利用混合高斯和拓扑结构的人体“鬼影”抑制算法
2021-07-05许国梁周航袁良友
许国梁,周航,袁良友
(北京交通大学 电子信息工程学院,北京 100044)
监控视频中的人体检测和跟踪一直是研究的热点,在人工智能、安全监控和人机交互等领域有广泛的应用[1-4]。通过建立背景模型,利用背景差分法检测目标具有检测速度快、准确度高和易实现的特点,得到了广泛的研究[5-9]。但缺点是会因为背景模型中包含目标像素而在检测中产生“鬼影”。背景差分法包括GMM (Gaussian mixture model)、Vibe、CodeBook、Color (基于颜色信息的背景建模检测方法) 等算法[10-15]。Shahbaz等[16]将检测算法分为了三类,并利用大型真实标准数据集对算法进行定量和定性比较。Wren等[17]首次提出使用单高斯模型对简单背景建模,对单一背景有较好的效果。为了提高算法的鲁棒性,算法需要适应在复杂背景情况下的建模[18]。Stauffer等[19]提出利用K个高斯分布对背景的每一个像素建模,实现了对汽车和行人的分类和跟踪。Zivkovic等[20]提出将混合高斯模型中的K值根据背景的复杂度自适应调整,提高了算法的执行效率。以上提出的高斯背景建模算法建模速度快,对运动目标有较好的检测效果,但是对缓慢运动或静止的目标会检测不完整。Kim等[21]利用CodeBook算法对动态目标进行检测,算法在室内外的效果都比较好并且适应小范围周期运动的背景。Barnich等[22-23]提出一种有效的ViBe目标检测算法,该算法实现简单并且运行效率高。针对ViBe不足,国内外学者也对其进行了许多改进[24-26]。文献[24]利用多帧平均法改进Vibe的建模过程并给出自适应半径阈值的计算方法。文献[25]通过利用时空梯度改进ViBe算法。文献[26]通过灰度空间信息构建像素生命长度字典改进ViBe。文献[21-26]算法虽然可以检测出较为完整的目标,但是依然无法准确剔除目标像素,会使检测结果可能产生“鬼影”。现阶段抑制 “鬼影”的方法分为两类:1) 在建模阶段通过剔除目标像素去除“鬼影”;2) 目标检测阶段将“鬼影” 检测为背景并且更新进背景内。Codebook通过过滤初始化码本中的目标像素削弱“鬼影”的影响。ViBe采用首帧建模思想,若首帧存在目标,则会产生严重“鬼影”。文献[24-26]产生的“鬼影”都需要利用背景模型的更新消除。St-Charles P L等[27-28]利用背景的快速更新去除“鬼影”,但过快的更新容易将目标更新进背景内,会使目标检测不完整。由上述算法看出,在建模阶段有效地从背景模型中剔除目标像素是一个关键问题,否则 “鬼影”会影响检测结果。
为了有效解决建模阶段包含目标像素造成的“鬼影”问题,本文结合混合高斯模型和拓扑结构提出GMMT算法,在背景建模阶段剔除目标像素,在目标检测阶段利用邻域相关性实现目标分割,有效地抑制了“鬼影”。
1 算法概述
本文提出的GMMT算法需要先进行背景建模,然后利用背景模型实现目标检测。在背景建模阶段采用双通道建模方式,通道一利用混合高斯模型进行预检测,接着利用Meanshift确定分散区域之间的联系,在区域之间生成网状拓扑结构[29],形成统一的整体并计算整体区域的外接矩形。最后将矩形外的像素加入背景模型中,利用多帧平均法计算空背景; 通道二保留背景建模阶段的输入帧,直接利用多帧平均法计算空背景。通过设置建模帧数阈值T判断建模方式,若建模帧数小于T,则使用通道一建模,否则使用双通道联合建模。在目标检测阶段,利用改进的背景差分法考虑邻域像素的相关性检测目标并且进一步消除背景建模阶段由于抑制不彻底而遗留的“鬼影”。GMMT算法通过这两个阶段的处理,可以有效地抑制“鬼影”,实现目标分割。图1中为GMMT的框图结构。
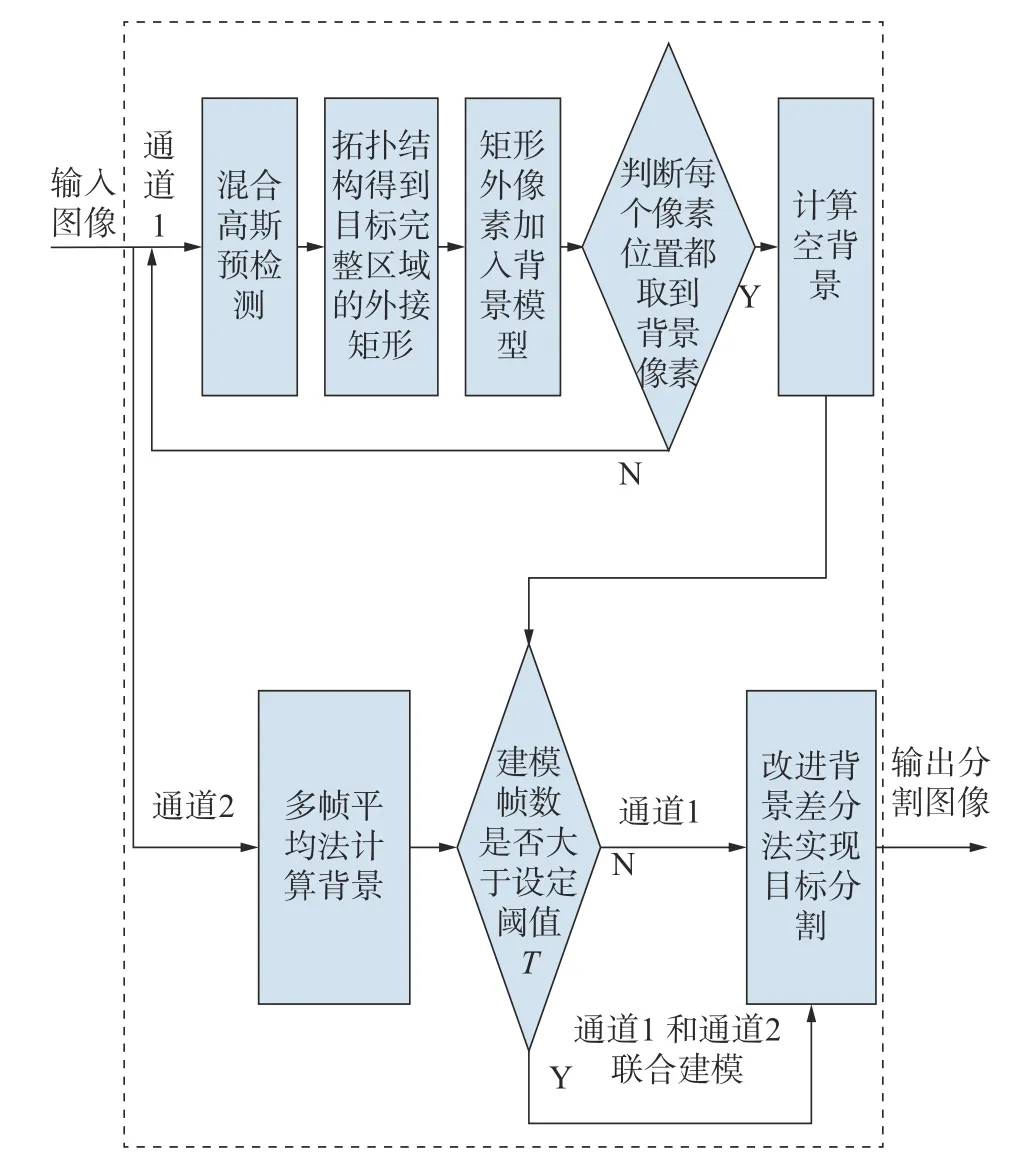
图 1 GMMT算法框图Fig. 1 Block diagram of GMMT
2 背景建模
首先,对人体静止、缓慢运动和快速运动加以定义。本文中人体静止是指人体不走动,但是上肢或者 下 肢在摆动角区间 [10°,90°] 范围内摆动;运动缓慢和运动快速区分是通过视频序列前后两帧图像中人体目标运动是否相差半个身位:相差小于半个身位则为缓慢运动,大于半个身位则为快速运动。
“鬼影”即为虚假目标,通常是由于背景模型中包含目标像素造成的。当利用背景模型进行背景差分时,若背景模型中包含目标像素,而待检测帧的对应位置不包含真正的目标时,依然会检测出目标,此时就形成了“鬼影”。背景建模的难点就在于目标像素会进入背景模型中。其中,在目标静止或运动缓慢时“鬼影”问题尤为严重。因为背景像素会被目标像素长期遮挡,无法采集到真实的背景像素,这样会在检测过程中产生 “鬼影”。GMMT通过利用混合高斯模型和拓扑结构剔 除目标1像素,建立有效的背景模型。
2.1 混合高斯模型
混合高斯模型由于更新速度快,所以可以有效地检测目标的运动信息。混合高斯模型的概率函数可表达为
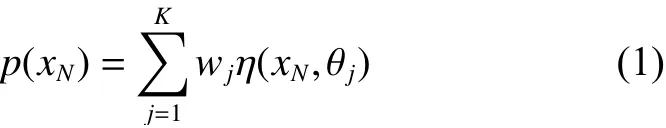
式中:wj表示每个高斯分布所占的权重;η(xN,θj)表示标准K高斯分布的概率密度函数。
GMMT利用混合高斯模型检测目标的运动信息。图2为混合高斯模型对目标运动信息的检测结果。由图2可看出,运动快速的目标检测完整,运动缓慢和静止的目标检测不完整。图2中(b)和(d)可看出,目标静止或运动缓慢时,变化最明显的位置是目标边缘。

图 2 混合高斯模型对不同运动状态目标的检测结果Fig. 2 Detection results of Gaussian mixture model for ob- jects in different moving states
为了建立有效的背景模型,需要将检测到的目标像素和未检测到目标像素全部剔除,GMMT将混合高斯模型检测得到的运动目标信息作为先验信息,然后利用拓扑结构估计未检测到的目标像素。
2.2 利用拓扑估计目标完整区域
受到网状拓扑结构在计算机网络中应用的启发,本文将网状拓扑结构应用于目标区域的估计。图3为网状拓扑结构1示意图,图中身体各部分表示节点,直线表示连接关系。从图中可以看出利用网状拓扑结构可以充分将分散的身体运动区域连接为一个整体。GMMT就是利用拓扑结构这种将所有分散个体连接成统一整体的思想。由图2可知,不易检测的像素容易出现在目标内部,而易检测像素出现在目标边缘,所以GMMT充分利用目标边缘的变化信息,用网状拓扑结构将边缘所有的运动像素连接。在GMMT中将已检测到的目标区域抽象节点,然后使用Meanshift算法确定节点之间的连接关系。
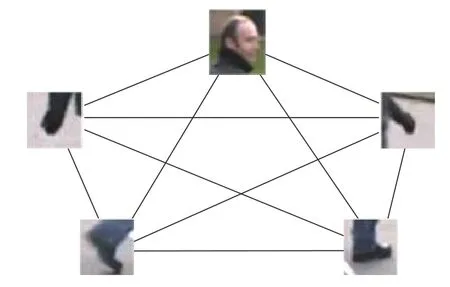
图 3 网状拓扑结构Fig. 3 Mesh topology
2.2.1 Meanshift
Meanshift聚类采用欧式距离判断点是否为当前聚类的兴趣点。为了使算法更好地适应对人体区域的聚类,GMMT中利用更符合人体长宽比的矩形框代替欧式距离判断。下面是Meanshift的具体步骤:
1)首先随机选取一个未被标记的点作为聚类中心center;
2)找出以center为中心长宽比为2的矩形框区域内所有的数据点集合N,认为集合N属于同一聚类C,并记录数据点在该类出现的次数加1;
3)计算以center为起始到集合N中每一个元素的向量,将向量相加得到shift向量;
4)使center沿着shift向量移动,即 center=center+shift;
5)重复步骤2)~4),直至shift向量很小,GMMT设置shift为0时迭代停止,该过程遇到的全部点属于聚类C;
6)重复步骤1)~5),直至所有的点都被访问;
7)若一个聚类中心在另一个聚类中心的长宽比为2的矩形框区域内,则合并两个聚类并将数据点出现的次数也合并;
8)按照每个点不同类的访问频率进行分类,将点分配给访问频率最大的聚类。
通过Meanshift将混合高斯模型检测后图像中的区域聚类,同一目标或相邻很近目标分离的区域被聚类为一类。通过在多个场景进行测试,Meanshift采用长宽为200×100的矩形框。在利用Meanshift聚类前,利用混合高斯模型预检测得到的图像需要进行形态学运算去除过小的噪声点。图4为利用Meanshift得到的聚类结果,彩图表示原图,二值图表示对原图预检测后聚类的结果,不同的颜色表示不同的类别。从(b)、(d)、(f)、(h)和(j)可以看出,Meanshift将同一目标或相邻目标分散的区域聚为一类。需要注意的是图(h)中红色聚类为目标造成的阴影区域,GMMT算法在背景建模阶段会将目标造成的阴影像素当作目标像素处理。

图 4 Meanshift聚类结果Fig. 4 Results of Meanshift clustering
2.2.2 估计目标区域
由Meanshift确定点之间的联系后,在同一类点内生成网状拓扑结构,将分散的区域连接成一个整体并得到整体区域的外接矩形。图5为利用网状拓扑结构将分散区域连接的流程图,聚类过程的介绍以图4(h)中蓝色聚类为例。图5(d)为利用网状拓扑结构思想将分散的目标区域连接在一起,然后在图5(e)中取整体区域的外接矩形,最后图5(f)为将外接矩形在原图中标记。网状拓扑会在每个节点连接多条边,目的是将同一类的区域全部连接在一起。通过估计目标区域得到的外接矩形内包含已检测的目标像素(白色区域)和未检测到的目标像素。背景建模时将矩形框内的像素全部剔除,这样可以尽可能剔除所有的目标像素,达到有效抑制“鬼影”的目的。
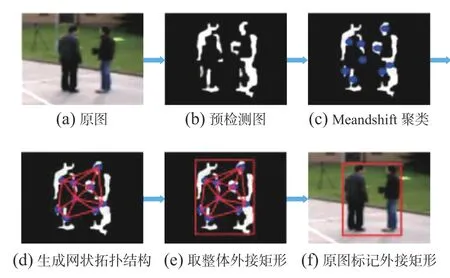
图 5 估计目标区域流程Fig. 5 Process of estimate target area
2.3 计算空背景
得到背景像素后需要计算空背景,利用背景差分法实现目标检测。在计算空背景时考虑到部分背景像素可能由于目标长期遮挡背景或背景长期剧烈变化(如树枝剧烈晃动)不能采集到稳定的背景像素,所以GMMT算法如图6所示采用双通道的方式计算背景模型。
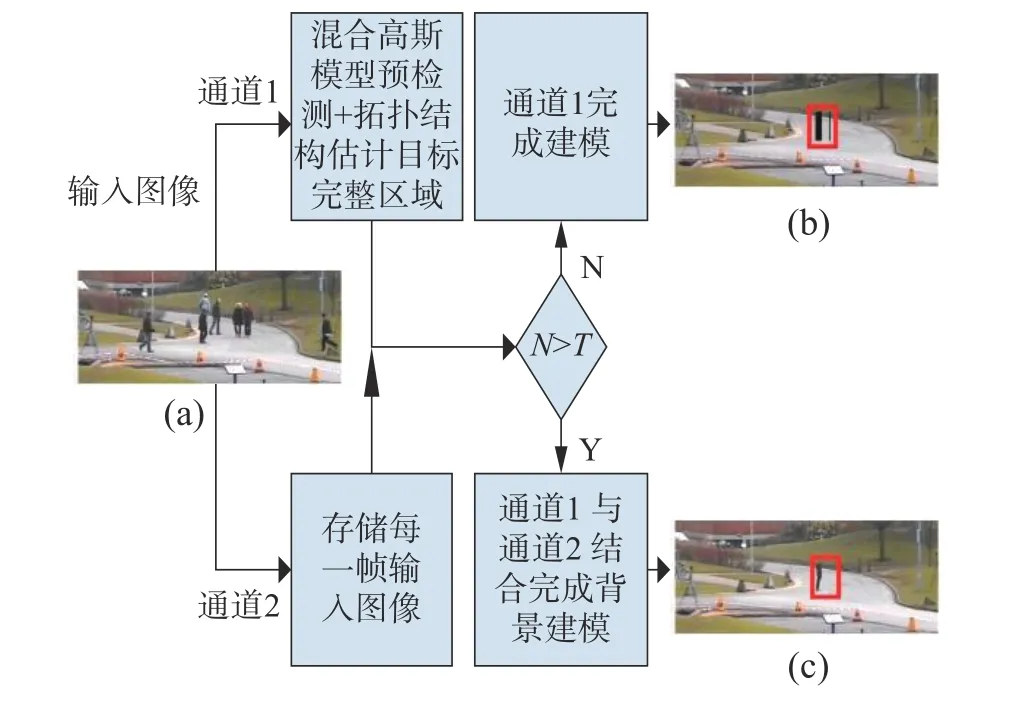
图 6 双通道计算背景流程Fig. 6 Process of two channel computing background
通道1 根据2.2节和2.3节介绍的方法剔除目标像素,当所有的背景像素出现至少一次后就计算空背景。计算背景公式为
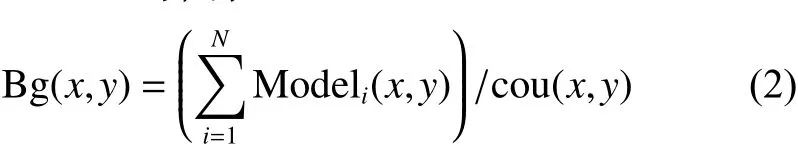
式中:Bg(x,y) 表示计算得到的空背景;Modeli(x,y)表示背景模型,存储每一帧剔除目标像素后留下的背景像素; c ou(x,y) 表示每一个像素位置背景像素的采集次数;N表示建模用的帧数。
通道2 存储每一帧输入的图像 F ramei(x,y),当建模帧数N>T时,利用多帧平均法计算输入图像的均值图像 M ean(x,y)。
如图6所示为GMMT算法利用双通道计算空背景,输入图像中示例场景建模帧数大于200,图(b)中矩形框内为通道一无法采集的背景像素,图(c)中矩形框为使用联合建模采集的背景像素。阈值T可以按照实验时所能接受的建模帧数上限设置,本文设置建模所用帧数阈值T=200帧。若建模帧数小于T时,则只用通道一完成背景建模;否则采用通道一与通道二联合建模。因为建模帧数不小于T说明通道一存在无法采集的背景像素。如图6中示例场景由于人群密集导致在建模帧数上限内存在无法采集的背景像素(图(b)矩形框内的黑色像素),所以将无法采集的背景像素利用通道二多帧平均法填补。通过通道一建模和双通道联合建模对比可发现,双通道联合建模填补了缺失的背景像素。
3 目标分割
GMMT使用背景差分法将人体与背景分离,这样可以使算法快速地实现目标检测。传统的背景差分法只考虑了单个像素,没有考虑像素邻域的相关性。像素邻域的分布是比较相似的,可以借助像素邻域之间的相似性提高算法的鲁棒性。如图7所示为像素f(x,y) 与背景相同位置的像素Bg(x,y) 及其8邻域像素,箭头表示f(x,y) 需要和Bg(x,y) 像素运算。
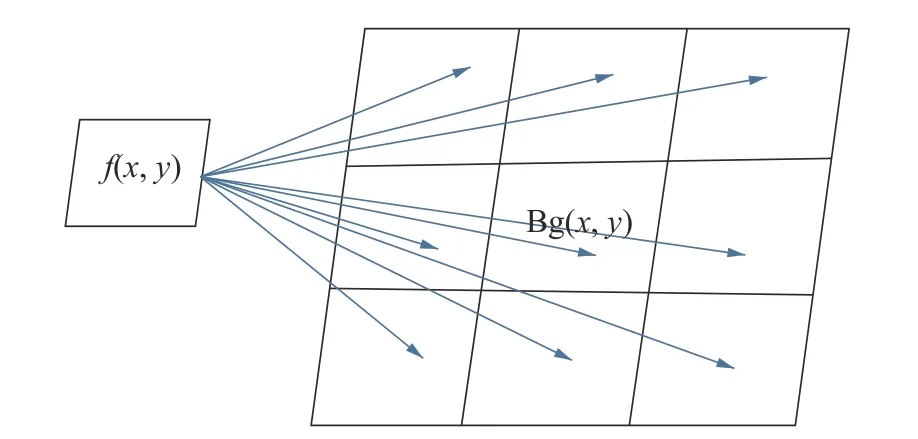
图 7 当前像素和与其对应的空背景8邻域像素Fig. 7 Current pixel and its corresponding empty background 8 neighborhood pixels
改进的背景差分法计算方法为
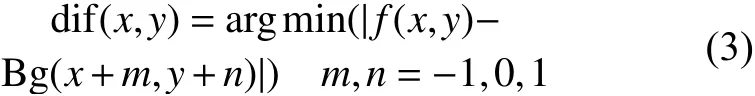
改进的背景差分法使像素f(x,y) 与其对应的背 景像素及其8邻域像素作差并取绝对值,形成差值序列,然后取序列的最小值赋值给 dif(x,y)。这样可以改善目标像素偏移造成的误检测。经实验发现,改进后的背景差分法可以适应动态的背景,比如风吹动树叶、横幅等小幅摆动并且还可以快速地消除“鬼影”。图8(a)~(c)为改进的背景差分法处理动态背景,可以发现改进后的背景差分法的检测结果中无条幅出现,提高了算法的鲁棒性。由于改进的背景差分法考虑了像素的邻域信息,所以“鬼影”区域会由外到内逐渐更新为背景。图8(d)~(f)为改进的差分法消除“鬼影”,经过114帧“鬼影”区域就完全消除。
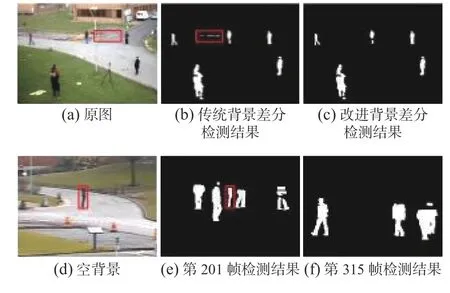
图 8 改进的背景差分法处理动态背景和消除“鬼影”Fig. 8 Improved background difference method deals with dynamic background and eliminates “ghosts”
4 实验结果及分析
为了验证GMMT可以在建模时准确地剔除目标像素,本文与文献[21] CodeBook算法、文献[23]Vibe算法、文献[27]Subsense算法和文献[28]Pawcs算法在Dataset2012数据库、Camera- Parameter数据库和LightSwitch数据库进行比较。由于建模阶段经常在场景中出现目标,为了验证算法可以有效剔除背景模型中的目标像素,所用场景背景建模时的每一帧都存在目标。表1中为测试用的场景起始帧和测试帧在数据库中的帧位置。
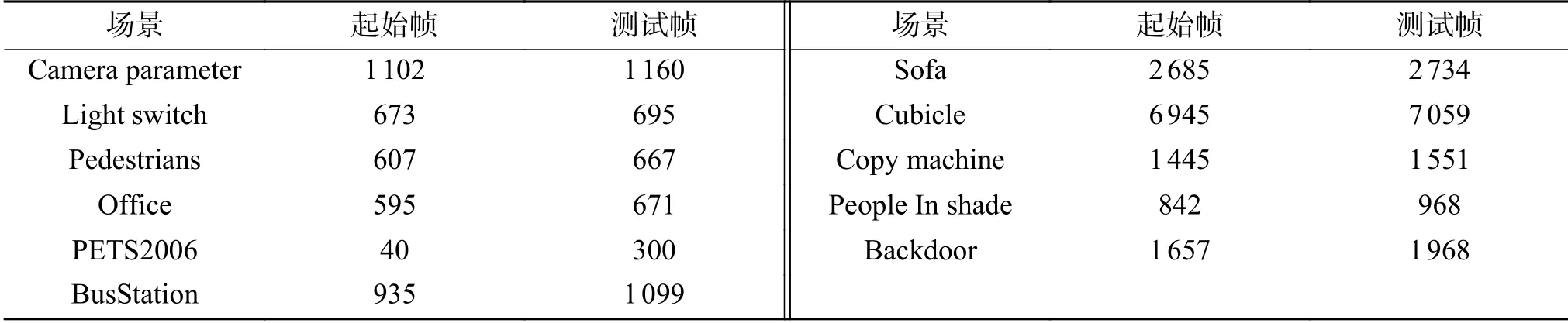
表 1 测试场景信息Table 1 The information of test scenes
从图9中每种算法在不同场景下的建模效果对比可以看出,Codebook、Vibe、Subsense和Pawcs背景模型中包含了大量的目标像素,而GMMT建立的背景模型剔除了目标像素,建立的背景更符合真实场景。

图 9 算法在不同场景下的建模效果Fig. 9 Modeling effect of the algorithm in different scenes
图10为算法在各场景中的检测结果,从图10中可以看出Codebook和Vibe算法在检测结果中产生了较多的“鬼影”,Subsense产生了较少的“鬼影”,Pawcs和GMMT没有产生“鬼影”。因为Subsense和Pawcs算法背景更新速度快,所以经过一段时间更新后可以消除“鬼影”,但是过快的更新会使运动缓慢或静止的目标更新进背景内,会使目标检测不完整。GMMT在背景建模阶段就消除了目标像素,使检测结果没产生“鬼影”。

图 10 算法在不同场景中的检测结果Fig. 10 Result of algorithms in each scene
“鬼影”像素为FP像素(背景像素误划分为目标像素的个数),从表2中可以看出,Codebook和Vibe算法由于“鬼影”的影响FP像素数量很高,而Subsense、Pawcs和GMMT算法的FP像素数量一直保持在较低水平。Subsense和Pawcs算法利用快速更新的方法降低了FP像素的数量。为了进一步验证GMMT消除“鬼影”时不会使目标检测不完整,本文利用召回率(R)将GMMT与Sub-sense和Pawcs算法进行对比。召回率可以衡量算 法对真实目标像素的检测能力,R=TP/(TP+FN)。通过计算得到Subsense、Pawcs和GMMT的在数据集上的平均召回率分别为0.781 1、0.720 2和0.821 9。从召回率中可看出GMMT在抑制“鬼影”的同时召回率高于Subsense和Pawcs算法。
最后,本文对各算法的运行效率进行分析。本文所用的实验环境为WIN7 64位、Inter Core i5-3230M CPU、VS2017搭配OpenCV2.4.9。如表3所示为各算法在数据库上的平均运行时间,可以看出GMMT在保证检测效果的基础上有较高的运行效率,算法复杂度较低。
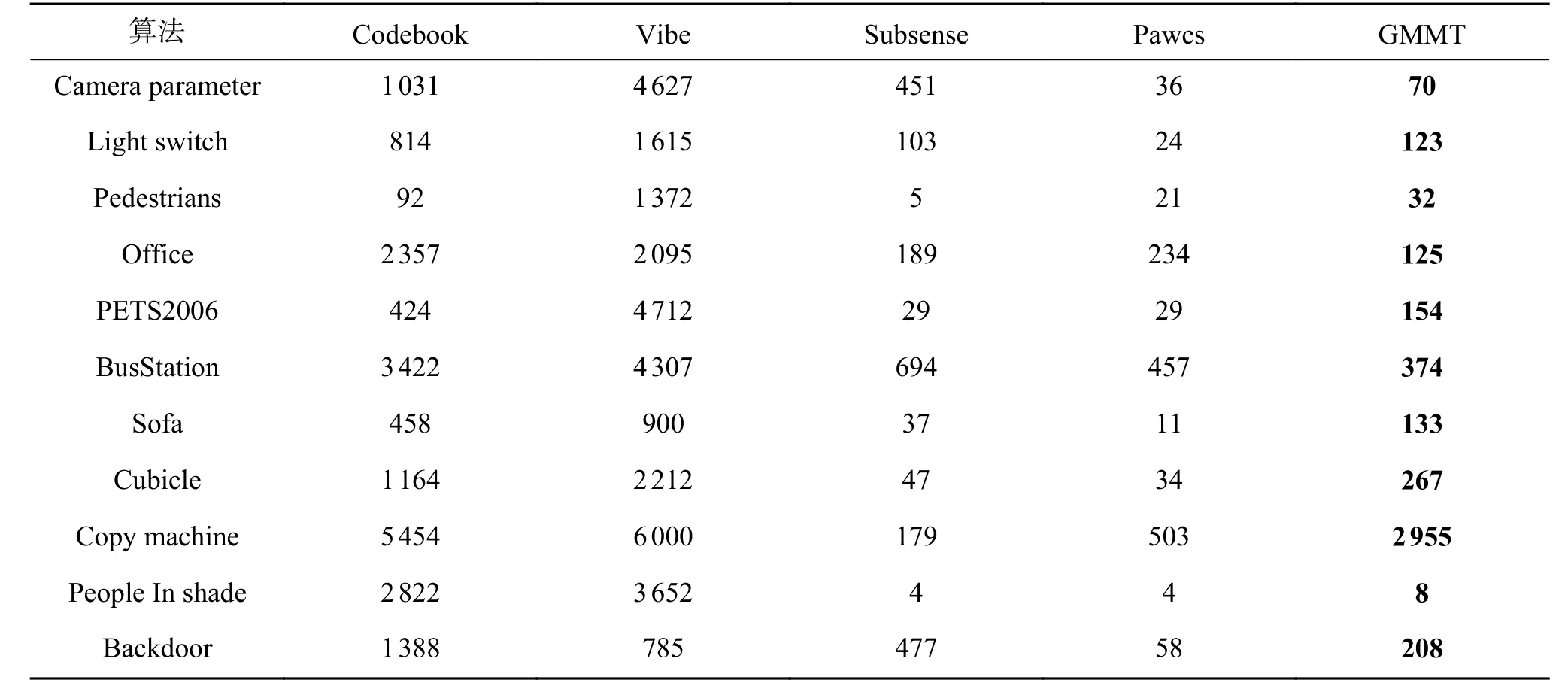
表 2 算法在各场景的检测结果中 F P 像素数量Table 2 Number of F P pixels detected by the algorithm in each scene

表 3 在数据集上不同算法处理的图像数量Table 3 Average number of images processed by the algorithm per second on the dataset 帧/s
5 结束语
GMMT算法使用双通道建模方式和改进的背景差分法实现背景建模和目标分割。通道一利用混合高斯模型预检测和拓扑结构连接分散区域的方式剔除目标像素,通道二采用多帧平均法。双通道建模保证了算法在复杂背景下完成建模并且有效地剔除目标像素抑制“鬼影”。改进的背景差分法可快速分割目标并利用邻域信息消除“鬼影”。通过与Codebook、Vibe、Subsense和Pawcs的对比,证明了GMMT算法的有效性。算法有效地抑制了 “鬼影”并且保持了较高召回率。
背景建模会受多种因素的影响,现阶段主要可以概括为4个方面:1)光照的缓慢变化和突然变化问题;2)背景会不断发生变化的动态背景问题;3)背景中物体、运动目标等形成的阴影问题;4)由视频采集设备造成的噪声问题。这些问题都会影响背景建模和目标检测的效果,所以算法需要适应多模态的背景、相机抖动和PTZ相机等复杂环境,这是以后需要努力的方向。
