神经网络多层特征信息融合的人脸识别方法
2021-07-05方涛陈志国傅毅
方涛,陈志国,傅毅,2
(1. 江南大学 物联网工程学院,江苏 无锡 214122; 2. 无锡环境科学与工程研究中心,江苏 无锡 214153)
人脸识别一直以来都是计算机视觉方向与模式识别领域的研究热点,作为生物特征识别技术一个重要的研究方向,人脸识别技术因其很高的商业价值和极为广阔的应用前景而进行了大力的发展。人脸识别已经融入到了生活中的方方面面,诸如视觉监控、自动身份验证、银行安全、门禁安全等专业领域。计算机硬件技术的快速发展为计算机视觉、机器学习等领域的发展提供了坚实的基础支撑,也为深度学习的进步与流行提供了基础。深度学习是包含多级非线性变换连接的机器学习方法,受启发于动物视觉皮层组织,模拟生物神经元间的连接模式[1]。随着深度学习模型不断发展成熟,由于其优越的性能,人们开始神经网络应用人脸识别领域,主要是利用神经网络进行特征提取再利用不同分类器进行识别[2-5],或者直接利用神经网络进行识别[6-7]。
卷积神经网络是其中一种经典而广泛应用的结构。卷积神经网络具有局部连接、权值共享及池化操作等特性,可以有效地降低网络的复杂度,减少训练参数的数目,使模型保持一定的不变性,并具有强鲁棒性和容错能力,且也易于训练和优化。基于这些优越的特性,它在各种信号和信息处理任务中的性能优于标准的全连接神经网络[1]。Taigman等提出了DeepFace[8],使用CNN代替了传统的手工特征提取方式来提取人脸特征,奠定了基于深度学习的人脸识别方法的基础。Google的团队提出了FaceNet[5],商汤科技的视觉团队提出了DeepID[9]系列人脸方法,通过卷积神经网络提取合适的人脸特征。还有一些重要工作是从人脸识别的损失函数方面突破,添加约束促进不同类特征之间的分离性,目的是获得判别性较高的人脸特征,提高人脸识别的准确率。
为了解释卷积神经网络提取到的特征,一些研究提取卷积层进行可视化,发现卷积神经网络低层学习到的主要是纹理特征,高层学习到的主要是语义特征[10],为了充分利用网络提取到的低层纹理特征和高层语义特征信息,以及两者之间的互补性,可以对多层特征进行融合得到更适合用于人脸识别的特征,以提高人脸识别的精度。信息融合一般分为数据级整合、特征级融合和决策级融合3个层面,数据级融合是最低层次的融合,直接对原始数据进行融合;特征级融合是一种中间层次的信息融合,对原始数据提取特征后进行分析与融合;决策级融合是一种更高层次的融合,对各个数据或特征进行分类或识别后的结果进行分析与融合。
为了能够得到更好的人脸特征,提高人脸识别准确率,本文在已有的经典网络结构的基础上进行改进,融合上下层信息并提取作为多层特征,基于特征级融合与决策级融合的融合方式进行信息融合。本文构建适合于多层特征提取的网络模型,研究加权融合方式,通过定义中心变量后,计算自适应权重,结合卷积神经网络训练方式学习中心变量,通过训练学习到的中心变量计算加权融合相似度,进一步提高识别率。
1 多层特征信息融合模型
1.1 卷积神经网络
卷积神经网络的相关研究最早是在1962年,生物学家Hubel和Wiesel通过对猫脑视觉皮层的研究,发现了“感受野”和视觉皮层中的细胞的层级结构。1980年,Fukushima在此基础上根据层级模型提出了结构与之类似的神经认知机(neocognitron),之后才逐渐发展成现在的卷积神经网络。LeCun等基于Fukushima的研究工作使用BP算法设计并训练了奠定了卷积神经网络基础经典模型LeNet-5,后续有许多工作都是基于此模型进行改进[1],图1为LetNet-5模型结构图。
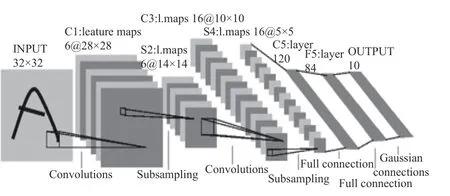
图 1 LeNet-5结构Fig. 1 Structure of LeNet-5
如图1所示,卷积神经网络是一种非全连接的多层神经网络,一般由卷积层、下采样层和全连接层组成,原始图像首先通过卷积层与滤波器进行卷积,得到若干特征图,然后通过下采样层对特征进行模糊,卷积神经网络的隐藏层是由卷积层和下采样层交替组成,最后通过一个全连接层或者全局平均池化输出一组特征向量,用于分类器分类识别。
1.2 特征提取神经网络结构改进
神经网络具有低层纹理特征和高层语义特征的差异,为了更好地提取多层特征,对已有的经典卷积神经网络结构做出改进。下采样层能整合特征,保持不变性,是为了特征更好表达,因此在下采样层的前一层位置进行改进。
不同层次的特征旨在编码不同层次的信息,进行上下层特征融合后,不同层次的特征相互补充,有时互补,能够获取更多的所需的信息,能够更充分的表达特征,从而有更好的效果。
网络结构选择ResNet来改进,图2为使用的ResNet网络结构,图3为Resblock结构,图4是改进后的网络结构,在尽量不增大网络规模的前提下,将Resblock之间的卷积层拆成不同大小卷积核,将上层特征送入下层并通过不同大小卷积核后进行融合,融合后的特征再次送入下层,然后将所有拼接后的特征以及最后一层输出的特征作为要提取的多层特征,进行下一步的操作。
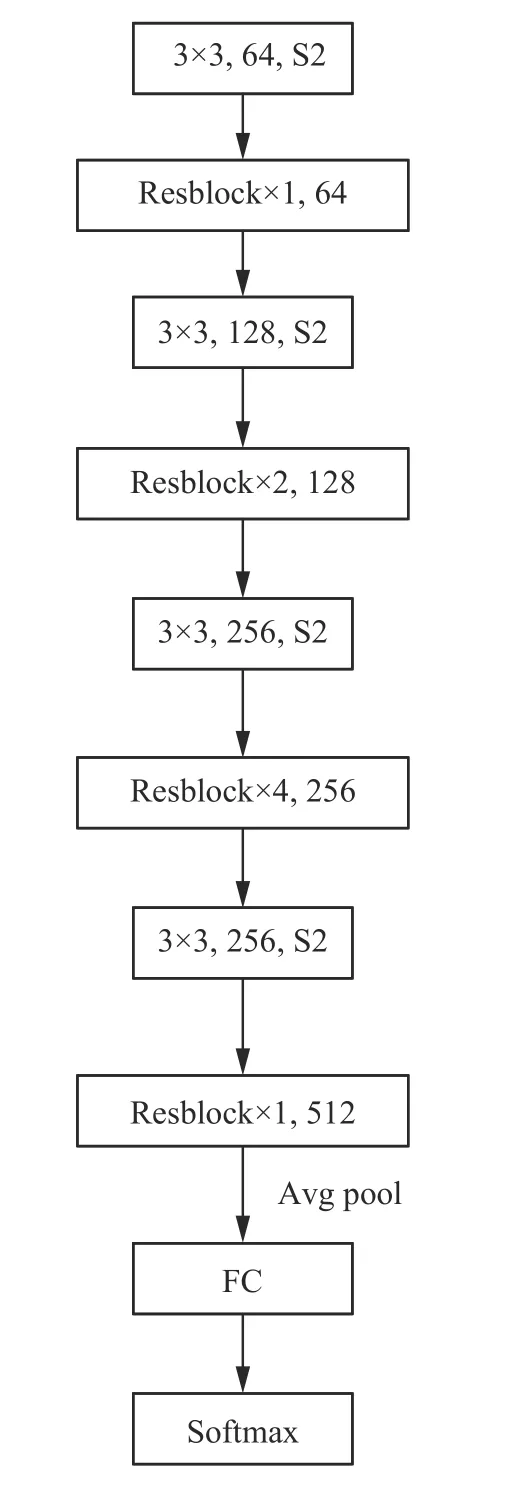
图 2 ResNet网络结构Fig. 2 Structure of ResNet

图 3 Resblock结构Fig. 3 Structure of Resblock
1.3 特征融合
特征融合是为了将不同类型的特征进行整合,实现去冗余,从而得到有利于分析处理的特征,在神经网络中直观的融合方式一般分为add和concatenate两种,add方式是特征图相加,使得描述图像的特征下的信息量增多了,但是描述图像的维度本身并没有增加,只是每一维下的信息量在增加,这显然是对最终的图像分类是有益的。而concatenate是通道数的合并,也就是说描述图像本身的特征增加了,而每一特征下的信息是没有增加。网络中的多层信息的直接拼接并不能更好地利用特征之间的互补性,所以考虑将特征映射到多个子空间进行加权融合,再拼接起来。

图 4 基于ResNet改进的网络结构Fig. 4 Improved network structure based on ResNet
结合神经网络训练方式,与一般的神经网络方法类似,子空间数目作为超参数,对于各个子空间,定义各自对应的中心变量并随机初始化,映射矩阵也通过同样随机初始化,根据特征与中心变量之间的距离来计算自适应权重,与神经网络模型参数一样,最终所有的映射矩阵和中心变量都通过BP算法训练神经网络来得到。
假设提取了n层特征,每层特征用Fi(i=1,2,···n) 表示,特征维度为 d,定义映射矩阵将特征映射到子空间,在子空间下进行加权融合,定义中心变量 M=[M1,M2,···,Mk]∈R1×f,其中d=k×f,k 表示设置的子空间数量,f 表示映射到子空间后的特征维度。计算自适应权重,然后将各个子空间特征拼接起来,特征融合过程如下:

式中:swi,j表示在第j个子空间中第i个特征对应的权重; S Fj表示在第j个子空间按权重相加融合后的特征; S F 表示将各个子空间融合特征拼接起来 形成的最后的融合特征。
1.4 决策融合
为进一步提高效果,与特征融合类似,直接对分类结果进行加权融合,同样通过训练获得中心变量最优值,中心变量不仅仅用于决策融合,为了更好地利用中心变量,加强多层特征的联系,在1.5小节介绍了利用训练过程中学习到中心变量来计算加权融合相似度。
将特征 Fi(i=1,2,···,n)(这里包括融合特征)送入Softmax分类器后,特征对应输出结果为CFi(i=1,2,···,n),类别数为c,定义中心变量 DM∈R1×df,决策融合方式如下:

式中: d wi为第i个结果对应的权重;DF 为融合后的 输出决策结果。
1.5 加权融合相似度
一般人脸识别、人脸验证中,提取特征后,通过欧式距离或者余弦距离来判断两张人脸的相似度,目前常用的是使用余弦距离。
从1.4节我们得到了中心变量 DM,从而能够得到多层特征的决策融合权重,多层特征对应多个相似度,权重大的特征对应的相似度也应该占更大权重,计算方式如下。
首先计算两张图片对应的两组特征 {F11,F12,···,F1n} 和 {F21,F22,···,F2n} 对应的余弦距离即相似度 {Sim1,Sim2,···,Simn},以及对应的两组权重{w11,w12,···,w1n}和{w11,w12,···,w1n},计算方式为

最终融合的相似度为

1.6 训练使用的损失函数
神经网络训练一般使用BP算法,而损失函数最直观的作用就是通过计算其反传梯度来实现对模型参数的更新,使用不同的损失函数往往可以使模型更加侧重于学习到数据某一方面的特性,并在之后能够更好地保证提取到的特征的独有特性,因此损失函数对于网络优化有导向性的作用。
神经网络一般使用交叉熵损失函数来训练,形式为

式中:WTjxi+bj代表全连接层输出;yi表示对应输入样本的真实类别标签,在损失函数下降过程中实质是提高 WyTixi+byi所占的比重,使得该类的样本更多地落入到该类的决策边界之内。
但是对于人脸识别来说,交叉熵损失函数无法保证提取的特征的类间距离增大,主要考虑样本是否能正确分类,缺乏类内和类间距离的约束。为解决人脸识别中损失函数的问题一般从两个方面入手,一方面是结合度量学习的方法[11-14],另一方面在此Softmax交叉熵损失函数的基础上进行了改进。CenterLoss[12]在交叉熵损失函数后面添加额外损失函数,加强对类内距离的约束,使得同个类直接的样本的类内特征距离变得紧凑。CenterLoss使得类内变得紧凑,但是对类间没有足够约束。于是直接对交叉熵损失函数进行改进[15-18],先对W和x进行归一化操作,将其转换为余弦距离表示为
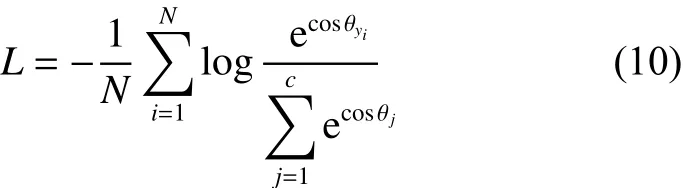
然后引入间隔约束,这里使用文献[17]提出的AM-Softmax方法:

对于所有特征,各自送入Softmax分类器,使
用式(11)损失函数:
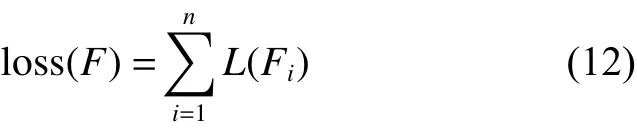
在此基础上,增加融合部分的损失,损失函数计算流程如下:1)图片预处理后输入神经网络;2)提取多层特征后进行特征融合;3)融合后的特征送入Softmax分类器计算loss(SF);4)每层提取的特征送入Softmax分类器计算loss(F);5) 每层提取的特征送入Softmax分类器后的结果进行决策融合,计算loss(DF)。
对于特征融合部分,将融合后的特征送入Softmax分类器,使用上述损失函数,用loss(SF)表示;对于决策融合部分,直接应用上述损失函数,用loss(DF)表示。将所有的损失函数相加,作为最终的损失函数,最终的形式为
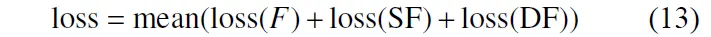
2 实验结果与分析
为验证本文提出方法的有效性,在LFW、CASIA-FaceV5、CNBC等人脸数据集上进行人脸识别实验。实验主要分为Close-set和Open-set两个部分,Close-set指的是所有的测试集类别都在训练集中出现过,所以每次的预测直接得出测试图片的ID;Open-set指的是训练集中没有出现过测试集的类别[15,19]。
实验环境使用Tensorflow框架,Tensorflow是一个采用数据流图形式,用于数值计算的开源软件库,支持GPU加速,自动求微分的能力等优点,使得研究人员能够更便捷地研究与应用神经网络。
2.1 Closet-set实验
LFW[20]数据集是由13 000多张全世界知名人士在自然场景下不同朝向、表情和光照环境人脸图片组成,共有5 000多人。每张人脸图片都有其唯一的姓名ID和序号加以区分。实验使用所有图片,进行数据增强扩充图片数量后,随机划分训练集与测试集,训练集与测试比例为3∶1,训练前进行归一化预处理,取特征融合子空间数量为k=4。实验结果如表1所示,其中,MLFF指的是本文改进方法,ResNet为图2所示结构,Normalization指的是1.6节介绍的归一化操作。
之后以同样的条件在以下数据集上进行了实验,CNBC数据集包括200多个不同种族的200多个人的多幅图像,其中收集了每个人相隔几周后发型或胡子变化的图片,实验结果如表2所示。

表 1 在LFW上的实验结果Table 1 Experimental results on LFW

表 2 在CNBC上的实验结果Table 2 Experimental results on CNBC
CASIA-FaceV5数据集包含了来自500个人的2 500张亚洲人脸图片,实验结果如表3所示。
由于一般的Softmax难以训练且效果较差,所以使用Centerloss时进行归一化操作,从表1~3可知,与ResNet相比,同样使用AM-Softmax,改进后的正确率有所提升,同时与其他的方法相比,本文方法的效果也有所提升。
子空间数量对结果会有一定的影响,表4为不同子空间数量下的实验结果。

表 3 在CASIA-FaceV5上的实验结果Table 3 Experimental results on CASIA-FaceV5
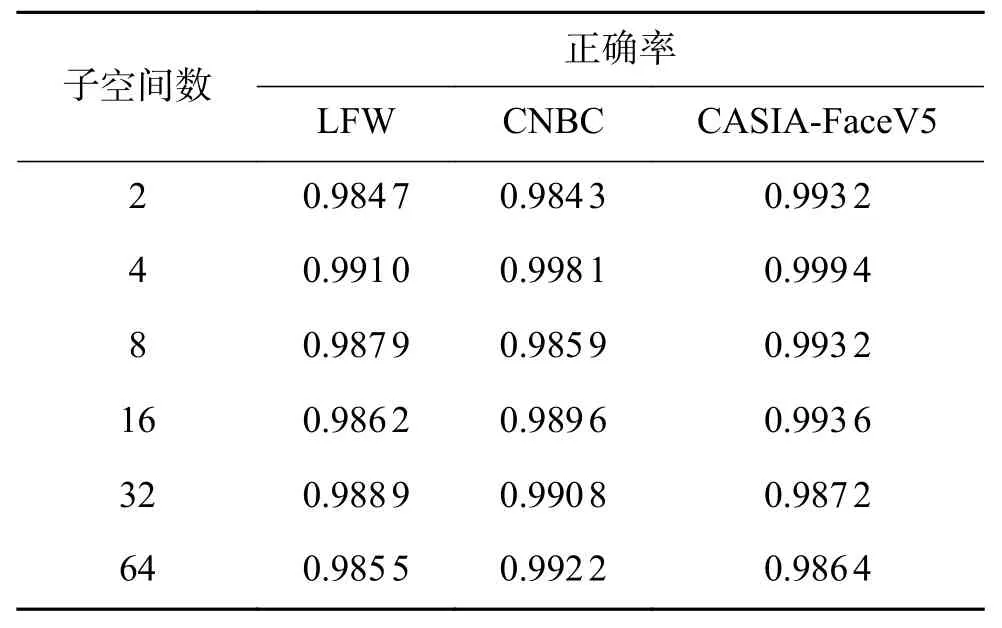
表 4 不同子空间下的实验结果Table 4 Experimental results in different subspaces
从表4可以看出,随着子空间数量的增加,正确率先上升后下降,根据结果在实验过程中选择k=4作为子空间数量。
2.2 Open-set实验
实验时选择CASIA-WebFace作为训练集,LFW作为测试集,在LFW标准协议上的人脸识别算法性能比较。
由于实验条件限制,在有限的条件下,图片裁剪人脸部分后,重组大小为56×48,在RGB图像中,每个像素([0, 255])通过减去127.5然后除以128进行归一化。使用随机梯度下降法进行优化,权重衰减设置为0.000 5,学习率最初设置为0.1,当训练迭代次数达到16 000、28 000、38 000时,分别设为0.01、0.001、0.000 1,迭代次数达到40 000已 基本收敛,完成训练。实验结果如表5所示。

表 5 CASIA-WebFace作为训练集, 在LFW标准协议上的实验结果Table 5 CASIA-WebFace as a training set, experimental results on the LFW standard protocol
从表5可知,融合后的特征具有更好的识别效果,同样使用AM-Softmax,在同样的条件下,融合特征的效果更好。同时利用训练得到的中心变量计算融合相似度,能够有效利用多层特征之间的互补性,进一步提高识别效果。
3 结束语
本文提出的神经网络多层特征信息融合的人脸识别方法,在已有的网络结构基础上对结构进行适当改进,使得其更适合提取多层特征,然后对提取的多层特征在子空间进行加权特征融合并拼接,对每层特征分类结果进行加权决策融合,定义中心变量计算自适应权重,结合神经网络学习中心变量,并利用学习到的中心变量来计算加权融合相似度,进一步提升效果。在LFW等数据集上进行的实验证明了改进后的方法比原来的效果更好,Open-Set情况下,在LFW上提升2.2%。
本文是在特征融合与决策融合层面进行研究与实验,而3维人脸数据能对人脸识别的提高起到作用,可以从这一方面或者是其他多源数据考虑数据融合;同时在训练神经网络时,多个损失函数直接相加,不一定能达到最优的训练效果,可做进一步改进。下一步可以将融合相似度的方法加入到分类器中,做进一步的研究。
