基于云计算与物联网技术的数据挖掘分析
2021-06-10房悦
房悦


摘要:目前,物联网产生的繁杂的数据,缺乏有效的管理方法。云和集群技术提供了解决这些问题的思路。文章旨在建立数据挖掘与物联网的关系本文讨论了一种基于actors模型和物联网概念的数据挖掘算法的分布式执行方法。该方法允许将数据挖掘算法分解为参与者,并在分布式环境中执行。该模型将应用在物联网的集中系统(云计算)和分布式系统中提供数据分析。实验表明,文章所提出的模型提高了数据分析的性能,减少了终端设备和云之间的网络流量。
关键词:物联网;数据挖掘;模型;流量
中图分类号:TP311.13;TP391.44;TN929.5 文献标识码:A 文章编号:1001-5922(2021)01-0163-04
物联网(Internet of Things,loT)代表了下一代互联网,它包含数百万个节点,这些节点将代表从不同设备到web服务器的对象。它协调了计算机和通信的新进展,制造了因特网的改进。物联网识别和控制现有网络中的对象,为将物理世界直接混合到基于计算机的系统中创造机会,从而提高效率、准确性和经济效益
物联网中的数据可分为地址/唯一标识符、RFID数据流、位置数据描述数据、传感器网络数据、环境数据等。数据挖掘是从不同角度分析数据并将其压缩为有用信息的过程。它结合了从大数据中发现新的、创新的、有趣的和有用的模式,并应用算法挖掘隐藏的数据。图1显示数据挖掘的过程。数据挖掘使用了许多不同的术语,如数据库中的知识发现(KDD)、从原始数据中提取知识、模式分析和信息获取。任何数据挖掘过程的目的都是建立一个模型,该模型能够有效地预测或描述最适合它的大数据,并且还可以推广到新数据。
目前,物联网产生的繁杂的数据,缺乏有效的管理方法。云和集群技术提供了解决这些问题的思路。因此,数据挖掘和云计算技术的集成是非常现实可行的。
本文提出了一种针对不同物联网体系结构构建数据挖掘系统的方法。将数据挖掘算法表示为功能块序列和分布式计算模型。论文的结构如下:第一节将回顾物联网数据挖掘系统的体系结构。第二部分描述了一种通用方法,该方法允许将算法分解成模型上的块进行映射。第三部分描述了多层体系结构的实现方法。最后一部分讨论了将该方法的实验与结果分析。
1物联网数据挖掘系统的体系结构
目前。广泛用于解释物联网方法的物联网基本架构为三层结构:
其中,感知层是进行数据采集的底层,可以看作是硬件层或物理层;网络层(中间层)负责连接感知层和应用层,使数据能够在它们之间传递;应用层通常扮演提供服务或应用程序的角色,这些服务或应用程序集成或分析从其他两层接收的数据。
一些研究人员提议扩展这些层m,添加了新层,如图1所示。
接人网关层负责消息路由、发布和订阅,并在需要时执行跨平台通信;中间件层是底层硬件层和上层应用层之间的接口,负责设备管理、信息管理等关键功能,并负责数据过滤、数据聚合、语义分析、访问控制、信息发现等问题。
通常,应用程序和中间件层的实现都使用云计算技术。云提供可伸缩的存储、计算时间和其他工具来构建应用程序服务。在这种情况下,网络层负责连接物联网设备(如传感器、RFID、摄像头和其他设备)和云。它通过互联网产生很大的流量。这个问题的解决方案可以是Fog计算。雾将云扩展到更靠近产生和作用于物联网数据的设备。Fog节点提供本地化,因此支持低延迟和上下文感知,云提供全局集中。许多应用程序既需要雾定位,也需要云全球化,特别是对于分析和大数据。
为了构建物联网的数据挖掘服务,现行通常的方法是使用readmake云(如Azure机器学习)或大数据的数据挖掘系统。
微软Azure机器学习(Azure ML)为一个基于SaaS云的预测分析服务。它提供付费服务,允许我们进行一个完整的数据分析周期(获取数据、预处理数据、定义特征、选择和应用算法、评估模型、发布模型)。用户只能在Azure ML机器学习算法中应用:分类、回归、异常检测和聚类。用户只能添加机器学习市场上可用的算法。它包含可以通过Azure API发布集成的其他模块和服务。
Apache Spark机器学习库(MLlib)是ApacheSpark平台上可扩展的机器学习库。它由常用的学习算法和工具组成,包括分类、回归、聚类、协同过滤、降维,以及低级优化原语和高级流水线api。它有自己的MapReduce范例实现,它使用内存来存储数据(而ApacheHadoop使用磁盘存储)。它使我们能够提高算法性能的效率。用户可以通过自己的实现扩展一组机器学习算法。但是,用户应该在地图上分解算法,减少和其他Spark的特定功能。它极大地限制了数据挖掘算法的并行化能力。
Weka4WS是著名的开源数据挖掘库Weka(用于知识分析的Waikato环境)的扩展。扩展实现了支持WSRF网格中数据挖掘算法执行的框架。weka4ws允许在远程网格节点上执行其所有数据挖掘算法。为了支持远程调用,Weka库提供的数据挖掘算法作为Web服务公开,可以很容易地部署在可用的网格节点上。Weka4WS只能处理单个存储节点包含的数据集。然后将该数据集传输到要挖掘的计算节点。很遗憾,现在不支持此库(2008年7月的最新版本)。
这些系统在大型计算集群上的集中式云上运行良好。但是,它們不能用于将计算移近数据(例如,在雾节点上)。因此本文使用actors模型作为分布式计算平台来解决这个问题。
2分布式模型算法描述
本文使用了将数据挖掘算法表示为功能块序列的方法(基于功能语言原理)。在函数语言中的经典函
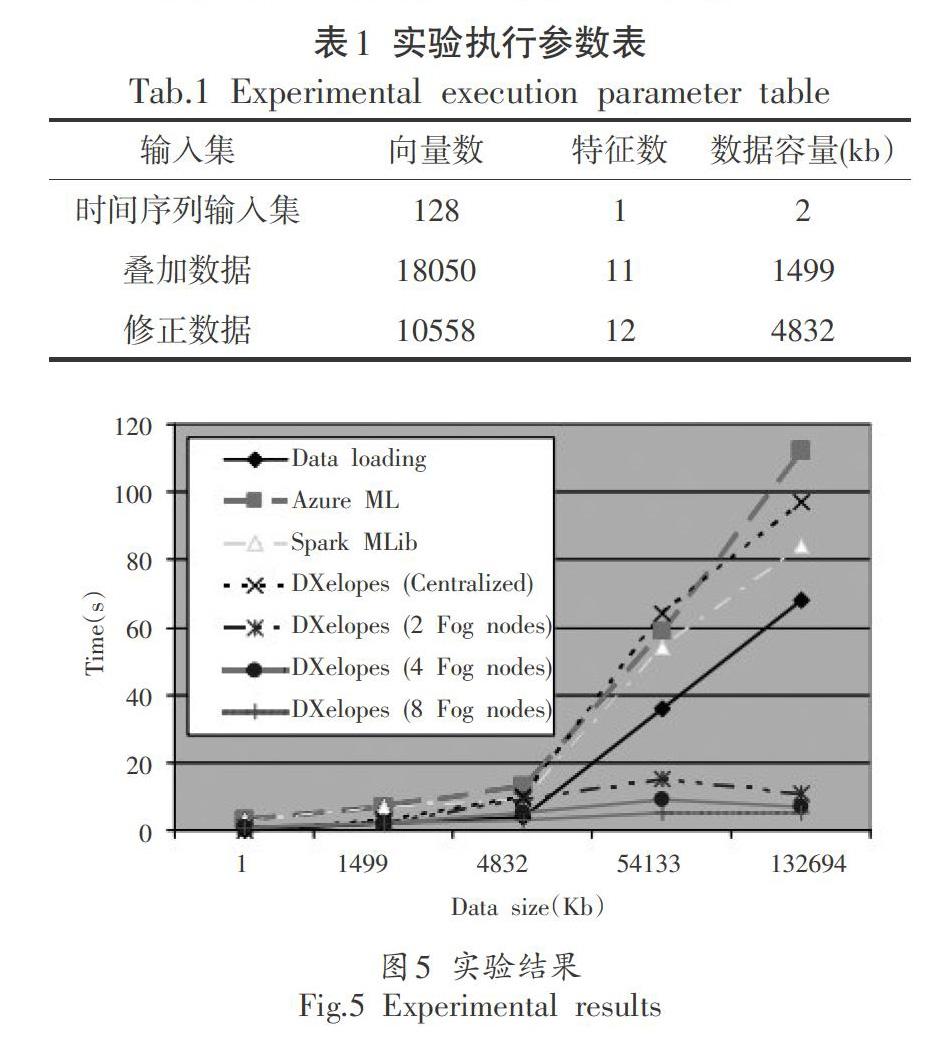
实验使用Azure ML中的数据集。其参数如表1所示。对于采用集中式架构的系统,我们将执行时间计算为数据加载和数据分析的时间。所有这些系统的数据加载时间设置为相同。对于采用分布式结构的系统,我们将数据集分为2、4和8个光纤陀螺节点。这些节点中的每一个都保存数据集的相等部分。
实验结果如图5所示,对于大型数据集(当数据量大于挖掘模型的大小时),基于actors模型(DXel.poes)的分布式体系结构物联网中的算与传统算法(Data loading、zure ML、Spark MLb)的执行时间更快,因为它不需要时间将数据加载到集中存储中。在这种情况下,向量的数量比数据量更重要,因为文件不通过网络传输,但向量是并行处理的。因此,采用分布式体系结构的物联网分析数据集更快。因此,将计算移近数据可以提高物联网系统的性能。
5结语
物联网可以采用集中式或分布式架构。大多数现有的物联网数据挖掘解决方案只能使用集中式体系结构。然而,分布式体系结构(Fog计算)由于能够减少大量终端设备在Internet上的网络流量而变得越来越流行。文章提出的方法使数据挖掘算法在不同的物联网体系结构中的应用成为可能。我们使用的方法是将数据挖掘算法分解为功能块,并将它们映射到参与者上。所提出的模型提高了数据分析的性能,减少了终端设备和云之间的网络流量。
