深度优先局部聚合哈希
2021-07-03龙显忠程成李云
龙显忠,程成,李云
(1.南京邮电大学 计算机学院,江苏 南京 210023;2.江苏省大数据安全与智能处理重点实验室,江苏 南京 210023)
随着信息检索技术的不断发展和完善,如今人们可以利用互联网轻易获取感兴趣的数据内容,然而,信息技术的发展同时导致了数据规模的迅猛增长.面对海量的数据以及超大规模的数据集,利用最近邻搜索[1](Nearest Neighbor Search,NN)的检索技术已经无法获得理想的检索效果与可接受的检索时间.因此,近年来,近似最近邻搜索[2](Approximate Nearest Neighbor Search,ANN)变得越来越流行,它通过搜索可能相似的几个数据而不再局限于返回最相似的数据,在牺牲可接受范围的精度下提高了检索效率.作为一种广泛使用的ANN 搜索技术,哈希方法(Hashing)[3]将数据转换为紧凑的二进制编码(哈希编码)表示,同时保证相似的数据对生成相似的二进制编码.利用哈希编码来表示原始数据,显著减少了数据的存储和查询开销,从而可以应对大规模数据中的检索问题.因此,哈希方法吸引了越来越多学者的关注.
当前哈希方法主要分为两类:数据独立的哈希方法和数据依赖的哈希方法,这两类哈希方法的区别在于哈希函数是否需要训练数据来定义.局部敏感哈希(Locality Sensitive Hashing,LSH)[4]作为数据独立的哈希代表,它利用独立于训练数据的随机投影作为哈希函数.相反,数据依赖哈希的哈希函数需要通过训练数据学习出来,因此,数据依赖的哈希也被称为哈希学习,数据依赖的哈希通常具有更好的性能.近年来,哈希方法的研究主要侧重于哈希学习方面.
根据哈希学习过程中是否使用标签,哈希学习方法可以进一步分为:监督哈希学习和无监督哈希学习.典型的无监督哈希学习包括:谱哈希[5](Spectral Hashing,SH);迭代量化哈希[6](Iterative Quantization,ITQ);离散图哈希[7](Discrete Graph Hashing,DGH);有序嵌入哈希[8](Ordinal Embedding Hashing,OEH)等.无监督哈希学习方法仅使用无标签的数据来学习哈希函数,将输入的数据映射为哈希编码的形式.相反,监督哈希学习方法通过利用监督信息来学习哈希函数,由于利用了带有标签的数据,监督哈希方法往往比无监督哈希方法具有更好的准确性,本文的研究主要针对监督哈希学习方法.
传统的监督哈希方法包括:核监督哈希[9](Supervised Hashing with Kernels,KSH);潜在因子哈希[10](Latent Factor Hashing,LFH);快速监督哈希[11](Fast Supervised Hashing,FastH);监督离散哈希[12](Supervised Discrete Hashing,SDH)等.随着深度学习技术的发展[13],利用神经网络提取的特征已经逐渐替代手工特征,推动了深度监督哈希的进步.具有代表性的深度监督哈希方法包括:卷积神经网络哈希[14](Convolutional Neural Networks Hashing,CNNH);深度语义排序哈希[15](Deep Semantic Ranking Based Hashing,DSRH);深度成对监督哈希[16](Deep Pairwise-Supervised Hashing,DPSH);深度监督离散哈希[17](Deep Supervised Discrete Hashing,DSDH);深度优先哈希[18](Deep Priority Hashing,DPH)等.通过将特征学习和哈希编码学习(或哈希函数学习)集成到一个端到端网络中,深度监督哈希方法可以显著优于非深度监督哈希方法.
到目前为止,大多数现有的深度哈希方法都采用对称策略来学习查询数据和数据集的哈希编码以及深度哈希函数.相反,非对称深度监督哈希[19](Asymmetric Deep Supervised Hashing,ADSH)以非对称的方式处理查询数据和整个数据库数据,解决了对称方式中训练开销较大的问题,仅仅通过查询数据就可以对神经网络进行训练来学习哈希函数,整个数据库的哈希编码可以通过优化直接得到.本文的模型同样利用了ADSH 的非对称训练策略.
然而,现有的非对称深度监督哈希方法并没有考虑到数据之间的相似性分布对于哈希网络的影响,可能导致结果是:容易在汉明空间中保持相似关系的数据对,往往会被训练得越来越好;相反,那些难以在汉明空间中保持相似关系的数据对,往往在训练后得到的提升并不显著.同时大部分现有的深度监督哈希方法在哈希网络中没有充分有效利用提取到的卷积特征.
本文提出了一种新的深度监督哈希方法,称为深度优先局部聚合哈希(Deep Priority Local Aggregated Hashing,DPLAH).DPLAH 的贡献主要有三个方面:
1)DPLAH 采用非对称的方式处理查询数据和数据库数据,同时DPLAH 网络会优先学习查询数据和数据库数据之间困难的数据对,从而减轻相似性分布倾斜对哈希网络的影响.
2)DPLAH 设计了全新的深度哈希网络,具体来说,DPLAH 将局部聚合表示融入到哈希网络中,提高了哈希网络对同类数据的表达能力.同时考虑到数据的局部聚合表示对于分类任务的有效性.
3)在两个大型数据集上的实验结果表明,DPLAH 在实际应用中性能优越.
1 相关工作
本节分别对哈希学习[3]、NetVLAD[20]和Focal Loss[21]进行介绍.DPLAH 分别利用NetVLAD 和Focal Loss 提高哈希网络对同类数据的表达能力及减轻数据之间相似性分布倾斜对于哈希网络的影响.
1.1 哈希学习
哈希学习[3]的任务是学习查询数据和数据库数据的哈希编码表示,同时要满足原始数据之间的近邻关系与数据哈希编码之间的近邻关系相一致的条件.具体来说,利用机器学习方法将所有数据映射成{0,1}r形式的二进制编码(r 表示哈希编码长度),在原空间中不相似的数据点将被映射成不相似(即汉明距离较大)的两个二进制编码,而原空间中相似的两个数据点将被映射成相似(即汉明距离较小)的两个二进制编码.
为了便于计算,大部分哈希方法学习{-1,1}r形式的哈希编码,这是因为{-1,1}r形式的哈希编码对之间的内积等于哈希编码的长度减去汉明距离的两倍,同时{-1,1}r形式的哈希编码可以容易转化为{0,1}r形式的二进制编码.
图1 是哈希学习的示意图.经过特征提取后的高维向量被用来表示原始图像,哈希函数h 将每张图像映射成8 bits 的哈希编码,使原来相似的数据对(图中老虎1 和老虎2)之间的哈希编码汉明距离尽可能小,原来不相似的数据对(图中大象和老虎1)之间的哈希编码汉明距离尽可能大.

图1 哈希学习示意图Fig.1 Hashing learning diagram
1.2 NetVLAD
NetVLAD 的提出是用于解决端到端的场景识别问题[20](场景识别被当作一个实例检索任务),它将传统的局部聚合描述子向量(Vector of Locally Aggregated Descriptors,VLAD[22])结构嵌入到CNN 网络中,得到了一个新的VLAD 层.可以容易地将NetVLAD使用在任意CNN 结构中,利用反向传播算法进行优化,它能够有效地提高对同类别图像的表达能力,并提高分类的性能.
NetVLAD 的编码步骤为:利用卷积神经网络提取图像的卷积特征;利用NetVLAD 层对卷积特征进行聚合操作.图2 为NetVLAD 层的示意图.在特征提取阶段,NetVLAD 会在最后一个卷积层上裁剪卷积特征,并将其视为密集的描述符提取器,最后一个卷积层的输出是H×W×D 映射,可以将其视为在H×W 空间位置提取的一组D 维特征,该方法在实例检索和纹理识别任务[23-24]中都表现出了很好的效果.
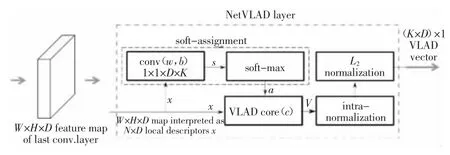
图2 NetVLAD 层示意图[20]Fig.2 NetVLAD layer diagram[20]
NetVLAD 在特征聚合阶段,利用一个新的池化层对裁剪的CNN 特征进行聚合,这个新的池化层被称为NetVLAD 层.NetVLAD 的聚合操作公式如下:

式中:xi(j)和ck(j)分别表示第i 个特征的第j 维和第k 个聚类中心的第j 维;ak(xi)表示特征xi与第k 个视觉单词之间的权.NetVLAD 特征聚合的输入为:NetVLAD 裁剪得到的N 个D 维的卷积特征,K 个聚类中心.
VLAD 的特征分配方式是硬分配,即每个特征只和对应的最近邻聚类中心相关联,这种分配方式会造成较大的量化误差,并且,这种分配方式嵌入到卷积神经网络中无法进行反向传播更新参数.因此,NetVLAD 采用软分配的方式进行特征分配,软分配对应的公式如下:

如果α→+∞,那么对于最接近的聚类中心,ak(xi)的值为1,其他为0.ak(xi)可以进一步重写为:

式中:wk=2αck;bk=-α‖ck‖2.最终的NetVLAD 的聚合表示可以写为:
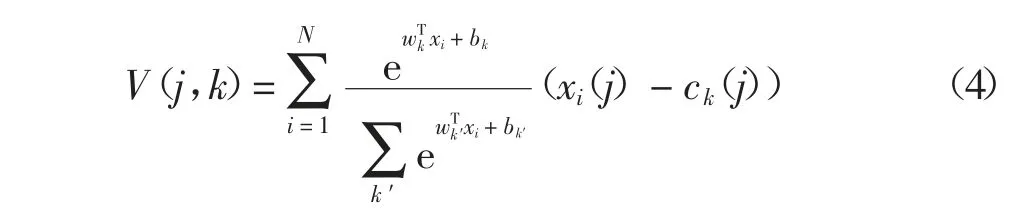
1.3 Focal Loss
对于目标检测方法,一般可以分为两种类型:单阶段目标检测和两阶段目标检测,通常情况下,两阶段的目标检测效果要优于单阶段的目标检测.Lin 等人[21]揭示了前景和背景的极度不平衡导致了单阶段目标检测的效果无法令人满意,具体而言,容易被分类的背景虽然对应的损失很低,但由于图像中背景的比重很大,对于损失依旧有很大的贡献,从而导致收敛到不够好的一个结果.Lin 等人[21]提出了Focal Loss 应对这一问题,图3 是对应的示意图.使用交叉熵作为目标检测中的分类损失,对于易分类的样本,它的损失虽然很低,但数据的不平衡导致大量易分类的损失之和压倒了难分类的样本损失,最终难分类的样本不能在神经网络中得到有效的训练.Focal Loss 的本质是一种加权思想,权重可根据分类正确的概率pt得到,利用γ 可以对该权重的强度进行调整.

图3 Focal Loss 示意图[21]Fig.3 Focal Loss diagram[21]
针对非对称深度哈希方法,希望难以在汉明空间中保持相似关系的数据对优先训练,具体来说,对于DPLAH 的整体训练损失,通过施加权重的方式,相对提高难以在汉明空间中保持相似关系的数据对之间的训练损失.然而深度哈希学习并不是一个分类任务,因此无法像Focal Loss 一样根据分类正确的概率设计权重,哈希学习的目的是学到保相似性的哈希编码,本文最终利用数据对哈希编码的相似度作为权重的设计依据,具体的权重形式将在模型部分详细介绍.
2 深度优先局部聚合哈希
2.1 基本定义
对于DPLAH 模型,它在特征提取部分采用预训练好的Resnet18 网络[25].图4 为DPLAH 网络的结构示意图,利用NetVLAD 层聚合Resnet18 网络提取到的卷积特征,哈希编码通过VLAD 编码得到,由于VLAD 编码在分类任务中被广泛使用,于是本文将NetVLAD 层的输出作为分类任务的输入,利用图像的标签信息监督NetVLAD 层对卷积特征的利用.事实上,任何一种CNN 模型都能实现图像特征提取的功能,所以对于选用哪种网络进行特征学习并不是本文的重点.
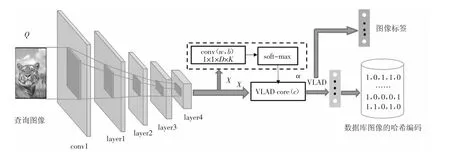
图4 DPLAH 结构Fig.4 DPLAH structure
2.2 DPLAH 模型的目标函数
为了学习可以保留查询图像与数据库图像之间相似性的哈希编码,一种常见的方法是利用相似性的监督信息S∈{-1,1}n×m、生成的哈希编码长度r,以及查询图像的哈希编码ui和数据库中图像的哈希编码bj三者之间的关系[9],即最小化相似性的监督信息与哈希编码对(ui,bj)内积之间的L2损失.考虑到相似性分布的倾斜问题,本文通过施加权重来调节查询图像和数据库图像之间的损失,其公式可以表示为:
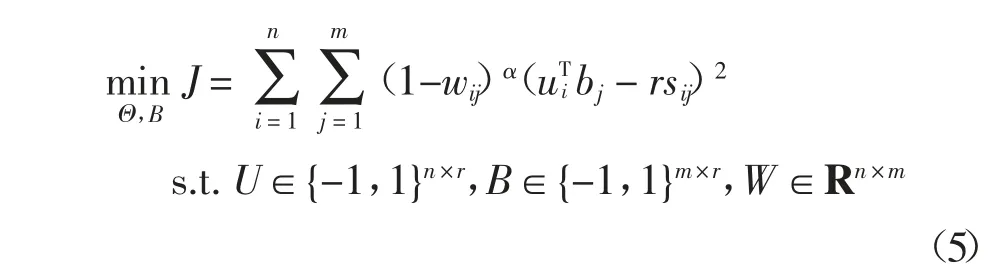
受Focal Loss 启发,希望深度哈希网络优先训练相似性不容易保留图像对,然而Focal Loss 利用图像的分类结果对损失进行调整,因此,需要重新进行设计,由于哈希学习的目的是为了保留图像在汉明空间中的相似性关系,本文利用哈希编码的余弦相似度来设计权重,其表达式为:
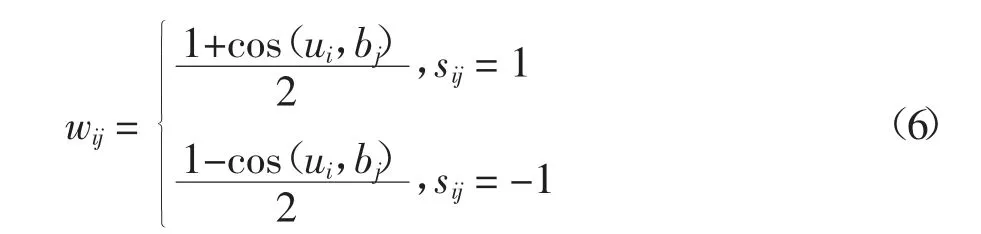
式中:ui和bj分别表示查询图像i 和数据库图像j 的哈希编码;sij=1 表示图像i 和j 语义相似,sij=-1 表示图像i 和j 语义不相似.从公式(6)中可以发现,若ui和bj越相似,且图像i 和j 语义相似,则wij的值接近1,这就表示哈希编码ui和bj相似的难度低;反之ui和bj不相似,而图像i 和j 语义相似,则wij的值接近0,这就表示哈希编码ui和bj相似的难度高.本文希望深度哈希网络优先关注相似难度高的图像对,因此对查询图像和数据库图像之间施加权重(1-wij)α,α是一个超参数.

使用Ψ={1,2,…,m}表示数据库中所有图像的索引,随机地从数据库中选择nΨΥ 张图像创建查询集,并用Υ={i1,i2,…,in}⊆Ψ 表示查询集的索引.此时,公式(7)可以表示为:
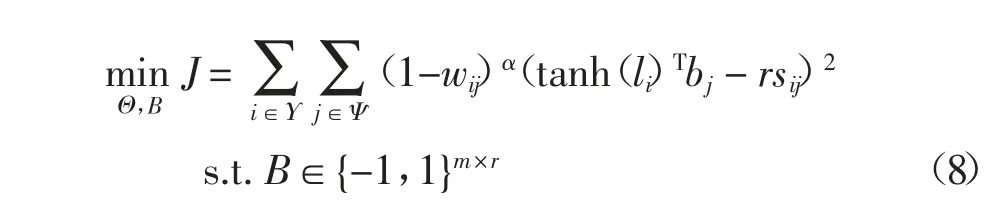
创建的查询集通过深度哈希网络生成哈希编码,同样它们在整个数据集中的哈希编码也可以通过优化直接得到,因此,还需要保证查询集在哈希网络中学习到的哈希编码要与数据集中的哈希编码尽可能相同.对应的优化问题可进一步表示为:
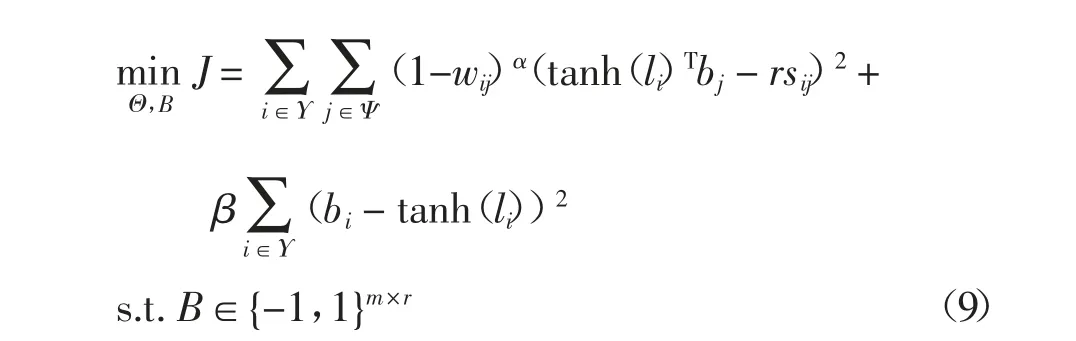
由于VLAD 对于图像具有较好的表示性能,并且VLAD 同样被广泛运用于图像分类任务中,因此,NetVLAD 层的输出对于分类任务也依然有效,并将NetVLAD 层的输出pi作为分类网络的输入.利用NetVLAD 在分类网络中的预测标签和图像的真实标签之间的损失更新网络参数,希望图像哈希网络能够提取到更具有判别力的特征.最终,DPLAH 的目标函数可写为:
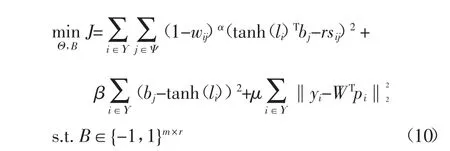
2.3 学习过程
本文采用迭代优化的方式来学习DPLAH 网络的参数Θ 和数据库图像的哈希编码B.算法1 是整个DPLAH 算法的学习过程.
固定B,学习参数Θ.当B 被固定,直接使用反向传播算法(BP)来更新参数Θ,具体来说,从查询集中采样一个批次的图像来更新深度哈希网络的参数.
固定参数Θ,学习B.当深度哈希网络的参数Θ被固定时,使用与非对称深度哈希[19]相同的优化策略来更新数据库中的哈希编码B,公式如下所示:
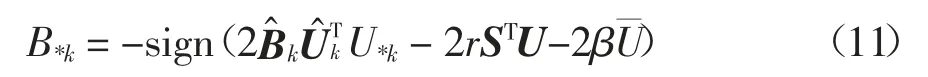
式中:B*k表示B 的第k 列;是矩阵B 除了第k 列的矩阵;U*k表示U 的第k 列;是矩阵U 除了第k列的矩阵;S 为相似性矩阵.

3 实验设计与分析
3.1 实验设计
3.1.1 数据集
为了验证DPLAH 算法的有效性,在CIFAR-10[26]和NUS-WIDE[27]数据集上进行实验.
CIFAR-10 数据集由60 000 张32×32 的RGB彩色图像构成,它是一个用于识别普适物体的数据集.这些图像被手动标记为10 个类别,分别是飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车.
NUS-WIDE 是一个真实的网络数据集,一共包含269 648 张图像,每张图像都与来自81 个语义类别中的一个或多个类别相关联.本文遵循与ADSH类似的实验方案,使用最常见的21 个类别中的图像,其中每个类别中至少包含了5 000 张图像,从而总共使用了195 834 张图像.
3.1.2 实验运行环境及超参数配置
所有关于DPLAH 的实验都是利用Pytorch 深度框架完成的,利用预训练好的Resnet18 网络[25]提取图像的特征,NetVLAD 层对Resnet18 模型输出的卷积特征进行聚合,最后,利用聚合得到的特征进行哈希编码的学习.
对CIFAR-10 和NUS-WIDE 数据集,NetVLAD的聚类中心个数设置为64.超参数β、μ 和Υ 分别设置为200、200 和2 000,DPLAH 网络的学习率在10-7~10-3区间进行调整,tl和ts分别为60 和3,超参数α 为0.2.
在本文实验中,使用到的NetVLAD 层去掉了规范化操作,由于整个数据集的哈希编码是通过优化算法直接得到,因此在训练初期并不使用权重.具体来说,当超参数tl的值小于10 时,都不施加优先权重;当tl的值大于10 时,施加权重进行训练的同时,会对学习率进行调整.
3.1.3 实验对比
按照现有的深度哈希方法中的评估指标,使用平均准确率均值(MAP)和Top-5K 精度来评估DPLAH 算法的性能.对于NUS-WIDE 数据集,计算前5 000 张返回图像的MAP.对于CIFAR-10 数据集,在每个类别中选取100 张图像作为测试图像,对于NUS-WIDE 数据集,同样在每个类别中选取100张图像作为测试图像,因此这两个数据集的测试图像数量分别为1 000 和2 100 张,剩余图像作为数据库图像.遵循非对称深度哈希等方法[19]在图像相似性上的构造方法,利用图像标签构造用于深度哈希函数学习的相似性矩阵.具体来说:若两张图像共享至少一个标签,则它们被视为语义相似对,否则,它们是语义不相似的图像对.
多种哈希学习方法被用来与DPLAH 进行比较,如SH、ITQ 等无监督的哈希方法(包括SH+CNN、ITQ+CNN),SDH、FastH 和LFH 等有监督的哈希方法(包括SDH+CNN、FastH+CNN 和LFH+CNN),CNNH、DPSH 和ADSH 等深度哈希方法(其中CNNH 是两阶段的深度哈希学习方法,其他都是端到端的深度哈希学习方法).
3.2 实验结果和分析
在两个数据集上的MAP 对比结果如表1 所示.由于ADSH 算法的优越性能,它成为本文重点比较的方法.为了进行公平的比较,此处利用Pytorch 版本的ADSH 来进行实验对比,预训练好的Resnet18模型同样会被用来提取图像的卷积特征,其他哈希算法的实验结果来源于DPSH[16]和ADSH[19].
表1 中的非深度哈希学习算法使用图像的手工特征,同时也比较了使用CNN 特征的非深度哈希学习算法,可以发现端到端的深度哈希方法优于传统的哈希学习方法,非对称的深度哈希方法优于对称的深度哈希方法.与LFH+CNN 的最好结果0.814 相比,DPLAH 的平均准确率均值要高出11%,同时,DPLAH 的平均准确率均值最多比非对称深度监督哈希方法ADSH 高出2%.
由于非对称深度监督哈希方法(ADSH)的性能远优于其他哈希学习方法,因此,比较DPLAH 和ADSH 在不同比特长度下的Top-5K 精度,结果如图5 所示.由表1 和图5 可知,DPLAH 无论在MAP 还是Top-5K 精度的衡量下,其性能都优于现有的深度监督哈希方法.
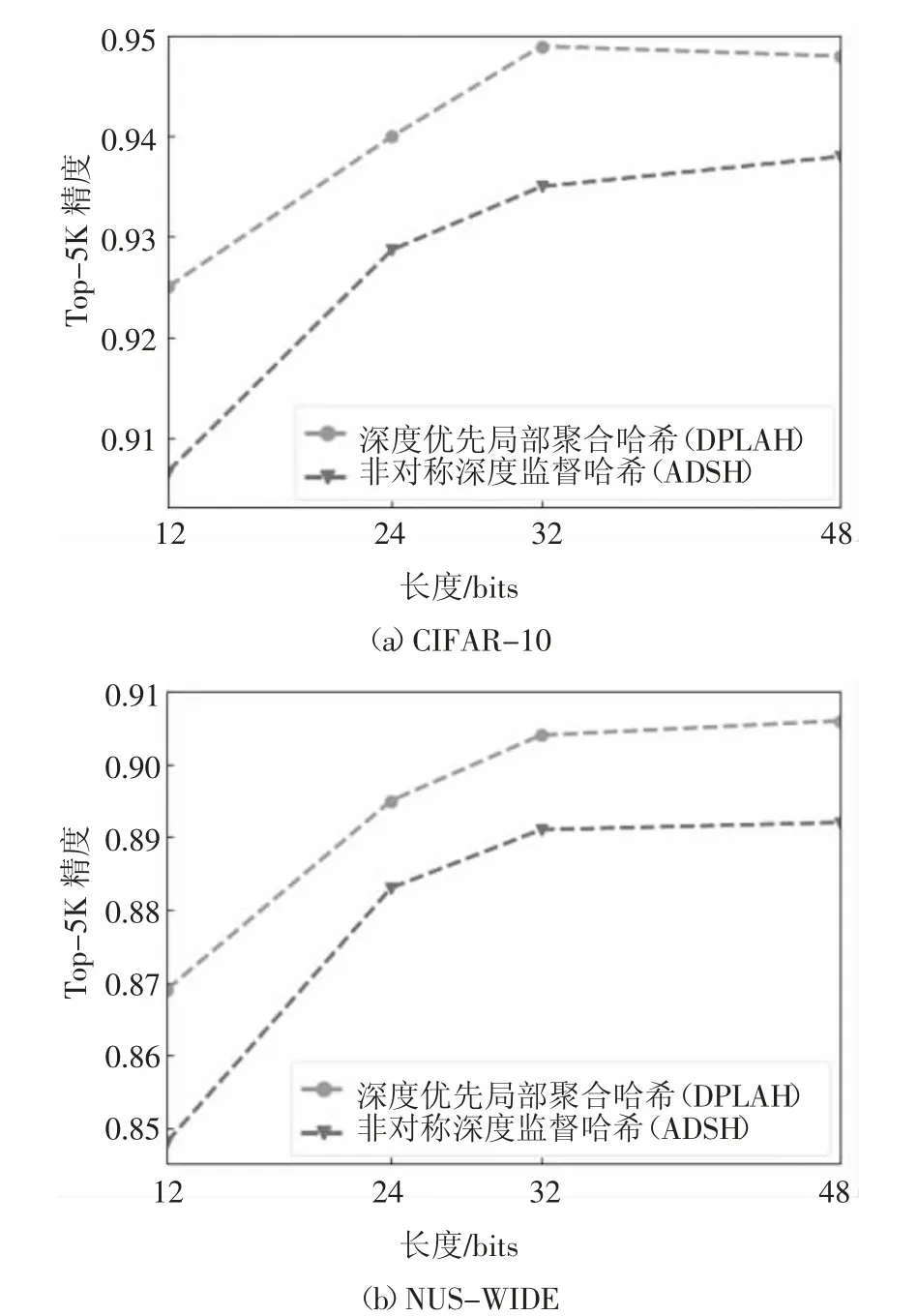
图5 两个数据集下的Top-5K 精度Fig.5 Top-5K precision under two data sets
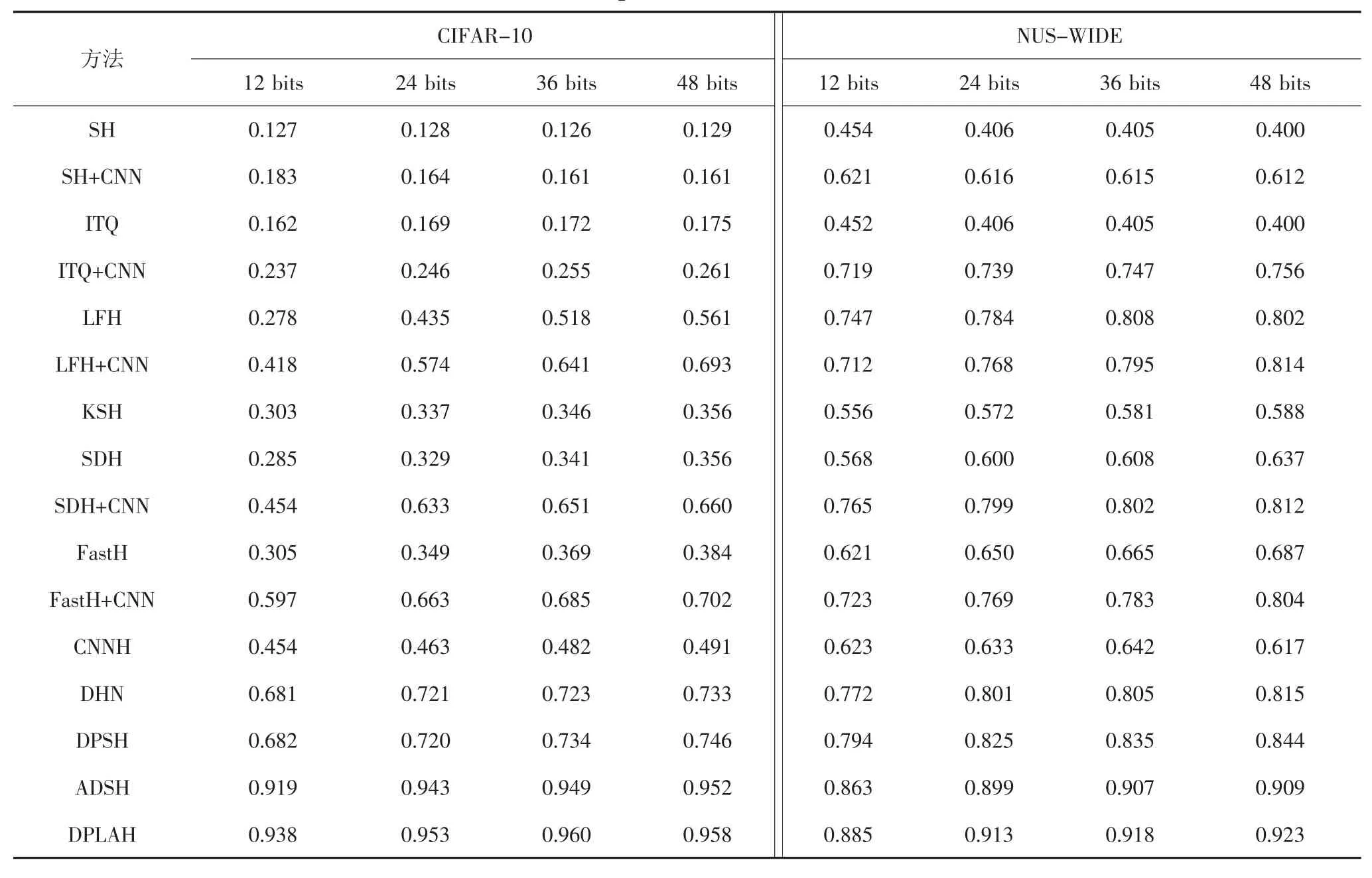
表1 两个基准数据集上的MAP 对比Tab.1 The MAP comparison on two benchmark datasets
根据实验结果,发现DPLAH 方法在NUS-WIDE数据集上性能较好.这可能由于NUS-WIDE 数据集中的图像来自于真实世界,图像中包含的内容非常丰富;而NetVLAD 的提出就是为了解决现实中的场景识别问题,在面对图像中的光线变化、视角变化等情况,具备一定的鲁棒性,从而使得DPLAH 方法在NUS-WIDE 数据集上的性能较好.
为了验证NetVLAD 层确实能学习到具有区分力的哈希编码,本文在NUS-WIDE 数据集不使用优先权重的条件下,仅仅将NetVLAD 层加入哈希网络中,对比不同比特长度下的MAP.实验结果如图6 所示.
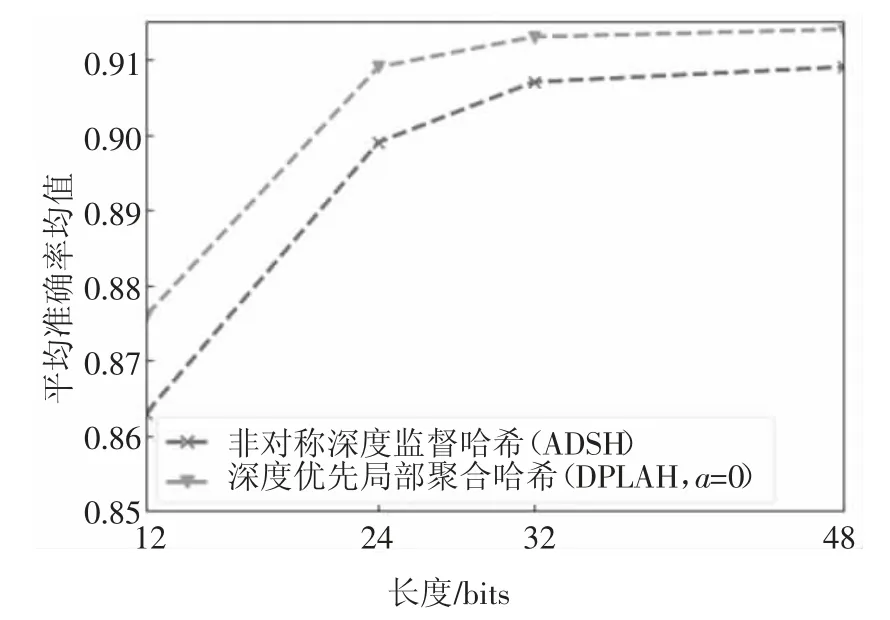
图6 在NUS-WIDE 数据集上的NetVLAD 实验结果Fig.6 NetVLAD experiment result on NUS-WIDE dataset
图7 为DPLAH 算法基于汉明距离排序的搜索结果.结果是基于32 bits 的哈希编码长度给出的几个示例.在图7 中,每行图片中的第1 张代表查询图像,后面10 张图像表示与查询图像的汉明距离最近的10 张图像.由图7 可知,DPLAH 算法具有优越的性能,尽管还存在一些错误的搜索结果(示例中最后一行的查询图像是飞机,然而检索出的图像是轮船),但这在接受的范围内.

图7 在CIFAR-10 数据集上的检索示例Fig.7 Retrieval example on CIFAR-10 dataset
4 结论
本文提出了一种基于局部聚合的深度优先哈希方法,在应对相似性分布倾斜方面,受到了Focal Loss 的启发,利用查询图像在哈希网络中学习的哈希编码和整个数据库图像的哈希编码之间的余弦相似度,设计了损失函数的优先权重,使得深度哈希网络优先关注相似难度高的图像,从而保证难以在汉明空间中保持相似关系的图像对得到充分训练.在哈希特征提取方面,由于NetVLAD 层能够有效地提高对同类别图像的表达能力,因此利用NetVLAD 层将卷积得到的特征进行聚合,从而使学到的哈希编码更具有区分性.在CIFAR-10 和NUS-WIDE 两个数据集下进行了实验,将DPLAH 与多种哈希学习方法进行比较,通过实验分析,表明了DPLAH 算法的优越性能.
