基于集成学习算法的恶意软件感染二分类预测
2021-06-03张银杰揣锦华翟晓惠
张银杰,揣锦华,翟晓惠
(长安大学 信息工程学院,陕西 西安 710064)
0 引 言
集成学习算法是近些年来较为流行的基于树的机器学习方法[1],常用于数据挖掘领域的分类或回归预测任务[2-4]。在此背景下,该文选择kaggle平台的开源数据集,对计算机感染恶意软件这一主题进行二分类预测,以探究集成学习算法在网络安全相关的多维数据预测过程中的应用[5]。主要关注集成学习在特征选择与预测模型建立中的实际运用。对原始数据进行预处理,提出利用原有特征进行时间戳特征的构建使得原数据在时间上有序,也为数据集提供了时间维度的特征。
如何尽可能地展现出原数据集中的有效信息并建立二分类模型,实现对计算机是否感染恶意软件的预测目标是该文研究的主要内容。
1 数据认知与预处理
1.1 数据认知
文中数据来源于kaggle开源数据集,记录了千万台Windows计算机的信息,包括计算机所属地理区域、硬件、防卫软件、操作系统设置等多维信息,共计82个属性。预测标签为属性HasDetections,其包含两个数量相当的类别0和1,当其数值为1时表示感染恶意软件,为0时表示未感染恶意软件。为探究集成学习算法在本数据集上的分类预测作用,采用前200万条数据进行研究。
原始数据集存在大量属性字段,经过初步的数据探索性分析[6],发现属性字段不同值对预测标签的影响是不同的。例如图1为Census_OSInstallTypeName字段属性值HasDetections率的分布。该字段共包含九个类别值,每个类别值的数量如图中条形图所示,感染恶意软件的概率用折线图表示,可以看出类别之间的感染率存在着差异,部分安装类型下感染率明显超过了0.5均值,说明通过这些安装方式安装操作系统的计算机更容易感染恶意软件。通过对所有属性列的分析,证明了对该数据集进行分类预测的可行性。
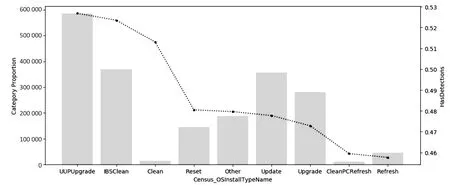
图1 不同操作系统安装类型下“HasDetections”率分布
1.2 数据预处理
原始数据集中需要进行初步的数据清洗。例如,类别型字段SmartScreen,该字段记录了注册表中SmartScreen的字符串值,该值的设置影响防卫软件的部分防卫功能。在原始数据集中该字段含有如“Off”、“off”、“OFF”含义相同的类别值,经处理后合并为同一类。
通过以上过程,对所有类别型字段进行标签编码以简化数据。数据集中的数值型字段存在部分不符合常理的异常值,如标识显示器尺寸的数值字段存在负值和0值,负值剔除负号,0值直接视为无效信息,并以该字段众数填充。对于布尔型字段,则确保有效值只有0和1两个变量。
2 特征工程应用
2.1 初始特征构建
特征工程(feature engineering),是一系列与特征相关的工程活动的总称。其作用是尽可能地在原始数据基础上挖掘出适合于预测模型的特征。文中的特征从原始数据的各属性列提取,预处理阶段将原始数据集转换为模型可以输入的格式后,需进行特征工程以调整特征数量,有助于模型发挥更好的预测性能。
将文中使用的数据集中所有的字段转换为原始特征,共计53个类别型特征(如特征CityIdentifier,反映计算机所属城市的标识),10个数值型特征(如特征AVProductsEnabled,数值表示可以使用防卫软件数量),18个布尔型特征(如特征Census_IsTouchEnabled,用0或1变量表示是否为可触屏设备)。
2.2 时间戳特征的构造
数据集中的每一台计算机信息是微软公司于2018年抽取的真实计算机脱敏数据。按照传统思维,软件版本越新,对恶意软件的防卫就越强,计算机感染恶意软件概率就越低。为构造出更能反映时间差异信息的特征,该文对AppVersion、AvSigVersion、Census_OSVersion三个含有时间信息的特征进行拆分。例如AppVersion代表防卫软件APP版本号(例如4.18.1807.18075)由四个数据组成,其中第二、第三、第四个数字具有版本信息差异,因此对原特征拆分,得到新的三个拆分特征,如AppVersion2代表版本号的第二个数字,文中此特征为18时代表相关软件已更新到最新版本。同理基于AvSigVersion的第二、第三个数字和Census_OSVersion的第三、第四个数字得到4个新的拆分特征。共计得到7个拆分特征。
此外,设计了如表1所示的三个时间戳特征,用版本最新号减去相应版本信息,以衡量不同计算机之间的软件版本差异。表中AppVersion2_3指APP版本号第二和第三个数字的小数组合,AvSigVersion2_3指防卫软件sig版本号第二和第三个数字的小数组合,Census_OSVersion3_4指操作系统版本号第三和第四个数字的小数组合。

表1 时间戳特征的构建
以上时间戳特征可以确定计算机防卫软件或操作系统与最新版本的差异程度。在对时间戳特征不同区间下的HasDetections率变化分析过程中发现,防卫软件版本的差异确实会影响计算机感染恶意软件的概率。例如特征lag1在1~5区间内HasDetections率只有30%~40%,明显低于所有区间的感染平均值50%。
经过时间戳相关特征的构造,文中数据集的特征数达到91个。
2.3 集成学习在特征重要性分析中的应用
对上述过程构建的所有特征进行重要性分析,以判断每个特征是否与最终的预测标签相关。集成学习算法可以快速地判断每个特征与预测标签的相关性,并给出每个特征的重要性分数。该文选择随机森林算法评价特征重要性[7]。
随机森林是多重决策树算法集成组合的算法,内部决策树由随机特征构成的决策树生成,最终预测结果综合考虑各个决策树的预测结果确定,解决了单个决策树经常产生的过拟合问题[8]。在处理分类问题时,随机森林采用大部分决策树选择的分类结果[9]。在不需要设置过多的超参数的基础上,随机森林即可判断各个特征与预测标签的相关性。将文中的91个特征与预测标签HasDetections作相关性分析,在总特征分数为100的前提下,得到各个特征的重要性分数,如图2所示。
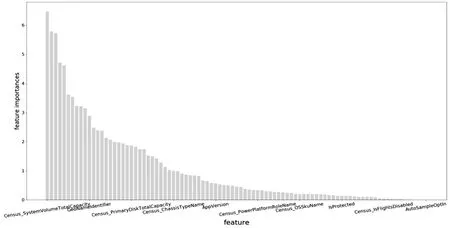
图2 随机森林算法计算出的特征重要性分数
由图2可见,绝大部分原始特征和文中新构建的特征都与预测标签有相关性,但是重要性分数参差不齐,说明每个特征的影响程度有所差异[10]。在上文中构造的两个新特征,包括拆分特征AvSigVersion3与时间戳特征lag2都有较高的分数,在91个特征中排到了前5位,其余新构建的特征也都有一定的重要性,说明文中新特征的构建是有效和合理的。分数最高的前5位特征还包括硬盘总容量、处理器型号以及SmartScreen字符串值三个特征,这也为恶意软件的防范提供了启示。另外,有4个特征的特征重要性为0,说明其与预测标签无相关性。后文中将依据特征重要性分数讨论特征数量对预测模型的影响。
3 集成学习在二分类预测中的应用
3.1 分类算法及分类模型评估指标
3.1.1 二分类算法
二分类算法的实现是机器学习的一大重要应用。二分类算法通过自我训练按照一定的规则将所有样本分为两类,从而可用于未知类别数据的预测。构建分类算法需要借助训练集与测试集,训练集负责分类模型的建立过程;测试集负责对已建立的模型进行测试,将得到的预测结果与实际结果相比对,并借助相关指标判断模型的准确性。
决策树属于常见的分类算法,基本的有ID3、CART算法等。集成学习算法包括随机森林、GBDT、Lightgbm、Xgboost算法等。这些算法的集成方式包括Bagging和Boosting两种,基模型都是决策树模型,近些年来集成学习模型在机器学习领域应用较为广泛,其中部分也常用于数据挖掘中的二分类预测[11]。
3.1.2 二分类模型评估指标——ROC曲线与AUC值
在二分类模型中,可将所有样本划分为正样本和负样本。该文将感染恶意软件的计算机标注为正样本,未感染恶意软件的计算机标记为负样本。
ROC曲线(receiver operating characteristics curve)和AUC(area under curve)现在常用于评估机器学习模型的性能。ROC曲线依靠假正率和真正率两个指标形成,两个指标含义如下。
ROC曲线横坐标为假正率,假正率(FPR)公式如下:
其中,FP是被模型错误预测为正类的负样本数量,TN是被模型正确预测为负类的负样本数量,两者之和为负样本总和。
ROC曲线纵坐标为真正率,真正率(TPR)公式如下:
其中,TP是被模型正确预测为正类的正样本数量,FN是被模型错误预测为负类的正样本数量,两者之和为负样本总和。
假正率和真正率在不同的阈值下形成不同的ROC空间点,最终标注点连接形成ROC曲线。形成的ROC曲线代表一个分类器的性能。在大多数情况下,ROC曲线经过(0,0)和(1,1)并在两点连线之上。
AUC指的是ROC曲线下的面积。对于一个分类器来说,其ROC曲线越趋向于左上角,则其AUC值越接近于1。AUC较ROC曲线有更直观的数值表达方式,也不受ROC曲线中阈值的影响,因此该文采用训练集与测试集的AUC值作为评估二分类模型的主要指标。
3.2 基于集成学习的预测模型的建立
3.2.1 基于LightGBM的预测模型
LightGBM是一种基于Boosting集成的方法,内部各个基学习器顺序学习,后续学习器的算法重点关注前面算法的错误[12]。作为一种分布式梯度提升框架,LightGBM算法具有运算速度快,支持直接输入类别特征的优势。将前文中得到的91特征数据集划分为训练集与测试集,训练集与测试集的划分比例为1∶1。将训练集输入LightGBM算法训练,建立预测模型[13]。在Python的sklearn环境下,设置算法参数n_estimators为3 000,colsample_bytree设置为0.2,其余参数保留默认值。
最终得到的训练集与测试集的ROC曲线如图3所示。从图3可以看出,测试集的AUC值达到0.73,虽然低于训练集的AUC值0.78,但过拟合程度并不严重。说明通过LightGBM算法实现数据集预测恶意软件感染的可行性。
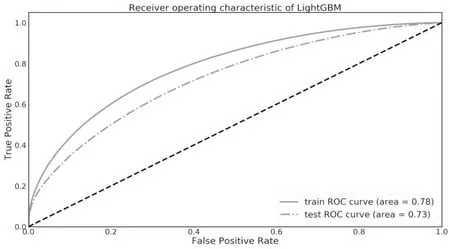
图3 LightGBM算法下的训练集与测试集ROC曲线
3.2.2 基于随机森林的预测模型
随机森林算法是一种基于Bagging集成的方法,内部各个基学习器互不影响,在训练时并行化处理。在分类建立预测模型的过程中,算法内部的每棵决策树的构成过程都会随机选取特征与样本,最后采用投票决定最终的分类结果。这使得随机森林是高度泛化的集成学习模型。在默认参数下使用训练集建立随机森林分类预测模型,得到训练集与测试集的ROC曲线,如图4点划线所示。可以看出,默认参数下生成的随机森林预测模型过拟合严重,训练集的AUC值已近似于1,测试集AUC值为0.66。为提高预测模型的泛性,需对随机森林算法进行调整,以降低过拟合现象[14]。
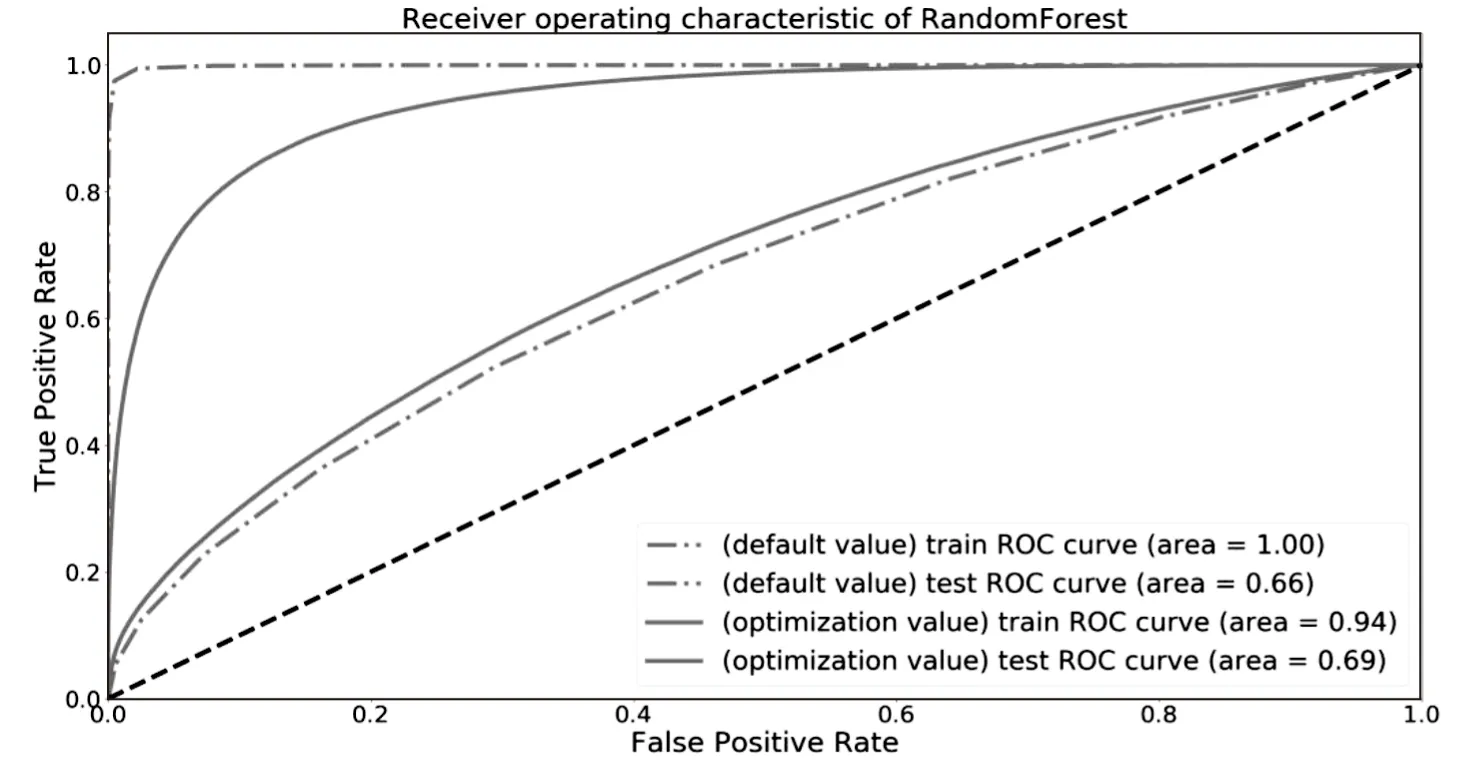
图4 随机森林算法下的训练集与测试集ROC曲线
对随机森林算法参数进行设置,降低树最大深度max_depth至3 000(默认为None),调大节点再划分所需最小样本数min_samples_split与叶子节点最少样本数min_samples_leaf分别至3和5(默认值为2和1)。再次训练并测试得到训练集与测试集ROC曲线如图4中实线所示。实线反映训练集AUC降至0.94,但测试集AUC提高至0.69,说明参数调整降低了过拟合现象,提高了对测试集的预测能力,使模型对非训练数据的预测能力增强。
3.3 数据集的降维处理
过多的特征会影响算法的执行效率。前文中已通过随机森林算法得出91个特征的重要性分数,本节旨在保证预测精度的前提下,尽可能地减少使用的特征[15]。按照特征重要性分数划定不同的阈值,对阈值以下分数的特征予以剔除,按照不同的阈值划分为不同的特征集。使用随机森林算法训练不同的数据集并进行测试[16]。每次模型构建过程中,训练集与测试集的划分方式相同,得到随机森林算法测试集AUC随阈值变化曲线,如图5所示。
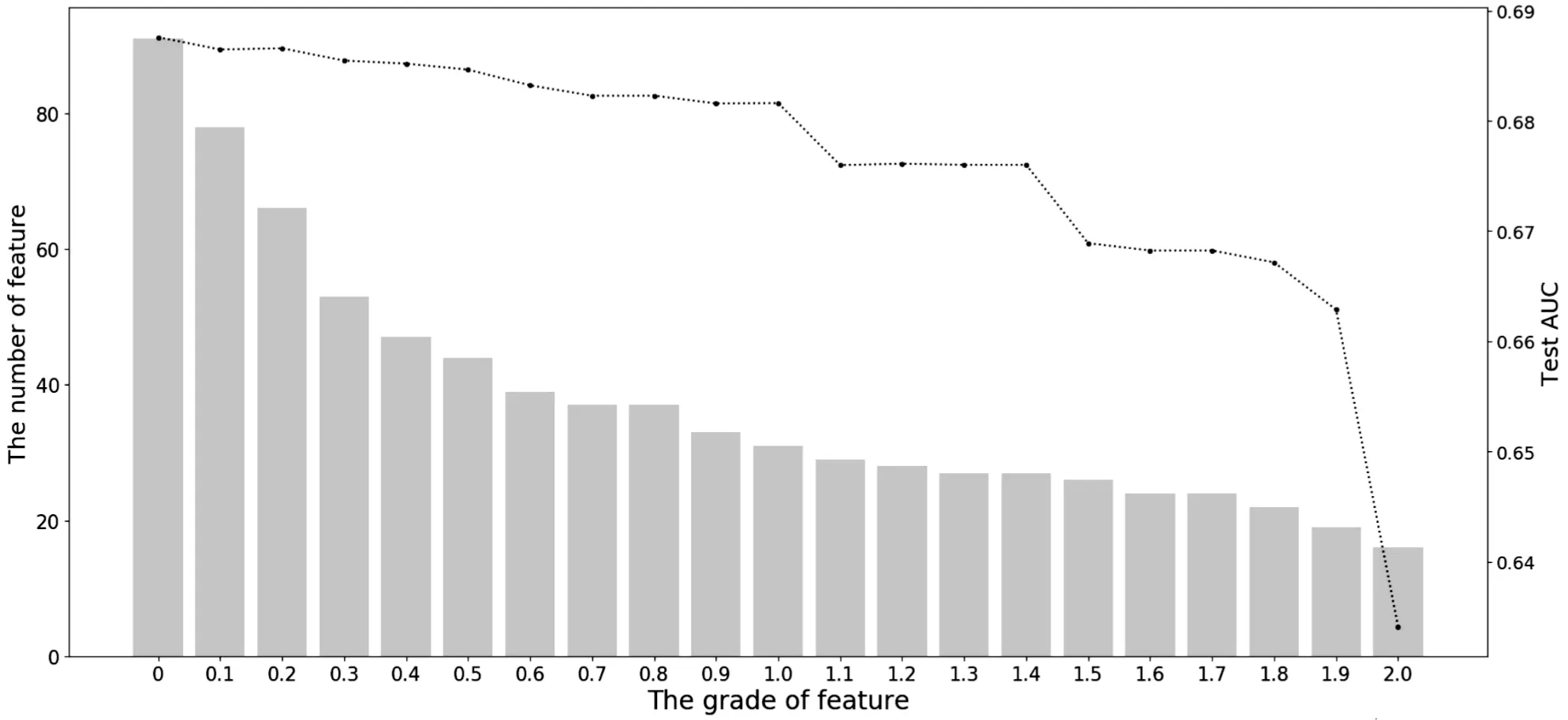
图5 不同分数阈值下特征数目与测试集AUC变化
图5显示在特征分数的阈值设置在1.0以下时,AUC值变化较为平缓。阈值在1.0以上时,特征数目的减少使AUC值明显降低。说明重要性分数在1.0以上的特征对于预测模型的构建较为重要。最终将特征分数的阈值设定为1.0,此时特征数目为31,大幅降低了特征数量,提高了算法运行效率,最终预测结果也没有受到过多影响。
3.4 集成学习与传统决策树算法的对比
通过基于Boosting集成的LightGBM算法和基于Bagging集成的随机森林算法形成的预测模型,其结果表明训练的模型可用于恶意软件感染结果的预测。为验证基于树的集成学习算法相对于传统决策树的优势,该文分别选择基尼系数和信息熵作为目标函数建立决策树算法与集成学习算法作预测结果对比。
在Python相关机器学习包环境下[17],将含有31特征的数据集分别输入四种算法进行完全相同的五折交叉验证,即将数据集划分为大致相同的五部分,依次选择其中一部分作为测试集,其他四部分作为训练集,得到各算法五折交叉验证测试集AUC值的对比如表2所示。

表2 四种算法五折交叉验证测试集AUC对比
从表2的对比结果来看,两种集成学习算法在五折交叉验证的测试集AUC值均高于传统决策树的结果,集成学习算法中LighGBM的AUC值普遍高于随机森林,说明其在该数据集上预测效果更好。集成学习算法解决了树模型算法经常出现的过拟合现象,提升了预测模型的泛化能力。表中数据也反映了对于处理这种含有多维数据集的预测问题,更适合于集成学习算法建立分类预测模型。
4 结束语
将集成学习算法应用到恶意软件二分类预测上,集成学习算法可以得到特征重要性以筛选最合适的特征数量,其次证明基于集成算法建立的预测模型的预测效果明显好于传统决策树算法。此外,考虑到实际的预测问题,借助数据集解决了对恶意软件感染这一主题的预测过程,在特征选择过程中,考虑特征拆分与构建时间戳特征以增加时间维度的信息,根据AUC值确定合适的特征分数阈值以减少特征数量。但该文考虑两种算法已是高度集成的机器学习算法,未进行合适的模型融合以进一步提高预测效果,期望后续进一步的研究与扩展。
