面向学习情境的个性化学习资源推荐研究
2021-05-16张颖敏
张 颖 敏
(广州民航职业技术学院民航经营管理学院, 广州 510403)
在个性化学习方面,学习者可通过线上碎片化的学习方式随时随地选择自己感兴趣的学习内容。然而,在移动互联网背景下信息资源爆炸性增长,学习者难以从海量的碎片化信息中快速找到所需资源。随着网络碎片化信息的巨量涌现,碎片化学习的弊端日益凸显。过量的碎片化学习会对学习者的感知、注意、记忆和思维等认知过程造成“障碍”,从而影响学习效果[1]。因此,需要发展个性化学习资源推荐,实现对信息的实时精准推荐,以助于提升学习者的碎片化信息学习效率。
个性化学习资源推荐是在线学习系统面临的一项重要挑战。个性化主动推荐技术主要包括基于关联规则算法(AR)、基于推荐内容(CB)以及基于协同过滤(CF)的推荐方法[2]。协同过滤算法不需要考虑被推荐项目的内容,推荐形式多样化,可实现潜在兴趣发现与推荐[3],因此得到了广泛的研究与应用。但由于个性化推荐的理念及其技术的实现存在局限性,目前基于协同过滤的传统推荐算法受冷启动问题的影响,资源推荐的精度受限,难以满足学习者的个性化学习需求。另外,学习情境呈动态变化,因而整个学习路径上的推荐精准度也很难得以保证。本次研究将探讨面向动态学习情境的学习者画像方法,通过建立学习者画像进行学习情境的匹配与实现个性化学习资源的精准推荐。
1 个性化学习资源推荐系统框架
1.1 概念模型
领域本体被广泛应用于知识建模中[4-5],以机器可读的方式描述领域内的概念、属性、关系,通过本体语义的识别来实现机器对结构化、半结构化、非结构化数据的“理解”。本次研究在传统协同过滤“用户-项目”的推荐维度上增加了情境维度与学习者个性化学习行为维度,构建了学习者个性化学习资源偏好本体概念模型OntoPLR。此概念模型为一个四元组集合:ML{L,C,R,I}。L、C、R分别表示学习者、学习情境、学习资源的集合;I表示学习者与学习资源之间的交互行为集合,如学习者对某项学习资源的点击、浏览、点赞、收藏、转发、评价等行为。例如:pi,j,k{li,cj,rk,ii,j,k}表示学习者li在cj情境下对学习资源rk的交互行为ii,j,k,表征面向情境的学习资源偏好。
1.2 实现框架
用户画像方法是指通过对用户与行为数据的挖掘,构建反映用户行为特征的标签体系,并绘制出目标用户的行为模型,从而满足用户的个性化精准服务需求[6-7]。基于学习者兴趣偏好的画像方法,是通过抽象学习者的基本属性、学习兴趣偏好、学习情境等信息全貌,了解学习者的学习需求及其变化,据此匹配学习资源并予以推荐。在上述面向情境的学习资源偏好本体概念模型的基础上,引入了用户画像方法建立学习者画像,进行个性化学习资源偏好的预测与推荐。该推荐系统分为数据资源层、数据挖掘层、应用层,其实现过程围绕着学习者信息的获取、学习者画像的建立、情境化学习资源的推荐、面向应用层的结果输出等方面内容展开(见图1)。
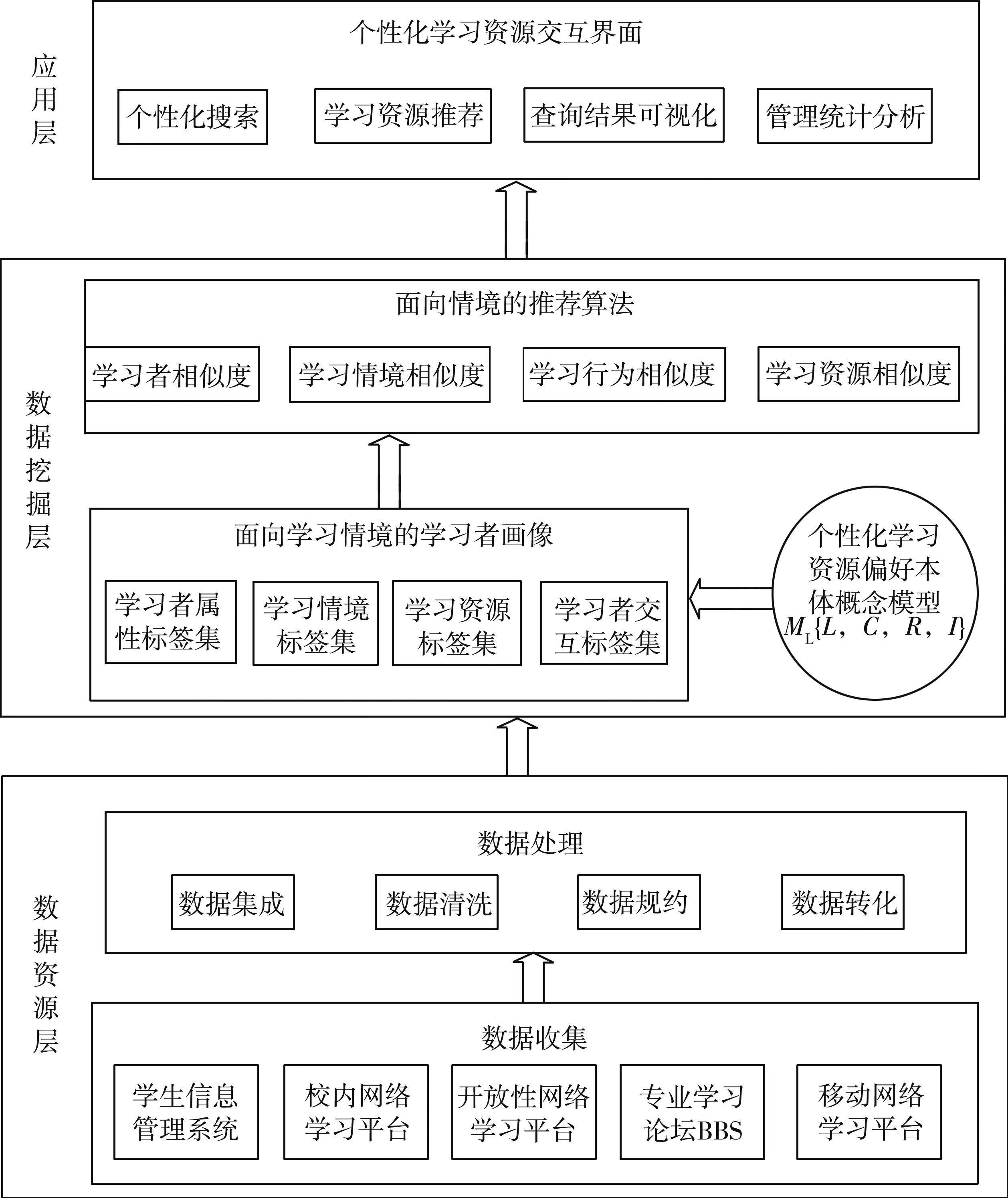
图1 面向学习情境的个性化学习资源推荐框架
(1) 数据资源层。数据资源层是获取用户个性化学习偏好数据的基础。收集到的信息越多,构建的画像模型就越能准确反映学习者的学习偏好。但由于信息搜索成本及隐私保护方面的限制,难以构建与学习者完全匹配的“精准”画像。因此,在信息搜集过程中需要充分考虑实际的应用场景,能够构建满足面向学习情境条件需求的学习者画像模型即可。在此,主要通过学校的学生信息管理系统、校内网络学习平台、开放性网络学习平台、专业学习论坛以及微信、移动App平台,获取学习者的基本属性、学习资源基本属性、学习情境、学习者互动等信息数据,然后通过数据清洗、数据规约、数据转换等方法对获取的学习者数据进行预处理。
(2) 数据挖掘层。数据挖掘层是整个推荐系统的核心构成部分,主要包括学习者画像与情境化推荐算法。在此引入用户画像方法对学习者的情境信息进行标签划分和描述,建立标签化的学习者画像,并设计面向情境的推荐算法进行学习者学习资源推荐。其中,如何给学习者贴“标签”,是构建学习者画像的关键环节。此标签是搜集并深入分析学习者信息后得出的特征标识,可高度概括学习者的此类信息属性。基于上述模型OntoPLR,以及收集到的学习者与学习行为数据,经过相关分析、因子分析、聚类分析、关联挖掘等算法处理,从海量的学习者数据中提取出关键特征信息,建立学习者基本属性标签库、学习资源属性标签库、学习情境标签库、学习者交互行为标签库,进而刻画出学习者的立体“画像”。根据学习者画像的标签进行相似性计算,可据此确定特定情境或相似学习情境下目标用户对学习资源的偏好。
(3) 应用层。在应用层,通过计算目标学习者与学习资源的相似度,结合学习者当前的学习情境(时间、位置、学习状态等)及相应的偏好特征标签,为学习者推送与其情境最为匹配的个性化学习资源,并应用于个性化搜索、推荐结果可视化、管理决策等领域。
2 学习者画像
2.1 构建学习者标签集
面向情境的个性化学习推荐系统概念模型从学习者、学习资源、学习情境、学习者对学习资源的交互行为等4个维度进行刻画,根据这4个维度来构建学习者标签体系。
(1) 学习者基本信息标签。此标签主要用于描述学习者的基本情况,如学习者的姓名、性别、年龄、所处城市、教育程度、收入情况、联系方式等。
(2) 学习资源基本信息标签。此标签主要用于描述学习资源项目的基本信息,如资源的名称、所属类型(文本、PPT、音频、视频)、大小等。
(3) 学习情境信息标签。此标签主要包括反映学习者所在位置、发生时间等学习情境的信息。学习位置信息标签,是通过学习者所处的位置来反映其学习特征,如学习某项资源时是在教室、图书馆或校园外等。学习时间信息标签,是通过与学习时间相关的信息来反映学习者的学习特征,如某学生选择某网络学习平台的时间节点、页面停留的时间等。
(4) 学习者行为信息标签。学习者的行为信息主要体现学习者的学习需求特征、偏好兴趣等,据此可以结合学习者的情境信息进行协同过滤推荐。体现学习者对学习资源的主要行为信息包括浏览、查询、点赞、评论、分享、收藏等。
2.2 学习者画像模型的建立
在本体概念模型ML{L,C,R,I}的基础上,通过4维学习者标签构建学习者画像。
学习者基本信息标签的形式为:L={LID,LName,Gender,Age,City,Edu,Career,Income}。其中:LID为学习者标识;LName为学习者姓名;Gender为学习者性别;Age表示年龄,在此将年龄段分为12~21、22~34、35~44、45~54、55~64、65岁及以上;City表示所在城市;Edu表示教育程度,包括初中以下、高中/中专、大学/本科、研究生以上;Career为学习者的职业;Income为月收入情况。
学习资源基本信息标签的形式为:R={RID,RName,Type,Size}。其中:RID为学习资源标识,是学习资源记录的唯一标识;RName为学习资源名字;Type代表学习资源所属类型;Size代表学习资源的容量大小。
学习情境信息标签的形式为:C={Time,Location}。其中:Time为学习情境发生的时间,该时间属性为一个四元组Time={Date,Time,Weekday,Holiday},Date,、Time、Weekday、 Holiday分别表示日期(可用于知道学习的季节)、时间(用于表示早、午、晚等具体时间段)、工作日、假期;Location 用于记录学习情境发生的位置。
学习者行为标签的形式为:I= {Resource,Interaction Behaviors}。其中:Resource表示学习者发生交互行为的学习资源;Interaction Behaviors表示具体的行为方式,包括浏览、搜索、点赞、评论、分享、收藏等。
根据上述标签,构建了学习资源情境化推荐的学习者画像模型(见图2)。
3 相似度
相似度的计算是信息服务推荐的关键。根据学习者习得行为及推荐系统的推荐原理,作以下假设:
(1) 学习者倾向于选择自己曾经使用过的、相似的学习资源。
(2) 相同类型的学习者感兴趣的学习资源具有相似性。
(3) 在同一或相似学习情境下,学习者对学习资源的偏好具有相似性。
基于此假设,研究面向情境的个性化学习资源偏好推荐,并通过学习者、学习情境以及学习者选择学习资源的相似度计算来实现学习资源偏好的预测与推荐。
3.1 学习者的相似度
学习者的相似度一般通过学习者的属性或标签(学习者注册或购买机票时填写的属性信息)差值来获得。对于学习者L,其属性向量为A(a1,a2,…,an),其中表ai示第i个属性的值,一般采用属性的平均绝对差来衡量属性的相似度。不同数据类型的属性值度量的数据颗粒度差异问题,其属性相似度的计算方法不一。在此,将学习者属性信息分为数值型属性(如年龄、年级等)与标称型属性(如性别、籍贯、专业等),分别计算其相似度。
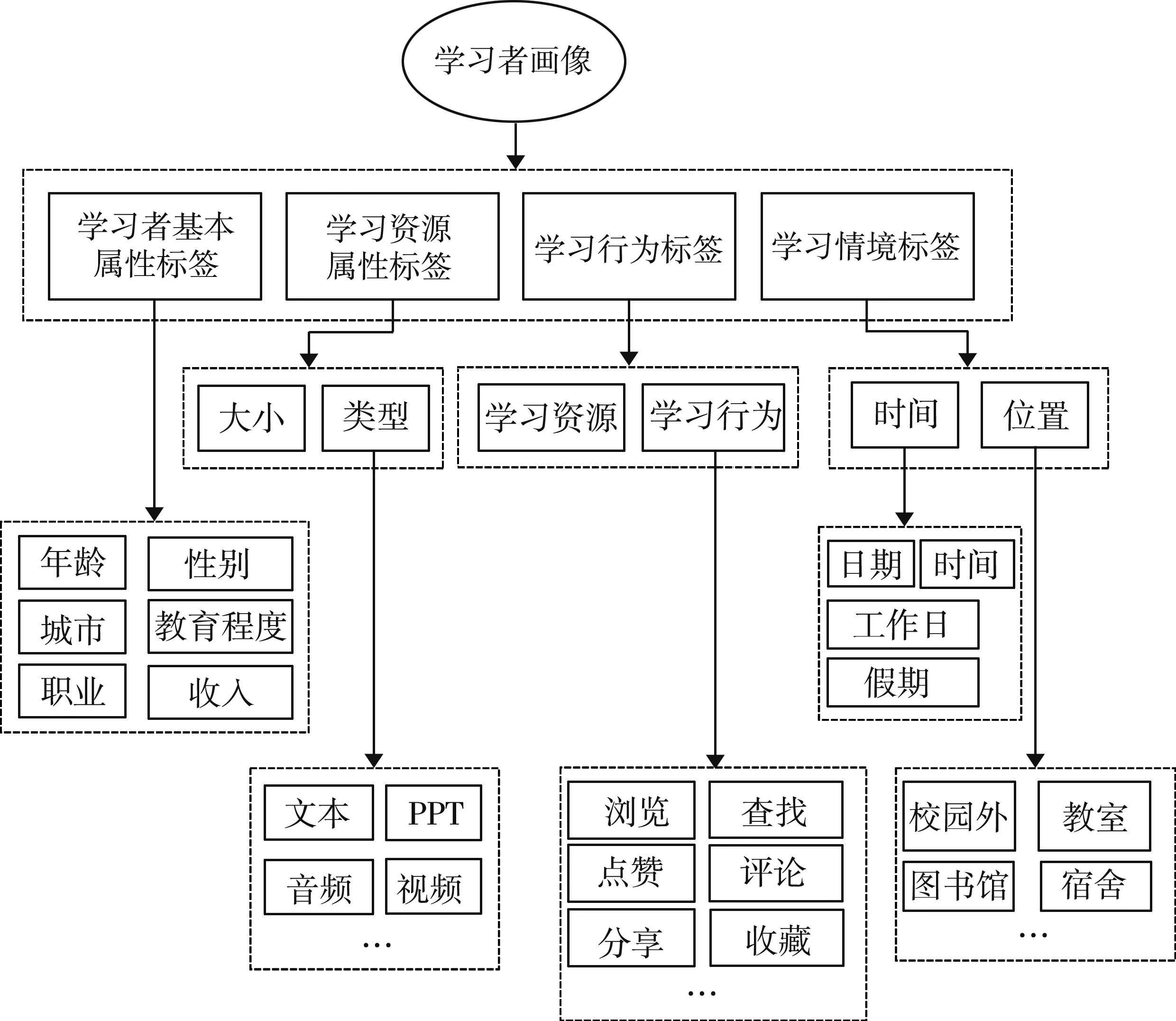
图2 基于学习资源情境化推荐的学习者画像
(1) 数值型属性的相似度。对于数值型属性,其属性度量单位不同,属性的平均绝对差可比性(相似度)存在较大差异。按照式(1) 对其进行标准化,以消除度量单位的影响。
(1)
式中:Sai表示标准化属性;ai表示第i个数值型属性;MA表示属性的平均值。
进一步借鉴曼哈顿距离[7]来计算学习者数值型属性的相似度,如式(2)所示:
(2)
式中:Snum(Li,Lj)为学习者Li、Lj的数值型属性相似度,其值等于标准化后的各个属性ak的差值之和。
(2) 标称型属性的相似度。两个不同对象标称型属性的相似度一般用其标称属性的属性值匹配个数来表示。假设学习者Li、Lj共有m个标称型属性,则其标称属性的相似度Snom(Li,Lj)可以用其匹配的标称属性个数nequ(Li,Lj)来表示。
因此,学习者的相似度为:
S(Li,Lj)=Snum(Li,Lj)+Snom(Li,Lj)
(3)
3.2 学习情境的相似度
属性向量C(c1,c2,…,cn)中,ci表示第i个情境属性的值。学习情境的相似度可以通过类似于学习者属性相似度的方法确定适用的标准化方法。此外,考虑到不同学习情境因素对学习者选择学习资源的影响有差异,在此加入了不同情境要素的相似度权重系数pk,k表示情境因素的个数,取值为1,2,…,n。由此,学习情境(cx,cy)的相似度计算如式(4)所示:
(4)
3.3 学习资源选择行为的相似度
对于学习者L,他所选择的学习资源集合表示为:RL={r1,r2,…,rn}。
定义:若学习者L和L′在相同或相似情境集合C下对学习资源ri进行了选择、评价、点赞等交互行为xj(xj∈X,X={x1,x2,…,xn}表示学习者对学习资源的交互行为集合),则称学习者L和L′对学习资源ri的偏好相似;同时,称两者的相似度为对相同学习资源进行同类型同交互行为的次数N。 次数越多,表明相似度越高。学习者学习资源偏好行为的相似度计算公式为:
(5)
4 面向情境的学习者学习资源推荐
在个性化学习资源推荐系统中,学习者对学习资源项目的兴趣度与其学习情境具有较大关系。在相似的学习情境下,同一学习者或同类型学习者对学习资源的选择具有相似性。因此,可以利用相似类型学习者在相似情境下的学习资源偏好进行推荐。
首先,计算学习者相似度进行学习者类型匹配,以寻找最近邻学习者;然后,计算当前学习情境与近邻学习者的历史情境相似程度,以获取与当前学习情境相近的历史情境;最后,利用top-N规则选择近邻学习者在相似情境下排名靠前的N项学习资源,推荐给目标学习者。
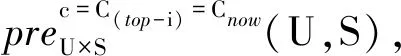
5 实验结果分析
为了验证上述个性化学习资源推荐方法的可行性,采集某高校信息作为实验数据。实验数据类型包括学习者的个人信息、学习资源信息、学习者学习资源信息等。对获取的学习者姓名、年龄,选择的学习资源名称、时间,以及学习资源的搜索、预定、支付、收藏、分享、浏览路径等信息进行分类处理。同时,学习者的学习时间还体现了学习资源被使用时的时刻,由此可确定与该资源相关联的情境属性,如当日时间段(工作日、周末、寒暑假等)、天气等。将数据集分别代入传统协同过滤推荐和本文情境化推荐方法,分别进行测试,得出推荐学习资源列表A与列表B并发送给目标用户,最后根据目标用户反馈的信息来比较用户的满意度与2种推荐方法的准确性。实验中抽选50名测试用户进行学习资源推荐。
首先,对用户信息进行识别处理,如学习者L性别为男,年龄为21。通过查询原始后台日志,获悉其登录学习平台门户、浏览、在线咨询的次数较多,属于活跃型用户。而从其选择的学习资源、检索关键词、收藏内容来看,该学习者对网店运营、网络营销、直播带货比较感兴趣。
此外,平台时间戳记录了学习者的部分情境信息。如某高校学生通过移动端浏览某一资源,时间为2020年7月11日(星期六)上午10点过。根据以上数据进行top-5推荐,可以得出基于传统协同过滤法推荐给学习者L的学习资源列表A与面向情境的偏好聚类推荐学习资源列表B,并发送给学习者L。根据反馈,该学习者对推荐列表B中的3项学习资源具有较为浓厚的兴趣,而仅对学习资源列表A中的1项资源感兴趣,表明本次推荐的成功率较高。
按照上述方法,为其他实验者推荐学习资源,并调查其对推荐结果的满意程度。采用五级量表制表示:非常不满意计1分,不满意计2分,一般满意计3分,比较满意计4分,非常满意计5分。这50名学习者的满意度结果如表1所示,其中传统的协同过滤推荐方法表示为RCF,本次提出的情境化推荐方法表示为RCox-aware。

表1 学习者对推荐结果的满意度调查结果
被调查者对传统协同过滤推荐结果的平均满意度表示为:
VCF=(5×1+12×2+16×3+10×4+7×5)÷50
=3.04
本次面向情境推荐方法的平均满意程度表示为:
Vcox-aware=(1×1+5×2+12×3+20×4+
12×5)÷50
=3.74
计算结果显示,被调查者对后者的满意度高于前者。其主要原因是,在数据资源环境下学习者对学习资源互动数据的稀疏性会导致许多他们没有或极少有共同交互的学习资源,因此在使用传统推荐时很难实现有效的个性化推荐,导致推荐的准确度大大降低。
本次研究将学习者的基本信息、学习资源信息、学习者互动与学习情境融入到学习资源推荐中,通过上述4个维度特征信息构建了面向情境的学习者画像。在此基础上,计算学习者对学习资源的偏好相似度,通过学习者特征寻找与目标学习者的近邻学习者,然后基于学习情境相似度过滤而找出与学习者当前学习情境相同的历史情境下近邻学习者最感兴趣的前N项学习资源,最后予以推荐。采用此方法,可改善学习者对学习资源互动数据稀疏的问题,从而提高个性化学习资源推荐的有效性与精确度。
6 结 语
本次研究中,基于学习者的基本信息、学习资源信息、学习情境、学习者互动等4个维度特征信息,构建了个性化学习本体概念模型及面向情境的学习者画像,引入协同过滤推荐思路来计算学习者对学习资源偏好的相似度,从而能更准确地实现个性化学习资源推荐。实验结果表明,融合学习者特征与学习情境的推荐改善了传统协同过滤中依赖用户评分导致的数据稀疏问题,提高了推荐精度。本次研究中,参与实验调查的学习者仅50名。如果加大样本容量,抽样误差导致的结果偏差将会更小。
