基于点对相似度的深度非松弛哈希算法
2021-06-20汪海龙肖创柏
汪海龙 禹 晶 肖创柏
近年来,随着计算机软件和硬件技术的发展,图像、视频等数据的维度和数量不断增加,为了解决海量的高维数据的存储和检索问题,研究学者提出了将高维数据投影到低维二值空间的哈希学习方法.哈希学习方法是一种在保持图像或视频等高维数据间相似性的条件下,通过哈希函数或函数簇将高维空间的数据投影到低维汉明空间的二值编码的机器学习方法.通过哈希学习方法对数据建立索引,提高图像等高维数据的检索效率,并节省存储空间.现有的哈希方法大致可以分为两类:数据独立的方法和数据依赖的方法[1].
数据独立的方法使用随机投影来构造哈希函数.局部敏感哈希(Locality sensitive hashing,LSH)算法[2-4]于1998 年由Indyk 等提出,该算法在原始空间中使用随机线性投影将距离近的数据投影到相似的二值编码中.该算法的哈希函数简单易实现,计算速度快,但准确率不高.核化局部敏感哈希(Kernelized locality-sensitive hashing,KLSH)算法[5]对LSH 算法提出了改进,KLSH 在核空间中随机构造哈希函数,不需要考虑原始空间的数据分布,可以选择任意核函数作为相似性度量函数.但由于核函数的引入,很大程度上增加了计算复杂度.数据独立的方法虽然简单易实现,但是由于这类方法不使用训练数据训练模型,所以需要很长的哈希码才能达到较高的准确率.数据依赖的方法使用训练数据来学习将高维数据投影为低维二值编码的哈希函数.如同一般的机器学习方法,数据依赖的方法可以分为非监督型方法和监督型方法.
非监督型哈希学习方法是在数据没有类别信息或不利用类别信息情况下,根据某种距离度量检索最近邻数据的方法.谱哈希(Spectral hashing,SH)算法[6]是一种典型的非监督哈希算法,其采用主成分分析(Principal component analysis,PCA)算法[7]获取图像数据的各个主成分方向,并计算所有的解析特征函数(Analytical eigenfunction),然后使用符号函数将这些解析特征函数的值量化为二值编码.由于在实际情况中很难同时满足谱哈希的两个约束条件,即假设从多维均匀分布的空间中采样数据以及不同维度上的哈希编码之间相互独立,因此谱哈希的使用受到一定限制.迭代量化哈希(Iterative quantization,ITQ)算法[8]将数据投影到中心为零(Zero-centered)的二值超立方体(Binary hypercube)的顶点,使得投影后的数据与原数据之间的量化误差能够最小化,并使用一种简单有效的交替最小化(Alternating minimization)方法求解目标函数.与SH 算法相比,ITQ 算法不仅应用范围更广,而且经实验验证ITQ 算法的检索效果更好.
监督型哈希学习方法是指将图像或其他高维数据的类别标签用于估计二值编码模型的输出,在迭代过程中不断利用图像的标签信息计算实际输出与预期输出之间的误差反馈给模型,不断调整模型参数的方法.由于监督型哈希方法利用了数据的标签信息,一般情况,监督型哈希方法的效果比非监督性哈希方法的效果好.2011 年,Norouzi 等提出了最小损失哈希(Minimal loss hashing,MLH)算法[9],这是一种典型的监督型哈希学习算法,该算法通过结构化支撑向量机(Structural support vector machine,Structural SVM)建立损失函数,由于损失函数不连续且非凸,难以直接求解,该算法通过构造并最小化损失函数的上界来求解损失函数.基于核的监督哈希(Kernel-based supervised hashing,KSH)算法[10]采用核的形式来构造哈希函数,使得其泛化可以处理非线性可分的问题,并且,不同于MLH 算法的是,KSH 算法不直接通过最小化哈希码之间的汉明距离来学习哈希函数,而是通过最小化哈希码的内积,使问题变得更简单,更容易求解.2015 年,Shen 等[11]提出了监督型离散哈希(Supervised discrete hashing,SDH)算法,该算法使用Lagrange 乘子法将离散约束问题松弛为凸优化问题,在求解阶段使用循环坐标下降法(Cyclic coordinate descent,DCC)求解目标函数,即每次迭代固定其他的哈希位,只将一个哈希位作为变量求解,SDH 算法在保持准确率的同时,提高了算法的效率.
上述传统的哈希学习方法在提取图像特征时采用手工设计特征,例如梯度方向直方图(Histogram of oriented gradient,HOG)、尺度不变特征变换(Scale invariant feature transform,SIFT)等,不同场景的图像使用相同的手工设计特征在一定程度上影响了哈希学习算法的性能,单一的特征导致检索准确率不高.近年来,卷积神经网络(Convolutional neural network,CNN)[12-13]在计算机视觉领域成为主要的特征学习工具,在图像分类[14]、目标检测[15-16]等方向得到广泛应用.目前许多学者也尝试将CNN 用于哈希学习方法中,陆续出现了一些深度哈希学习方法.
2014 年,Xia 等[17]提出了卷积神经网络哈希(Convolutional neural network hashing,CNNH)算法,该算法利用深层框架来学习图像的特征,然后以此特征学习哈希函数.这是一种两阶段哈希学习算法,第1 阶段通过对相似度矩阵进行分解,预生成样本的二值编码;第2 阶段将样本数据输入CNN,使用卷积层提取图像特征,通过最小化网络输出值与第1 阶段预编码之间的误差,获得样本的哈希码.CNNH 相对于非深度哈希学习算法在准确率上有明显的提高,然而也存在明显的问题,第1 阶段中相似度矩阵分解是一个非凸优化问题,分解过程中需要大量的松弛方法,导致准确率会受到很大的影响;第2 阶段仅利用了CNN 自动提取图像特征,没有参与第1 阶段的计算.基于监督型深度哈希的快速图像检索(Deep supervised hashing for fast image retrieval,DSH)算法[18]利用成对的图像和图像的标签作为网络的输入进行训练,并联合使用对比损失函数(Contrastive loss)与哈希码的ℓ1范数正则项作为网络的损失函数,以此约束哈希码,使输出在汉明空间的哈希码更加多样化,避免了两阶段哈希算法中第1 阶段不能利用CNN 网络,以及使用sigmoid 函数导致网络收敛速度过慢的问题.2016年,Li 等[19]提出了基于标签对的监督型深度哈希特征学习(Feature learning based deep supervised hashing with pairwise labels,DPSH)算法,该算法通过图像的类别标签构造图像的标签对矩阵,根据图像的标签对构建交叉熵损失函数,以此衡量深度卷积神经网络训练的损失,使用基于Lagrange 乘子法的松弛优化方法,对约束条件进行松弛,去掉符号函数的约束条件,解决离散约束问题.但是由于该算法使用Lagrange 乘子,某些哈希位会被过度松弛,导致相似点对之间的语义信息保留不完整.连续深度哈希学习(Deep learning to hash by continuation,HashNet)算法[20]也使用图像的标签对构建目标损失函数,该算法在目标函数构造过程中引入加权似然函数,有效地解决了相似点对数据不平衡问题,同时在网络的输出端使用尺度双曲正切函数(Scaled tanh function)对网络输出进行阈值化,并在迭代过程中,不断增大尺度系数,使其逼近符号函数的功能.从实验结果来看,与传统的哈希学习方法相比,监督型深度哈希学习方法在准确率方面明显胜过传统的方法.
本文提出了一种基于点对相似度的深度非松弛哈希(Deep non-relaxing hashing based on point pair similarity,DNRH)算法,该算法使用交叉熵保持相似点对之间的语义相似性,在卷积神经网络的输出端使用一种软阈值函数阈值化网络输出得到准哈希码,并使用ℓ1范数约束输出端的准哈希码,使得准哈希码的绝对值逼近1,避免了Lagrange 乘子的松弛求解对模型准确率的影响.本文利用卷积神经网络提取图像的特征表示并学习哈希函数生成哈希码,这样就避免了相似度矩阵分解的不准确对后续量化过程的影响.综上所述,本文的主要贡献归纳如下:
1)在损失函数中引入ℓ1范数约束输出端的准哈希码,通过正则项约束准哈希码,使其各哈希位的绝对值逼近1.
2)为了减小量化误差,在CNN 的输出端使用软阈值函数,使输出的准哈希码非线性地接近-1或1.在模型外部使用符号函数sgn(·),将准哈希码量化为二值哈希码.
本文后续结构组织如下:第1 节介绍本文算法的背景,第2 节描述本文算法的模型、求解以及网络结构,第3 节通过实验验证本文算法的性能,第4 节为全文结论.
1 背景
1.1 问题描述
在监督型哈希学习中,每一个数据样本都有一个标签,样本的标签矩阵为其中,yi∈{0,1}C,C 为样本的总类别数.每一个样本数据xi对应一个yi,当样本xi属于第c 类时,yi的第c 位为1,其他位均为0.通过样本的标签矩阵Y,可以定义样本之间的相似度矩阵S ∈{0,1}n×n,对于任意两个样本xi与xj,若xi与xj属于同一类别,则sij=1,否则,sij=0.
1.2 交叉熵损失函数
对于任意两个长度相等的哈希码bi和bj,将这两个哈希码的相似度φij用它们的内积定义为

内积越大,相似度越大,使用sigmoid 函数对相似度φij进行非线性阈值化,将其范围规范化到区间(0,1),可得

基于哈希码相似度的度量,Li 等[19]和Zhang等[21]利用交叉熵损失函数保持点对之间的相似度,图像点对的哈希码与相似度之间的似然p(sij|B)定义为
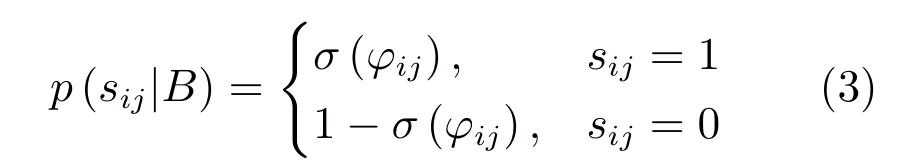
式中,sij表示样本对之间的相似度,B 表示样本数据对应的哈希码.由该似然函数表明,当哈希码bi与bj越相似,即σ(φij)越大,对应的似然函数p(sij|B)就越大;当哈希码bi与bj越不相似,即1-σ(φij)越大,对应的似然函数p(sij|B)仍越大.极大似然估计可表示为
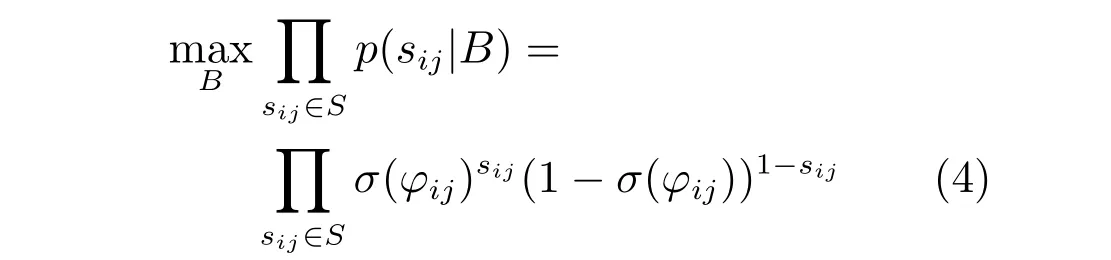
对式(4)中极大似然估计的目标函数取负对数即是交叉熵损失函数,可表示为

于是将极大似然估计转换为最小化交叉熵损失函数,建立如下的约束最优化问题:

式中,W 表示全连接层的神经元参数,W 表示偏移量,θ 表示网络卷积层的参数集合,bi表示二值哈希码,bi中每一位量化到离散值-1 或1,φ(·)表示网络提取的图像特征,sgn(·)为符号函数,若x >0,则sgn(·)=1;否则sgn(·)=-1.
由于符号函数不连续,上述问题是一个离散的最优化问题,很难求解.为了求解上述问题,Li 等[19]使用基于Lagrange 乘子法的松弛优化方法,对约束条件进行松弛,简化约束条件中符号函数的离散约束,使其成为凸优化问题,其目标函数为
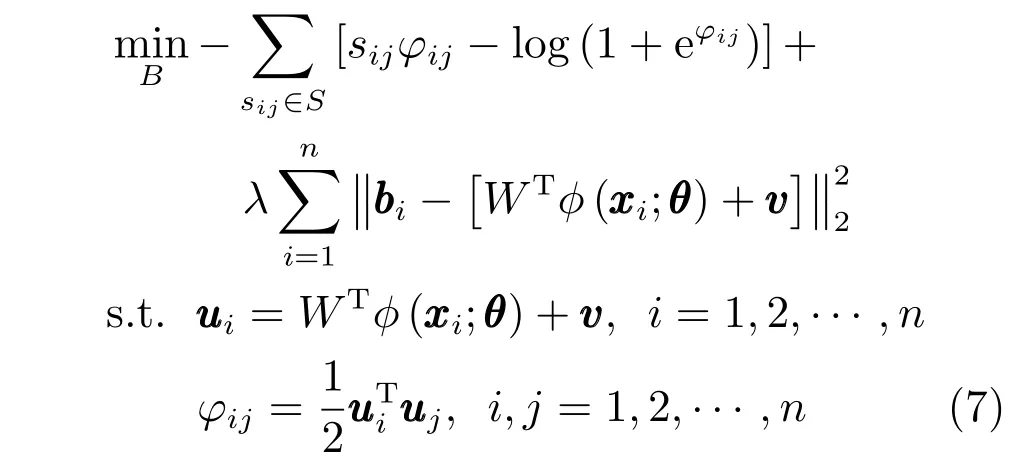
其中,ui表示网络的直接输出结果.该方法在每一次迭代过程中使用符号函数量化生成bi,这样会出现大量不可忽略的损失,导致某些特征对应哈希位的约束变弱,使得计算结果不准确,这也是使用Lagrange 乘子法对约束条件松弛导致某些哈希码过度松弛的问题.
2 深度非松弛哈希算法
2.1 模型的建立
本文利用深度卷积神经网络训练样本数据,利用交叉熵保持样本对之间的语义相似性,为了减少网络输出的准哈希码的量化误差,本文使用Liu等[18]提出的ℓ1范数对网络输出的准哈希码的分布进行约束
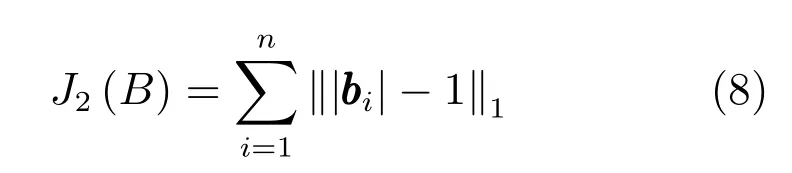
该正则项旨在使准哈希码bi的各个哈希位逼近两个离散值-1 或1,即bi中每一位的绝对值越接近1时,损失越小.
在迭代过程中直接使用网络的输出作为准哈希码有很大概率过度偏离-1 或1,这样将增大式(8)中J2(B)的损失值,尽管符号函数能够很好地对其进行量化,然而符号函数不可导.相对于符号函数的离散编码,双曲正切函数能够使准哈希码的各哈希位非线性地接近-1 或1,且具有连续无限可导的良好性质,其形式为

Cao 等[20]使用尺度双曲正切函数tanh(βx)阈值化网络输出值为准哈希码,其中β 为尺度系数,控制函数值逼近1 或-1 的速度.类似地,在双曲正切函数的基础上,本文使用如下形式的函数:
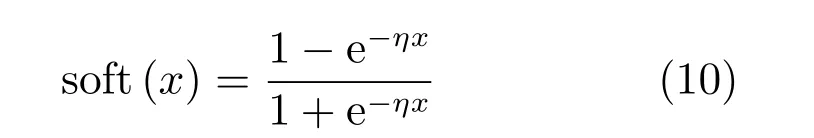
式中,η 控制阈值函数的斜率,本文中称其为软阈值函数.
与HashNet 算法[20]不同的是,HashNet 算法在训练的过程中,逐渐增大阈值函数的尺度系数,随着迭代次数的增加,阈值函数不断逼近并最终收敛至符号函数,而本文的算法中软阈值系数η 为模型参数,通过实验获取最优参数后,在每次迭代中,η保持不变,这样将简化模型并使模型快速收敛.本文在网络输出端使用式(10)的软阈值函数,离散约束问题就转化为可导损失函数对模型参数求导的问题.在迭代过程中,软阈值函数将网络输出的结果平滑地非线性映射到(-1,1)之间,并且将大部分哈希位阈值化到-1和1 两个值附近.图1 给出一维空间soft(x)函数的曲线,随着η 的增大,软阈值函数soft(x)的函数值更加迅速地集中靠近离散值-1 或1.

图1 soft(x)的函数曲线Fig.1 The function curve of the soft(x)
结合式(5)的交叉熵损失函数和式(8)的正则项,并在卷积网络输出端使用式(10)的软阈值函数soft(x),本文建立如下目标函数:
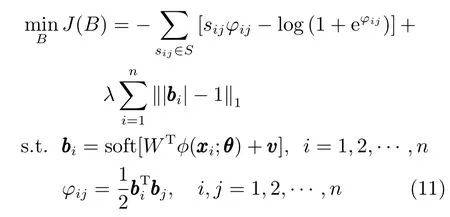
式中,n 表示样本数,sij∈{0,1}表示样本i和样本j 是否相似,λ 表示正则项系数,soft(·)表示软阈值函数,对向量逐元素运算,η 表示软阈值函数的控制参数,bi表示前向网络输出的准哈希码,φij表示两个哈希码之间的相似度.目标函数中,第1 项为语义保真项,第2 项为准哈希码的正则项.在本文的网络模型输出端使用soft(·),输出结果bi将迅速逼近-1和1 这两个值,使得ℓ1范数正则项损失减小,同时加快网络收敛的速度.网络经过训练后,在网络模型外部使用符号函数将准哈希码量化为二值哈希码.
2.2 参数学习
参数变量W和W 通过神经网络的反向传播(Back propagation,BP)求解,在每一次迭代中,通过随机梯度下降算法(Stochastic gradient descent,SGD)更新W和W.目标函数用两项之和表示为J=J1+λJ2,其中,
1)对准哈希码bi求偏导
第1 项J1对bi求偏导,可得:

第2 项J2对bi求偏导,可得:

结合式(12)和式(13)可得损失函数J 对bi的偏导数为

2)对参数W 求偏导
设zzzi=WTφ(xi;θ)+W,损失函数J 对W 求偏导,根据链式求导法则可推导出:


其中,diag{·}表示主对角线上为向量元素的对角矩阵,soft′(x)=(2ηe-ηx)/(1+e-ηx)2,对向量逐元素运算.
因此,可得损失函数J 对W 的偏导数为
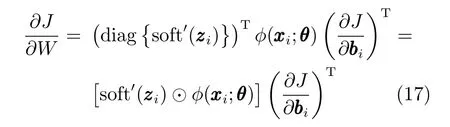
其中,⊙为哈达玛积(Hadamard product).
3)对偏移量W 求偏导
损失函数J 对W 求偏导,根据链式求导法则可得:
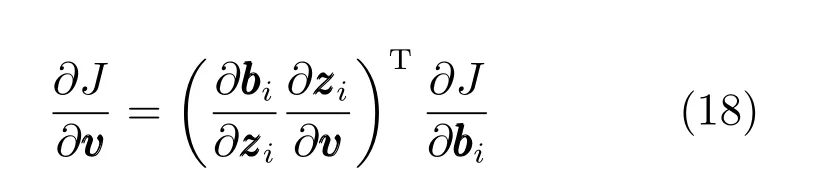

其中,Il∈Rl×l为单位矩阵.
因此,可得损失函数J 对W 的偏导数:

由以上求解过程可知,损失函数可导,即反向传播的过程偏导数存在,网络模型经过一定迭代能够收敛.
2.3 网络结构与参数
本文采用AlexNet 网络模型作为深度哈希学习的基础模型,AlexNet 模型一共分为8 层,5 个卷积层和3 个全连接层[12].在每一个卷积层中使用线性整流函数(Rectified linear unit,ReLU)作为激励函数以及局部响应归一化(Local response normalization,LRN)处理数据,然后经过下采样(Pooling),自动提取图像的特征表示,再经过全连接层输出结果.本文使用的AlexNet 网络模型及参数如图2 所示,第1,3,5,6,7 层为卷积层.卷积层均使用保留边界的滑动方式,第1和第3 层使用的卷积核的尺寸分别为11×11和5×5,其他3 个卷积核的尺寸为3×3,第1 层的滑动步长水平垂直方向均为2,其他4 个卷积层的滑动步长水平垂直方向均为1.第2,4,8 层为下采样层,使用非保留边界的滑动方式,窗口尺寸为3×3,滑动步长水平和垂直方向均为2,后三层为全连接层,输出端使用软阈值函数阈值化输出为准哈希码.

图2 本文算法使用的网络模型Fig.2 The network model of our algorithm
2.4 算法流程
算法1 给出了本文算法的伪代码,输入数据为一定格式的图像,通过CNN 的卷积层和池化层提取图像的特征表示,将图像的特征表示输入CNN 全连接层后使用软阈值函数得到图像的准哈希码.根据目标函数,使用反向传播算法更新参数W和W,通过指定次数的迭代训练完成模型,最后,在训练完成的模型外部使用符号函数,对图像的准哈希码量化输出二值哈希码.
算法1.深度非松弛哈希学习算法(DNRH)

3 实验结果与分析
3.1 在CIFAR-10和NUS-WIDE 上的实验
将本文提出的算法与各种流行的哈希学习算法进行比较,其中包括2 个非监督哈希学习算法SH[6]和ITQ[8],4 个监督型非深度哈希学习算法MLH[9]、KSH[10]、SDH[11]和BRE[22],以及6 个监督型深度哈希学习算法CNNH[17]、FP-CNNH[23]、NINH[24]、DHN[25]、DSH[18]和DPSH[19].在6 个非深度哈希学习算法中从图像中提取512 维的GIST 特征向量作为哈希函数的输入.本文的DNRH 算法和其他6个深度哈希学习算法CNNH、DHN、FP-CNNH、NINH、DSH、DPSH 根据图像的尺寸使用AlexNet网络卷积层自动提取一定维度的图像特征作为哈希函数的输入,生成哈希码.
为了将本文提出的DNRH 算法与上述哈希学习算法的性能比较,实验中,本文选取CIFAR-10[26]和NUS-WIDE[27]两个公开的数据集.在这两个数据集上训练模型并进行测试.CIFAR-10 由60 000幅32×32 像素的RGB 彩色图像构成,共包含飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车10 个类别[26].其中50 000 幅作为训练数据,10 000 幅作为测试数据.NUS-WIDE 数据集是由新加坡国立大学媒体搜索实验室创建的网络图像数据集,共有5 018个标签,81 个类别,将近270 000 幅来源于网络的图像.与CIFAR-10 不同的是,NUS-WIDE 数据集中某一幅图像可能赋予一个或者多个标签,在本文实验中,主要抽取动物、建筑、植物、夕阳、人、天空、云、水、草、窗户、湖、树、汽车、沙滩、鸟、狗、马、雪、花、海洋、马路21 个常用的类别[27]用于实验,每个类别中至少包括5 000 幅图像.
在实验阶段,在CIFAR-10 数据集中,本文随机从每一个类别中抽取500 幅图像作为训练数据,100 幅图像作为测试数据,一共5 000 幅图像组成训练集,1 000 幅图像组成测试集.在NUS-WIDE数据集中,随机从每一个类别选出500 幅图像作为训练数据,100 幅图像作为测试数据.一共10 500幅图像组成训练集,2 100 幅图像组成测试集.在NUS-WIDE 数据集上直接使用AlexNet 网络模型,将每幅图像调整为224 × 224 像素的尺寸以适应AlexNet 网络模型的输入.为了验证算法的鲁棒性,本文在CIFAR-10和NUS-WIDE 两个数据集上ℓ1范数正则项系数λ 均设置为0.05,软阈值函数控制参数η 均设置为12.
为了避免实验误差以及随机性,在评价哈希学习算法的有效性上,本文采用平均准确率(Mean average precision,MAP)[28]作为检索图像的评价指标.选取一定长度的哈希码后,在测试集中,选取一部分图像作为待检索的样本,依次计算待检索的图像与数据集中其他图像的汉明距离,根据汉明距离将图像排序并计算排序列表中与待检索图像类别相同的图像数量与检索图像总数之间的比值,作为准确率.
表1 比较了CIFAR-10 数据集上本文的DNRH算法与现有的哈希学习算法的MAP.从表1 可以观察到,在4 种长度的哈希码上,本文的DNRH 算法的平均准确率均明显高于其他所有算法.通过比较CNNH、DHN、FP-CNNH、NINH、DPSH、DSH和DNRH 等7 个深度哈希算法以及其他6 个非深度哈希算法的MAP 可知,深度哈希算法高于非深度哈希算法的平均准确率,这表明使用CNN 模型的深度哈希学习算法自动提取图像特征表示比传统手工提取图像特征表示具有更好的性能.对于12 bit的哈希码,所有算法的检索准确率相对偏低,随着哈希码长度的增加,所有算法检索准确率都逐渐提高,哈希码长度为48 bit 时,所有算法的检索准确率达到了最高.相比于48 bit 以下的哈希码,使用48 bit的哈希码可以存储更多的图像特征,在检索时,可以利用更多的图像特征,取得更高的准确率.
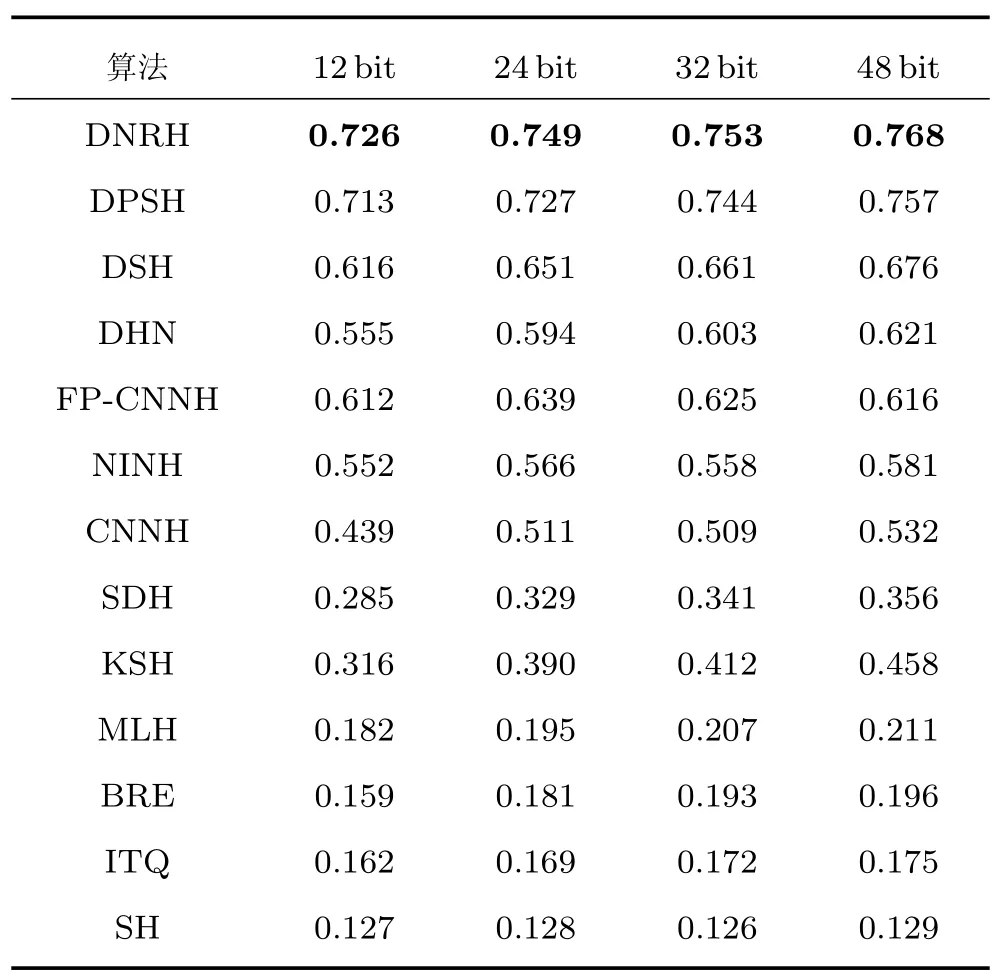
表1 各种算法在CIFAR-10 上的MAPTable 1 The MAP of different algorithms on CIFAR-10
NUS-WIDE 数据集的图像相对于CIFAR-10数据集的图像具有更高的像素,更完整的图像细节,更贴近实际应用中的图像.在NUS-WIDE 数据集中,一幅图像可能包含多个标签,在检索过程中,只要检索到的图像与待检索图像包含有相同的标签,就判定为正确检索.表2 比较了在NUS-WIDE数据集上本文的DNRH 算法与现有的哈希学习算法在不同长度哈希码上的平均准确率.由于NUSWIDE 数据集的图像数量很大,在该数据集上,本文用每个测试样本检索返回的前5 000 个样本计算MAP.在相同长度的哈希码上,本文DNRH 算法在12 bit、24 bit、32 bit、48 bit 上的平均准确率分别为0.769、0.792、0.804、0.814,均高于其他的哈希学习算法,证明了本文的算法的普适性.其中,对于DPSH 算法,本文仍然使用在CIFAR-10 数据集上实验的Lagrange 乘子η=10,并在各种算法使用相同的训练集和测试集的设置下,在NUS-WIDE数据集上重新运行作者提供的代码,计算其平均准确率.随着哈希码长度的增加,几乎所有算法的平均检索准确率都有一定程度的提高,尤其SDH 算法,48 bit 的哈希码对应的平均准确率相对于12 bit 的哈希码的平均准确率提高了近7%,表明更多的哈希位能够表示更多的图像特征,提高检索准确率.
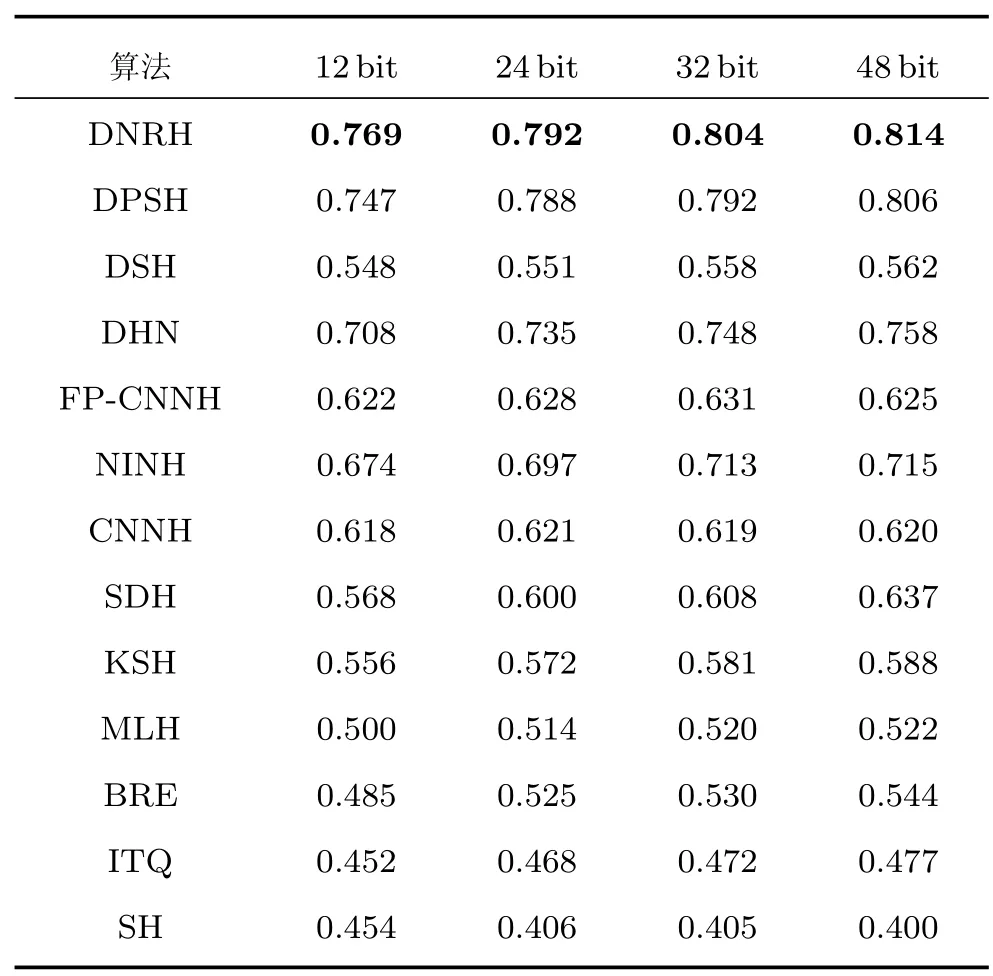
表2 各种算法在NUS-WIDE 上的MAPTable 2 The MAP of different algorithms on NUS-WIDE
3.2 ℓ1 范数和软阈值函数的约束效果
在本文提出的DNRH 算法中,软阈值函数的作用是在模型的前向计算中直接阈值化网络输出端的结果,而ℓ1范数作为目标函数的正则项在模型的反向传播中约束准哈希码,使准哈希码各个位的绝对值逼近1,这两个模块的作用均为约束准哈希码.为了验证联合使用ℓ1范数和软阈值函数的约束性能,本文在CIFAR-10 数据集上分别对ℓ1范数正则项独立约束、软阈值函数独立约束以及ℓ1范数和软阈值函数联合约束进行了实验.
表3 列出了在4 种长度的哈希码上,不同模型对应的平均准确率,其中,“交叉熵+软阈值”表示使用式(5)的损失函数,并在网络的输出端使用软阈值函数的模型,“交叉熵+ℓ1范数”表示使用式(11)的损失函数,并略去约束条件,即在网络的输出端不使用软阈值函数的模型,“交叉熵+ℓ1范数+软阈值”表示本文的DNRH 算法模型,即联合使用ℓ1范数和软阈值函数.观察表3 可知,“交叉熵+ℓ1范数”和“交叉熵+软阈值”这两个模型的平均准确率明显低于DPSH 算法,表明单独使用ℓ1范数和软阈值函数的效果并不如以Lagrange 乘子松弛求解的DPSH 算法.而联合使用ℓ1范数和软阈值函数(交叉熵+ℓ1范数+软阈值)在4 种长度哈希码长度上,其MAP 相比于单独使用其中一个模块均提高了近10%,并且高于DPSH 算法.因此可得出结论,联合使用ℓ1范数和软阈值函数能够更好地约束哈希码,提升算法性能.

表3 ℓ1 范数和软阈值函数约束在CIFAR-10 上的MAPTable 3 The MAP of ℓ1-norm and soft threshold function constraint on CIFAR-10
3.3 参数影响的分析
3.3.1 正则项系数λ 对准哈希码分布的影响
为了检验ℓ1范数正则项对全连接层输出的准哈希码的约束能力,本文在CIFAR-10 数据集上对输出的准哈希码的分布情况进行了统计.统计准哈希码中每一位的绝对值相对于1 的距离分别在区间[0,0.1),[0.1,0.2),[0.2,0.3),[0.3,0.4)的概率,如图3 所示,不同颜色表示不同的分布区间,横轴表示正则项系数λ,纵轴表示哈希位落在不同区间的概率.
从图3 中准哈希码各哈希位的分布情况可以看出,随着λ 的增大,准哈希码各哈希位的绝对值更集中靠近1,尤其在不使用ℓ1范数(λ=0)约束的情况下,准哈希码的哈希位在0~0.4 之间分布相对均匀,这样在最后的量化过程中损失会增加,导致结果不准确.在目标函数中,语义保真项用于保持点对之间的相似性,ℓ1范数正则项用于约束准哈希码的分布,正则项系数λ 过大将过分增大ℓ1范数正则项的比重,从而减小语义保真项的作用,影响分类效果.由此可以看出,适当的ℓ1范数正则项对准哈希码的分布有很好的约束作用.
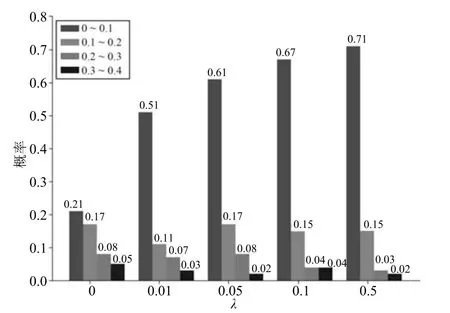
图3 不同正则项系数λ 下准哈希码的分布Fig.3 The distribution of hash code with different regularization coefficient λ
3.3.2 正则项系数λ 对准确率的影响
正则项系数λ 的取值,不仅影响模型输出的准哈希码各哈希位的分布,而且影响本文的DNRH 算法训练模型的准确率.表4 给出了哈希码的长度取48 时,在CIFAR-10和NUS-WIDE 数据集上λ 取不同值时的平均准确率.

表4 λ 的不同取值对应的MAPTable 4 The MAP on different λ
从表4 可以看出,在两个数据集上λ 的取值对MAP 的影响分布相同.当λ=0.05 时,测试集上的检索效果最好,λ 取值过小或过大都会对检索的MAP 造成影响.分析其原因可知,λ 值过小,目标函数对准哈希码分布的约束变弱,模型输出的准哈希码的部分哈希位将过度偏离-1 或1,造成最终量化为哈希码时损失增大;λ 的取值过大将造成目标函数中语义保真项的比重减小,由于该约束项的作用是保持图像之间的相似语义,减小该约束项的比重会造成相同类别之间的距离增大或者不同类别之间的距离减小,即图像之间的相似性约束变弱,使得检索效果变差.
3.3.3 软阈值函数控制参数η 对准哈希码分布的影响
为了验证软阈值函数对准哈希码的阈值化效果,本文在NUS-WIDE 数据集上进行实验,统计软阈值函数控制参数η 取不同值时,模型输出的准哈希码的分布情况.同样统计准哈希码中每一位的绝对值相对于1 的距离分别在区间[0,0.1),[0.1,0.2),[0.2,0.3),[0.3,0.4)的概率,如图4 所示,横轴表示软阈值函数控制参数η 的取值,纵轴表示哈希位落在不同区间的概率.

图4 参数η 取不同值时准哈希码的分布Fig.4 The distribution of hash code with different η
由图4 可以看出,η 的取值越大,准哈希码的各哈希位的越逼近1 或-1,尤其在η=20 时,准哈希码误差在0.1 以内的比例达到了90%,但是η 的取值过大也会带来严重的问题,当η=20 时,在模型的训练过程中,损失函数始终振荡难以收敛,这是因为当η 取值过大时,软阈值函数趋于不可导.为了在模型训练中使损失平稳收敛,并且使准哈希码绝对值逼近1,经过多次实验,本文中η 的取值为12.
4 结论
本文提出了一种基于点对相似度的深度非松弛哈希学习算法,该算法通过CNN 自动提取图像特征,在目标函数中使用交叉熵保持相似点对之间的语义相似性,在CNN 输出端使用可导的软阈值函数代替传统方法中的符号函数,使准哈希码非线性地接近-1 或1.并在损失函数中引入ℓ1范数约束输出的准哈希码,使得准哈希码逼近二值编码.最终在训练好的模型外部使用符号函数,将准哈希码量化为二值哈希码.在公开数据集(CIFAR-10、NUSWIDE)上的实验验证了本文提出的DNRH 算法优于其他哈希学习算法,取得了令人满意的效果.
