端到端说话人辨认的对抗样本应用比较研究
2021-06-18廖俊帆顾益军张培晶
廖俊帆,顾益军,张培晶,廖 茜
(1.中国人民公安大学 信息网络安全学院,北京 102600;2.中国人民公安大学 网络信息中心,北京 100038)
0 概述
语音是人与人之间最自然直接的交流方式,也是具有最大信息容量的信息载体。目前,说话人识别技术已在人们日常生活中得到了广泛的应用,说话人辨认技术作为其重要分支在公安司法等领域具有较好的发展前景。随着人工智能和大数据时代的到来,同时得益于计算机计算能力的不断提高,深度学习技术已经成为各界研究的热点,其可应用于说话人辨认系统的后端,使声学特征更具区分性,从而更有利于区分说话人,而端到端网络架构使用一个神经网络连接输入端和输出端,能将特征训练和分类打分进行联合优化[1-3]。因此,结合基于深度学习的端到端网络的说话人辨认技术能克服复杂环境干扰,具有易构建、强泛化的特点。机器学习算法是人工智能中的重要部分,给人们带来便利的同时也带来了诸多安全问题。机器学习模型的攻击方式一般为破坏其机密性、完整性和可用性,主要包括隐私攻击、针对训练数据的攻击以及针对算法模型的攻击[4-5]三类方式。对抗样本是能轻易地引发模型分类错误的针对算法模型的攻击方式[6-7],随着对抗样本在图像、自动驾驶等领域被证实可使攻击者逃避模型检测,研究人员发现机器学习模型面对对抗样本表现出的脆弱性问题是普遍存在的,而基于深度学习的端到端说话人辨认模型也可能受到对抗样本的攻击。
为准确全面地评估端到端说话人识别技术面临的安全问题,本文系统地分析端到端说话人辨认系统和目前多种经典的白盒算法和黑盒算法,以基于卷积结构的端到端说话人辨认模型作为实验对象,通过实验比较评估这些对抗样本对端到端说话人辨认系统的攻击性能。
1 端到端说话人辨认
1.1 基于深度学习的端到端说话人辨认
说话人辨认是多分类问题[8],即判断某段语音是由若干人中哪个人所说。端到端说话人辨认系统由深度神经网络组成,深度神经网络将不同长度的语段映射为一定维度的特征向量,即深度嵌入,再将不同说话人的语音特征映射到超球面的不同区域,最终通过各区域之间的差异实现分类。在识别过程中需要先在语音数据中提取声学特征,使用X⊂Rd表示声学特征向量的域,声学特征表示为向量序列x=(x1,x2,…,xT),其中xi∊X且1≤i≤T,由于输入信号长度不固定,因此T值也不固定。将特征向量x输入深度神经网络生成帧级别的特征,帧级别的特征被激活后输入平均池化层得到话语级别的特征,再利用仿射层进行维度转换得到固定维度的深度说话人嵌入,最终输出层将固定维度的深度说话人嵌入映射到训练说话人类别。
1.2 针对端到端说话人辨认的攻击模型
针对端到端说话人辨认系统的对抗攻击,需要运用对抗样本生成算法制作针对端到端说话人辨认模型的对抗样本。对抗样本可以诱导模型算法出现误判或漏判,从而躲避系统的识别实现攻击。本文将在白盒和黑盒设置下对端到端说话人辨认模型进行攻击。在白盒设置下,攻击者可以完全访问说话人辨认系统,根据获取到的梯度信息制作噪声,并且能最大程度地减少扰动提高成功率。在黑盒设置下,攻击者只能有限制地访问模型,并且仅获得端到端说话人辨认模型的输出,无法直接获取输入与输出之间的梯度。与在声学特征上生成对抗样本的方法[9-10]不同,本文是在音频上直接制作对抗样本,具备更好的隐蔽性。如图1所示,一段音频经攻击者添加噪声后被输入目标说话人辨认系统中,攻击者根据模型反馈信息反复对噪声进行修改,最终制作出对抗样本,实现端到端说话人辨认系统的错误识别。

图1 攻击步骤Fig.1 Attack steps
2 对抗样本生成算法
利用深度神经网络训练得到的模型在输入和输出之间的映射通常为非线性,因此在输入数据中通过故意添加不易察觉的细微扰动来生成的对抗样本,能够导致模型以高置信度给出一个错误的输出。对抗样本能够找出机器学习模型的弱点,在网络安全领域主要用于模型安全评估和对抗鲁棒性强化。
目前,关于攻击的分类有很多种,按照是否获得目标模型的具体结构和参数可分为白盒攻击和黑盒攻击。白盒攻击指攻击者能获取目标模型的所有信息,对抗样本较多,如FGSM[11]、JSMA[12]、BIM[13]、C&W[14]、PGD[15]等;黑盒攻击指攻击者无法直接获取模型的任何信息,只能通过访问模型来获取反馈信息对黑盒模型进行估计,从而使得攻击成功,如ZOO[16]、HSJA[17]等。此外,按照是否需要指定攻击类目可分为无目标攻击和有目标攻击。无目标攻击不指定具体类目,只需使识别模型出现错误,如Deepfool[18]等。有目标攻击比无目标攻击更困难,不仅需要识别模型出现错误,还需模型输出指定的结果,如C&W 等。现有的对抗样本生成算法并不都能适应音频数据中复杂的时间域信息和计算复杂度,因此难以在端到端说话人辨认系统中进行实现,如Deepfool。本文仅选取可用于端到端说话人辨认系统的FGSM、JSMA、BIM、C&W、PGD 这5 种白盒算法和ZOO、HSJA 这2 种黑盒算法进行对抗样本攻击实验。
2.1 白盒算法
2.1.1 FSGM 算法
在一般情况下,给定分类网络F和输入x,通过求优化问题式(1)生成对抗样本,即在允许的最大扰动量ε的约束下,扰动δ的p范数能实现最大化网络预测F(x+δ)和真实标签y的损失函数L。
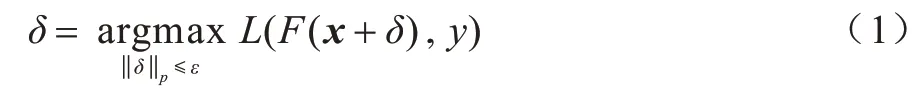

FSGM[8]是根据高维空间下深度神经网络的线性行为会导致对抗样本的产生而设计得到,并利用损失函数梯度解决优化问题式(1),计算公式如下:其中,∇L(F(x),y))表示损失函数的偏导数。若是目标攻击,则将y换成目标标签t。FSGM 攻击需要考虑损失函数相对于输入梯度的符号,适用于端到端说话人辨认的非线性模型。本文采用的分类模型F包含特征提取模块,对应输入音频x无需进行过多预处理,仅将扰动噪声添加到测试音频中。FGSM对抗样本生成速度快,但攻击性较弱,对模型防御能力提升小。
2.1.2 JSMA 算法
JSMA[12]算法利用显著性映射,能够表征分类器的输出与输入之间的关联,仅在样本x的关键分量上添加扰动,能够得到使分类器输出指定类目的对抗样本。因为分类器的结果受输入样本x某些分量的影响较大,不同于FGSM 的梯度通过对损失函数求导获得,JSMA算法的前向导数是神经网络的logit层的输出Z(˙)对输入特征的偏导,所以在端到端说话人辨认网络中实现分类器对样本x的显著性映射如下:
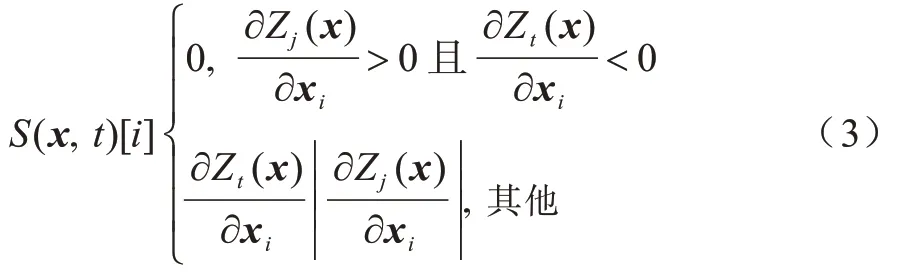
其中,i表示对应的输入分量,t表示分类器对应目标标签的输出分量,j表示输出的其他分量。根据最大化显著性效果获得输入的关键分量k,因此在迭代过程中对其添加扰动:
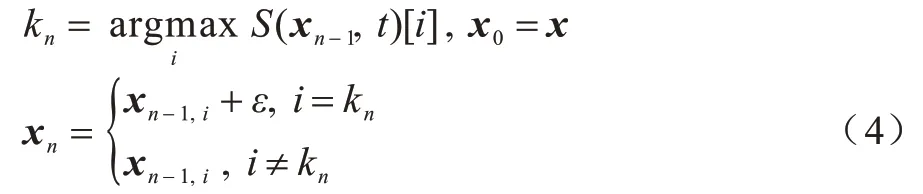
在获得的特征上添加扰动获得对抗样本,扰动方式分为正向扰动和反向扰动。不同于图像数值全为正值,音频的波形数值是正负值并存,实现结果可能有所差异。JSMA 是基于梯度的迭代算法,仅对样本的部分分量进行修改,与原样本的相似度高,但是每次迭代均需要重新计算显著图,因此生成速度较慢,不适用于部分大规模数据集。
2.1.3 BIM 算法
由于FGSM 算法仅涉及单次梯度更新,对于大规模数据出错概率较高,因此KURAKIN 等人[13]提出快速梯度符号法的改进迭代算法。迭代梯度符号法的对抗样本生成算法如下:
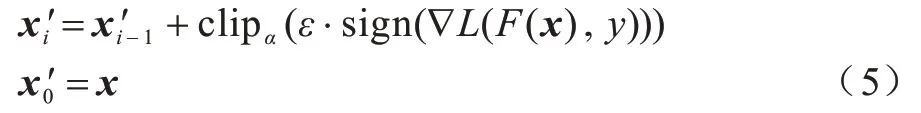
其中,clip 表示将溢出的数值用边界值代替,这是因为在迭代更新中,随着迭代次数的增加,部分元素可能会溢出,只有代替这些数值原有的边界值,才能生成有效的对抗样本。相比FGSM,BIM 能够在音频信号中寻找更精准有效的噪声点,实现性能更优的对抗音频。
2.1.4 C&W 算法
C&W[14]算法在式(1)的优化问题上添加欧几里得距离来量化对抗样本x'和原始样本x之间的差异。为消除x'∊[0,1]p区间约束,将x'替换为(tanhω+1),ω∊Rp,由此将优化问题转化为无约束的最小化问题,如式(6)所示:
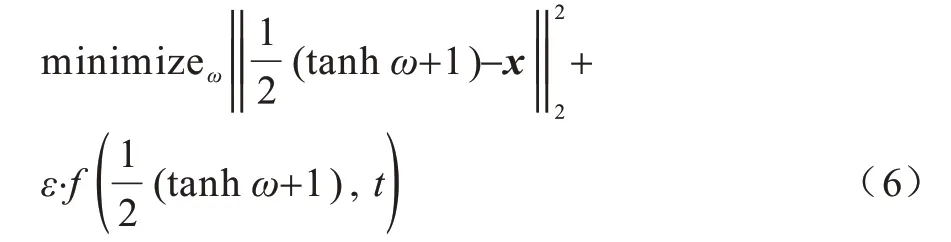
通过映射到tanh 空间,对抗样本能在(-∞,+∞)上进行变换,其中f(x,t)表示损失函数,反映了对抗攻击的不成功概率,t表示目标类别。损失函数一般表示为:

其中:k≥0 表示攻击传递性的调整参数,k确保了的恒定距离,随着k值的增大,攻击成功率越高;Z(˙)表 示logit 层的输 出。C&W 算法生成的扰动极小,但消耗时间较长。CARLINI 等人[19]将C&W 算法应用在语音识别模型中,并使语音识别模型能将任意音频输出为特定目标句子,因此C&W 算法也可应用在说话人辨认模型中。
2.1.5 PGD 算法
PGD[15]算法是一种迭代算法,可看作是在BIM 的基础上添加一层随机化处理,其允许在范数球内的随机点上初始化,然后进行基本迭代,每次迭代均会将扰动投影到规定范围内,但能产生比BIM 更好的攻击效果。在迭代过程中,将对抗音频进行如下操作:
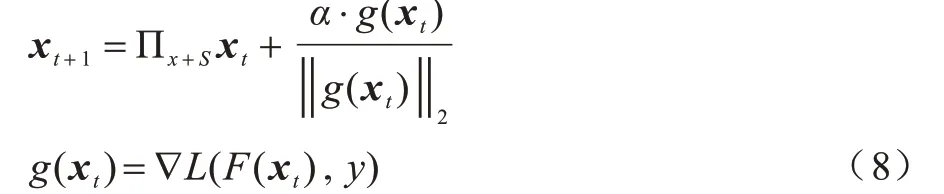
其中,S=r∊R(d‖r‖2≤ε)表示扰动的约束空间,α表示扰动修改的步长,Πx+S表示在范数球上进行投影。在迭代过程中,若添加的扰动幅度过大,则将其拉回范数球的边界。通过一阶梯度得到的样本被称为一阶对抗样本,而PGD 是一阶对抗样本中最优的对抗样本生成算法。PGD 可看作是FGSM 的拓展,能够在端到端说话人辨认模型上进行实现。
2.2 黑盒算法
2.2.1 ZOO 算法
ZOO[16]算法基于C&W 算法并修改其损失函数实现黑盒设置下的攻击,而无需替代模型[20],其使用有限差分法获取近似梯度来解决黑盒设置下无法获取模型梯度的问题。受C&W 算法启发,CHEN[16]等人提出一种新的类似铰链的损失函数,具体为:
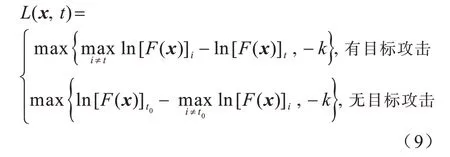
其中,t0表示x的原始标签,表示除t0之外最可能的预测类别。
对数运算符对黑盒攻击至关重要,因为DNN 通常会在输出F上产生偏斜的概率分布,此类的置信度得分显著地支配另一类的置信度得分。因此,使用对数运算可减少主导效应,并保留由于单调性而导致的置信度得分顺序,同时采用对称差商[21]或Hessian 估计来估计梯度:
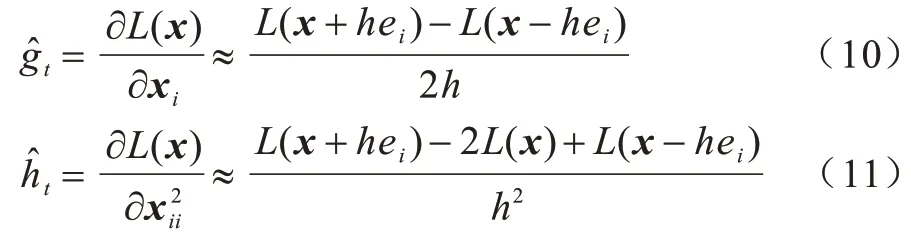
梯度评估是将黑盒转化为白盒的过程。两种估计方式分别对应ZOO 的两种变体,即ZOO-ADAM和ZOO-Newton,并对应ADAM 和Newton 求解器以找到最佳的坐标进行更新。ZOO 采用随机坐标下降来替代梯度下降方法,在每次迭代中随机选择一个变量(坐标),通过沿该坐标近似最小化目标函数进行更新,实现更快速有效的更新过程。ZOO 适用于端到端说话人辨认模型,但对目标模型的访问次数较多,查询效率较低。
2.2.2 HSJA 算法
HSJA[17]算法在决策边界使用二进制信息对目标模型的梯度方向进行预估,利用L2和L∞的相似性指标进行优化的无目标和有目标攻击。与边界攻击[22]相比,HSJA 需要的模型查询更少,在攻击多种广泛使用的防御机制时,具有一定优势。HSJA 引入布尔值函数ϕx*:[0,1]d→{-1,1}作为成功扰动的指标,对抗样本的目标是生成对抗样本x′,使得ϕx*(x′)=1,同时保持x′接近原始样本x,从而将对抗样本制作问题转化为最优化问题,如式(12)所示:

其中,d是量化相似度的距离函数,HSJA 为迭代算法,每次迭代均涉及梯度方向估计、通过几何级数进行步长搜索以及利用二分搜索将最后一次迭代推向边界这3 个步骤。HSJA 查询效率高,具有收敛性分析,适用于端到端说话人辨认模型,但对于限制边界查询的目标模型的攻击效果较差。
3 实验设置与结果分析
3.1 实验目标模型
本文选用百度的DeepSpeaker[23]作为目标模型,包括ResCNN 和GRU 两种模型,它们是目前最具代表性的基于深度学习的端到端说话人识别模型。在声学特征提取阶段,为保留更丰富的原始音频信息,将语音信号利用帧长25 ms、帧移10 ms 的滑动窗口转化为64 维FBank(FilterBank)特征。每个样本随机截取多个约1.5 s 的语音段,生成160×64 的特征矩阵。ResCNN 和GRU 网络结构见表1 和表2,其中,“—”表示该层网络不涉及相应参数。

表1 ResCNN 网络结构Table 1 ResCNN network structure
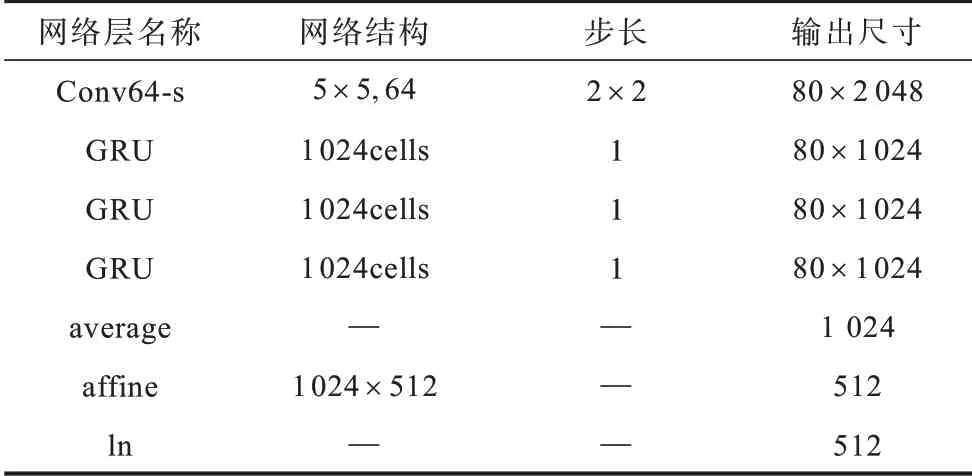
表2 GRU 网络结构Table 2 GRU network structure
ResCNN 网络中两个卷积核为3×3、步长为1×1的卷积层组成1 个残差块,实现低层输出到高层输入的直接连接。ResCNN 网络具有4 种残差块,每种残差块有3 个。同时,残差块后的一个卷积核为5×5、步长为2×2 的卷积层使频域的维度在输出通道数增加时保持不变。经过多个卷积层和残差块提取到的帧级别特征进入时间平均池化层(average)。GRU 网络使用和ResCNN 网络相同的卷积层来降低时域和频域的维度。卷积层之后是3 个前向的GRU层。时间平均池化层对特征在时域上整体取均值,得到话语级别的特征,使得构建的网络在时间位置上具有不变性,再经过仿射层(affine)将语音级别的特征映射成512 维的深度说话人嵌入。最后输入Softmax 层进行分类。
3.2 实验数据集及环境设置
实验使用中文语音数据库AISHELL-1(简记为AISHELL)[24]和英文语音数据库LIBRISPEECH(简记 为LIBRI)[25]。AISHELL 的录音文本涉及智能家居、无人驾驶和工业生产等,并且在安静室内同时使用3 种不同设备总共录制178 h,其中包含400 个说话人。LIBRI 数据集包含1 000 h 的16 kHz 英语语料。实验训练了400 个说话人和10 个说话人的端到端说话人识别模型,分别用于无目标的对抗攻击和有目标的对抗攻击。
实验平台及环境:Intel®XeonTMGold 5118 CPU@2.30 GHz(CPU),Tesla-V100-SXM2-32 GB(GPU),32 GB memory,Ubuntu 18.04.3 LTS(OS),Python 3.6,Tensorflow 2.10。
3.3 评价指标
本文使用攻击成功率(Attack Success Rate,ASR)、扰动大小、置信度、对抗样本生成时间来评价各生成算法对端到端说话人识别模型的性能。
攻击成功率:成功逃避模型识别的样本数占测试样本总数的比例,计算公式如下:

其中,ssumNum(˙)表示样本数量,x表示原音频,x′表示对抗样本,llabel(˙)表示模型输出标签,y0表示真实说话人标签;若有目标攻击时,分母改为ssumNum(llabel(x′)=yt),yt是目标说话人标签。
生成时间:生成一定数量的对抗样本所需的时间。为了准确地评估各算法的生成速度,实验设置的算法生成批次大小均为1,即每批次只生成一个对抗样本。
扰动大小:样本修改前后的变化量,衡量样本被处理前后的变化程度,计算公式如下:

其中,N为样本个数,‖˙‖1为1 范数。
信噪比(Signal to Noise Ratio,SNR):信号功率与噪声功率的比值,通常用来评估音频质量,计算公式如下:
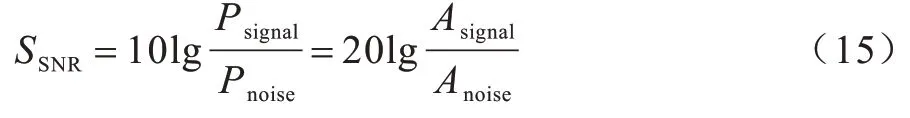
其中,Psignal为信号功率,Pnoise为噪声功率,Asignal为信号幅度,Anoise为噪声幅度。较大的SNR 值表示较小的噪声等级。在本文实验中,SNR 用来衡量对抗音频相对于原始音频的失真,比较生成算法生成的对抗性音频的差异。
置信度:在无目标攻击实验中,样本鲁棒性使用原类标置信度表示,对抗样本被识别为原类标的置信度越低,表示该样本越鲁棒。在有目标攻击的实验中,样本鲁棒性使用目标类标置信度表示,对抗样本被识别成目标类别的置信度越高,表示该样本越鲁棒。
3.4 算法参数设置
表3 和表4 表明FGSM、BIM、PGD 的ASR 和扰动随参数ε增加而增大,C&W 在范数L2和L∞下的ASR 随k变化不大,而扰动随之增大。但是,JSMA、ZOO 和HSJA 参数多样,难以统一比较。为在相似的攻击强度下对生成算法进行比较,在后续实验中:FGSM、BIM、PGD 的度量单位均为L∞且ε=0.001(描述可修改的L∞范围大小);JSMA 的度量单位为L2;C&W 和ZOO 使用置信度参数k来描述扰动大小且设置为0.0,其中C&W 分别使用L2和L∞两种度量单位进行实验;JSMA 设置每步修改的扰动量为0.1,最大特征分数为1.0。HSJA 的初次和最大评估次数分别设置为100 和1 000。
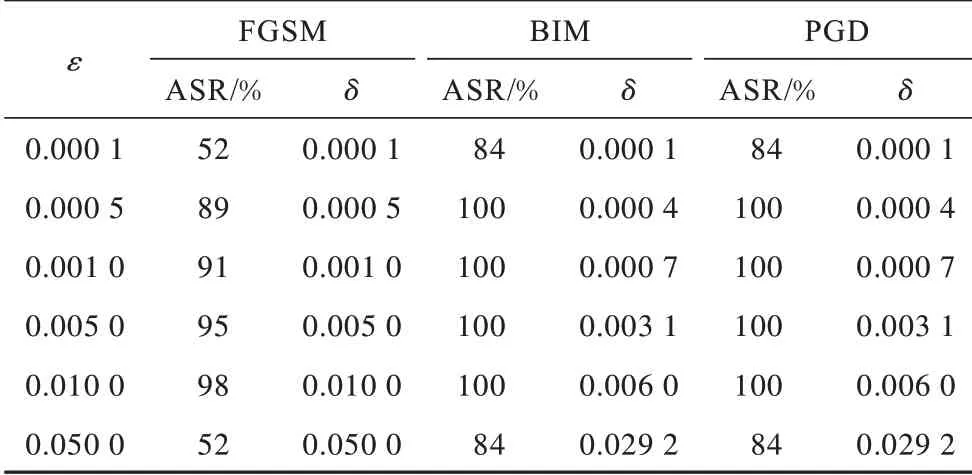
表3 不同ε下FGSM、BIM和PGD算法的ASR和扰动大小Table 3 The ASR and perturbation size of FGSM,BIM and PGD algorithms under different ε

表4 不同k 和范数下C&W 算法的ASR 和扰动大小Table 4 The ASR and and perturbation size of C&W algorithm under different k and norms
3.5 实验结果分析
3.5.1 无目标攻击实验结果分析
在无目标攻击的实验中,对于不同的生成算法,使用相同的100 段音频,各自分别对不同网络结构和数据库训练的模型生成100 个对抗样本。
表5 给出了无目标攻击时各生成对抗样本算法的ASR、扰动大小和生成时间。对于说话人辨认的无目标攻击,8 种算法均能躲避系统识别。平均扰动的值越小,噪声越小,这样能使对抗音频对人类的听力更加难以察觉,各算法均具有较小的扰动。FGSM 无需进行迭代,生成速度最快,但ASR 劣于其他算法。从生成时间而言,黑盒攻击明显比白盒攻击花费更多的生成时间。

表5 无目标攻击时各生成对抗样本算法的ASR、扰动大小和生成时间Table 5 The ASR,perturbation size and generation time of each algorithm for generating adversarial samples with non-targeted attacks
表6 给出了无目标攻击时各生成对抗样本算法的信噪比,各算法得到的对抗样本都有较好的平均信噪比,但JSMA、C&W(L∞)和ZOO 的最低信噪比接近0,甚至负值。这说明音频信息完全丢失,无法完成攻击,C&W(L2)和HSJA 的平均信噪比在白盒和黑盒攻击时均最高,几乎能够躲避人听力的察觉。
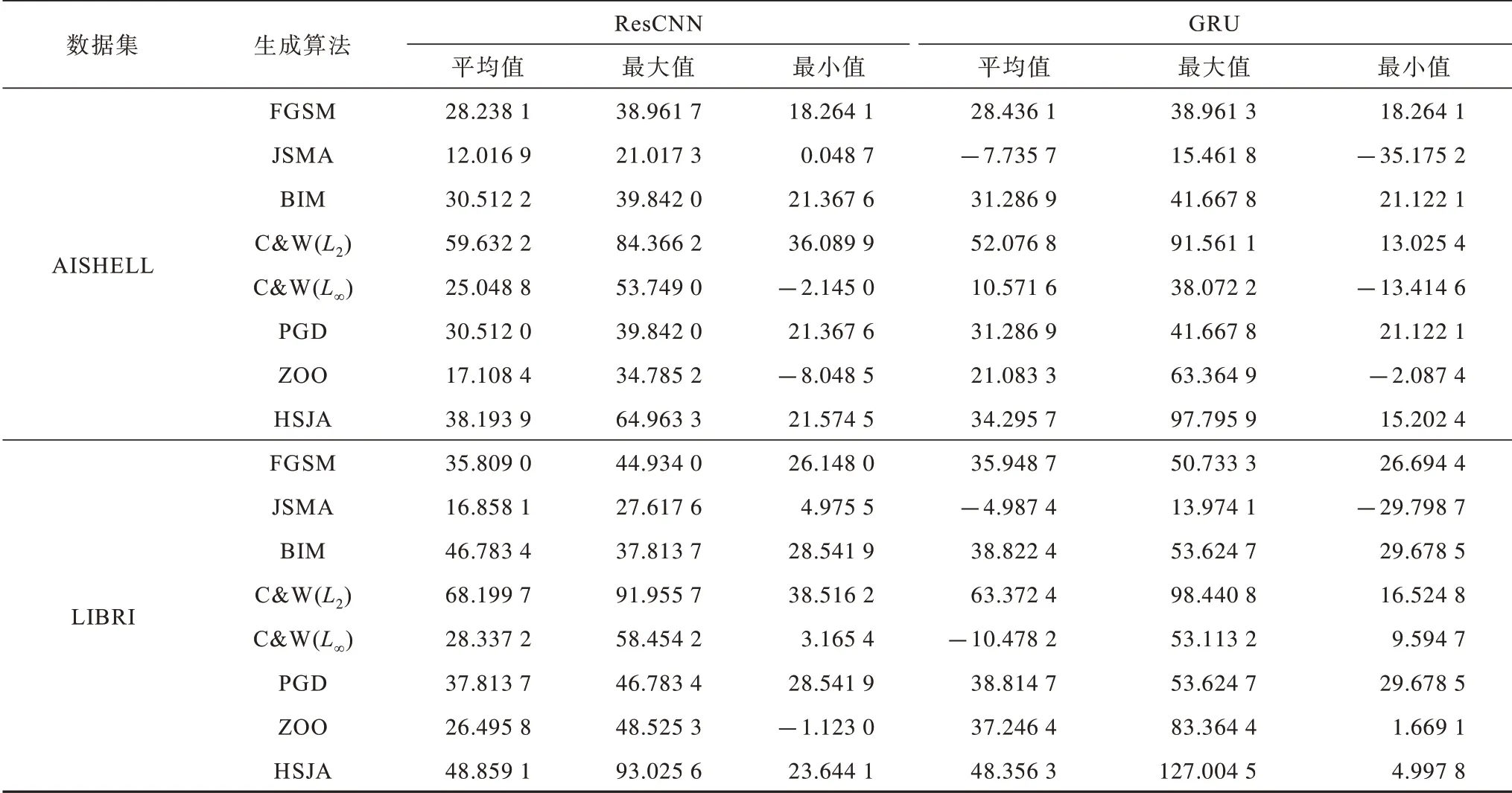
表6 无目标攻击时各生成对抗样本算法的信噪比Table 6 The SNR of each algorithm for generating adversarial samples with non-targeted attacks dB
表7 给出了无目标攻击中对抗样本被端到端说话人辨认模型识别为真实类目的置信度。可以看出,面对端到端说话人辨认模型,每种算法均能使对抗样本偏离真实类目,但C&W(L2)、C&W(L∞)和ZOO 高低差异较大,稳定性较差。PGD、BIM 真实类目的置信度最低,对抗样本最具鲁棒性且稳定性较强。
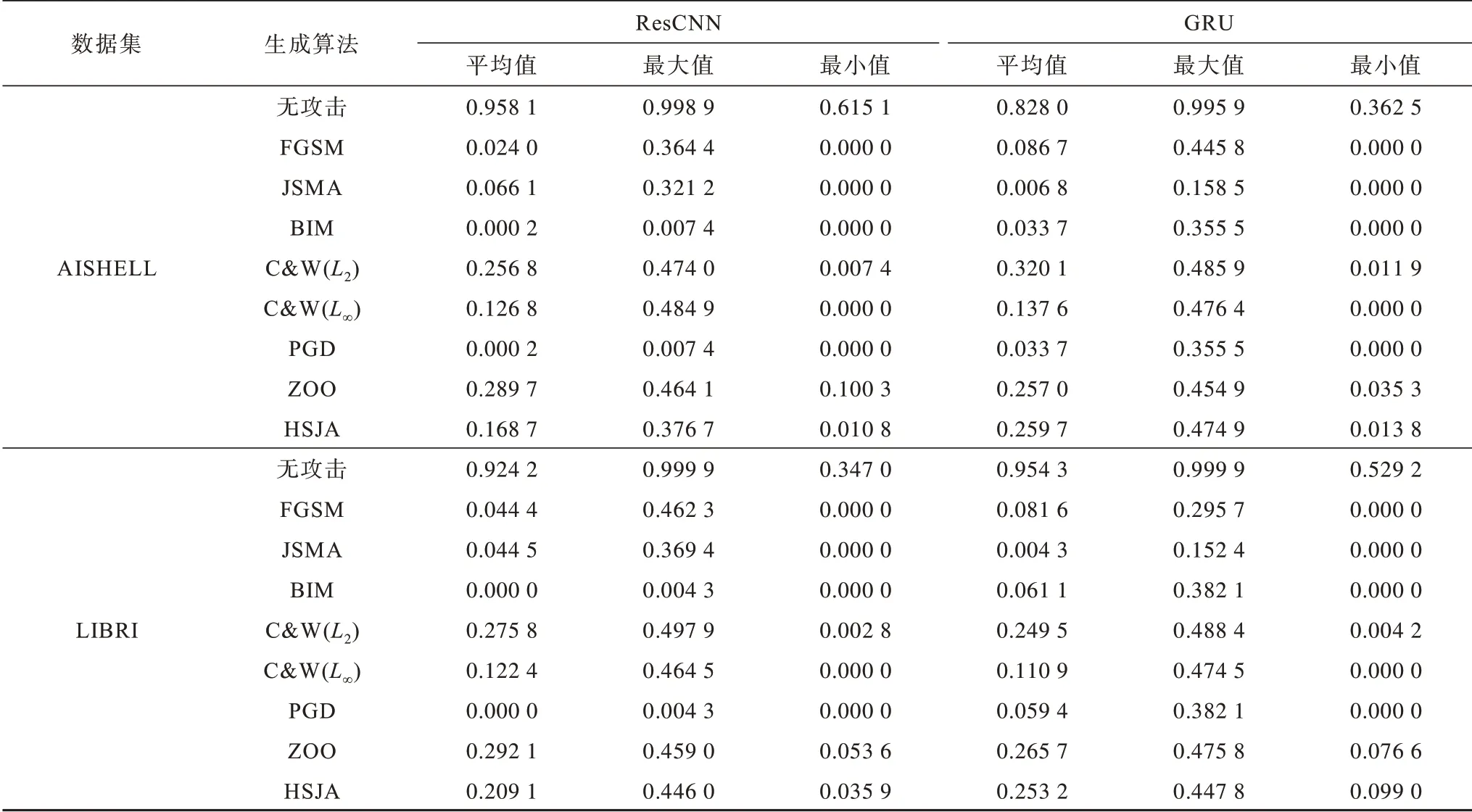
表7 无目标攻击时各生成对抗样本算法的置信度Table 7 The confidence of each algorithms for generating adversarial samples with non-targeted attacks
3.5.2 有目标攻击实验结果分析
在有目标攻击的实验中,随机抽取10 段不同说话人的音频,每段音频以与该音频的真实标签不同的说话人为目标,生成9 个对抗样本。
表8 给出了有目标攻击中对抗样本的攻击成功率以及成功对抗样本的平均信噪比、置信度、扰动大小和生成时间。可以看出,JSMA、BIM 和PGD 的ASR 较高,但JSMA 的SNR 和置信度较低,表现劣于BIM 和PGD。在黑盒攻击中,ZOO 和HSJA 表现较差,但HSJA 在信噪比、置信度和扰动三方面优于ZOO。图2 给出了对抗样本对目标说话人的置信度的热力图,其中,横坐标Source Speaker 表示真实说话人,纵坐标Target Speaker 表示目标说话人,置信度从高到低进行分布。

图2 有目标攻击时各算法置信度的矩阵热力图Fig.2 The matrix heat map of the confidence of each algorithms with target attack

表8 有目标攻击时各生成对抗样本算法的ASR 以及平均SNR、置信度、扰动大小和生成时间Table 8 The ASR and average SNR,confidence,perturbation size and generation time of each algorithm for generating adversarial samples with targeted attacks
BIM 和PGD 将10 个音频都生成相应目标的鲁棒性对抗样本,表现最优。在ZOO 和HSJA 的热力图上可以看出,以说话人S0163 为目标的不同对抗样本的置信度都较高,推测模型存在部分薄弱的类目,较容易被算法估计出特征。
3.5.3 不同网络结构下的生成算法实验结果分析
在ResCNN 和GRU 网络结构模型的测试结果中,大部分算法在GRU 模型测试的ASR 较低、生成时间较长。这表明对GRU 模型进行无目标攻击较为困难,其中JSMA 的生成难度最大。而ResCNN 和GRU 网络结构的平均信噪比和真实类目的平均置信度相差不大。在有目标攻击时,其他算法对GRU模型的ASR 较低(除了JSMA 和HSJA 之外),生成时间较长(除ZOO 之外)。由此得出,对抗样本生成算法的性能会受端到端说话人辨认系统的网络结构限制,并且生成算法对GRU 的攻击效果较差。
3.5.4 不同语种下的生成算法实验结果分析
上述实验结果显示,在相同的网络结构下,JSMA 和ZOO 在LIBRI 英文数据集训练的模型和AISHELL 中文数据集训练的模型上的生成时间差异较大,其他指标相近,这可能是因为模型训练差异,而其他算法的各项指标测试结果差异不大。由此得出,各对抗样本生成算法对模型攻击效果受不同语种的影响较小。
3.5.5 隐蔽性测试结果分析
为验证对抗音频与原始音频的区别,本文对30 个听众进行3 项测试:1)判断每种对抗音频是否为噪声(每种随机抽取1 个);2)确认能否听清对抗音频的内容(每种随机抽取1 个);3)听1 对音频(原始音频和相应的对抗音频),找出对抗音频,属于ABX 测试。每项都设置对照组,测试结果见表9,其中,测试结果A 表明感觉音频没有噪声的听众比例,测试结果B 表明能听清音频内容的听众比例,测试结果C 表明能正确找出对抗音频的听众比例。测试1 的实验结果表明大部分听众认为JMSA 和ZOO的对抗音频有明显的噪声,测试2 的实验结果表明听众基本都能听清音频的内容,测试3 的实验结果表明ABX 测试中BIM、C&W(L2)和PGD 正确找出对抗音频的听众比例接近50%,可以认为其对抗音频与原始音频无法被人耳区分。

表9 隐蔽性测试结果Table 9 Concealment test results %
上述实验结果表明,FGSM、JSMA、BIM、C&W、PGD、ZOO 和HSJA 这6 种生成算法都能生成针对端到端说话人辨认模型识别的对抗样本,实现逃避攻击,但只有BIM、C&W(L2)、PGD 能实现无法被人耳察觉的对抗音频。在无目标攻击时,HSJA 黑盒算法能达到白盒攻击的较好水平。在有目标攻击时,BIM 和PGD 白盒算法面对不同说话人音频都能很好地生成高置信度的目标对抗样本,ZOO 和HSJA黑盒算法只能对模型的薄弱目标生成对抗样本,但质量不高,对抗样本生成算法的实现会受网络结构的限制。
4 结束语
为探究语音领域的对抗样本,本文基于端到端说话人辨认系统对现有经典的对抗样本生成算法在音频领域进行实现与比较研究。实验结果表明:在无目标攻击时,各类对抗样本在白盒和黑盒设置下均能逃避说话人辨认系统的识别,在整体性能表现上,BIM 和PGD 在白盒设置下表现最佳,在黑盒设置下HSJA 表现较好;在有目标攻击时,BIM 和PGD同样具有很好的性能表现,但在黑盒攻击方面,ZOO和HSJA 在有目标攻击时均未能达到其作用在图像数据上的攻击性能表现。由于端到端说话人辨认模型存在安全脆弱性、实验数据局限于较短音频等问题,因此下一阶段将探索更具实际意义的语音对抗样本以及端到端说话人辨认的安全学习机制,提高深度学习模型防御对抗攻击的能力。
