基于二级并行架构的颗粒全息图快速重建方法
2021-05-10浦世亮金其文陈晓锋吴学成
浦世亮,金其文,陈晓锋,毛 慧,吴学成*
(1.杭州海康威视数字技术股份有限公司,杭州 310051;2.浙江大学 能源清洁利用国家重点实验室,杭州 310027)
引 言
全息术作为一种3维照像技术,自发明以来经过记录介质的更新换代,由光学全息发展为数字全息,并广泛地应用在流场和颗粒场测量领域[1-2]。数字全息技术测量颗粒场的优势在于可同时测量3维空间中的颗粒位置、形貌、粒径参量,结合粒子图像/轨迹测速(particle image/trackingvelocimetry,PIV/PTV)还可进一步测量速度、旋转等参量。然而数字全息技术的重建过程需要大量的计算时间,全息图数量越多、分辨率越高、重建截面越多,计算耗时也迅速增加。这限制了全息技术应用于工业过程中颗粒场实时在线监测[3]。
为了提高全息重建的速度,国内外的研究人员已经开展了相关的研究工作。加快重建速度一般可以从两方面着手:一方面是采用性能更强的计算硬件,比如采用图形处理单元(graphics processing unit,GPU)[4-7]和大规模可编程门阵列(field-programmable gate array,FPGA)[8];另一方面是优化重建算法和并行架构,比如采用多线程编译框架(open multi-processing,OpenMP)。其中,GPU技术由于具有开发过程更为简单和可移植性更强的优点[9],已经被广泛使用,一般需要搭配NVIDIA显卡的统一计算设备架构(compute unified device architecture,CUDA)[10]。
快速傅里叶变换(fast Fourier transform,FFT)是全息重建中的主要耗时算法,MASUDA等人[8]设计的全息PTV系统,FFT 由FPGA芯片完成,对于256×256的全息图,重建100个截面的时间为266ms。ZHANG等人[11]比较了CPU和GPU进行全息重建的计算性能,使用OpenMP多线程技术进行算法优化,重建速度显著增加。YAMAMOTO等人[12]发展了一种用于高速全息3维成像的专用计算机,包括4个计算模块,重建速度相比于普通计算机提高了68倍。ZHU等人[7]基于GPU并行技术,开发了数字全息实时再现系统,每秒平均可以处理20张分辨率为512×512的全息图。MA等人[13]将OpenMP应用于数字全息3维重构,比较了不同并行方法的加速效果,证明了OpenMP可有效提高全息重建速度。
为了满足数字全息技术在工业应用过程中的实时性需求,快速获取3维颗粒场信息,本文中提出了一种基于OpenMP图片级并行和基于CUDA像素级并行的二级并行架构。以小波重建方法为例,分析了小波重建的计算流程,在此基础上提出了计算流程改进、并行计算思路和二级并行实现方式。以煤粉颗粒全息图为实验对象,测试了二级并行架构的重建准确性和加速性能。
1 理论基础与并行实现
数字同轴全息3维颗粒场测量主要包括颗粒全息图的记录和数值重建两个过程。在全息记录过程中,一束平行激光照射颗粒场,一部分光由颗粒散射作为物光,另一部分未经散射的光作为参考光,物光与参考光干涉后,由数字相机记录形成颗粒全息图。数字全息重建是指用计算机模拟光的传播,采用全息重建算法获得全息图中的3维颗粒场信息。菲涅耳积分重建、角谱重建、分数傅里叶变换重建和小波重建是常见的全息重建方法。小波重建具有全息重建图像信噪比高和图像背景均匀的优点,本文中利用小波重建方法进行全息重建提取颗粒信息[14],并对基于小波重建的并行设计进行分析介绍。根据小波母函数Ψ0(x,y)=sin(x2+y2),构造小波函数:
(1)
式中,a为尺度参量,与重建距离有关,其表达式为:
(2)
式中,λ是激光波长。
对构造的小波函数进行适当调整,引入高斯窗函数exp[-(x2+y2)/(a2σ2)]使小波函数在偏离中心点处的值迅速趋于零,同时引入一个调零参量K,使其均值为零,K(σ)的表达式为:
(3)
式中,σ为窗函数带宽因子,代表窗函数的宽度,依赖于全息图采样特性,其表达式为:
(4)
式中,N和δ分别为相机分辨率和像素尺寸,ε为一个数值极小的常数。最终得到校正的小波函数可表示为:
Ψ(x,y)=
(5)
全息图Iholo(x,y)重建图像的光强I(x,y,z)可以表示为:
I(x,y,z)=

(6)
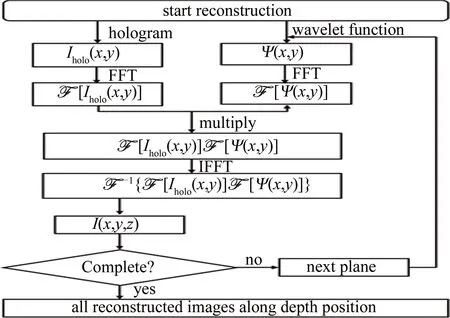
Fig.1 Flow chart of reconstruction with wavelet method
全息重建是在深度方向进行切分,得到一系列不同深度z处的重建图像。计算过程中有些变量与z有关,如a和σ,有些变量与z无关,如(x2+y2),对于与z无关的变量可作为局部变量保存,避免多次计算。全息图的重建过程具有二级特征,第1级为重建截面之间的独立性,第2级为像素点之间的独立性,因为重建截面之间和像素点之间没有数据的交换,得到结果像素的计算过程对于每个像素是独立的。这使得并行计算非常适用于全息图的快速重建,而且是“图片级+像素级”的二级并行,二级并行架构的具体实现如图 2所示。利用OpenMP实现图片级并行,利用CUDA实现像素级并行。除了用于单张全息图的并行重建,当面对海量的全息图数据而这些全息图重建参量一致时,可以将每个重建截面的F[Ψ(x,y)]作为局部变量保存,同样可以避免重复计算,加快批处理速度。
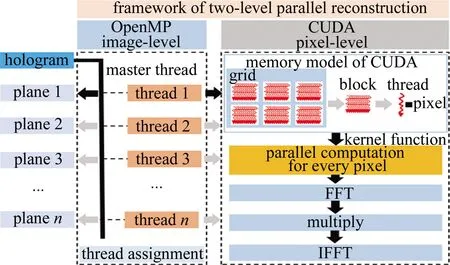
Fig.2 Framework of two-level parallel reconstruction
OpenMP是一个应用程序接口(application programming interface,API),用于在多个处理器上编写并行程序实现多线程之间的并行计算、内存共享和负载分配。OpenMP使用最频繁的编译指导语句为#pragma omp parallel for[子语句],用OpenMP实现图片级并行的主要代码如图3所示。主程序中firstprivate(z)表示重建深度z为私有变量,变量image为全息图的傅里叶变换F[Iholo(x,y)],为公有变量。CUDA并行架构程序包括主机端和设备端两部分,分别在GPU和CPU上执行,主要流程是显存申请(cudaMalloc)、数据拷贝(cudaMemcpy)、数据运算、数据拷贝。数据运算由核函数在GPU上运行,采用__global__ static void function进行函数定义,再用function函数可设置线程块和线程数量。此外CUDA中有针对傅里叶变换的专用函数CUFFT,可直接调用。本文中针对小波重建编写的一些子函数及其功能如图3所示。

Fig.3 Some codes for OpenMP and CUDA
2 实验与结果
2.1 实验装置
本文中采用煤粉颗粒全息图作为实验对象,测试二级并行架构的准确性和加速效果。实验装置如图4所示。采用同轴数字全息系统记录煤粉颗粒流的全息图。激光器发出的激光束经过光强衰减、滤波、扩束、准直后照射煤粉颗粒场,CCD相机记录煤粉颗粒全息图,其中激光器波长为532nm,相机像素大小为5.5μm、分辨率可调。高性能工作站用于重建煤粉颗粒全息图,工作站配备了2块骁龙处理器(Intel Xeon E5-2680 v4)和4块英伟达显卡(NVIDIA Tesla P100)。实验中获得了一系列不同分辨率的煤粉颗粒全息图。

Fig.4 Experimental setup
2.2 重建准确性验证
在二级并行架构重建准确性的验证中,比较了并行算法与单线程算法重建不同分辨率的煤粉颗粒全息图的差异。图5a为分辨率为1000×1000的煤粉颗粒全息图;图5b为单线程重建结果;图5c为并行重建结果。重建深度z范围为9cm至10cm,重建截面间隔为1mm。

Fig.5 Reconstructed images of coal powder hologram with different calculation method
计算图5b和图5c对应位置的像素值的方差,作为重建准确性的判别依据。计算得到图5中二级并行与单线程重建结果图的方差S=0.078,由于像素值的大小在0~255之间,所以可以基本认为图5b和图5c是一致的。分别处理多张不同分辨率和重建参量的全息图,计算两种重建算法的结果方差,结果如表1所示。表中,zmin为重建深度的最小值,zmax为重建深度的最大值,interval为重建间隔,variance为方差计算结果,随着全息图分辨率的增加,方差逐渐增大,但都小于0.1,表明不同方法重建图差别极小。结果说明基于二级并行架构的全息重建程序与单线程全息重建程序在重建结果上是基本一致的,证明了二级并行架构的重建准确性。

Table 1 Comparisonofreconstructionresultsbetweensinglethreadandtwo-level parallel
2.3 重建加速效果对比
在二级并行架构重建加速效果的验证中,首先同时使用单线程重建算法、二级并行架构重建算法以及单线程调用CUDA的并行算法重建了从100×100~5000×5000的6种不同分辨率的全息图,重建截面数都为40。3种方法计算耗时以及加速比(speedup ratio)如图6所示。speedup ratio 1为单线程耗时与单线程调用CUDA耗时的比值,speedup ratio 2为单线程耗时与二级并行耗时的比值。如图6所示,重建低分辨率的全息图时,二级并行架构的加速效果不明显,主要是因为计算量小,单线程重建程序也有足够的计算能力在短时间内处理完成,而并行计算能力没有充分体现出来。当全息图分辨率增大时,重建耗时明显减少。对于100×100,200×200,500×500,1000×1000,2000×2000和5000×5000的全息图,二级并行架构的加速比分别达到了22.8倍、30.7倍、36.1倍、42.7倍和48.3倍,充分显示了其并行加速能力。全息图的分辨率增大到1000×1000时,加速比的增加开始变得缓慢。这主要是由于一个重建截面的内存动态申请过程不能通过并行处理来加速,因此动态申请内存所消耗的时间占了很大的比例,加速比的增加也就逐渐平缓。单线程调用CUDA的重建耗时结果也证明了全息图分辨率增大时动态申请内存的耗时会大大增加,分辨率大于1000×1000后,单线程调用CUDA的加速比迅速下降。在实际工程应用中,例如工业粉体粒度的在线监测,往往要求数字全息技术的结果反馈时间在分钟级,假设全息图分辨率为1000×1000,每张全息图捕捉的颗粒数目为1000。60000颗颗粒能够具有充分的代表性,那么至少需要处理60张全息图。如果要在2min内反馈结果,则一张全息图的处理时间要少于2s,而本文中采用的并行架构处理时间为1.41s,能够满足要求。
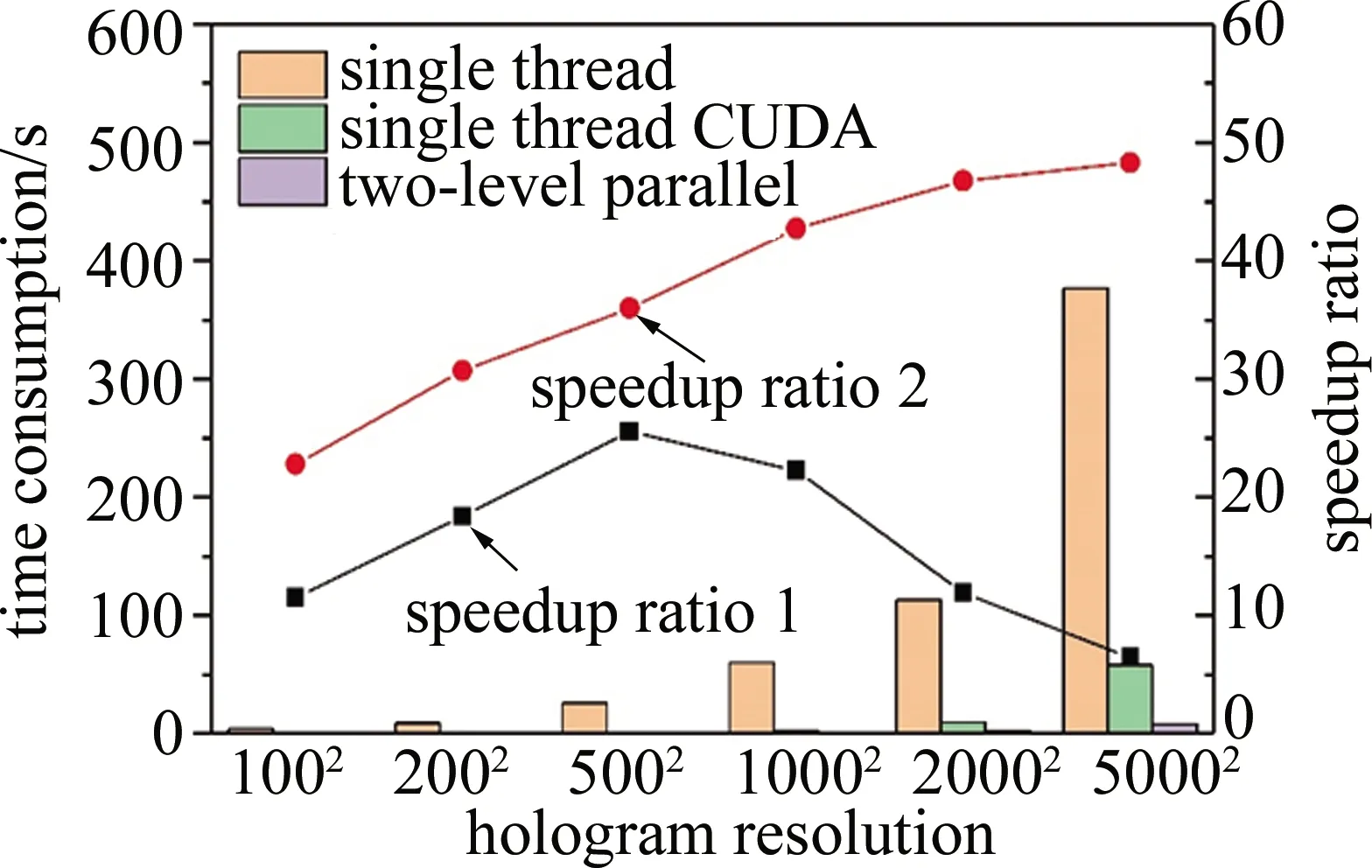
Fig.6 Time consumption of the three methods for holograms with different resolution
其次,选择分辨率为1000×1000的全息图,测试3种算法在重建截面数目不同时的计算耗时和加速比,结果如图7所示。随着重建截面的增多,单线程重建耗时急剧增加。二级并行算法的加速效果受限于线程数量,重建截面较少时,计算耗时主要来源于线程通信,重建截面数目影响较小,随着重建截面数目的增加,线程趋于满负荷状态,此时二级并行算法的计算耗时随之也会有较大的增加。而对于单线程调用CUDA,加速比都在20左右,重建截面数大于200后略有下降,这说明CUDA的并行效果稳定,单线程调用CUDA的重建耗时与单纯单线程的重建耗时为近似线性的关系。以上不同分辨率和不同截面数下的实验结果表明,采用二级并行架构重建全息图,当分辨率过大或重建截面过多时,加速效果会受到内存申请和线程通信的限制,在实际应用过程中应加以考虑。

Fig.7 Time consumption of the three methods for reconstruction with different plane numbers
3 结 论
提出了一种基于二级并行架构的颗粒全息图快速重建方法,该架构结合了OpenMP多线程技术和CUDA技术,利用OpenMP实现图片级并行,利用CUDA实现像素级并行。以煤粉颗粒全息图为实验对象,验证了二级并行架构全息重建的准确性和加速效果。结果表明二级并行架构在保证了重建准确性的同时,可极大提高重建速度。对于分辨率为5000×5000的全息图,可实现48.3倍的加速比。但随着全息图分辨率增大,加速比的增加会趋于平缓;随着重建截面的增多,加速比则趋于稳定。
