基于十字感受野网络的场景文本检测
2021-06-09赵朝阳杜晓杰张振清刘松岩郭海云王金桥
赵 旭,赵朝阳,杜晓杰,2,张振清,刘松岩,郭海云,唐 明,2,王金桥,2
(1.中国科学院自动化研究所,北京100190;2.中国科学院大学,北京100049;3.铁道警察学院,河南 郑州450053;4.云南大学 信息学院,云南 昆明650504)
0 引言
场景文本检测一般是指将文本目标按矩形框或倾斜矩形框的形式定位出来,是文本识别的前序步骤。主流的场景文本检测算法采用面向图像分类任务的卷积神经网络作为主干网络。本文认为,由于文本形状的特殊性,现有方法所采用的主干网络结构并不适用于场景文本检测任务。
一方面,图像分类任务中的物体一般不会像文本有极大的宽高比。因此,图像分类网络的卷积核一般是方形的,例如3×3大小。在文本检测任务中,目标往往占据一块宽高比悬殊的狭长区域。这时,直接沿用方形卷积核在神经网络的理论感受野中引入了背景噪声,也会加大有效感受野[1]的收敛难度。
另一方面,图像分类网络一般层数越深准确率越高[2-4],而本文认为由于文本目标的小尺寸特点,网络深度不宜过大,避免形成远大于目标尺寸的感受野。此外,文本检测网络的浅层网络层的宽度应该足够宽以容纳文本丰富的表观特征。
基于上述分析,提出了面向文本检测的十字感受野网络(CrossNet),有效提高了文本检测性能。
1 十字感受野网络
十字感受野网络(CrossNet)是一种根据文本检测任务特点设计的网络结构,可以整合进任何现有的文本检测方法中。本节对其搭建细节进行了阐述。
1.1 十字感受野模块
为了处理文本检测的目标形状与主干网络感受野不匹配的问题,本文提出了采用不同宽高比的矩形卷积核来搭建网络的基础模块,然后通过堆叠该基础模块组合成具备合适感受野的主干网络,优化文本检测器的性能。本文提出的基础模块为十字感受野模块(Cross-Receptive-Field Block,CrossRecepBlock),其结构如图1所示。模块内包含3个分支通路:一个跨层连接和两个由不同矩形卷积核(分别是3×1和1×3)开始的分支通路。通过堆叠CrossRecepBlock,可使神经网络通过选择不同模块的不同分支组合成多种感受野形状。
图1展示了3个面向神经网络不同位置的CrossRecepBlock。CrossRecepBlock-A是一般形式,CrossRecepBlock-B用来将特征图进行宽、高维度的降采样,来获得更大的感受野,CrossRecepBlock-C用来增加输出特征图的通道数。

(a) 残差模块 (b) 十字感受野模块-A (c) 十字感受野模块-B (d) 十字感受野模块-C图1 CrossRecepBlock结构示意图Fig.1 Proposed CrossRecepBlock
1.2 网络深度和宽度
本文认为分类网络中常用的深度、宽度设置并不十分适用于文本目标检测任务,有如下两点。
第一,用于文本检测任务的神经网络的深度不宜过深。在场景文本大多数目标都是小目标,即高度较小。适当深的网络层数可提高网络所提取特征的语义强度,而过于深的网络意味着较大的理论感受野,也意味着引入了过多的背景噪声来伤害最终的检测性能。实际上,一些文本检测[3,5-6]中的实验也表明了在主干网络从ResNet-50变为ResNet-101后,准确率并不提高。此外,在感受野较小的前几个网络阶段(Stage)设置更多的层数有利于小文本目标的检测。
第二,网络宽度就是每一层的通道数目,应该设置得足够大,特别是低层。网络的宽度与网络对样本变化的容量正相关。而场景文本通常在字体、颜色以及排版等底层特征上变化比较丰富。因而网络需要有足够的容量来处理这些变化。
1.3 CrossNet的结构细节
根据上两节的思考,本节搭建了针对文本检测任务的主干网络CrossNet,详细的网络的结构如表1所示。和ResNet的构成方式类似,CrossNet由CrossRecepBlock堆叠而来。CrossNet在输入侧有两个普通的卷积,用来将特征图空间分辨率下采样到原图边长1/4大小,在这两个卷积之后有8个CrossRecepBlock。

表1 CrossNet 网络结构示意
初始的两个卷积使得图像分辨率快速缩小,为了能保留更多细节信息,参考了AlexNet[7]和ResNet[4]中的设置,第一个卷积的卷积核采用了7×7大小。CrossNet在第一层卷积后采用了跨度为2的卷积层来进行下采样以保持更多细节。根据上面对于网络深度和宽度的讨论,4个网络阶段中CrossRecepBlock的数量设置为3、2、2、1。
1.4 基于CrossNet的文本检测算法
为了验证本文提出的CrossNet有效性,本节选取了当前性能较高的EAST算法,并用CrossNet作为EAST的主干网络,和其他主干网络对比,说明其有效性。图2展示了基于CrossNet的EAST算法,EAST算法是一种基于分割的场景文本检测算法,其在多个数据集上都有不错的表现。FOTS[8]的工作更是表明,通过丰富的数据扩增、大尺度训练图像尺寸等多种策略,EAST算法可以达到远超其他算法的最优水平。本文的主干网络和这些策略是兼容的。

图2 基于CrossNet的EAST算法结构示意图Fig.2 CrossNet based EAST text detector
EAST方法在主干网络之后添加了一个类似于特征金字塔结构(Feature Pyramid Networks,FPN)的模块,用于将不同层的信息进行融合。最后在融合后的最大空间分辨率特征图上,输出分类和回归两个任务的预测结果。
2 实验结果与分析
2.1 数据集及实验设置
本节在ICDAR2015数据集[9]上进行了实验。各个模型采用了统一的超参数设置。所有模型均在ICDAR2015和ICDAR2013的训练图像上训练,在ICDAR2015的测试图像上测试。除非额外说明,本节的实验均是将网络权重随机初始化后,从头开始训练的。
2.2 关键策略的有效性分析
为了验证CrossNet设计思路的有效性,在ICDAR2015上,对基于CrossNet的EAST的算法的各种结构变种做了一系列对比实验。同时,也对比了基于ResNet-50的EAST算法。
基础对比:表2对比了基于CrossNet的EAST文本检测器和基于ResNet-50的EAST文本检测器的性能。由表2可以看出,在参数量大致相同的情况下,CrossNet比ResNet-50提高了8.36%的准确率。为了对比FLOPS一致情况下的性能,将CrossNet每一层的通道数降为原通道数的1/2,得到0.5CrossNet。实验结果表明,0.5CrossNet依旧比ResNet-50高出3.86%,可见,CrossNet的结构在FLOPS和ResNet-50大致相同、参数量远小于ResNet-50的情况下,依然有明显的优势。这主要是由于本文提出的CrossRecepBlock使得网络可以学到更贴合文本区域的有效感受野,并且CrossNet有着更合理的深度、宽度设置,如图1所示。
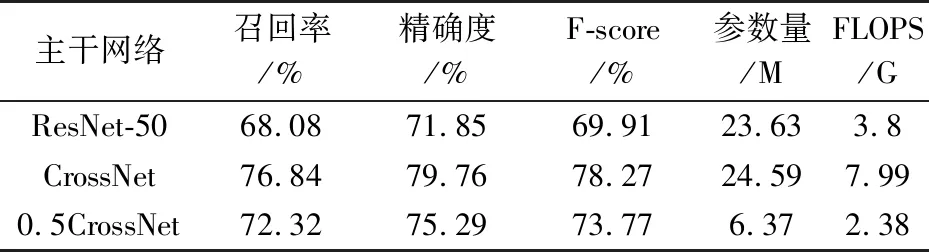
表2 ICDAR2015数据集上,采用不同的主干网络的评测结果比较
CrossRecepBlock对比:表3单独验证了CrossRecepBlock的作用。CrossRecepBlock中,最重要的部分是两个由矩形卷积核(3×1和1×3)的卷积分别开头的通路分支。这也是它和ResNet网络基础模块的区别。因而,将矩形卷积改成1×1的卷积,将这两个分支替换为ResNet的1×1-3×3-1×1单分支,同时保持每一层的通道数和对应的CrossRecepBlock一致,形成用残差网络基本模块搭建的CrossNet-ResNet’,来对比两种模块的性能。由于0.5CrossNet在FLOPS上和ResNet-50更接近,并且显存占用和速度上更高效,本组实验采用了0.5CrossNet进行修改和对比。实验结果表明,0.5CrossNet+ResBlock’比0.5CrossNet低了2.16%,而二者的参数量和FLOPS相似。所以,CrossRecepBlock中的矩形卷积核在文本检测主干网络中十分重要。
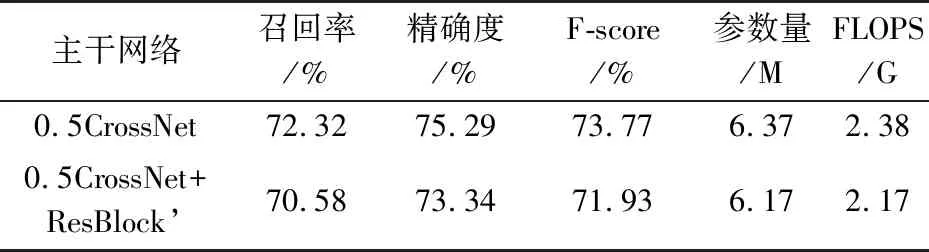
表3 ICDAR2015 上,采用不同基础模块搭建主干网络的评测结果比较
网络深度对比:表4验证了上文中关于文本检测主干网络的深度不必要太深的观点,并列举了 CrossNet和ResNet不同深度时的检测性能。为了避免显存不足,本组实验将ResNet和CrossNet的每层通道数砍至原网络1/4、1/2进行实验。首先,0.5CrossNet-double-D是把0.5CrossNet的每个网络阶段的CrossRecepBlock数翻倍,使得网络总深度也翻倍。由此可以看出,深度翻倍后,F-score略有提高,但是相对CrossNet比0.5CrossNet的提高要少很多。
为了说明结论的一般性,表4在ResNet上进行了对比实验。其中,0.25ResNet-50-half-D代表将0.25ResNet的每个网络阶段的模块数砍一半后得到的网络,该网络相对0.25ResNet-50有略微降低,但也不多,和CrossNet上的结论类似。而继续将0.25ResNet的每个网络阶段的模块数翻倍,得到0.25ResNet-50-double-D,实验结果表明,深度变深后,F-score反而有很明显的降低。为了说明这不是由于每个网络阶段的模块数配置不合理导致的,本文还评测了参数量和深度与0.25ResNet-50-double-D差不多的0.25ResNet-101网络,0.25ResNet-101比0.25ResNet-50-double-D略好,但仍比0.25ResNet-50差。并且,需要指出,这不是由于参数量大带来的过拟合导致的,因为ResNet-50、CrossNet比本组实验的100层左右的网络(0.25ResNet-50-double-D,0.25ResNet-101)参数量大很多,但是有着远远高于这些网络的评测得分。

表4 ICDAR2015 数据集上,采用不同的主干网络深度的评测结果比较
网络宽度对比:由表5可以看出,不管是CrossNet结构还是ResNet结构,增大网络宽度(即网络每层特征图通道数)可以明显增强检测器性能。

表5 WICDAR2015 数据集上,采用不同的主干网络宽度的评测结果比较
2.3 与其他算法的准确率比较与分析
本节在ICDAR2015数据集上将基于CrossNet的文本检测算法和当前最优算法进行对比。为了进一步提高性能,还将主干网络CrossNet在ImageNet上进行了预训练。
基于不同主干网络的EAST算法在ICDAR2015数据集上的评测结果如表6所示,可以看出在ImageNet数据集上预训练之后再在文本检测数据集ICDAR2015上训练的模型EAST-CrossNet-Pretrain达到了82.5%的F-score。这表明,尽管CrossNet不是针对分类任务设计的,在ImageNet上预训练依然可使其获得更好的初始化权重,相比随机初始化提升了4.23%。值得一提的是CrossNet可以用在其他任何文本检测框架中,表6中所有基于深度学习的方法都可以将其主干网络替换为专门针对文本检测任务设计的CrossNet来获得进一步提高。

表6 ICDAR2015数据集上,多种方法的评测结果比较
2.4 可视化分析
图3对比了基于CrossNet的EAST[11]文本检测算法和基于ResNet-50的EAST算法各自训练完毕后形成的有效感受野。其中,有效感受野是指在网络预测层上对应原图红点位置处的有效感受野,可视化采用了文献[13]的方法。有效感受野利用文献[13]的方法进行可视化。通过图3可以看出,基于CrossNet的EAST方法感受野比基于ResNet-50的EAST方法的感受野更好地聚焦在文字区域上。

图3 基于ResNet-50和CrossNet时的两种EAST方法有效感受野对比Fig.3 Visualization of effective receptive fields of EAST based on ResNet-50 and the proposed CrossNet respectively
3 结束语
本文提出了一种针对文本检测任务设计的主干网络结构,即CrossNet。首先设计了CrossNet的基础模块“CrossRecepBlock”。 CrossRecepBlock包含3个卷积通路,其中两个通路中包含了不同形状的矩形卷积核的卷积层,通过堆叠此模块,可以使搭建的主干网络形成更贴合文本区域的感受野。之后讨论了关于文本检测主干网络的宽度和深度的设置策略,发现主干网络应该足够宽但不宜太深。基于上述两种策略,搭建了CrossNet。实验结果表明,CrossNet相比当前普遍采用的针对图像分类任务设计的主干网络更适合文本目标检测任务,在同等参数量或同等计算量条件下均比图像分类网络有显著的准确率提升。
