整体优于SHAN模型,在Tmall数据集上的表现与SHAN模型相比各有优劣。LSSSAN在Gowalla数据集上指标召回率(N为20)和AUC分别提升了1.51%和0.37%,在Tmall数据集上指标AUC分别提升了1.48%,而在Tmall数据集上指标召回率(N为20)落后于SHAN模型14.6%。其原因是Gowalla数据集用户反馈数据之间的相互依赖和顺序相关性比Tmall数据集严格,本文模型相比SHAN模型利用自注意力机制和GRU着重捕捉了用户反馈数据之间的相互依赖和序列性,因此在Gowalla上LSSSAN的表现整体优于SHAN模型,而在Tmall数据集上的表现的稳定性不如SHAN模型。同时文献[22]也表明,对于相互依赖和序列性强的签到类型数据集,结合GRU的模型有较好的效果。综上所述,相比SHAN对长期数据的相互依赖分析不足、忽视序列性偏好,LSSSAN的Self-Attenion层分析了长期数据的相互依赖、GRU层提取了序列性偏好,在推荐结果上具有更好的表现。
3.3 消融实验
图6和表1展示了消融实验在Tmall和Gowalla数据集上的对照数据。
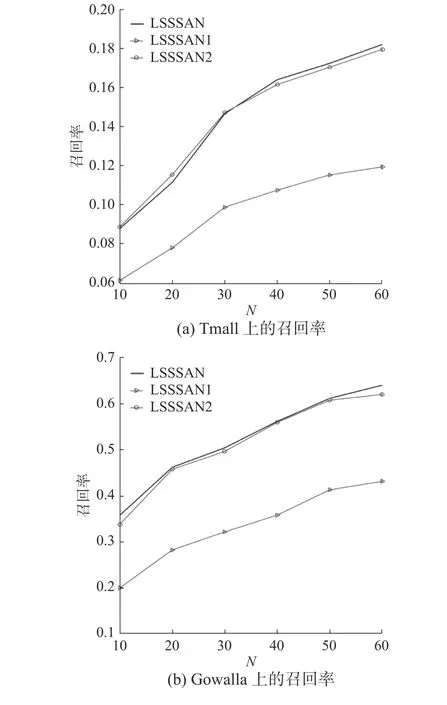
图 6 LSSSAN在Tmall和Gowalla数据集上的消融实验对照Fig. 6 Ablation study of LSSSAN on Tmall and Gowalla Datasets
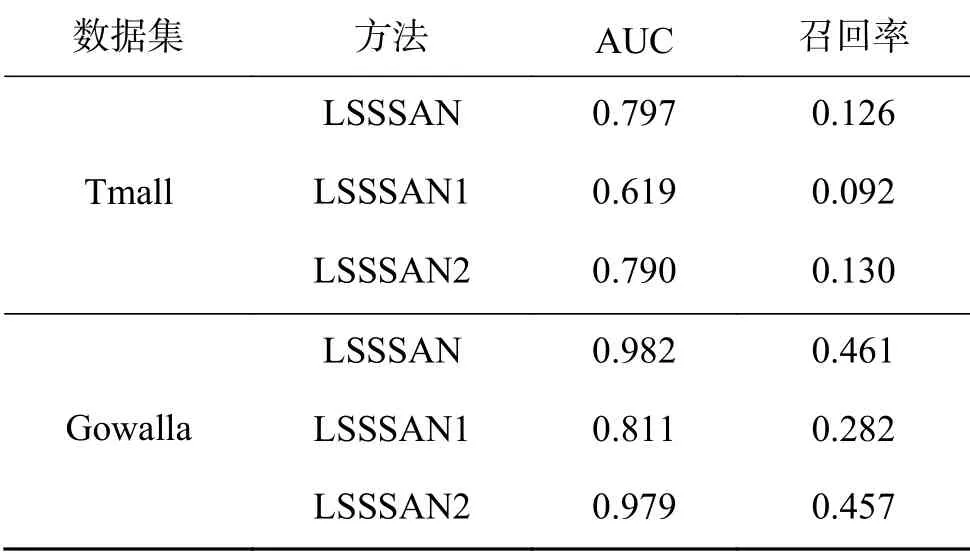
表 1 消融实验对照表Table 1 Results table of ablation study
LSSSAN1为LSSSAN消去自注意力层后的模型,在两个数据集上表现不佳。相比LSSSAN、LSSSAN1在两个数据集上指标召回率(N为20)分别降低了26.98%和38.83%,其原因主要是消去自注意力层后模型缺乏对长期/一般偏好的表达,也降低了相对重要的短期反馈数据在模型中的权重。
LSSSAN2为LSSSAN消去GRU层后的模型,LSSSAN2在Gowalla上的两个指标相比LSSSAN分别降低了0.87%、0.31%,LSSSAN2在Tmall上的AUC相比LSSSAN降低了0.89%,虽然LSSSAN2在Tmall数据集上指标召回率(N为20)相比LSSSAN提升了3.17%,但由图6可以观察到LSSSAN2在Tmall数据集上的整体表现稍劣于LSSSAN。以LSSSAN为基准,消去GRU层的LSSSAN2在Tmall数据集上的表现优于其在Gowalla的表现,其原因是Tmall数据集的顺序相关性和相互依赖性不如Gowalla数据集严格。而LSSSAN与LSSSAN2相比,N参数较大时指标召回率较稳定,此时对推荐结果而言,GRU层提取序列性偏好的优势会大于GRU层受非严格顺序相关性和弱相互依赖性的影响而不稳定的劣势。当数据集表现出明显的非严格顺序相关性和弱相互依赖性时,可以考虑以消去GRU层后的LSSSAN作为推荐模型的候选。
至此,消融实验验证了模型的GRU层和自注意 力层发挥的重要作用。
3.4 超参数分析
全局维度参数d反映了模型embedding和表示层的维度,图7反映了在Tmall和Gowalla数据集上维度参数d对模型效果的影响。可以观察到,高维度的表示可以更精确地表达用户和item,并有助于和模型之间的信息交互。在实验中,本模型权衡计算成本和模型精度,设置维度参数d=80。

图 7 维度参数对模型的影响Fig. 7 Impact of dimension parameter
4 结束语
LSSSAN相比AttRec方法,利用长期反馈数据对长期/一般偏好进行准确表达,并从结构上赋予了相对重要的短期反馈数据更高的权重;相比SHAN方法,LSSSAN考虑了序列性偏好和长期数据中的相互依赖关系。
本文在Tmall和Gowalla上对LSSSAN进行训练和测试,其效果整体优于其他先进的方案。且由于Gowalla数据集的反馈数据相互依赖性和顺序相关性严格于Tmall数据集,模型在Gowalla上表现优于在Tmall上的表现,表明模型擅长于处理相对严格的相互依赖关系和顺序相关性的数据,也表明模型可能会因为数据集数据的弱相互依赖性和弱顺序相关性而出现不稳定的情况。同时本文通过消融实验验证了模型结构的合理性,并给出了当数据出现明显的弱相互依赖性和弱顺序相关性时的候选方案。
LSSSAN在实际应用上可为众多互联网应用提供推荐模型,尤其在数据具有强相互依赖性和顺序相关性的互联网应用上将会保证可靠的性能;未来的工作会考虑在LSSSAN的基础上尝试采用内存机制以提高性能,并在更多的数据集上测试模型性能。
