光谱关键变量筛选在农产品及食品品质无损检测中的应用进展
2021-05-11吴静珠
王 冬,吴静珠,韩 平*,王 坤
1.北京农业质量标准与检测技术研究中心,北京 100097 2.北京工商大学食品安全大数据技术北京市重点实验室,北京 100048 3.农业农村部农产品质量安全风险评估实验室(北京),北京 100097
引 言
农产品和食品的品质优劣一直是人们关注的热点。农产品及食品品质与安全不仅关系着人们的身体健康,而且关系着社会稳定甚至国家安全。近年来,由于农产品及食品品质不合格导致的安全事件依然多发,造成了不良的社会影响。我国对农产品及食品的消费量非常大,对大量农产品及食品品质的无损快速检测成为当前亟待解决的问题。长久以来,对农产品和食品品质的高通量无损快速检测一直是分析检测领域的重点和难点[1]。
光谱分析法,尤其近红外光谱分析,以其无损、快速、高效、环境友好以及可实现在线及现场检测等诸多特点,为农产品及食品品质无损快速检测提供了良好的解决方案。然而,传统的光谱分析法在分析过程中所涉及的大量数据成为该方法应用过程中的瓶颈,主要表现为3个方面:(1)庞大的数据量增加建模过程的计算成本;(2)庞大的数据量对仪器装备的硬件提出了很高的要求,间接增加了技术应用成本;(3)对样品的预测仍采用全谱数据导致仪器工作效率降低,无法满足农产品及食品品质高通量无损快速检测的需求。
面对上述困难,近年来,尤其近十余年来,光谱变量筛选算法脱颖而出,并成为光谱分析的一个新热点[2]。通过对光谱数据筛选关键变量,基于所选的少量关键变量数据即可建立准确度较高的校正模型,有效提高了工作效率,并间接地降低光谱分析的应用成本,进而为农产品及食品品质的高通量检测提供了可靠的技术支持。目前,常用的关键变量筛选算法主要有以下几个类型:(1)根据偏最小二乘(partial least square,PLS)模型的一些参数进行变量筛选[3-5],如无信息变量消除(uninformative variable elimination,UVE)、竞争自适应重加权采样(competitive adaptive re-weighted sampling,CARS)等;(2)基于智能优化算法进行变量筛选[6],如遗传算法(genetic algorithm,GA)、模拟退火算法(simulated annealing,SA)等;(3)连续投影算法(successive projection algorithm,SPA);(4)模型集群分析策略变量筛选算法[7-8],如变量组合集群分析(variable combination population analysis,VCPA)、自举柔性收缩算法(bootstrapping soft shrinkage,BOSS)等;(5)变量区间选择算法[9],如区间偏最小二乘(interval partial least square,iPLS)、移动窗口偏最小二乘(moving window partial least square,MWPLS)。此外,为了提高变量筛选算法所选变量稳定性,近年来,蒙特卡洛(Monte-Carlo,MC)方法[10-11]正越来越多地被运用到关键变量筛选过程中,通过多次蒙特卡洛方法抽样选择关键变量,对所选变量进行频次统计,以提高所选变量的稳定性。
本文针对光谱关键变量筛选在农产品及食品品质无损快速检测中的应用,分别就粮食及粮食作物、蔬菜、水果、经济作物、肉类、食品品质与安全等方向进行综述,对光谱关键变量筛选技术的应用从筛选方法、应用范围、应用效果等方面进行了分类总结归纳,并就光谱关键变量筛选技术在农产品及食品品质无损检测中的应用从变量筛选方法特点及趋势、所选变量的稳定性和可靠性、所选变量的实际意义等方面进行了展望。
1 光谱关键变量筛选在粮食及粮食作物品质无损检测中的应用
粮食是指烹饪食品中各种植物种子的总称,富含蛋白质、维生素、膳食纤维、脂肪等营养物质,是人们获取能量的最主要来源,是国家之根本,其重要程度不言而喻。对粮食的品质检测关系到粮食储备、流通、消费等诸多环节。一些学者就粮食及粮食作物品质的无损快速检测过程中关键变量的筛选进行了研究,并取得了一定的成果。

由此可见,关键变量筛选算法在粮食及粮食作物品质无损快速检测方面有一定的应用效果,可为粮食及粮食作物品质的高通量无损快速检测提供技术支持。其中,恰当地选择关键变量甚至可以建立准确度更高的校正模型。
2 光谱关键变量筛选在蔬菜品质无损检测中的应用
蔬菜是指可以做菜、烹饪成为食品的植物或菌类,是人们日常饮食中必不可少的食物之一。蔬菜可提供人体所必需的多种维生素和矿物质等营养物质,此外,蔬菜中还有多种多样的植物化学物质,是人们公认的对健康有效的成分,对慢性疾病、退行性疾病有很好的预防作用。目前,近红外技术已在蔬菜品质无损检测中得以应用[19],其中不乏一些学者就蔬菜品质无损快速检测过程中关键变量的筛选进行了研究,并取得了一定的成果。

从以上内容可见,变量筛选算法在蔬菜品质无损快速检测中具有较好的应用效果,可为大量蔬菜的品质无损快速检测提供技术支持。其中不乏将多种变量筛选算法相结合的报道,例如将UVE与SPA相结合,在消除无信息变量的基础上进一步去掉变量间的共线性,其对关键变量的筛选结果优于单一变量筛选算法。
3 光谱关键变量筛选在水果品质无损检测中的应用
水果是指多汁且主要味觉为甜味和酸味、可食用的植物果实。水果不但含有丰富的营养物质,而且具有促进消化等保健作用。水果品质无损快速分级正成为主流趋势,而基于近红外技术对水果进行无损快速检测则可为水果品质无损快速分级提供有效的解决方案。根据水果品质的不同制定差异化价格进行销售,更好地实现物尽其用,在提高水果利用率的同时还可避免浪费。一些学者就水果品质无损速测过程中关键变量的筛选开展了研究,并取得了一定的成果。
王转卫等[31]采用近红外漫反射光谱研究了富士苹果品质指标的无损快速检测方法,采用主成分分析(principal component analysis,PCA)、SPA和UVE筛选关键变量,并结合LSSVM和极限学习机(extreme learning machine,ELM)建立校正模型;结果表明,SPA-ELM模型预测SSC,pH值准确度更高,RMSEP分别为0.44和0.006 8,PCA-ELM预测硬度、含水率准确度更高,RMSEP分别为0.26和0.62。Che等[32]采用可见-短波近红外光谱研究了苹果淤伤的检测,采用随机森林算法筛选关键变量,平均准确度达到99.9%,并根据随机森林模型优选出675和960 nm附近2个特征波段。Dong等[33]采用近红外高光谱成像对富士苹果在13周储存期内的SSC、硬度、水分和pH进行无损检测,采用SPA、UVE算法筛选关键变量,并结合PLS、LSSVM、反向传递网络建模(back propagation network modeling,BPNM)方法建立校正模型;结果表明,全部模型均可准确预测SSC和水分,SPA-LSSVM和全谱BPNM可粗略估算pH值,而采用上述任何模型预测硬度皆无法得到准确结果。在预测SSC、水分和pH值方面,SPA-LSSVM模型更具综合性,预测相关系数分别为0.961,0.984和0.882。Li等[34]采用近红外光谱研究了梨中SSC的无损检测,采用MC-UVE和SPA算法相结合筛选关键变量,结合PLS算法建立校正模型;结果表明,与MC-UVE-PLS和SPA-PLS模型相比,MC-UVE-SPA-PLS模型稳健性更好,而采用MC-UVE-SPA-PLS模型的18个关键变量所建SSC模型的校正集、预测集相关系数(r)分别为0.88和0.88,RMSE分别为0.49和0.35。进一步地,Li等[35]采用可见-近红外光谱研究了多品种梨硬度的无损检测,采用MC-UVE-SPA从全谱1 344个变量中筛选了17个关键变量,分别结合PLS和LSSVM建立校正模型;结果表明,MC-UVE-SPA-LSSVM模型预测准确度更高,“翠冠”、“黄花”、“清香”三种梨的预测集相关系数(r)分别为0.94,0.93和0.92,RMSEP分别为0.91,0.92和0.96。Zhang等[36]采用可见-短波近红外高光谱成像研究了砀山梨糖含量的无损快速检测,采用MC-UVE,SPA,CARS,GA,CARS-SPA和GA-SPA筛选关键变量,分别结合PLS、LSSVM、反向传递人工神经网络(back propagation-artificial neural network,BP-ANN)建立校正模型;结果表明,CARS-PLS和GA-SPA-PLS模型准确度更高,预测相关系数(rpre)分别为0.897 1和0.896 9,RMSEP分别为0.39%和0.35%。Guo等[37]采用近红外光谱研究了4个品种桃的无损鉴别,采用PCA,UVE和SPA分别从全谱2 074个变量中筛选出8个主成分、1 067个、10个特征波长,分别结合LSSVM和ELM建立桃品种鉴别模型;结果表明,PCA-LSSVM,UVE-LSSVM模型以及PCA-ELM模型的准确率可达到100%,其他模型准确率皆不低于96%。Zhang等[38]采用可见-短波近红外高光谱成像检测桃表面缺陷,采用MC-UVE和SPA筛选关键变量,结合PLS算法建立判别模型;结果表明,基于少量特征波长可建立人工缺陷、非人工缺陷模型,人工缺陷、非人工缺陷、对照和样品总准确度分别为87.5%,96.7%,95.0%和93.3%。Yu等[39]采用可见-短波近红外高光谱研究枇杷缺陷的识别,采用CARS算法选择了12个关键变量,结合PLS-DA算法建立判别模型;结果表明,CARS-PLS-DA模型对有缺陷枇杷的总体识别准确率为92.3%。Huang等[40]采用可见-近红外高光谱成像研究了桑葚中总花青素含量和抗氧化活性的检测,采用SPA,UVE和CARS三种波长选择算法筛选关键变量,结合PLS和LSSVM建立校正模型;结果表明,9变量CARS-LSSVM模型预测总花青素含量的准确度更高,交互验证R2=0.959,RPD=4.964,而18变量CARS-LSSVM模型预测抗氧化活性的准确度更高,交互验证R2=0.995,RPD=14.255。Zhao等[41]采用可见-短波近红外高光谱成像研究桑葚中总可溶性固形物(total soluble solid,TSS)的检测,采用随机蛙跳(random frog,RF)算法从512个变量中筛选关键变量,结合PLS,LSSVM建立TSS的校正模型;结果表明,RF-LSSVM(径向核函数)模型的校正集、交互验证集、预测集相关系数(r)分别为0.999,0.958和0.956,校正均方根误差(root mean square error of calibration,RMSEC)、交互验证均方根误差(root mean square error of cross validation,RMSECV)、RMSEP分别为0.061,0.453和0.430。Elfatih Abdel-Rahman等[42]采用可见-近红外高光谱数据研究甘蔗叶中氮浓度的检测,采用随机森林(random forest,RF)算法筛选关键变量,结合逐步多元回归算法建立校正模型;结果表明,非线性RF回归模型测定系数R2=0.67,验证均方根误差(root mean square error of validation,RMSEV)=0.15%。Zhang等[43]采用可见-短波近红外光谱建立哈密瓜SSC校正模型,采用CARS,UVE,CARS-SPA,UVE-SPA筛选关键变量,分别结合PLS和LSSVM建立校正模型;结果表明,哈密瓜赤道区域多光谱模型略优于总体多光谱模型,UVE-SPA-PLS模型和CARS-SPA-LSSVM模型预测相关系数(RP)分别为0.914 3和0.914 3,RMSEP分别为0.835 9和0.895 8。Hu等[44]采用可见-短波近红外光谱对哈密瓜SSC进行定量测定,采用SPA,MC-UVE,CARS和MC-UVE-SPA筛选关键变量,结合多元线性回归(multiple linear regression,MLR),PLS和LSSVM建立校正模型;结果表明,MC-UVE-SPA筛选的18个变量建模准确度更高,MC-UVE-SPA-PLS,MC-UVE-SPA-LSSVM,MC-UVE-SPA-MLR模型预测哈密瓜SSC的RMSEP在0.95~0.99之间。Mithun等[45]采用高光谱数据结合RGB数据对天然成熟和人工催熟香蕉进行识别,采用随机森林(random forest,RF)筛选关键变量,结合多层感知前向神经网络建立校正模型,自然成熟和人工催熟香蕉的识别准确度分别达到98.74%和89.49%。
从以上内容可见,变量筛选算法在水果品质无损快速检测中具有较好的应用效果,可为大量水果的品质无损快速检测提供技术支持,将为水果收购入库、精品出库、分级销售过程中的品质无损快速检测提供重要技术支持。
4 光谱关键变量筛选在经济作物品质无损检测中的应用
经济作物亦称“工业原料作物”,一般指为工业,特别是轻工业提供原料的作物。我国纳入人工栽培的经济作物种类繁多,包括纤维作物(如棉、麻等)、油料作物(如芝麻、花生等)、糖料作物(如甘蔗、甜菜等)、三料(饮料、香料、调料)作物、药用作物、染料作物、观赏作物、水果和其他经济作物等。近年来,近红外技术越来越多地被应用于经济作物品质的无损检测[46],其中一些学者就关键变量筛选进行了探索并取得了一定的成果。

从以上内容可见,变量筛选算法在经济作物品质无损快速检测中具有较好的应用效果,可为经济作物的品质无损快速检测提供技术支持,进而可为提高产品附加值、增强产品市场竞争力提供技术保障。
5 光谱关键变量筛选在肉类品质无损检测中的应用
肉类是指动物的皮下组织和肌肉,可以提供丰富的蛋白质、脂肪和热量。我国肉类消费总量近年来稳居世界前列;在采用近红外技术研究肉类品质的无损快速检测[55-56]中,针对肉类品质无损检测过程中的关键变量筛选,一些学者进行了探索并取得了一定的成果。

从以上内容可见,变量筛选算法在肉类品质无损快速检测中具有较好的应用效果,其中不乏采用所选关键变量建立模型优于全谱建模的例子,可为肉类品质无损快速检测提供技术支持,进而可为提高产品附加值、增强产品市场竞争力提供技术保障。
6 光谱关键变量筛选在食品品质与安全无损检测中的应用
食品一直以来是人们获取能量的重要来源,对人类的重要性不言而喻。食品安全(food safety)指食品无毒、无害,符合应当有的营养要求,对人体健康不造成任何急性、亚急性或者慢性危害。食品安全不仅关系着人们的身体健康,还关系到社会稳定甚至国家安全。在食品品质与安全无损检测方面,近红外技术近年来得以广泛应用;面对巨大的检测工作量,一些学者就光谱变量筛选在食品品质与安全无损检测中的应用开展了研究,并取得了一定的成果。
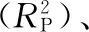
综上所述,变量筛选算法在食品品质与安全无损检测领域具有一定的应用成果,恰当地筛选关键变量可以使用较少的变量建立和全谱模型效果相近甚至超越全谱模型的校正模型,这将为食品品质与安全的无损快速检测、提高仪器工作效率等提供技术参考。
7 结 论
农产品及食品是人们获取能量的主要来源,其品质与质量安全不仅关系到百姓生活品质与身体健康,而且关系着社会稳定甚至国家安全。面对大量农产品及食品的品质检测工作,通过对样本采集全谱数据并筛选关键变量,从而简化校正模型、提高仪器工作效率是一种较为有效的技术方案。
就本文献综述而言,关键变量筛选工作可主要归纳为以下两方面趋势。(1)多种关键变量筛选算法相结合,取长补短。很多学者将UVE、CARS等算法与SPA算法相结合,克服了UVE、CARS算法第一轮筛选后所选变量仍较多的缺点,并充分发挥了SPA去共线性的功能。(2)关键变量筛选研究过程越来越多地引入蒙特卡洛(Monte-Carlo,MC)方法,为所选变量稳定性提供了保证。在样本数有限的前提下,根据MC方法随机生成多个子校正集并根据各子校正集筛选关键变量,在此基础上统计关键变量出现的频次,从而为稳健关键变量的筛选提供了可能,进而克服了基于不同校正集所选关键变量有差异的困难。
然而,光谱关键变量的筛选目前仍存在一些问题,主要体现在以下三个方面。(1)光谱数据预处理对关键变量筛选的影响尚不明确。恰当的数据预处理可以增强光谱质量,有利于光谱信息的提取;然而,光谱数据预处理对光谱关键变量的筛选有何影响,目前尚无定论。因此,在将来的研究中,针对不同状态、不同化学环境的样品,采用不同的光谱数据预处理对关键变量筛选结果的影响将会是下一步工作中值得研究的内容之一。(2)所选变量的可靠性以及方法的普适性仍有待提高。光谱关键变量的筛选在精简建模变量的同时剔除了冗余变量是目前对光谱变量筛选算法的共识。然而,在关键变量筛选过程中,根据所选变量建立的校正模型的准确度是否能达到实际工作需要,亦即所选变量的可靠性,以及变量筛选方法的普适性仍然是需要注意的问题。一般而言,对于统一体系,随着所选变量数目的减少,基于所选关键变量数据所建校正模型的准确度大体上呈下降趋势,但也不乏基于所选关键变量所建校正模型的预测准确度接近甚至优于全谱模型的例子;目前普遍认为基于所选关键变量建模的准确度和全谱建模准确度接近或能够满足实际工作需要即是可行的。值得注意的是,虽然一些学者的研究表明,恰当地筛选关键变量并基于所选关键变量数据建立校正模型的准确度完全可以满足实际工作需要,接近甚至优于全谱建模结果,但是上述结论对于种类、样式繁多的农产品及食品,以及各种各样品质指标是否具有普适性,仍存在一定的不确定性。因此,对于关键变量筛选工作,所选变量的稳定性、可靠性以及方法的普适性仍是需要继续研究的内容之一。(3)所选变量的理化含义有待进一步解析。以近红外光谱为例,近红外光谱主要来源于分子中含氢基团的合频与倍频吸收,而对近红外光谱筛选关键变量的过程很少有学者从分子角度讨论所选波长变量的归属或其理化意义。虽然一些学者就所选关键变量的归属做了简要的分析,但仍然停留在化学键的层面,没有上升为分子层面。而对所选关键波长变量从分子层面进行解析不仅可以间接验证变量筛选算法的正确性、有效性和变量筛选算法的普适性,而且有利于从分子角度揭示所建模型的机理。因此,对所选光谱关键变量从分子角度解释其理化意义将成为今后有待进一步研究的内容之一。
综上所述,光谱关键变量筛选在精简光谱变量数、提高建模和仪器工作效率方面可以提供良好的解决方案,可为大量农产品及食品品质与安全检测工作提供有效的技术保障;此外,光谱关键变量的筛选在精简输入变量方面具有十分重要的作用,因此还可为专用型仪器的研发提供可靠的技术支持,从而可为降低光谱分析技术的应用成本、扩展光谱分析技术的应用范围奠定坚实的理论基础。
