融合分类和情境偏好的矩阵分解电影推荐算法
2021-06-21王文铃虞慧群范贵生
王文铃, 虞慧群, 范贵生,2
(1. 华东理工大学计算机科学与工程系,上海 200237;2. 上海市计算机软件测评重点实验室,上海 201112)
近年来互联网技术的飞速发展,带动了视频网站的兴起,不论是观影人数还是人们投入到电影产业中的消费,都在不断地增长。目前大部分网站的电影推荐都是基于用户观看电影的历史纪录,通过历史纪录来分析用户的观影偏好来进行推荐。然而,用户对电影的喜好也受到情境信息的影响,如年龄、当地天气、外界环境等。在电影推荐领域,将情境信息融入到传统的推荐算法中,将会提供更加精确的推荐结果,算法也会更加灵活。
国内外很多学者对情境感知推荐进行了深入的研究。Baltrunas等[1]将情境信息融入推荐系统,提出了CAMF(Context-Aware Matrix Factorization)推荐模型,在传统的矩阵分解中融入了情境偏置。兰艳等[2]提出了一种改进的时间加权协同过滤算法。陈星等[3]尝试将情境感知应用到智能家居中。CAKIR等将协同过滤与关联性规则挖掘应用在电子商务中[4]。以上对情境感知推荐系统的研究都取得了一定的成果,但也存在着不同情境信息对同一个项目的影响权重没有分开考虑的问题。同时,通过矩阵分解算法得到的推荐结果也存在着可解释性差的问题。
为了解决上述问题,本文提出了一种混合推荐算法CAMF-CM(Context-Aware Matrix Factorization-Classification Model)。将用户和项目的情境信息数据输入到决策树模型中,以此来获得用户特征信息和电影特征信息,得到用户在给定情境信息下的观影倾向,再将其与改进了情境权重的CAMF算法结合,进一步加强推荐的准确性。因为矩阵分解算法具有良好的扩展性,并且可以一定程度上缓解数据稀疏问题,所以选取矩阵分解算法作为基础[5]。在LDOS-COMODA数据集上进行了相关的数据预处理,然后以平均绝对误差(MAE)为评价指标并设计了相关实验。实验结果表明,本文提出的CAMFCM算法能够有效地降低预测误差,改善推荐结果的质量。
1 情境感知推荐算法
1.1 基本矩阵分解算法
矩阵分解算法在推荐领域已有广泛的应用,其思想是将数据集中的用户评分矩阵R∈Rn×m分解成用户隐性特征矩阵P∈Rn×f和项目隐性特征矩阵Q∈Rm×f,且满足

将用户u的特征向量用pu表示,评分项目i的特征向量用qi表示,那么使用矩阵分解算法计算得出的向用户u推荐物品i的推荐分数可以表示为

为了找到式(2)中的特征向量pu、qi,也为了衡量矩阵分解的好坏,需要规定一个损失函数如下:
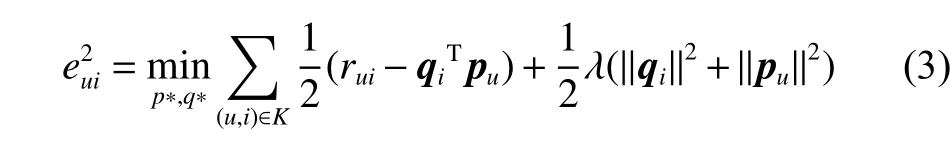
其中:K为已有评分记录的(u,i)对集合;rui为用户u对项目i的真实评分; λ (‖qi‖2+‖pu‖2) 为防止过拟合的正则化项; λ 为正则化系数。损失函数是为了计算平方项损失,需要达到的目标是使每一个元素(非缺失值)的e(i,j)的总和最小[6]。
1.2 Baseline预测算法
情境感知是一种能将用户和项目的情境信息进行综合考虑的技术[7]。传统的协同过滤算法需要计算用户和项目的相似度[8],在Baseline算法中,需要引入用户的全局偏置,记为bu。同理,也要引入项目的全局偏置,记为bi。Baseline算法的评分预测公式如下:

其中:μ为该项目评分的平均值。为了计算bi、bu,需要引入目标函数,计算公式如下:
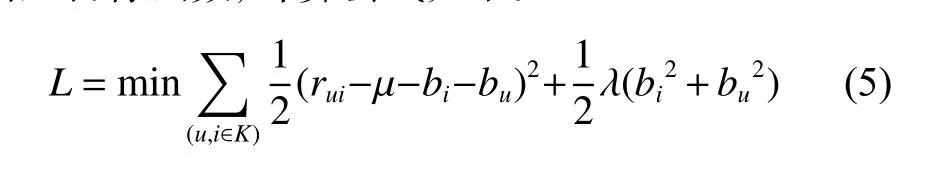
1.3 CAMF算法
CAMF预测模型[1]中设定每个情境信息对项目的影响权重相同。该预测模型中引入了情境偏置的概念,记为bc,作为情境因素对某个项目的影响。
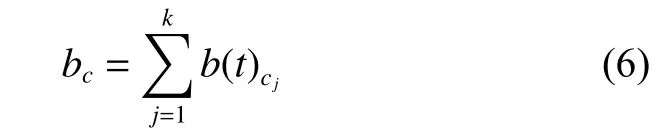
其中:t为项目所属类别;cj为情境要素,共包含k个情景要素;b(t)cj表示情境要素cj对t类别影视项目的影响。将情境偏置与传统的矩阵分解算法结合,得到融合了情境偏置的评分预测公式如下:
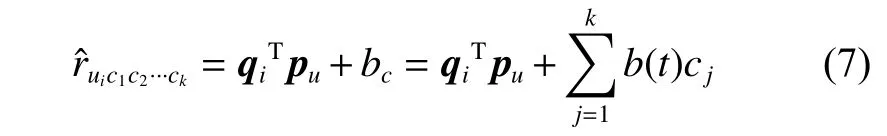
其 中:rˆuic1c2···ck表示用 户u在 情 境信 息c1,c2,···,ck下对影视项目i的预测评分。将该融入情境偏置的评分预测融入矩阵分解中,得到融合了情境信息的目标函数:
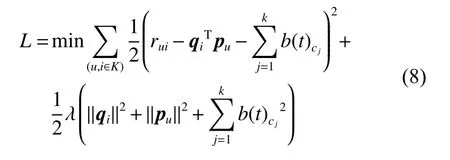
2 融入分类模型的混合推荐算法
2.1 决策树分类模型
推荐系统可以识别可能引起用户兴趣的项目,或预测用户对电影等项目的评分[9],将分类算法与其结合,可以进一步提高推荐的准确率。目前常用的分类算法有决策树算法、贝叶斯算法[10]、k-近邻算法和支持向量机算法,本文采用决策树算法。本文将LDOS-COMODA数据集中的日期、地点、情绪、状态、时间、天气等情境信息作为特征集,将电影的风格、年代、类型作为训练标签,通过决策树模型进行训练,得到基于情境数据下的用户和项目的隐性特征向量,以及用户在特定情境下的观影倾向。
2.2 改进的CAMF算法
情境信息是用来描述用户所处环境的如位置、时间、应用系统等信息[11]。CAMF算法设定每个情境信息对项目的影响权重相同,但每个情境信息对用户的影响权重应该不同,有些用户更容易受到特定情境信息的影响,例如天气和观影日期,对其他情境信息则并不太在意。因此,需要对情境信息设定各自的权重。本文从LDOS-COMODA数据集中选取了12个情境信息进行实验,对每个情境信息设定其权重gj,则修改后的情境偏置公式为
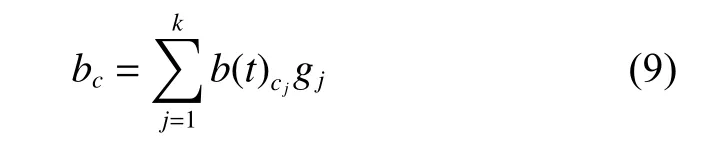
特定情境信息的权重值gj通过实验确定,信息增益作为衡量信息对决策的影响性的重要方法,将其应用在情境权重的计算中,对数据集中的情境信息分别计算其信息增益,结果取平均值,计算得出的不同情境信息的情境权重如表1所示。
为了进一步提高推荐的灵活性,将Baseline算法中用户和项目的全局偏置bi、bu引入改进后的CAMF算法的评分预测函数中,加入全局偏置后的预测公式如下:
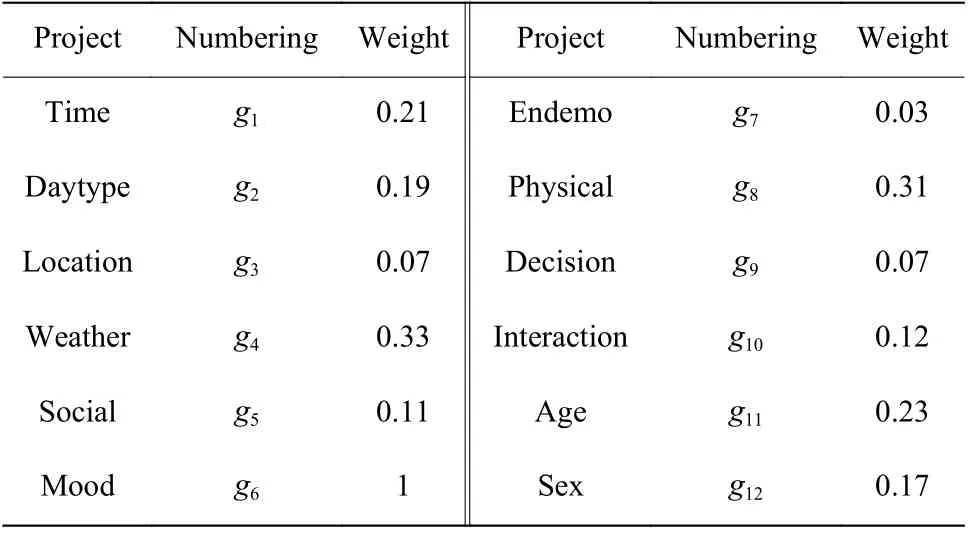
表1 情境权重描述Table 1 Description of context weights

2.3 CAMF-CM混合推荐算法
CAMF-CM是结合了改进的CAMF算法和决策树算法的混合推荐算法。其算法流程如图1所示。
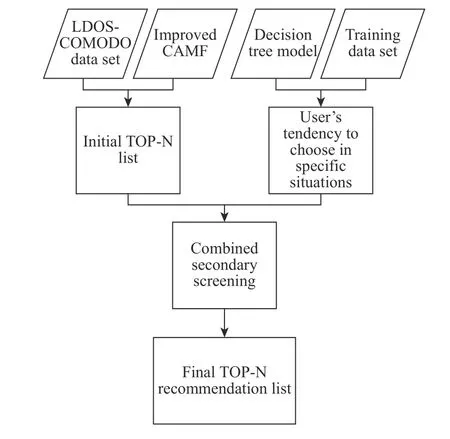
图1 CAMF-CM推荐模型算法流程Fig. 1 Flow chart of CAMF-CM recommendation model algorithm
首先,使用改进后的CAMF算法得到初始的推荐列表,该列表为包含了所有电影类型的推荐列表。情境感知推荐的问题之一是如何获取用户的情境信息[12],因为初始推荐列表中可能包含了用户在给定情境下并不感兴趣的电影类型。因而需要使用决策树模型对数据集进行训练,得出用户在特定情境下的观影倾向后对初始推荐列表进行筛选。CAMFCM混合推荐算法的计算流程如下:
算法1 混合推荐算法CAMF-CM
输入:用户电影评级矩阵R,用户特征矩阵P,电影特征矩阵Q,用户数量M,电影数量N,用户情境因素数量F1,电影特征标签数量F2,包含了用户对电影实际评分Ri的评分矩阵F3。
输出:MAE
计算流程:
开始:
(1)依据Bsaeline算法,计算用户全局偏置bi,电影项目全局偏置bu。
(2)计算用户特征向量pu,电影特征的隐藏向量qi。
(3)计算情境偏置,使用改进的CAMF算法,根据公式(10)计算评估分数Pi,并生成TOP-N推荐列表。
(4)使用决策树算法对情境数据集LDOSCOMODA进行特征标签训练,得到用户在给定情境下的电影偏好。
(5)根据第3步得到的TOP-N推荐结果,集合决策树模型得到的用户在给定情境下的选择倾向,对TOP-N列表进行再次筛选,得到最终TOP-N推荐列表。
(6)算法效率验证。采用10折交叉验证法,分别计算协同过滤算法基本矩阵分解算法、Baseline预测算法和CAMF-CM混合算法的MAE并进行比较,得到最终结果。
结束
CAMF-CM混合推荐算法将改进后的CAMF算法所生成的初始推荐列表,结合分类模型训练得出的用户在特定情境下的观影倾向进行二次筛选,得到最终的推荐列表。目前情境感知推荐系统的应用领域日益广泛,但在情境要素的选择问题、情境信息的兼容方法问题等方面还需进一步研究[13]。
3 实验结果与分析
3.1 数据集和数据预处理
本文所使用的数据集为LDOS-COMODA电影数据集,该数据集除了包含用户对电影的评分信息外也包含了情境信息,详细数据分布如表2所示。

表2 LDOS-COMODA电影评分数据集描述Table 2 LDOS-COMODA movie rating data set description
目前被广泛使用的预测模型算法有决策树和随机森林,该两种预测模型往往能够得到较好的预测效果[14],本文选用决策树模型。从LDOS-COMODA数 据 集 中 选 取 包 含Time、Daytype、Location、Weather、Social、Mood、Endemo、Physical、Decision、Interaction,Age和Sex这12个情境信息作为参数进行实验。先对数据进行预处理,设定情境信息的值均为正整数,若有缺失值,用该项情境信息已有数据中的众数进行填充。处理后的情境数据集内容描述如表3所示。

表3 情境要素描述Table 3 Description of context elements
实验环境:Windows 10操作系统,16 GB内存,Intel(R) Core(TM) i7-8700k CPU 3.70 GHz,编程语言采用Python3。
3.2 评价指标
情境感知推荐系统可以通过用户和项目的情境信息进行推荐[15],平均绝对误差(Mean Absolute Error,MAE)和均方根误差(Root Mean Squared Error,RMSE)是RS (Recommendation System)领域常用的预测准确度的评估标准。本文采用MAE作为算法的评价指标,它表示预测值和观测值之间绝对误差的平均值,计算公式如下:
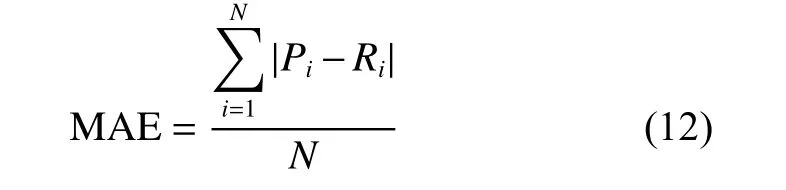
其中:N为测试集大小;Pi为预测评分;Ri为实际评分。MAE值越小,准确度越高,推荐质量越高。
3.3 实验结果与分析
为了得到精确的结果,采用10折交叉验证的方法进行实验。实验过程中,将数据集分为10份,根据不同的算法进行不同的配置。采用协同过滤算法进行实验时,取9份作为训练集,1份作为测试集。采用基本矩阵分解算法、Baseline预测算法和CAMFCM混合推荐算法进行实验时,取8份作为训练集,1份作为测试集,1份作为验证集。每次实验结束后将样本进行轮换,使用MAE作为评价指标。
3.3.1 基于用户的协同过滤算法 对于协同过滤算法,将近邻数量k设置为5 ~ 50,取间隔为5,观察MAE的变化曲线,如图2所示。由图2可知,MAE在0.96 ~ 0.98间波动,当k=30时,MAE取得极小值,约为0.959,此时推荐效果最好。
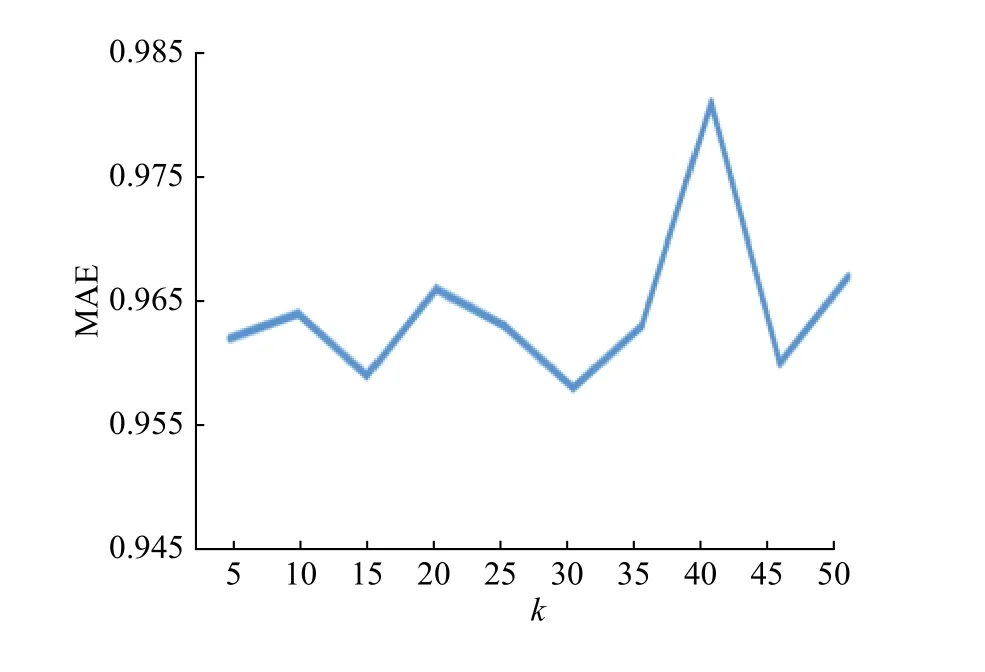
图2 基于用户的协同过滤算法的MAEFig. 2 MAE of user-based collaborative filtering algorithm
3.3.2 基本矩阵分解算法 对于基本矩阵分解算法,设定正则化系数λ和学习率 γ 的取值为0.01 ~ 0.05,取0.01作为间隔进行实验。迭代数设置为100次,向量维度为10,实验结果如图3所示。可见当λ=0.03、γ=0.01时,MAE取得极小值,约为1.95,此时推荐效果最好。
3.3.3 Baseline预测算法 对于Baseline预测算法,同样设定正则化系数λ和学习率 γ 的取值为0.01 ~0.05,取0.01作为间隔进行实验。迭代数设置为100次,向量维度为10,实验结果如图4所示。由图4可见,当λ=0.03且 γ =0.04 时,MAE取得极小值,约为0.806,此时推荐效果最好。
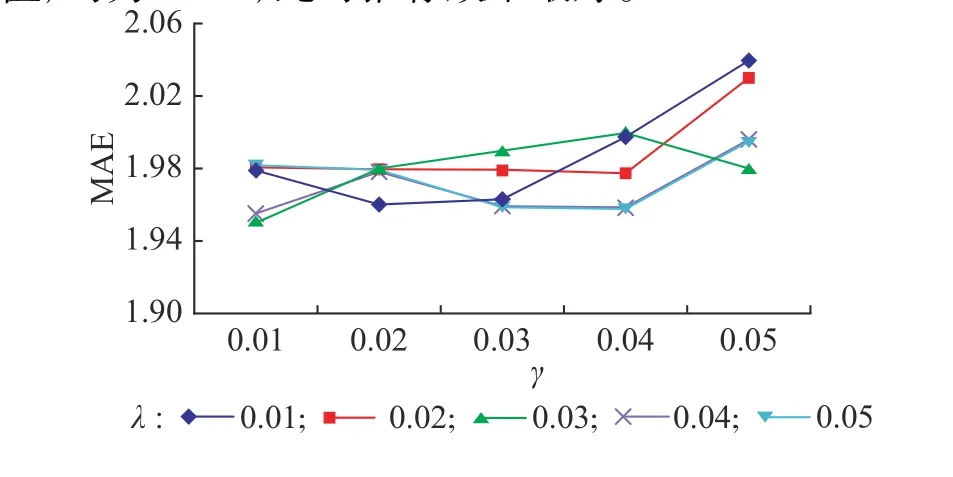
图3 基本矩阵分解算法的MAEFig. 3 MAE of basic matrix factorization algorithm
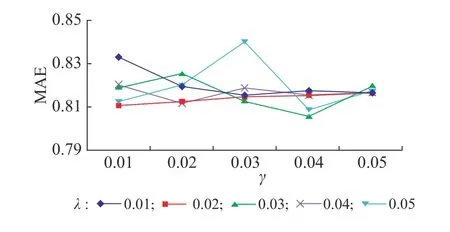
图4 Baseline预测算法的MAEFig. 4 MAE of baseline prediction algorithm
3.3.4 CAMF-CM推荐算法 在CAMF-CM混合算法中,分类模型采用决策树模型进行训练,改进的CAMF算法中设定正则化系数λ和学习率 γ 的取值同样为0.01~0.05,取0.01作为间隔进行实验。迭代数设置为100次,向量维度为10,CAMF-CM混合模型在λ取0.04且 γ =0.01 时,MAE最小,约为0.747,实验结果如图5所示。
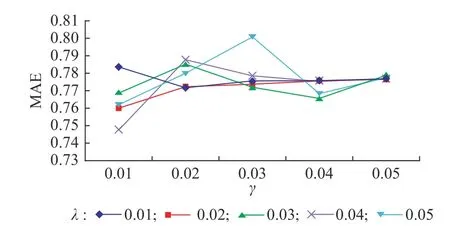
图5 CAMF-CM算法的MAEFig. 5 MAE of CAMF-CM algorithm
各种算法的MAE对比结果如图6所示。与其他3种算法相比,CAMF-CM混合算法的MAE最小,推荐结果更加精确。
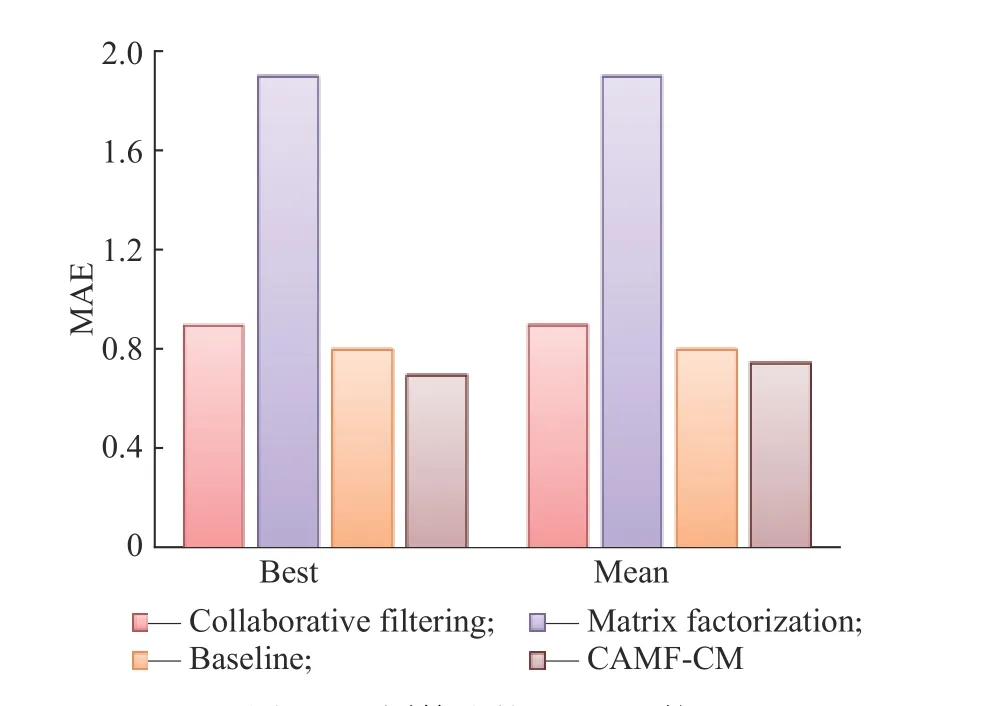
图6 不同算法的MAE比较Fig. 6 MAE of different algorithms
4 结束语
推荐系统如果能够将情境信息纳入考虑,就能提高推荐的准确率。本文提出了一种融合了矩阵分解算法和分类模型的混合推荐算法,实验结果表明,该混合算法相较于基于用户的协同过滤算法、基本矩阵分解算法和Baseline预测算法有着更高的准确率。本文提出的混合推荐算法还有进一步优化的空间,算法所使用的分类模型只使用了电影的类别、年份、总评分等标签信息,并且也没有对用户对电影评分的合理性进行分析。在之后的研究中,可以对用户对电影的评分进行预处理,去掉数据集中不合理的评分,并且在矩阵分解算法的目标函数中,对每一个情境信息的合理权重进行进一步的分析,使情境权重能够根据用户自身评分特征进行变化。此外,还可以在算法上进行一些其他的优化,例如添加评分用户个人的信用权重,对同一电影在不同时期的评分进行分析处理等。
