基于因素空间的人工智能样本选择策略
2021-07-05崔铁军李莎莎
崔铁军,李莎莎
(1. 辽宁工程技术大学 安全科学与工程学院,辽宁 阜新 123000; 2. 辽宁工程技术大学 工商管理学院,辽宁 葫芦岛 125105)
人工智能是面向人的,具备类人能力的实体或方法。人的最基本能力就是对事物的选择能力。人能通过各种渠道获得知识,而这些知识的主要应用就是人面对问题时的选择。因此人工智能的最基本操作就是模仿人对问题做出选择。人的选择过程是宏观到微观的过程,先选择关心的方面,再选择具体的定性定量特征,这是从内涵到外延的过程。目前人工智能的三大主流学派及大数据和深度学习等都是基于数据的研究。即首先从大数据的处理开始,再进行数据归类分析各类别之间的关系抽象为范围,再根据范围关系抽象为因素,最终用因素定义概念,完成外延到内涵的建立。因此人对样本的选择过程与现有人工智能样本选择过程是相反的。
关于人工智能的处理过程、理念及模型等有一些研究:知识驱动的智能生态网络研究[1];基于功能模型和层次分析法的智能方案构建[2];基于深度确定性的智能车汇流模型[3];多智能体情绪仿真模型[4];小波智能模型时序预测[5];智能电网可靠性模型预测[6];智能化云制造系统[7];智能网联环境下的车辆跟驰模型[8];智能制造成熟度评估模型[9];智能模型与自主智能系统[10];智能网联车环境下的数据转发模型[11];机制主义人工智能理论[12];人工智能的概念、方法、机遇[13];人工智能与科学方法创新[14]。这些研究各有所长,解决的问题也各不相同。但正如莫拉维克悖论[15]所述,高级的人类思维需要数据较少;反而人类的基本行为需要大量数据描述。这其实并不矛盾,高级思维涉及的因素很多;而基本行为则很少。人在分析问题时首先关注因素而不是数据;但人工智能方法需要大量数据。
为解决莫拉维克悖论提出的问题,论文基于因素空间理论[16-18]和作者的相关研究[19-26]对人的基本选择行为在人工智能框架下予以实现。最终建立了人工智能样本选择策略网络模型。
1 莫拉维克悖论
20世纪80年代,由H.莫拉维克等人提出了一种现象:像逻辑演绎这样高级理性思维只需要相对很少的计算能力,而实现感知、运动等低等级智能活动却需要耗费巨大的计算资源,即莫拉维克悖论。
这也许成为人工智能发展的一个方向。目前普遍认为人工智能应涉及大数据智能理论;跨媒体感知;人机协同智能、群体智能、个体控制与优化、机器学习、类脑智能和量子智能等。但现有人工智能基础普遍基于大数据分析抽象形成数学模型,进而模拟人受外界刺激后的响应。当然这是当下较为有效的方法。也形成了三大人工智能流派,即结构模拟(人工神经网络)[27-29]、功能模拟(物理符号系统)[30-33]和行为模拟(感知动作系统)[34-35]。这些研究更加倾向于以数据为基础的分析,但这并不是人脑真正的问题处理方式。正如莫拉维克悖论所说,人脑擅长对于逻辑、理念及感情方面的处理;而具体的定量数值处理则不擅长。例如:别人送了一些苹果,你要选择一个吃掉。你首先会根据自己的经验来选择因素从而判断选择哪个苹果,从苹果的颜色、大小、形状等方面进行判断。无论这次选择是否令你满意,其经验都会留在大脑中。相反一般不会有人拿着色谱、直尺等去对每一个苹果进行测量,再通过复杂的数学方法选择。高度抽象和演绎行为的多数信息来源于人的直观感受,比如视觉、听觉、触觉、味觉等。这些不提供具体信息,而只是客观事物在某些因素的表象。人通过事前表象和事后效果来判断是否完成目标,并形成对应关系。因此作者认为人对事物的理解首先是因素层面的理解与运算,如果难以确定才会使用因素的相进行模糊或精确分析。
汪培庄教授提出的因素空间也对莫拉维克悖论提出了相同的观点:1)只要找到描述因素,高级理性思维活动都是简单的;2)低级本能活动之所以困难,是因为人们不知道使用何种因素描述它们;3)因素由人输给机器,输给因素越多,机器就越聪明。根据莫拉维克悖论,基于数据的人工智能方法很难完成对人脑智能的模拟;同时受大数据获得条件限制也难以完成。
2 人的选择等同于比较
人的思维、感情及逻辑推理基本是对少量样本进行的。人们从古至今都是在少量样本组成的样本空间中选择。不同在于由于信息及大数据技术的发展,选择的样本空间越来越大。因此从以前的信息不对称变成了选择综合症。实际上人脑对大样本空间有自己的处理策略。人脑将大样本空间细化,形成样本数量大致相同的子样本空间来处理,当然这和个人的记忆和处理能力有关。通常的,人脑在子样本空间中选择最好的样本保留,这样多个子样本空间就得到了各自最好的样本组成下一轮样本空间进一步选择。该策略也应用于各大电商平台的购物车策略。过程中人脑基本使用因素及其相之间的推理和运算,这种运算适合于人脑,且处理速度相当快。
在样本空间中选择最好样本的具体过程则是比较,更为具体的是两两比较,类似于冒泡法,由于人脑并不擅长并行处理。那么回到莫拉维克悖论,这时样本空间中的样本已经很少,同时也基本符合人脑根据经验、逻辑和推理得到的结果。在只能选择一个样本时,人脑将使用类似冒泡法进行比较。这时考虑苹果需要装入方形礼盒,而礼盒的尺寸是固定的,那么要具体考虑苹果的尺寸和形状因素的具体相。形状因素的相尽可能方正;尺寸因素的相尽量适合。对于尺寸的相可使用模糊和精确测量,当然这取决于样本数。可通过测量找到小于礼盒尺寸且又最接近礼盒尺寸的苹果放入礼盒。
因此可以说,人的思维、推理和判断过程是一个选择比较过程,过程中样本数量是较少的,不需要大数据支持;通过选择适合的因素、因素概念相(如较大、红色)和因素量化相(如10 cm)来最终选择适合的样本。但这刚好与基于大数据的人工智能策略相反。
3 人工智能样本选择策略
人工智能选择是人工智能理论实现的方式之一。人工智能目标是使机器代替人进行工作,而人最基本的工作就是样本选择。因此从莫拉维克悖论来看人工智能完成样本选择应无需大数据支持,但现状却相反。这里作者提出一种基于莫拉维克悖论和因素空间理论的人工智能样本选择策略。以人工智能系统本身为主体,将人、物和环境作为辅助系统,考虑选择因素、因素概念相和因素量化相,在环境系统中按照人的要求对物(样本)进行选择。图1为研究对象的关系图。

图 1 研究对象关系图Fig. 1 Relationship of research objects
解释图1中符号含义。人工智能:代替人具有类人智能的实体或程序,其中包括信息接收、处理和存储的一系列子结构,但这里并不关心该结构。人:指自然人,用于为人工智能提供需求、以往积累的经验及可能的推理和理智策略等。一般环境:经验积累过程中出现的环境。一般物:经验积累过程中出现的物。实例环境:人工智能具体实施选择实例物时的环境。实例物:人工智能具体实施选择的物。图中关系有人对一般环境和一般物的以往处理过程和结果形成的人已有经验;人向人工智能提出工作需求;实例环境提供人工智能可感知的因素及其相;实例物提供人工智能可感知的因素及其相;人工智能对实例物进行选择。
图1的研究对象中心是人工智能系统,而不是人。更为重要的是该人工智能系统并不基于大数据,而是人的已有经验。这些经验往往不是具体的或模糊的数值,而是如上所述的因素及其相之间的逻辑推理和运算,结果形成了对应关系结构。这些操作在作为智能科学数学基础的因素空间理论中已有研究。该结构可定义为具体个人的喜好和偏向。选择具体对象时,根据这些偏好及对应的实例环境选择实例物。继续苹果的例子,考虑因素为尺寸∧颜色(∧表示合取[17]),相f(尺寸)={大,中,小}和f(颜色)={红,绿,黄},f(尺寸∧颜色)={大红,中红,小红,大绿,中绿,小绿,大黄,中黄,小黄}。人甲偏好可能是大红;而乙则偏好小黄。那么他们挑选苹果时选择的因素是尺寸∧颜色,这是第1次因素选择。选择的相分别是大红和小黄,这是第二次因素概念相选择;苹果需要装入礼盒考虑尺寸因素,度量礼盒(实例环境)尺寸和苹果尺寸(实例物)选择苹果,这是第三次因素量化相选择。对人而言,再复杂的选择都可通过这三步完成。目前各种方法论和数学方法等都是帮助人完成这三次选择的,同样也可帮助人工智能完成实例物的选择。
图2给出了类人的人工智能样本选择策略过程。这种策略分成3次选择实例物。第一次选择基于人的经验,是人工智能对人的学习结果。是基于实例环境和实例物所提供的可比较因素而非数据条件下完成的因素选择。其特点是速度快且少数据,人的因素选择往往是一瞬间。当人深思熟虑时,可能面临的是多因素、多样本,且需要后两次选择参与。但对因素的选择不会花费太长时间,当了解人偏好和需求时人工智能也是如此。第2次选择是对第一次选择得到因素的相的选择,包括概念相和量化相。参考人的目的和偏好,比较不同实例物(样本空间)相同因素的不同概念相,进行实例物选择。第3次选择是更为具体的对因素量化相的测量。这时因素量化相可以是模糊范围或精确数值,比较实例环境与各实例物的匹配性,从而选择实例物。通过这3次选择逐渐减少样本数量,最终选择适合的实例物。
图3给出了最终得到的人工智能样本选择策略网络结构。其中,f代表因素,共n个;x代表某因素下的因素相,共m个;x11、x13、x23、x4n-1为因素概念相;xm11、x53、x1n-1为因素量化相;Object()表示实例物的目标函数。图中3个层次都对应一种网络结构。第1次的网络结构基于人的现有经验(逻辑、概念、心理、理智、主观、偏好),将所有因素与被选因素的对应关系形成网络结构,即何物需要何种因素进行选择。第2次的网络结构基于实例环境和实例物,将所有被选因素的所有相与被选相(概念相和量化相)组成网络结构,即该物可在相同因素的何种程度进行选 择(只针对概念相选择)。第3次基于现有工具可测量的具体量化相,将所有量化相与目标函数形成网络。第3次是具体数据处理;第2次是因素相选择;第1次是因素选择。因此从该角度看,人工智能样本选择策略使用的数据量应该很小;而多数处理来源于因素相的比较和因素选择,基于人的经验。这符合莫拉维克悖论,也可简化目前基于大数据的人工智能方法,为其发展提供一条选择因素、因素概念相和量化相的样本选择策略道路。可在样本空间中不断选择适合样本,最终得到最优样本。

图 2 人工智能样本选择策略层次Fig. 2 Strategy level of artificial intelligence sample selection

图 3 人工智能样本选择策略网络模型Fig. 3 Strategy network model of artificial intelligence sample selection
4 选择对象过程
使用上述策略,分析一道智力题,如图4所示。

图 4 图形选择Fig. 4 Graph selection
第1次因素选择:f={颜色,形状,内线条数,内线条交叉,内线溢出}。第2次因素概念相选择:f(颜色)={黑},f(形状)={正方形,圆形}。第3次因素量化相选择:f(内线条数)={1,2},f(内线条交叉)={0,1},f(内线溢出)={0,2}。那么这5个图形的特征如表1所示。
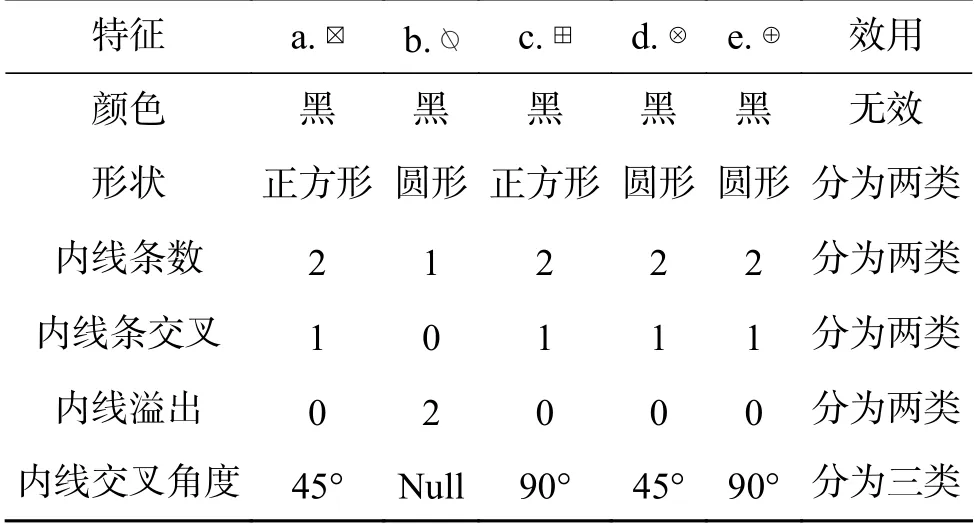
表 1 5个图形的特征Table 1 Characteristics of five graphs
Object={a,b,c,d,e}。Object(颜色)={a,b,c,d,e}/f(颜色)={a,b,c,d,e};Object(颜色,形状)={a,b,c,d,e}/f(形状)={a,c}+ {b,d,e};Object(颜色,形状,内线条数)= ({a,c}+ {b,d,e})/f(内线条数)={a,c}+{b}+{d,e};Object(颜色,形状,内线条数, 内线条交叉)= ({a,c}+ {b}+{d,e})/f(内线条交叉)={a,c}+{b}+{d,e};Object(颜色,形状,内线条数, 内线条交叉, 内线溢出)= ({a,c}+ {b}+{d,e})/f(内线溢出)={a,c}+ {b}+{d,e}。从该过程来看,b是区别于其他图像的选项,因此最终选择b图。同时也可了解到图a和c可以归为一类;d和e可以归为一类。如果再增加因素内线交叉角度,则a和c,d和e可进一步区分。但这时也进一步增大了b与他们的区别。也有类似的决定度等相关概念可区分对象[17]。
综上,实例分析过程基本是因素及因素相的运算,最后才涉及具体的数据统计和测量。这是人对样本的选择过程,也是人工智能样本选择应具备的策略。当然例子是简单的,大规模分析需实现图3中3次网络结构,组成人工智能样本选择策略网络。基于目前情况,第1、2次选择可通过因素空间理论实现,第3次可通过现有神经网络实现。因此我们得到实现人工智能的基础是学习人思维的本质。人思维的本质是依靠因素进行大规模的样本筛选从而确定关注点,再根据因素的定性相(概念相)选择喜好样本,最后才是根据因素的定量相(量化相)获得匹配最好的样本。从该角度分析,目前的人工智能面向大数据的驱动可能是背道而驰,大数据驱动的人工智能只能显示表象,冗余和虚假信息对结果有很大影响。这部分研究有待进一步展开。
5 结论
论文提出了一种人工智能样本选择策略。主要结论如下:
1)利用因素空间思想论述了莫拉维克悖论的合理性。认为人对事物的理解首先是因素层面的理解与运算,如果难以确定才会使用因素相进行模糊或精确分析。
2)人的选择过程就是比较过程。人的思维、推理和判断过程是选择比较过程,样本数量是较少的,不需大数据支持;通过选择适合的因素、因素概念相和因素量化相来选择适合样本。
3)建立了人工智能样本选择策略。首先给出了研究对象中人、机、环境及人工智能系统之间的关系。建立了人工智能样本选择策略结构,3次选择分别对应了因素、因素概念相和因素量化相选择。给出了3次选择的特点、基础和方法。最终建立人工智能样本选择策略网络模型,模型中3次选择对应于3种网络结构。
4)通过实例演示了人工智能样本选择策略。过程中基本是因素及因素相的运算,最后才涉及具体的数据统计和测量。该策略是人对样本的选择过程,也是人工智能样本选择应具备的策略。
