改进深度可分离卷积的SSD车型识别
2021-06-24郭融,王芳,刘伟
郭 融,王 芳,刘 伟
(太原理工大学 电气与动力工程学院,太原 030024)
随着人民生活水平的提高,汽车成了生活中人们常见的代步工具,在方便人们生活的同时,也造成了道路交通难以得到有效监管的问题。车型识别是电子不停车收费系统(electronic toll collection,ETC)的关键技术之一[1],对道路上车辆的通畅行驶有重要的意义,在车辆违规行驶和被盗车辆追踪等方面也有很高的应用价值。
传统的车型识别方法依赖人工特征设计,例如利用梯度方向直方图特征进行特征提取[2],提取车辆目标后使用支持向量机分类器进行分类,应用场景单一且易受背景、光照等因素影响。深度学习作为一种特征学习方法,在经过简单的非线性变换之后把原始数据变成更深层次、高语义的特征表达[3-4],其特征是可以根据不同对象进行自适应权值调节,完成多种不同检测任务。
2015年,Ren等[5]提出基于区域建议网络(region proposal networks,RPN)的Faster R-CNN目标检测算法,获得了相较传统方法更高的检测精度,但其检测速度较慢,只有5 fps。2016年,Redmon等[6]在CVPR会议上提出YOLO(you only look once)目标检测算法,同年,Liu等[7]在ECCV会议上提出了SSD目标检测算法。YOLO与SSD将预测边框的任务变成回归问题,在检测速度方面有明显提升,基本满足实时要求。深度学习目标检测算法已在车型识别领域有一定研究,文献[8]将Faster-RCNN分别与ZF,VGG-16以及ResNet-101 3种卷积神经网络相融合,可以针对不同的数据集选用最佳网络进行车型识别。由于该方法对候选框进行了预分类,虽然车型识别的精度有所提高,但是检测速度较慢。文献[9]融合循环神经网络和卷积神经网络嵌入二级框架,增强了内部特征信息的完整性,在对视频监控图像中车型识别的精确性上表现良好,但是其存在模型过大、运行时内存占用高的问题。
SSD目标检测算法在检测精度和速度方面综合性能更好,但仍存在参数多导致模型臃肿的缺点[10]。结合上述研究,笔者提出使用改进的深度可分离卷积作为SSD算法基础网络,对特征提取过程进行简化,重新设计区域候选框,减少了模型参数量,实现对车辆类型准确的识别,并且提升了模型的检测速度。
1 经典SSD模型
经典SSD深度模型用VGG16分类网络作为特征提取器,并将VGG16后两层全连接层FC6,FC7改为卷积层,随后,SSD在一系列不同尺度的卷积层上做特征提取,其尺度分别为38×38,19×19,10×10,5×5,3×3和1×1。在融合不同尺度的特征信息后,对目标的位置和类别进行预测。
目标检测损失函数由位置损失和分类损失加权求和获得,如式(1)所示。
(1)
式中:N是匹配正样本的总量;x表示默认框与真实框的匹配结果,x=0表示匹配失败,x=1表示匹配成功;c是softmax函数分别对任务中每一类别的置信度;l,g分别是预测框和真实框;α是位置损失的权重。
2 改进的SSD车型识别模型设计
经典SSD算法的模型参数运算繁多,运行时占用内存大,为了在有限的计算资源平台上完成图像识别任务并做出及时的反应,对SSD算法进行“减重”势在必行。
笔者提出改进的深度可分离卷积网络作为SSD前端特征提取的基础网络,避免卷积运算过程所带来的过大消耗,降低算法运算复杂度,适应未来实时识别车型的应用需求。
2.1 深度可分离卷积
深度可分离卷积(depthwise separable convolution,DSC)计算如式(2)所示。
(2)
式中:G为输出特征图;K为卷积核;F为输入特征图;i,j为特征图像素位置;k,l为输出特征图分辨率;m为通道数。
深度可分离卷积把卷积分为深度卷积DW(depthwise convolution)和点卷积PW(pointwise convolution)2个阶段。DW是深度可分离卷积的滤波阶段,每个通道对应卷积核进行卷积操作;PW是深度可分离卷积的组合阶段,整合多个特征图信息,串联输出。
模型训练中,输入M通道大小为DF×DF的图像,经过DK×DK大小的卷积核进行卷积操作后,输出大小为DI×DI的N通道特征图。
对于一般卷积来说,滤波器大小为DK×DK,输入大小为DF×DF的M通道图像,参数运算量为DF×DF×DK×DK×M×N。而深度可分离卷积中特征提取只用了一个大小为DK×DK×1卷积核,运算量为DF×DF×M×DK×DK,组合阶段用了N个点卷积,运算量为DF×DF×M×N,因此总计算量为DF×DF×M×N+DF×DF×M×DK×DK。
深度可分离卷积与传统卷积参数运算量对比计算如式(3)所示。
(3)
式中深度可分离卷积使用3×3的卷积核,即DK取值为3。深度可分离卷积在准确率较小下降的情况下运算量减少1/8~1/9[11]。在对模型轻量化过程中,引入了宽度参数α,压缩输入输出通道分别为αM,αN,α<1,计算量为DF×DF×αM×αN+DF×DF×αM×DK×DK。
2.2 反残差模块
宽度参数通过压缩通道数进一步减少模型参数量,但是也造成了特征压缩的问题。而修正线性单元(ReLU)对于负输入,全部输出为零,会导致更多的特征信息丢失,深度卷积DW无法改变输入通道,这种情况下,特征提取效果不理想,会导致目标检测准确率降低。
研究在DW之前引入反残差(inverted residuals,IR)[12]模块,实现过程如图1所示。

图1 反残差模块Fig. 1 Inverted residuals module
图1中,输入为h×w的k维特征图,将ReLU改为ReLU6以限制输出范围,输出h/s×w/s的k′维特征图。s是步长,t为扩张系数。首先用一个大小为1×1的扩展核把输入的低维特征图扩展到高维,在高维空间进行深度卷积,最后使用点卷积将特征提取结果降维映射到低维空间并用线性激活函数(linear)进行输出。对通道数扩增之后再收缩,提高了模型特征提取的能力,有效防止由于通道数较小时因非线性激活导致特征信息丢失的情况,可以提高目标检测准确率。结合反残差模块的深度可分离卷积SSD结构如图2所示。
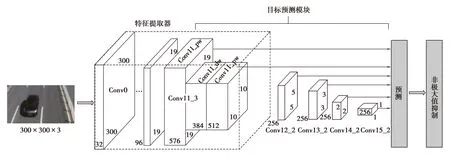
图2 改进SSD模型结构图Fig. 2 The model structure of improved SSD
图2中,特征提取部分除第1层之外全部为结合反残差模块的深度可分离卷积,扩张系数t为6,并且在conv1,conv3,conv6,conv11中采用步长s为2的卷积,在conv2,conv4,conv5,conv7,conv8,conv9,conv10中步长s为1,进行残差信息传递。模型选取包括特征提取器后两层在内的6种不同尺度的特征图,其尺度分别为19×19,10×10,5×5,3×3,2×2和1×1,并计算目标的分类信息和位置信息。
2.3 区域候选框重构
图3为SSD多尺度特征图及区域候选框示意图,网络的输入为训练集所包含图像及手工标定的目标的真实标签框,如图(a)所示。在特征图中的每一单位点处,预测多个具有不同尺度、不同宽高比的候选框,如图(b)(c)所示,对候选框与真实框做匹配来进行位置损失的计算。区域候选框与目标真实位置交并比大小是区分正负样本的条件,训练效果是由区域候选框决定的。

图3 多尺度特征图及区域候选框示意图Fig. 3 Sketch of multi-scale feature and regional candidate frame
区域候选框参数计算如式(4)所示。
(4)
式中:Sk是第k个特征图的minsize参数;smin是设计好的最小归一化尺寸,取值为0.2;smax为设计好的最大归一化尺寸,取值为0.9;m是特征图的总数。

区域候选框与目标真实位置框的匹配度是模型性能重要的指标之一,而不同的区域候选框与真实框的匹配操作是十分复杂的。根据车辆的刚体特性,且图像采集于固定角度,对区域候选框重新设计,利用先验知识判定车辆宽高比在特定范围,针对不同采样角度、公路交通状况可统分为ar>1或ar<1的不同类,在参数设定时删除不需要的候选框,通过减少候选框匹配运算,提升SSD深度学习网络模型速度。实验车辆图片为路面车辆正面俯视图,宽高比参数ar<1,将区域候选框取值范围选定为{1,1/2,1/3}。
SSD采用6个特征层来生成不同尺寸大小的候选框,假设特征图大小为n×n,在每单元点设置k个候选框,则单层特征图生成候选框的个数为n×n×k。笔者在SSD中使用反残差模块的深度可分离卷积进行特征提取,并且删除了宽高比例为2和3的框。由表1可以看出,经典SSD选取6个特征图的k值分别为4,6,6,6,4和4,计算可以得到8 732个候选框;改进后的SSD选取6个特征图的k值均为4,计算可以得到候选框2 000个,与原SSD的区域候选框生成总数相比减少了约3/4。

表1 区域候选框重构前后总数对比
3 实验分析
3.1 训练数据及平台
使用北京理工大学建立的BIT-Vehicle Dataset[13-14]数据集来验证改进算法有效性,数据集中的所有车辆都被分为6类:Bus、Microbus,、Minivan、Sedan、SUV和Truck,每种车型分别有558,883,476,5 922,1 392和822辆。图像分辨率为1 920×1 080和1 600×1 200。数据集按比例6∶ 2∶ 2分为训练集、验证集和测试集。
实验采用的软件和硬件设备:Linux系统、GPU采用NVIDIA RTX 2060、Tensorflow、AMD Ryzen 52600型号的CPU,CUDA9.0加cuDNN7版本深度学习加速库,python版本为3.6.5。算法设置每批次训练样本为32张,初始学习率设置为0.001,迭代80 000步后设置为0.000 1,在Loss变化差值基本不变,大概150 000步停止模型训练,得到车型识别模型。
3.2 实验结果及分析
实验选用imageNet[15]数据集上预训练的模型来初始化模型参数,可以加速模型收敛,获得更好的识别效果。笔者使用不同基础网络、不同区域候选框设计方法的目标检测算法进行消融实验,对比模型性能,验证改进算法有效性,结果如表2所示。

表2 不同实验算法模型性能对比
对表2分析可知,Faster R-CNN分步目标检测算法精度较高,但其模型参数量大,平均检测时间为0.635 s/帧,不满足实时性要求。表中加粗部分为笔者提出的改进深度可分离卷积的SSD车型识别方法所得结果,其识别精度达到96.12%,相较于原SSD算法有显著提升,参数量减少472 MB,平均检测时间由0.119 s/帧下降到0.078 s/帧。与区域候选框重构前的模型相比,在识别精度仅下降0.21%的前提下,经过区域候选框重构后的模型参数量减少21.14%,平均检测时间减少14.29%,综合性能最优,可以实现对车型的实时识别。
图4为经典SSD和改进SSD的车型识别效果结果对比图,其中,第1、第3列为经典SSD车型识别结果,第2、第4列为改进SSD车型识别结果。通过识别结果对比可以看出,算法改进使得模型在边框的回归有更好的效果,准确率相较于经典深度模型也有一定的提升。
4 结 语
针对目前车型实时识别能力不足的问题,笔者提出了基于改进深度可分离卷积的SSD模型对道路车辆类型进行识别。该算法大幅减少了模型参数量,识别精度达到96.12%,同时平均检测时间达到0.078 s/帧,各项指标均优于原SSD模型,满足车型实时识别要求,为交通场景中高速口缴费、车辆追踪及套牌检查等应用提供了参考。未来的研究方向是增加复杂场景道路图像数据,并对文中模型进行网络微调,提高模型在不同场景下车型识别能力。
