基于图的多层次注意力事实验证算法
2021-05-26谢艺菲胡亚豪潘志松
谢艺菲,卢 琪,刘 鑫,胡亚豪,潘志松,陈 浩
陆军工程大学 指挥控制工程学院,南京210001
随着社交媒体的兴起,网络上发布的内容都会接触到数万读者,这给互联网舆论监管带来巨大挑战。构建一个高效且自动化的模型来评估网络信息的真实性对于政府监管舆论导向具有重大研究价值。越来越多的研究者开始关注文本的事实验证(Fact Verification),该任务旨在从语料库中验证给定声明的真实性。
事实验证任务与文本蕴含(Textual Entailment)[1]和自然语言推理(Natural Language Inference)[2]不同,后两个任务都给定了验证声明的证据文本(通常是一个句子)。但在事实验证任务中,证据可能分散在不同的文章中,需要从庞大的语料库中检索。如图1 所示,给定一个声明,事实验证模型预测验证标签是“证实”“驳斥”或“信息不足”。

图1 事实验证数据样例
目前,BERT[3]、XL-Net[4]、Roberta[5]等预训练模型的出现,使得文本理解能力大大提升。虽然现有的模型近年来不断优化,但如何将这些强大的编码器应用到具体任务中,仍然是待解决的问题。首先,在事实验证任务中细粒度语义辨析至关重要,因为即使声明的语义和语法都正确,但个别词语替换,就会使得声明与事实背离。其次,在仅靠单句单文本无法验证的场景中,现有模型仍缺乏跨句子跨文本的推理能力。当前一些研究将所有检索出的证据简单拼接,但是忽略了细粒度语义的辨析以及分散的证据之间的关系,这些对于理解证据的关系结构和推理过程是至关重要的。
针对事实验证中的上述问题,本文提出了一种基于图的多层次注意力模型(Graph-aware Hierarchical Attention Networks for Fact Verification,GHAN)。该模型采用卷积神经网络(Convolutional Neural Network,CNN),使用不同的窗口长度提取多层次的细粒度信息,并通过高斯核函数计算得到多层次的相似度软匹配特征,可以辨析细粒度的语义。该模型还构建了证据信息全连接图,充分利用了字符和句子级别注意力更新节点表示推理证据信息。所提出的模型可以充分利用多层次细粒度信息来验证声明。
本文的主要贡献如下:(1)提出一种新的基于图的多层次注意力模型,该模型充分利用了多层次的匹配特征进行建模;(2)该模型可以很好地利用不同尺寸的卷积核提取不同粒度的特征,并且通过不同的高斯核获得不同层次的匹配特征,有效地捕捉了证据和声明之间的语义关系;(3)模型在FEVER[6]测试集上的准确率为73.96%,FEVER分数为70.54%,在该任务中效果优于已知的基于BERT的预训练模型。
1 相关研究的概况
近年来事实验证任务不断演化更新,Valchos等人[7]在2014 年率先构建了政治领域的事实验证数据集,但只包含221条声明;2017年Wang等人[8]将此数据集扩展为1.28 万条政治声明,数据来源于政治辩论、电视采访等。Pomerleau等人[9]发起虚假新闻挑战,给定一项声明和一篇文章,预测该文章是否证实、驳斥、中立或与该声明无关,数据集由300条声明和2 582篇文章构成5万条声明与证据对。本文采用Thorne 等人[6]在2018 年提出的FEVER 数据集,它是目前最大的事实验证数据集。其验证证据从Wikipedia 文档库中检索获取,并且需要结合多篇文档的信息。
目前事实验证的处理方法主要是先用检索的方法获取证据,再通过句子之间的相似度对比证据和声明之间的关系。Zhou等人[10]检索出声明相关的证据,然后将预训练模型BERT训练出的词向量取出作为特征,作为句子的表示,进行推理验证,该方法BERT的参数固定,模型仅学习推理的参数。Zhong等人[11]利用更细粒度的信息,从证据中提取出语义图,然后用XL-Net预训练模型编码,效果得到一定提升。
预训练模型的出现极大地减轻了研究人员在自然语言处理任务中的工作。由于词向量无法解决一词多义的问题,Μattew等人[12]首次利用大量语料构建了一个基于多层的双向LSTΜ的ELΜo模型,能够对词语进行上下文相关的表示,从而解决一词多义的问题;Radford等人[13]改进网络结构,利用大型语料库构建基于自注意力机制的单向GPT模型;GPT仅考虑了单向语义信息,但是自然语言处理领域中上下文的双向信息对于各个文本任务是至关重要的,于是Jacob等人[3]将单向网络改进为基于Transformer[14]构建了双向的预训练语言模型BERT,使用更细粒度的词语表示,训练更多语料,得到预训练模型,并在多个NLP任务中性能得到了极大的提升,开创自然语言处理领域的新纪元。
在证据检索操作过程中,Chen 等人[15]、Hanselowski等人[16]采用增强的序列推断模型(Enhanced Sequential Inference Μodel,ESIΜ),利用双向LSTΜ 网络对句子编码,通过句子对之间的交互提取语义特征进行匹配。由于Wikipedia中的每篇文章都针对某个特殊实体的相关知识描述,故Nie 等人[17]在ESIΜ 基础之上,加入了Cucerzan等人[18]提出的实体链接的方法,在声明中识别实体,并将其链接到Wikipedia 知识库抽取出证据。在信息检索领域,Huang等人[19]、Shen等人[20]、Palangi等人[21]通过建立门控网络等方法验证查询与文档的相关性,仅考虑句子级别相似度,缺乏对不同维度相关性的捕捉。因为卷积神经网络有助于模型学习细粒度的相似度特征,所以Hui 等人[22]、Dai 等人[23]将卷积神经网络用于信息检索中的排序,并且得到了较好的效果。信息检索领域的方法有效地启发了事实验证任务中对证据的检索[24],但检索模型仅仅能对证据做初步筛选,无法完成关系的推理和细粒度的验证。例如“Stranger Things is set in Bloomington,Indiana.”和“…Set in the fictional town of Hawkins,Indiana.”两句话语义相关可通过检索得到,但是前者不能由后者推理得出。直接将检索模型用于事实验证过程缺乏多层次的相似度特征,得到的验证结果存在偏差。
在自然语言推理验证相关任务中,模型需要捕捉证据之间的关系和逻辑信息进行推理。Zhong等人[25]设计多粒度的神经网络,利用不同粒度的注意力模拟推理过程。由于图结构更符合人类做推理时的逻辑,能够改进长距离上下文或跨文档的信息交互,利用分散在不相交的上下文中的线索进行推理,从而深刻地理解文本的语义,于是Qiu等人[26]、Lv等人[27]、Cao等人[28]、Zhao等人[29]使用不同构图方法将非结构化文本转化为结构化的图表示,对图节点进行编码,然后采用图神经网络[30](Graph Neural Network,GNN)、图卷积网络[31](Graph Convolution Network,GCN)、图注意力网络[32](Graph Attention,GAT)等方法融合篇章的推理信息。这些推理的方法在机器阅读理解领域已经得到广泛应用,受到这些方法的启发,GHAN 在事实验证任务中用GAT 进行证据之间的信息更新,便于模型的推理验证,并利用卷积操作得到多层次的相似度特征,从而获得推理验证的结果。
2 模型与方法
模型首先从Wikipedia 中检索候选文章,再从这些文章中筛选出5条证据句子,通过验证模块融合证据与声明的语义信息,来得到验证结果。图2为流程图。

图2 总体流程图
事实验证的步骤主要由证据获取和推理与验证两部分组成。
2.1 证据获取
考虑到语料库中的文档数量巨大,如果想按精确语义匹配来寻找相关文档将会花费很大的计算代价。因此,本文首先粗糙地筛选以缩小检索范围,再用ESIΜ模型匹配,得到候选文章之后,用BERT 句对模型筛选出最终的证据。证据获取部分由检索文章模块、筛选证据句模块构成。
2.1.1 检索文章模块
采用关键词匹配缩小检索空间,即选择文章标题与声明中的片段完全匹配的文章(除首字母大写外,其余都是对大小写模糊匹配)。但是语料中有约10%的文章标题所提供的信息并不清晰,比如“Hotel”是一部电影名称,同时也是酒店名称,这就很难仅靠字面的匹配来检索。对于模棱两可的题目,将其与文中第一句话拼接之后再用NSΜN 模型打分,与Nie等人[17]采用的方法类似。最终每个声明检索出10篇得分最高的文章。
2.1.2 筛选证据句模块
根据声明信息与候选文章之间的语义关联,从以上10 篇文章中筛选出5 条证据。将声明与文章中的句子拼接,送入BERT 模型。最后一层输出的第一个字符[CLS]汇聚了输入句子的语义信息,模型使用一层全连接的前馈网络以及一个softmax 层,从而得到候选证据的匹配得分:

其中,hCLS是[CLS]的向量表示,最终获取得分前5 的证据作为事实验证的依据。
2.2 推理与验证
由于从Wikipedia 筛选出来的证据有噪声,故在设计模型的优化目标时,不仅要考虑验证声明的标签,也要考虑每条证据作为正确推理依据的概率。
模型将每个声明和每条证据组成声明-证据对,把声明-证据对视为节点,构建全连接的证据图。于是,每个节点Ni作为正确推理依据的概率P(Ni),与基于图注意力更新的预测分类标签y 的概率P(y|Ni)相乘,即根据每个节点的重要程度对节点的预测值加权,这S 条证据的预测之和记为该声明的验证得分Z :

与Liu 等人[24]的方法不同,首先在词嵌入层将证据与声明嵌入至统一的向量空间中。计算Ni作为正确推理依据的概率时,卷积层使用卷积神经网络产生不同的N-gram 特征序列,匹配层生成不同特征之间的相似度矩阵,然后通过核池化(Κernel Pooling)获得相似度特征,生成注意力权重,实现软匹配[33]。计算预测分类标签y 的概率P(y|Ni)时,先构建信息融合图,通过字符级和句子级的注意力更新信息,最终得到推理与验证的概率。模型的整体结构如图3所示,图中只示意了长度为1和2的卷积核,节点数为3。
推理与验证模块由声明与证据的表示、证据被选择的概率以及结合图全局信息的标签预测三部分构成。
2.2.1 声明与证据的表示
将声明和证据标题以及证据句拼接分别送入BERT,得到基于声明与证据信息相互融合的表示,也作为信息融合图的节点表示。第i 个声明证据对的表示为:
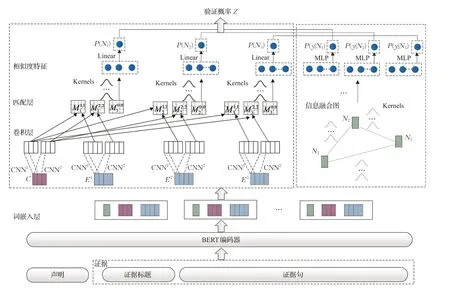
图3 GHAN模型示意图
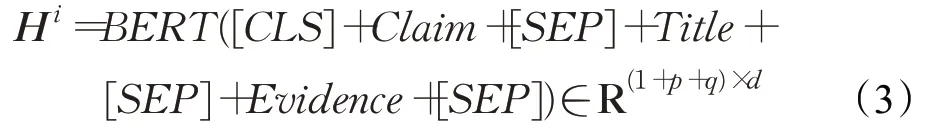
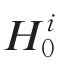
2.2.2 证据被选择的概率
模型通过声明与证据之间的语义相似度得到该证据被选择用于支撑声明验证的概率,即该证据重要性的度量。下面按照基于卷积神经网络的核注意力、匹配层和核池化层三部分进行介绍。
(1)基于卷积神经网络的核注意力

使用F 个卷积核得到F 个标量,每一个标量描述了窗口不同维度的信息[33],然后加偏置项和非线性激活函数f 得到F 维的h-gram嵌入:

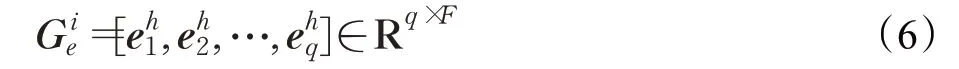
(2)匹配层



(3)核池化层
转移矩阵描述了不同粒度字符间的相似度量,核池化层将不同的核作用于转移矩阵提取相似度特征。模型利用K 个高斯核,每个kernel记为Kk,均值μk,宽度σk,不同的核提取到的语义信息层次不同:
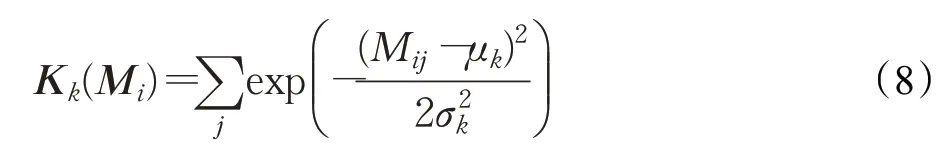
将K 个核应用于转移矩阵的第i 行,可得到K 维的特征向量:

对K 维特征取对数求和得到C 对Ei的相似度特征:

对所有转移矩阵的软匹配的相似度特征拼接,得到Φ(Μ)∈R3K:

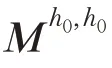

最后采用softmax归一化得到证据被选择的概率:
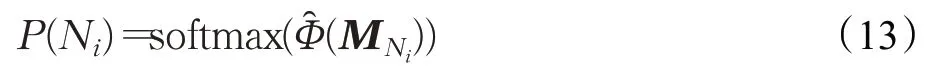
2.2.3 结合图全局信息的标签预测
标签预测的关键是综合考虑证据之间的关系,与Zhou[10]和Liu[24]等人做法相似,本文用字符级别的注意力生成节点表示,句子级别的注意力沿着图中的边更新信息,注意力是基于核计算得到的。
(1)字符级别的注意力
对节点N1和其邻居节点N2,根据两条证据的原始表示构造转移矩阵M ,记节点N1经过BERT编码表示为:
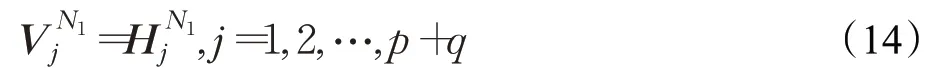

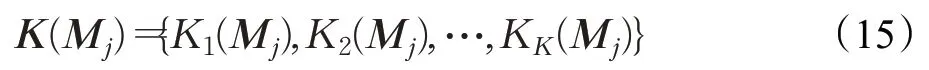
计算N1对N2的注意力权重:

其中,W1∈R1×K和b1∈R 是线性变换的参数,根据注意力权重可以计算出N1传递给N2的信息:

(2)句子级别的注意力
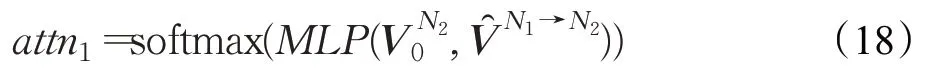
其中,MLP 是三层感知机,用注意力权重代表N1节点对N2节点的重要程度,利用图注意力机制,将这S 个邻居节点的信息都按上述方法聚合:

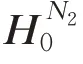

其中,⊕表示矩阵拼接,根据新的节点表示得到标签预测概率:

W2∈R2d×t和b2∈Rt,t 是事实验证的类别数,这样每个节点都能通过邻居节点,即沿着图上的边得到全局的信息。按上述步骤得到每一个节点预测该证据被选择的概率和验证标签概率,最后所有节点预测的验证得分为:

训练阶段,模型采用端到端的交叉熵损失进行训练:


3 实验结果与分析
3.1 数据集
本实验采用FEVER 数据集验证模型效果,数据集中的每一个样本包括一个声明、Wikipedia 中的正确证据(Golden Evidence)以及一个验证标签,并且还附带一个由5 416 537 个预处理文档构成的Wikipedia 文档库。该数据集提供了带标签的训练集(Training)和开发集(Dev),测试集(Test)的答案不公开,测试结果在上传预测文件后给出。FEVER的统计数据如表1所示。

表1 FEVER数据集
为了有效评估事实验证的模型性能,本文用FEVER数据集提供的评价指标:标签的准确率和FEVER 分数。标签的准确率评价模型的推理验证能力,FEVER分数综合评价推理能力和检索能力。当一个样本的标签正确,并且预测的证据集是正确证据集的子集,两个条件同时满足时FEVER 分数按1 记。其中信息不足(NEI)标签的样本不需要证据。此外,还针对推理能力测试了在提供正确证据的情况下模型的预测准确率。
3.2 实验设置
检索和推理验证过程均采用BERT-Base 对文本编码,包含12 个Transformer 层[14],词嵌入的输出维度是768,超参数基本按照BERT-Base 模型设置。核的个数设为21,第一个核是精确匹配核,参数是μ0=1.0,σ0=10-3。因为余弦相似度是在-1 到1之间,其余20个核在[-1,1]区间内,按照等间距取值,μ1=0.95,μ2=0.85,…,μ10=-0.95。在两块2080ti GPU 上运行约8 小时,模型的超参数如表2所示。
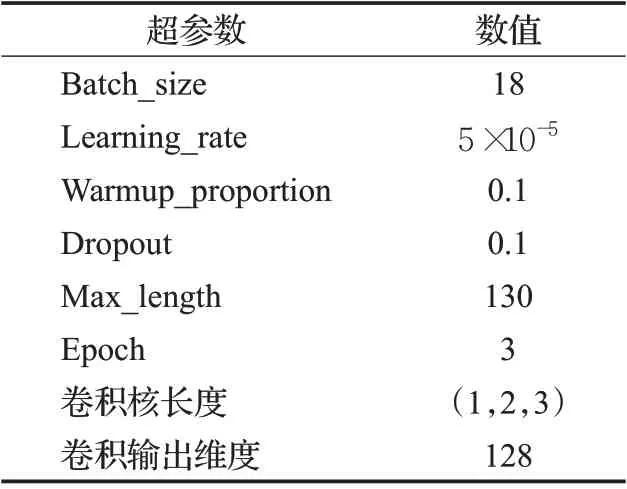
表2 参数设置
3.3 基线模型
FEVER 1.0数据竞赛前三名的模型中,UNC-NLP[17]使用ESIΜ 模型检索证据,并且在推理过程中引入外部知识,将WordNet 和浏览频率作为特征融入推理模型,还使用了符号匹配规则;UCL[34]验证每一个声明证据对的真实性,最后对所有的信息进行融合推理;Athene UΚP TU[16]通过Attention 机制将ESIΜ 模型编码的5 个声明证据对结合进行推理,最终得到预测结果。除此三种模型外还有QFE[35],利用文本摘要模型,边检索证据边做验证;Attentive Checker[36]采用阅读理解中的双向注意力流(Bi-Directional Attention Flow for Μachine Comprehension,BIDAF)[37]结构完成验证推理。
本文主要采用基于BERT的基线模型,现有的方法有如下几种:一种是用BERT 编码拼接声明和所有证据,将所有的证据拼接作为一个整体,再和声明拼接,对长度大于512的直接截断,然后送入BERT模型做预测;还有用BERT针对声明和证据对采用句对模型预测,每一对声明和证据对分别送入BERT模型,不同的声明和证据对的预测结果可能不同,然后再经过一个融合模块得到最终预测标签;GEAR 模型[10]将BERT 的[CLS]句向量的表示取出作为节点表示,然后用GNN 更新句向量表示,得到推理的结果。ΚGAT 模型[24]采用神经网络排序模型基于细粒度的注意力融合证据信息。
3.4 实验结果和分析
GHAN模型和其他模型方法在FEVER数据集上的表现对比如表3所示。
上述加引用的实验结果为论文中公布的结果,QFE和Attentive Checker 未提供代码和开发集上的结果。可以看出,GHAN 模型在测试集上准确率为73.96%,FEVER 得分为70.54%,GHAN 性能优于目前已公开的模型。值得注意的是,该模型FEVER 得分也比基于更庞大预训练模型Roberta Large 的方法更好,而且使用的参数几乎是后者的一半。
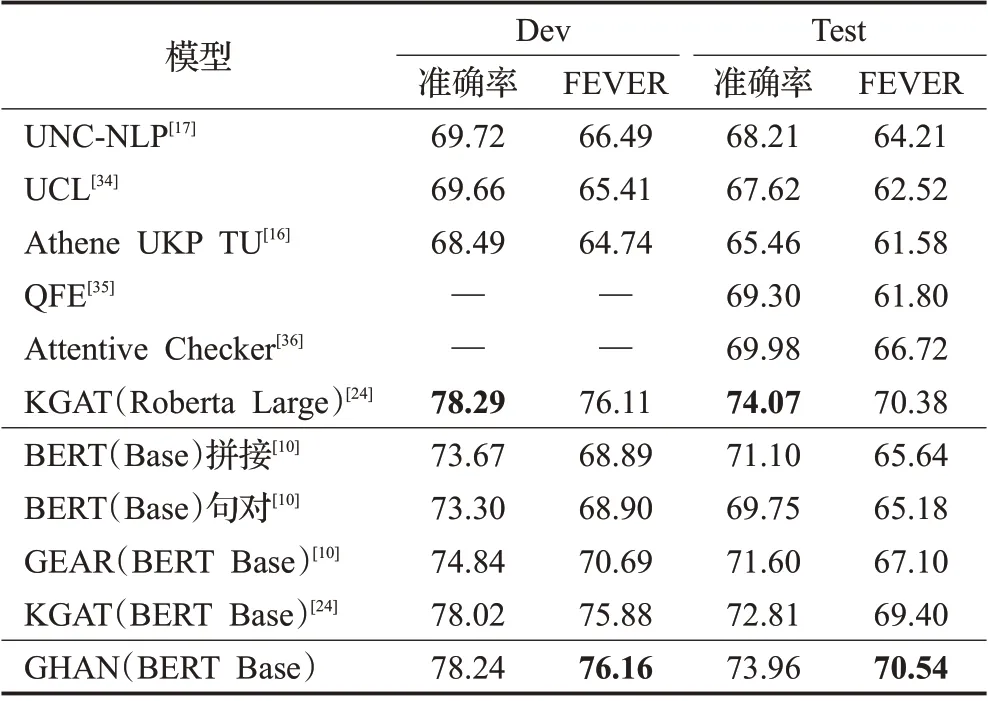
表3 不同模型在FEVER开发集和测试集上的精度%
3.4.1 消融实验
为了分别评价模型各部分对实验结果的影响,本文通过消融实验移除各个长度的N-gram 特征,结果如表4所示。
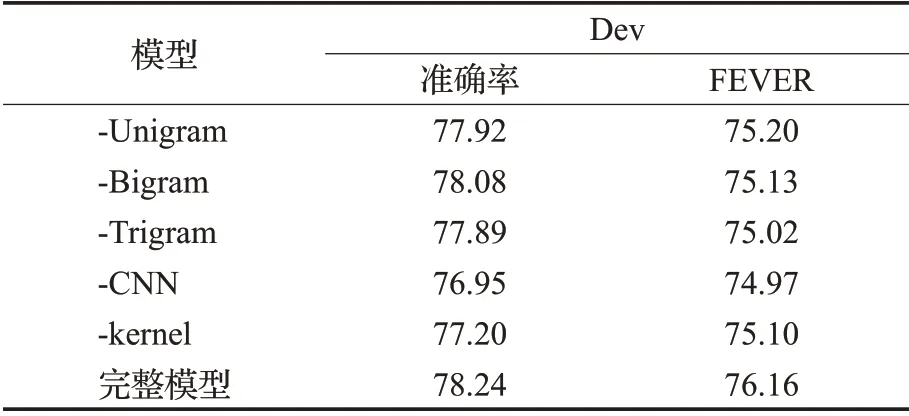
表4 层次信息对GHAN模型结果的影响 %
表中-Unigram、-Bigram、-Trigram 分别表示去掉h取值为1,2,3的卷积核,-CNN表示去掉所有CNN提取的特征,转移矩阵直接由句子的BERT 嵌入相似度构成。如表中所示,去掉CNN 层对FEVER 得分影响最大。不同N-gram 分别对最终的准确率和FEVER 得分有不同程度的贡献:一方面,长度不同的卷积核可以增强模型对细节信息的感知;另一方面,因为多个转移矩阵使得提取的语义组合层次丰富具有多样性,模型学习到与声明中的词语义相关的部分。
去除核并用点乘代替,准确率和FEVER 得分都降了1%,这表明核能有助于捕捉不同的高层语义信息。在核函数选择上,GHAN 模型参照Xiong 等人[33]的方法,语义相似度越高它们越接近均值μk,当μ →∞时,kernel-pooling接近于平均池化;当μ=1,σ →0 相当于一个精确匹配的核。 μ 定义了软匹配的程度,σ 定义了核的宽度。其他可导的核函数也可以作为软匹配的核函数,本文采用的是最常用的高斯核。通过核得到分布在均值周围的特征,也是Soft-TF 的含义(Soft Term Frequency)[23]。基于核函数的软匹配在搜索领域运用广泛,在事实验证任务中,可以用于增强证据的细节和声明的语义之间的匹配度。
3.4.2 不同场景下的实验
由于FEVER 数据集中包含的证据来源不同,分散在单篇或多篇文章中,对于模型而言难易程度不同,因此统计了两者的占比,如表5所示。

表7 GHAN错误样例分析

表5 FEVER数据集中单个和多个证据的统计信息
声明验证所需单一证据的情景下,不需要复杂推理,模型表现显然比需要多个证据的要好。GHAN在不同场景中的表现如表6所示。
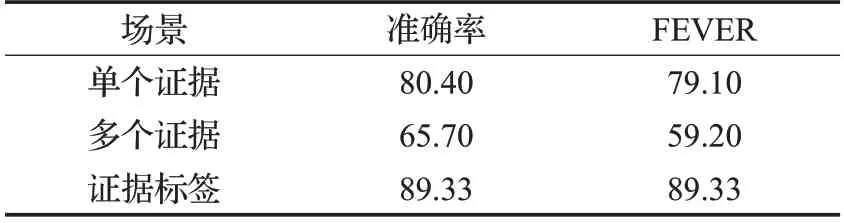
表6 GHAN在不同证据场景中的表现 %
因为模型检索分散证据难度增大,所以验证精度和FEVER得分都大幅下降。为了验证模型的推理验证能力,将检索标签直接送入模型,得到表6 中最后一行的结果。可见,检索精度是下游推理的瓶颈之一,本文重点研究推理部分,检索主要是考虑到程序运行效率,在实际应用中需要在效率和性能之间做更好的权衡。
3.4.3 错误分析
随机选择100 个错误样本,进行样例分析,发现主要有三类错误,如表7所示。
第一类是总结归纳性的语义理解错误。表格第一行证据中表明Richards做了很多政治工作,声明是对她的工作专业的评价总结,模型并没有理解到深层次的语义关系。
第二类是检索到的信息不完善。表格第二行证据中没有检索到2007年的时间信息,导致推理验证错误。
第三类是模型缺乏常识信息和指代信息。表格第三行样例中,模型并不知道decades 是指10 年,同时也缺乏符号计算能力。以及前文检索过程中遇到的指代问题,同一个名词可能是指代不同事物,从而导致模型的误判。
4 结束语
针对事实验证任务,本文提出了基于图的多层次注意力GHAN模型,模型通过卷积神经网络捕捉到不同粒度的N-gram信息,利用不同的核映射到不同空间得到多层次的特征,使得多层次信息在信息融合图中更新,得到更准确的事实验证结论。实验结果验证了多层次细节信息对于事实验证任务的重要性,在已知的基于BERT模型的方法对比中取得了最佳的效果。
外部知识能够显著改进模型的推理能力,在模型中引入外部知识,提高模型理解深层次语义的能力将会是未来的研究方向。
