基于FPGA 的SoC 接口在CNN 加速器中的研究
2021-06-27夏冰洁王琴
夏冰洁,王琴
(上海交通大学电子信息与电气工程学院,上海 200240)
集成电路的概念出现后,集成电路设计从早期简单逻辑门的集成,逐渐地发展到了知识产权(Intellectual Property core,IP 核)的集成,人们对于更加微型且集成了更多功能的芯片要求越来越高。需求刺激了新技术的发展,新技术又刺激产生了新一轮的需求。到目前为止,已经实现了在一方小小的芯片上集成十几个IP 的功能。
当涉及多个IP核同时运作时,对数据流的控制就显得尤为重要。为了使数据能够有条不紊地在各个IP 核之间流通,如何协调各个IP 之间的关系、对多个IP 进行全局控制成为了最重要的研究课题。
1 整体架构搭建
在卷积神经网络加速器的整体框架中,针对卷积神经网络计算量大、数据流动复杂等特点,在Vivado 2018.3 中搭建了一个整体的数据通路框架,其基本的数据流程如图1 所示。
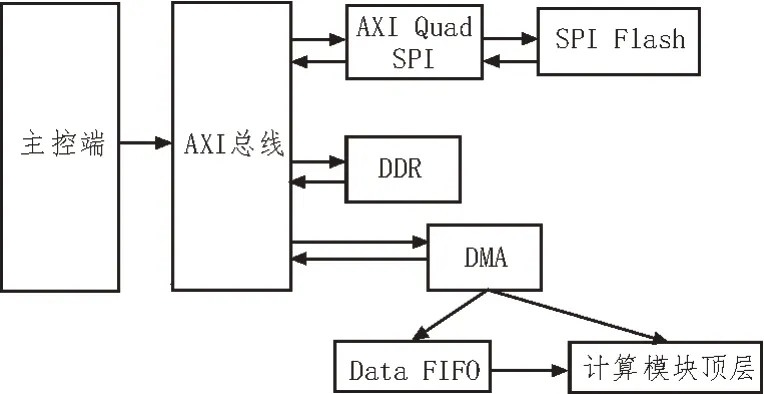
图1 基本数据流程
目前,对SoC 接口设计的研究面较为广泛,但多数研究仍然集中在已经普及使用的AXI 总线协议对应的接口设计。在对自定义IP 的研究方面,虽然许多功能因为经常被调用而被封装成了IP,但因为缺乏通用的协议而限制了对它的使用。
如图1 所示,基本数据流框架是指首先在主控端中编写接口的驱动代码,这些代码经过AXI 总线与FPGA 进行通信,先通过AXI Quad SPI 这个接口转接IP 操控SPI Flash 内的数据,并将其中的数据输出至AXI总线。接着,主控端的C代码继续操控连在AXI总线上的DMA,利用DMA对DDR进行配置,就能将AXI总线上的数据读取至DDR 中。然后,当需要将DDR内数据输出至计算模块时,再将DDR的地址配置进读写通道,将DDR 内对应地址中的数据读取出来,经由Data FIFO 输入计算模块顶层,供加速器算法使用。
1.1 SPI Flash至AXI总线通路设计
AXI Quad SPI是一个用于接口转换功能的IP。该IP 的一端以AXI4 Lite协议为接口,另一端则以SPI协议为接口。因此,这个IP实现了从AXI Lite协议到SPI协议的接口转换功能。通过引入AXI Quad SPI 接在SPI Flash 和AXI 总线之间,可以将AXI Quad SPI 和SPI Flash 两者视为一个以AXI 协议为接口的Flash存储器,整体框架如图2所示。

图2 AXI Quad SPI与SPI Flash整体框架
1.2 DDR到AXI总线通路设计
在整体框架中,通过引入AXI DMA 这一IP,可以实现控制板上外围设备。如图3 所示,AXI DMA 通过配置外围设备的读写通道,来对外设进行数据流的读写,在此处引入AXI DMA,可以利用其接在AXI总线上的S_AXI_Lite 实现与总线之间的数据交流。此处,为了能使数据流从SPI Flash 进入DDR,可以利用软件工具开发包(Software Development Kit,SDK)内的C 代码对该DMA 进行配置。将DDR 的基地址配置进读入数据的通道,就可以利用DMA 实现将AXI 总线上的数据读取至DDR 对应地址内的操作。

图3 从AXI到DDR数据通路
1.3 DDR到计算模块通路设计
基于计算模块本身的算法设计,其接口是自定义形成的,因此需要对该计算模块的算法外加一个顶层,以保证计算模块IP 能够以AXI 协议为接口,准确地卡在DMA 模块和先进先出存储器(First Input First Output,FIFO)模块之间,如图4所示。

图4 从DDR到计算模块数据通路
针对从DDR 中取出至Data FIFO 的数据,计算模块以AXI4 Stream 接口协议接收这部分数据,然后将数据送入计算模块内。为了能构成一个回路,再将计算模块连回DMA 以留出设计余地,以便实现计算模块中的数据再次通过DMA 传输回DDR 中的过程。
1.4 主控端驱动设计
如图5 所示,在该项目的设计中,选用的是Xil_MemCpy(参数1、参数2、参数3)函数。参数1 是一个基地址,参数2 也是一个基地址。将参数1 基地址开始往后的参数中3 个字节的数据拷贝到参数2基地址下。
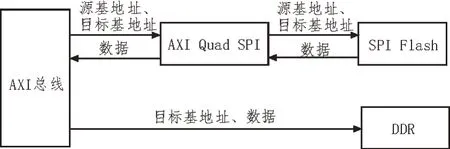
图5 Flash传输数据至DDR
2 硬件数据流优化设计
对于PingPong 操作中所用到的两块FIFO 而言,它们循环往复地进行读或写的操作。对其进行简单的分类,可以分为4 种工作状态:
1)idle状态:两块FIFO均为既不读也不写的操作;
2)start状态:FIFO1 读入数据,FIFO2 无操作;
3)Ping 状态:FIFO1 读入数据,FIFO2 写出数据;
4)Pong 状态:FIFO1 写出数据,FIFO2 读入数据;
将以上4 种状态的转换展现在状态机转换图中,如图6 所示。

图6 PingPong状态机转换流程
针对FIFO 的内部逻辑而言,需要对控制信号分别进行控制。Data_valid 信号代表FIFO 内部是否存在数据,当FIFO 内存在数据时,Data_valid=1;当FIFO 内没有数据时,Data_valid=0。当FIFO 内部没有数据并且此时要将数据读入FIFO,Data_valid 信号由0 置为1;当FIFO 内部已有数据并且此时要将数据写出至计算模块,Data_valid 信号由1 置为0。FIFO 内的逻辑控制流程如图7 所示。

图7 FIFO内逻辑控制流程
3 实验结果与分析
通过在Vivado 2018.3 平台中进行综合仿真,所得出的时序结果如表1 所示。该工程的时钟周期为10 ns,时钟频率为100 MHz,最长延迟为5.5 ns。

表1 Vivado仿真时序报告
资源报告如表2 所示。
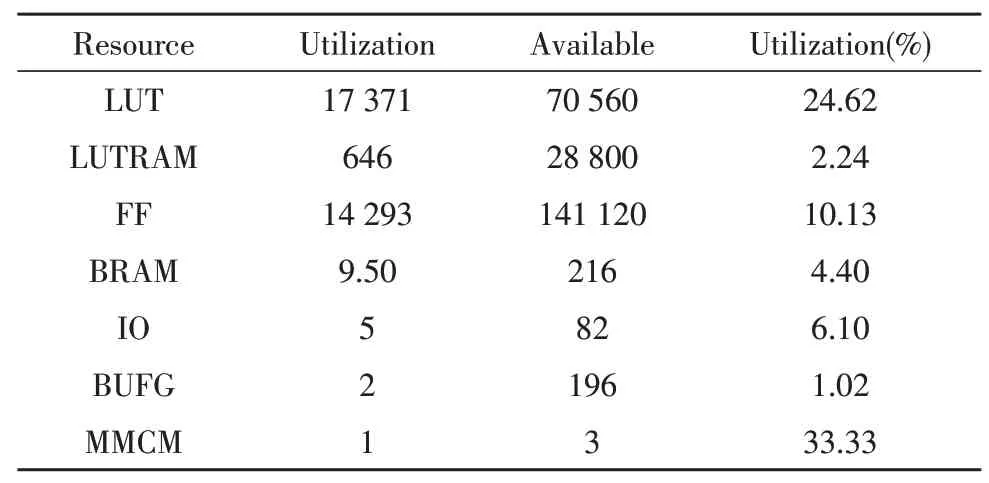
表2 Vivado仿真资源报告
除了上述时序报告和资源报告外,这个工程的带宽是3 200 Mbits,即在1 s 内,有3 200 Mbits 的数据进入计算模块被处理。
32 bits×100 MHz=3 200 Mbits
按照计算模块的需求,不同的卷积层会用到不同大小的数据量。对于一个普通的具有8 层卷积的CNN 加速器而言,根据每一层所给出的数据量,可得到输入用时,如表3 所示。

表3 每层卷积输入数据量和输入用时
4 结束语
文中依托一个典型的CNN 加速器结构,主要实现了在Vivado 2018.3 中设计底层硬件数据流通路,并对进入计算模块算法部分的数据的通路进行优化。在这个项目中,选择了DMA 访问来控制对外围存储设备的读写,并在计算模块的顶层加入一个PingPong 的FIFO 来对进入计算模块的数据进行流水化操作。最终实现了对数据流架构的优化,使得时钟周期达到10 ns,并依次给出了资源报告和每层卷积的输入用时。该项目对基于FPGA 的SoC 接口设计具有参考意义,提供了一种SoC 接口设计方法,为未来的研究提供了一个参考方向。
